大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺

lenet
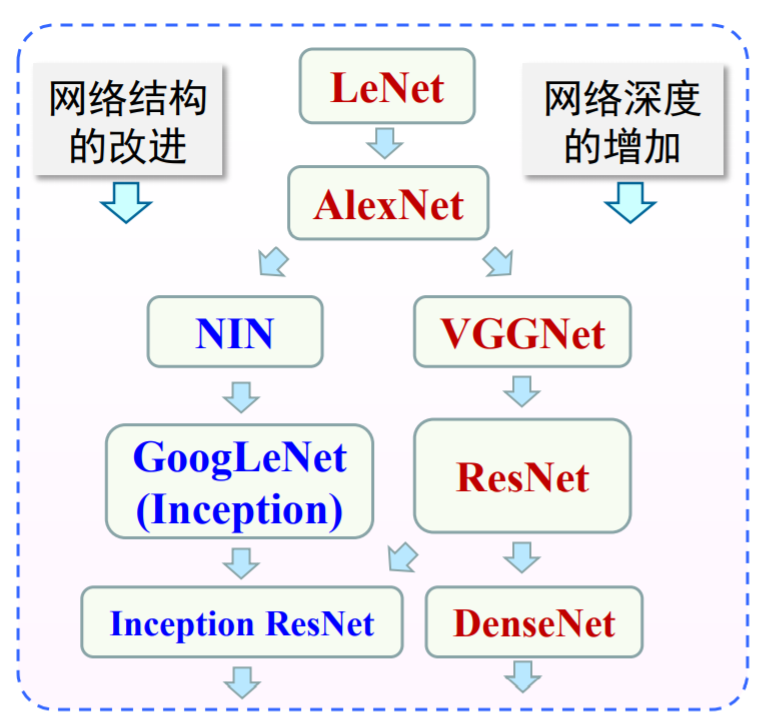
Lenet 是最早的卷积神经网络之一,并且推动了深度学习领域的发展,最初是为手写数字识别建立的网络。
LeNet分为卷积层块和全连接层块两个部分。
卷积层块里的基本单位是卷积层后接最大池化层,卷积层用来识别图像里的空间模式,如线条。
最大池化层则用来降低卷积层对位置的敏感性。有最大池化和平均池化两种。卷积层块由两个这样的基本单位重复堆叠构成。由于池化窗口与步幅形状相同,池化窗口在输入上每次滑动所覆盖的区域互不重叠。卷积层块的输出形状为(批量大小, 通道, 高, 宽)。当卷积层块的输出传入全连接层块时,全连接层块会将小批量中每个样本变平(flatten)。图片中相邻列之间的结构关系会被改变。
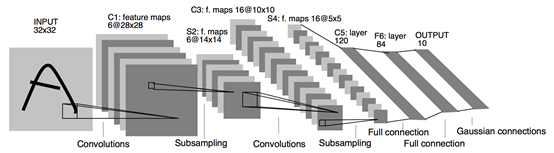
Alexnet
在Alexnet最重要的意义在于,通过8层卷积神经网络证明了机器自主学习的特征可以优于人工选择的特征,这进一步降低了机器学习的难度。
(1) AlexNet包含8层变换,其中有5层卷积和2层全连接隐藏层,以及1个全连接输出层。
(2)AlexNet将sigmoid激活函数改成了ReLU。ReLU激活函数在正区间的梯度恒为1,计算简单,且不会出现梯度无限接近0 的情况。
(3)AlexNet通过丢弃法来控制全连接层的模型复杂度。随机丢弃一部分神经元,降低复杂度,减少过拟合的可能。
VGG
VGG提出了可以通过重复使用简单的基础块来构建深度模型的思路。VGG由卷积层+池化层组成。
VGG块的组成规律是:连续使用数个相同的填充为1、窗口形状为3×33\times 33×3的卷积层后接上一个步幅为2、窗口形状为2×22\times 22×2的最大池化层。卷积层保持输入的高和宽不变,而池化层则对其减半。VGG网络由卷积层模块后接全连接层模块构成。卷积层模块串联数个vgg块。
NIN
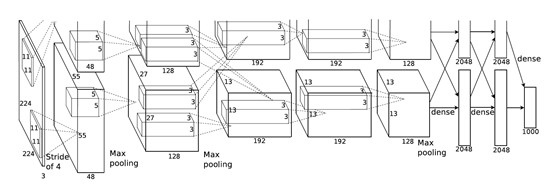
NIN提出了另外一个思路,即串联多个由卷积层和“全连接”层构成的小网络来构建一个深层网络。这里使用1*1卷积层代替全连接层。
除使用NiN块以外,NiN还有一个设计与AlexNet显著不同:NiN去掉了AlexNet最后的3个全连接层,取而代之地,NiN使用了输出通道数等于标签类别数的NiN块,然后使用全局平均池化层对每个通道中所有元素求平均并直接用于分类。这里的全局平均池化层即窗口形状等于输入空间维形状的平均池化层。NiN的这个设计的好处是可以显著减小模型参数尺寸,从而缓解过拟合。然而,该设计有时会造成获得有效模型的训练时间的增加。
NIN特别之处:
- NiN重复使用由卷积层和代替全连接层的1×11\times 11×1卷积层构成的NiN块来构建深层网络。
- NiN去除了容易造成过拟合的全连接输出层,而是将其替换成输出通道数等于标签类别数的NiN块和全局平均池化层。
Googlenet
GoogLeNet v1继承了NIN的思想,将多个Inception块和其他层串联起来。其中Inception块的通道数分配之比是在ImageNet数据集上通过大量的实验得来的。Inception块相当于一个有4条线路的子网络。它通过不同窗口形状的卷积层和最大池化层来并行抽取信息,并使用1×11\times 11×1卷积层减少通道数从而降低模型复杂度。
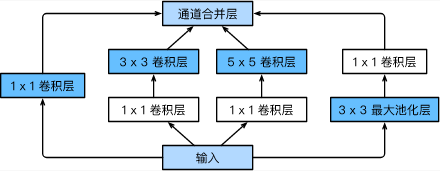
inception块的结构

Inception块相当于一个有4条线路的子网络。它通过不同窗口形状的卷积层和最大池化层来并行抽取信息,并使用11×1卷积层减少通道数从而降低模型复杂度。GoogLeNet在主体卷积部分中使用5个模块,每个模块之间使用步幅为2的3 3×3最大池化层来减小输出高宽。
(1)第一模块使用一个64通道的7×7卷积层。
(2)第二模块使用2个卷积层:首先是64通道的1×1卷积层,然后是将通道增大3倍的3×3卷积层。
(3)第三模块串联2个完整的Inception块。
(4)第四个模块中线路的通道数分配和第三模块中的类似,首先含3×3卷积层的第二条线路输出最多通道,其次是仅含1×1卷积层的第一条线路,之后是含5×5卷积层的第三条线路和含3×3最大池化层的第四条线路。
(5)第五模块有两个Inception块。其中每条线路的通道数的分配思路和第三、第四模块中的一致,只是在具体数值上有所不同。第五模块连接输出层,因此模块使用全局平均池化层以便全连接。
Resnet
解决了深度神经网络误差较大的弊端。
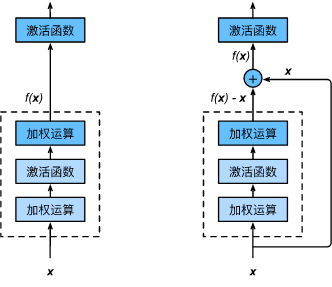
在残差块中,输入可通过跨层的数据线路更快地向前传播。神经网络所需要的拟合的f(x)-x 更容易被拟合优化。因此resnet更有效。
模型结构:卷积+批量归一化+激活+池化+4个残差块(卷积+池化+激活+卷积+池化+激活)+全局平均池化+全连接输出
Densenet
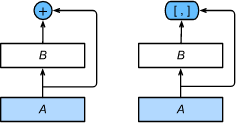
DenseNet里模块B的输出不是像ResNet那样和模块A的输出相加,而是在通道维上连结。这样模块A的输出可以直接传入模块B后面的层。在这个设计里,模块A直接跟模块BBB后面的所有层连接在了一起。这也是它被称为“稠密连接”的原因。 DenseNet的主要构建模块是稠密块(dense block)和过渡层(transition layer)。前者定义了输入和输出是如何连结的,后者则用来控制通道数,使之不过大。
Densenet结构:卷积+批量归一化+激活+池化+多个【稠密块+过渡层】+批量归一化+激活+全局归一化+全连接层
稠密块(多个层cov_block【归一化+激活+卷积】顺次连接),过渡层(批量归一化+激活+卷积+池化)
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/167200.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
