大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
https://r4ds.had.co.nz/transform.html#grouped-summaries-with-summarise
5.6 通过summarise()进行分组概括
summarise()将数据框折叠为单行:
summarise(flights, delay = mean(dep_delay, na.rm = TRUE))
#> # A tibble: 1 x 1
#> delay
#> <dbl>
#> 1 12.6
除非我们将它与group_by()配对,否则summarize()并不是非常有用。这会将分析单位从完整数据集更改为单个组。当在分组数据框上使用dplyr时,它们将自动“按组”应用。例如,如果我们将完全相同的代码应用于按日期分组的数据框,我们会得到每个日期的平均延迟:
by_day <- group_by(flights, year, month, day)
summarise(by_day, delay = mean(dep_delay, na.rm = TRUE))
#> # A tibble: 365 x 4
#> # Groups: year, month [?]
#> year month day delay
#> <int> <int> <int> <dbl>
#> 1 2013 1 1 11.5
#> 2 2013 1 2 13.9
#> 3 2013 1 3 11.0
#> 4 2013 1 4 8.95
#> 5 2013 1 5 5.73
#> 6 2013 1 6 7.15
#> # … with 359 more rows
在使用dplyr时group_by()和summarize()是同时使用最常用的工具之一:分组概括。但在我们进一步研究之前,我们需要引入管道的概念。
5.6.1 通过管道连接多个操作符
想要探索每个位置的距离和平均延迟之间的关系,可以编写如下代码:
by_dest <- group_by(flights, dest)
delay <- summarise(by_dest,
count = n(),
dist = mean(distance, na.rm = TRUE),
delay = mean(arr_delay, na.rm = TRUE)
)
delay <- filter(delay, count > 20, dest != "HNL")
# It looks like delays increase with distance up to ~750 miles
# and then decrease. Maybe as flights get longer there's more
# ability to make up delays in the air?
ggplot(data = delay, mapping = aes(x = dist, y = delay)) +
geom_point(aes(size = count), alpha = 1/3) +
geom_smooth(se = FALSE)
#> `geom_smooth()` using method = 'loess' and formula 'y ~ x'
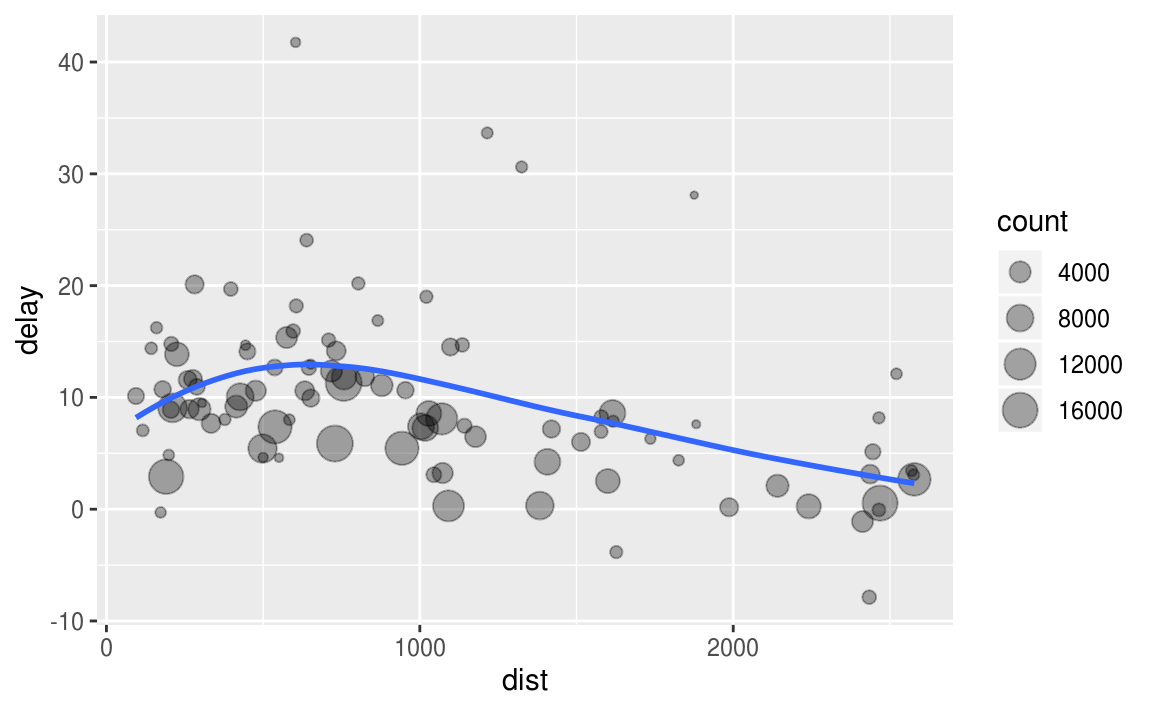

准备数据的三步:
- 按照destination过滤
- 概括计算distance,average delay和flights。
- 过滤,移除噪音点,移除Honolulu airport,因为它的距离大约是下一个最近的机场的两倍。
这段代码有点繁,因为我们必须为每个中间数据框命名。 命名有时候很难,所以这会减慢我们的分析速度。
还有另一种解决管道相同问题的方法,%>%:
delays <- flights %>%
group_by(dest) %>%
summarise(
count = n(),
dist = mean(distance, na.rm = TRUE),
delay = mean(arr_delay, na.rm = TRUE)
) %>%
filter(count > 20, dest != "HNL")
这侧重于转换,而不是转换的内容,这使代码更容易阅读。 可以将其作为一系列命令性语句阅读:组,然后汇总,然后过滤。 正如本文所述,在阅读代码时%>%意味着“然后”。
在幕后,x%>%f(y)变为f(x, y),x%>%f(y)%>%g(z)变为g(f(x,y),z) 等等。可以使用管道以从左到右,从上到下的方式重写多个操作。从现在开始会经常使用管道,因为它大大提高了代码的可读性.
使用管道是属于tidyverse的关键标准之一。唯一的例外是ggplot2:它是在发布管道操作符之前编写的。不幸的是,ggplot2的下一次迭代,ggvis,确实使用了这个管道,但是还没有为黄金时间做好准备。
5.6.2 缺失值
您可能想知道我们上面使用的na.rm参数。 如果我们不设置它会发生什么?
flights %>%
group_by(year, month, day) %>%
summarise(mean = mean(dep_delay))
#> # A tibble: 365 x 4
#> # Groups: year, month [?]
#> year month day mean
#> <int> <int> <int> <dbl>
#> 1 2013 1 1 NA
#> 2 2013 1 2 NA
#> 3 2013 1 3 NA
#> 4 2013 1 4 NA
#> 5 2013 1 5 NA
#> 6 2013 1 6 NA
#> # … with 359 more rows
我们得到了很多缺失值!这是因为聚合函数遵循通常的缺失值规则:如果输入中有任何缺失值,则输出将是缺失值。幸运的是,所有聚合函数都有一个na.rm参数,该参数在计算之前删除缺失值:
flights %>%
group_by(year, month, day) %>%
summarise(mean = mean(dep_delay, na.rm = TRUE))
#> # A tibble: 365 x 4
#> # Groups: year, month [?]
#> year month day mean
#> <int> <int> <int> <dbl>
#> 1 2013 1 1 11.5
#> 2 2013 1 2 13.9
#> 3 2013 1 3 11.0
#> 4 2013 1 4 8.95
#> 5 2013 1 5 5.73
#> 6 2013 1 6 7.15
#> # … with 359 more rows
在这种情况下,如果缺失值代表取消的航班,我们也可以通过首先删除已取消的航班来解决问题。我们将保存此数据集,以便我们可以在接下来的几个示例中重复使用它。
not_cancelled <- flights %>%
filter(!is.na(dep_delay), !is.na(arr_delay))
not_cancelled %>%
group_by(year, month, day) %>%
summarise(mean = mean(dep_delay))
#> # A tibble: 365 x 4
#> # Groups: year, month [?]
#> year month day mean
#> <int> <int> <int> <dbl>
#> 1 2013 1 1 11.4
#> 2 2013 1 2 13.7
#> 3 2013 1 3 10.9
#> 4 2013 1 4 8.97
#> 5 2013 1 5 5.73
#> 6 2013 1 6 7.15
#> # … with 359 more rows
5.6.3 计数
无论何时进行任何聚合,最好包括count(n())或非缺失值的计数(sum(!is.na(x)))。这样,可以根据非常少量的数据检查。例如,让我们看一下具有最高平均延迟的平面(由它们的尾号标识):
delays <- not_cancelled %>%
group_by(tailnum) %>%
summarise(
delay = mean(arr_delay)
)
ggplot(data = delays, mapping = aes(x = delay)) +
geom_freqpoly(binwidth = 10)
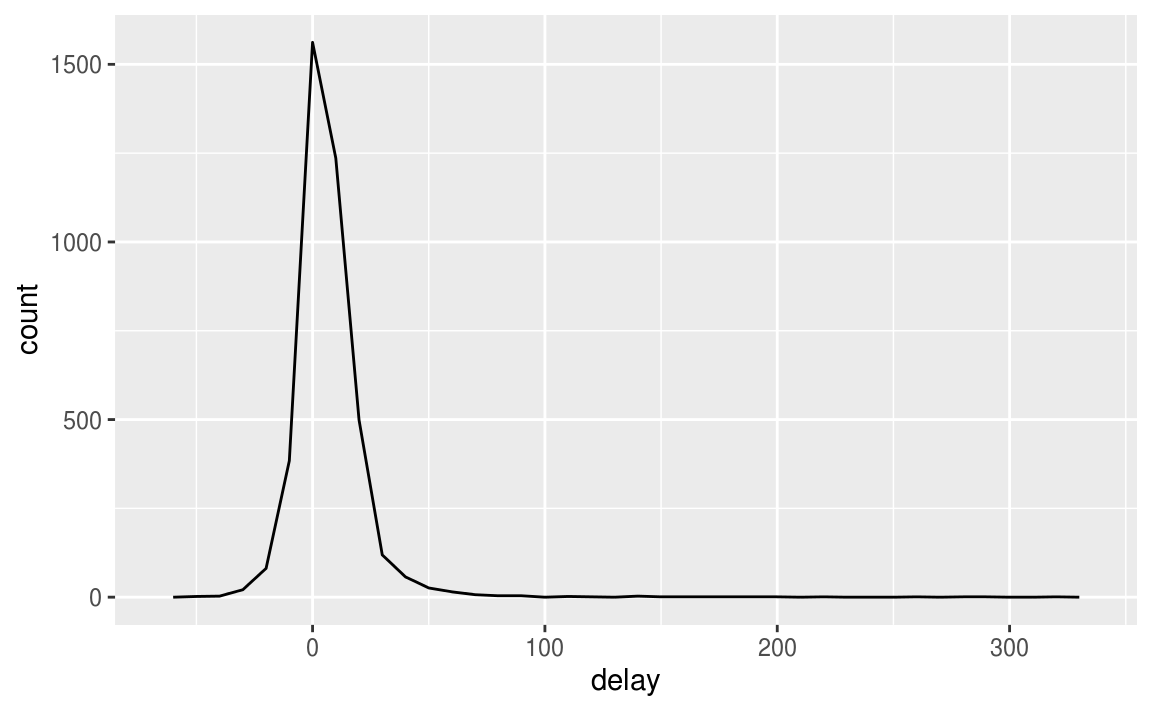
有些飞机的平均延误时间为5小时(300分钟)!
这个故事实际上有点微妙。 如果我们绘制航班数量与平均延误的散点图,我们可以获得更多信息:
delays <- not_cancelled %>%
group_by(tailnum) %>%
summarise(
delay = mean(arr_delay, na.rm = TRUE),
n = n()
)
ggplot(data = delays, mapping = aes(x = n, y = delay)) +
geom_point(alpha = 1/10)
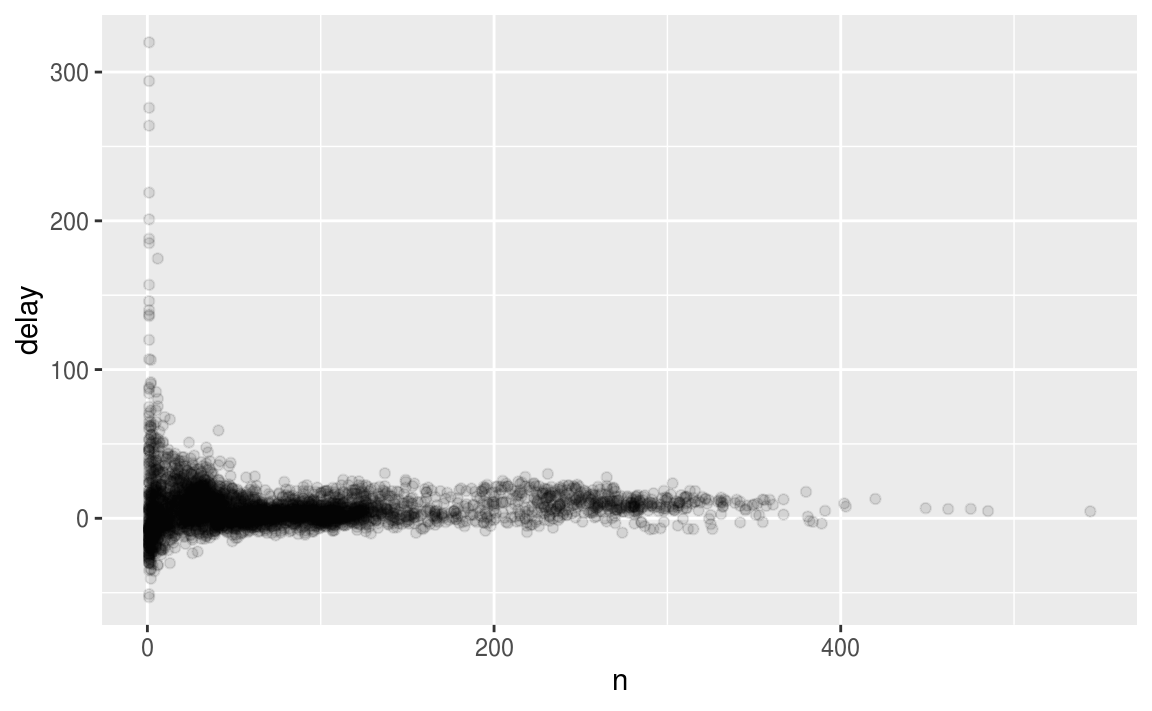
毫不奇怪,当航班很少时,平均延误会有更大的变化。此图的形状非常有特色:无论何时绘制平均值(或其他摘要)与组大小,都会看到随着样本量的增加,变化会减小。
在查看此类图时,过滤掉具有最少观察数的组通常很有用,因此可以看到更多的模式,而不是最小组中的极端变化。这就是下面的代码所做的,并向您展示了将ggplot2集成到dplyr流中的便捷模式。 必须从%>%切换到+,这有点痛苦,但是一旦掌握了它,就会非常方便。
delays %>%
filter(n > 25) %>%
ggplot(mapping = aes(x = n, y = delay)) +
geom_point(alpha = 1/10)
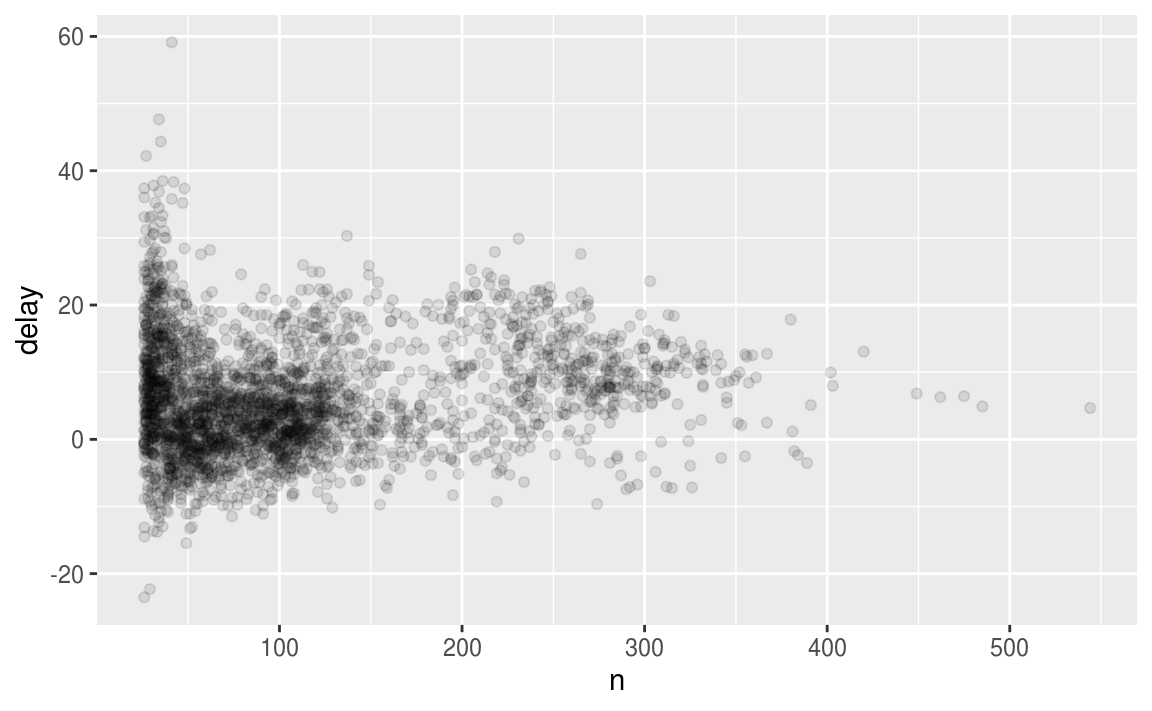
RStudio提示:一个有用的键盘快捷键是Cmd / Ctrl + Shift + P.这会将之前发送的块从编辑器重新发送到控制台。 当(例如)在上面的示例中探索n的值时,这非常方便。 使用Cmd / Ctrl + Enter发送整个块一次,然后修改n的值并按Cmd / Ctrl + Shift + P重新发送完整块。
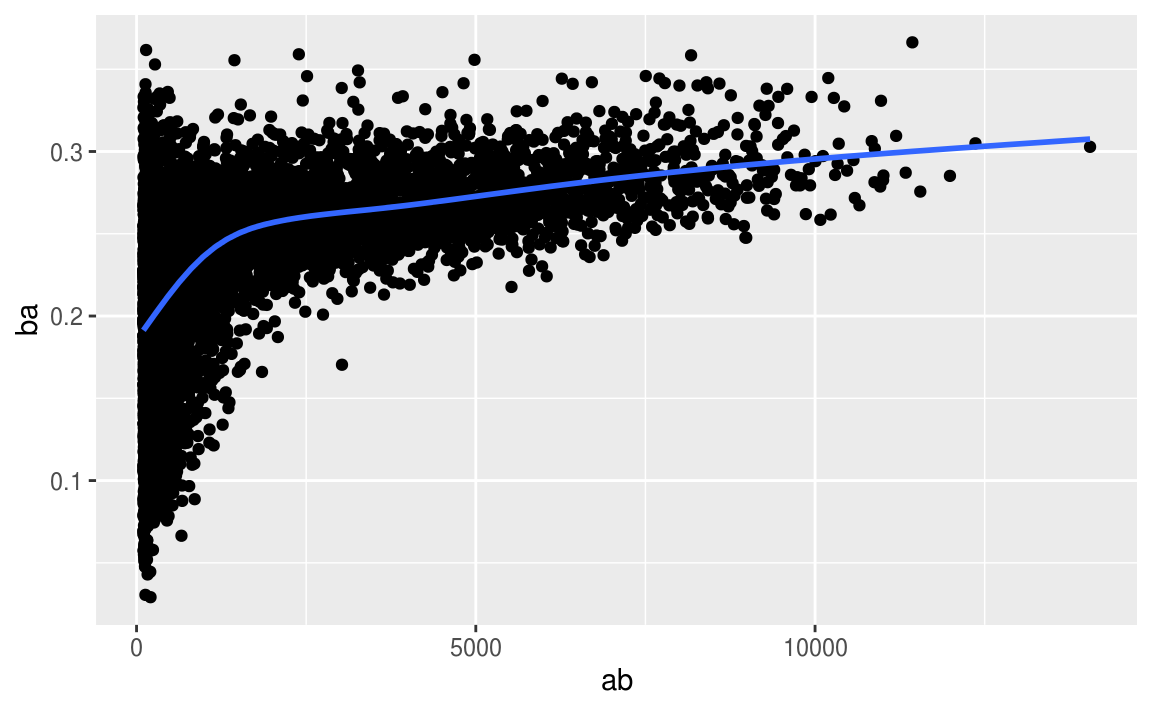
这种模式还有另一种常见的变化。让我们来看看棒球击球手的平均表现如何与他们击球的次数有关。在这里,使用来自拉赫曼包的数据来计算每个大联盟棒球运动员的击球率(击球次数/尝试次数)。
当绘制击球手的技能(按击球平均数,ba测量)与击球的机会数(ab测量)时,会看到两种模式:
- 如上所述,随着我们获得更多数据点,我们聚合的变化会减少。
- 技能(ba)与击球机会(ab)之间存在正相关关系。 这是因为球队控制谁去比赛,显然他们会选择最好的球员。
# Convert to a tibble so it prints nicely
batting <- as_tibble(Lahman::Batting)
batters <- batting %>%
group_by(playerID) %>%
summarise(
ba = sum(H, na.rm = TRUE) / sum(AB, na.rm = TRUE),
ab = sum(AB, na.rm = TRUE)
)
batters %>%
filter(ab > 100) %>%
ggplot(mapping = aes(x = ab, y = ba)) +
geom_point() +
geom_smooth(se = FALSE)
#> `geom_smooth()` using method = 'gam' and formula 'y ~ s(x, bs = "cs")'
这对排名也有重要意义。如果天真地对desc(ba)进行排序,那么打击率最高的人显然很幸运,不熟练:
batters %>%
arrange(desc(ba))
#> # A tibble: 18,915 x 3
#> playerID ba ab
#> <chr> <dbl> <int>
#> 1 abramge01 1 1
#> 2 banisje01 1 1
#> 3 bartocl01 1 1
#> 4 bassdo01 1 1
#> 5 berrijo01 1 1
#> 6 birasst01 1 2
#> # … with 1.891e+04 more rows
可以在这里找到对这个问题的一个很好的解释:http://varianceexplained.org/r/empirical_bayes_baseball/ 和 http://www.evanmiller.org/how-not-to-sort-by-average-rating.html。
5.6.4 实用的汇总功能
只使用平均值,计数和求和就可以获得很长的路要走,但R提供了许多其他有用的汇总函数:
- 衡量定位:我们使用均值
mean(x),但中位数median(x)也很有用。均值是除以长度的总和;中位数是一个值,其中50%的x高于它,50%低于它。
将聚合与逻辑子集相结合有时很有用。我们还没有谈到这种子集化,但你会在子集中了解更多。
not_cancelled %>%
group_by(year, month, day) %>%
summarise(
avg_delay1 = mean(arr_delay),
avg_delay2 = mean(arr_delay[arr_delay > 0]) # the average positive delay
)
#> # A tibble: 365 x 5
#> # Groups: year, month [?]
#> year month day avg_delay1 avg_delay2
#> <int> <int> <int> <dbl> <dbl>
#> 1 2013 1 1 12.7 32.5
#> 2 2013 1 2 12.7 32.0
#> 3 2013 1 3 5.73 27.7
#> 4 2013 1 4 -1.93 28.3
#> 5 2013 1 5 -1.53 22.6
#> 6 2013 1 6 4.24 24.4
#> # … with 359 more rows
- 衡量离散度:
sd(x),IQR(x),mad(x)。均方根偏差或标准差sd(x)是离散的标准度量。四分位数范围IQR(x)和中位数绝对偏差mad(x)是稳健的等价物,如果有异常值可能会更有用。
# Why is distance to some destinations more variable than to others?
not_cancelled %>%
group_by(dest) %>%
summarise(distance_sd = sd(distance)) %>%
arrange(desc(distance_sd))
#> # A tibble: 104 x 2
#> dest distance_sd
#> <chr> <dbl>
#> 1 EGE 10.5
#> 2 SAN 10.4
#> 3 SFO 10.2
#> 4 HNL 10.0
#> 5 SEA 9.98
#> 6 LAS 9.91
#> # … with 98 more rows
- 等级衡量:
minx(x),quantile(x,0.25),max(x)。 分位数是中位数的推广。 例如,quantile(x, 0.25)将发现x中值大于25%,并且小于剩余的75%的值。
# When do the first and last flights leave each day?
not_cancelled %>%
group_by(year, month, day) %>%
summarise(
first = min(dep_time),
last = max(dep_time)
)
#> # A tibble: 365 x 5
#> # Groups: year, month [?]
#> year month day first last
#> <int> <int> <int> <dbl> <dbl>
#> 1 2013 1 1 517 2356
#> 2 2013 1 2 42 2354
#> 3 2013 1 3 32 2349
#> 4 2013 1 4 25 2358
#> 5 2013 1 5 14 2357
#> 6 2013 1 6 16 2355
#> # … with 359 more rows
- Measures of position:
first(x),nth(x, 2),last(x)。与x[1],x[2]和x[length(x)]相似,但是如果该位置不存在,则允许设置默认值(即,您试图从组中获取第3个元素)只有两个元素)。 例如,我们可以找到每天的第一次和最后一次出发:
not_cancelled %>%
group_by(year, month, day) %>%
summarise(
first_dep = first(dep_time),
last_dep = last(dep_time)
)
#> # A tibble: 365 x 5
#> # Groups: year, month [?]
#> year month day first_dep last_dep
#> <int> <int> <int> <int> <int>
#> 1 2013 1 1 517 2356
#> 2 2013 1 2 42 2354
#> 3 2013 1 3 32 2349
#> 4 2013 1 4 25 2358
#> 5 2013 1 5 14 2357
#> 6 2013 1 6 16 2355
#> # … with 359 more rows
这些功能是对排名过滤的补充。 过滤提供所有变量,每个观察在一个单独的行中:
not_cancelled %>%
group_by(year, month, day) %>%
mutate(r = min_rank(desc(dep_time))) %>%
filter(r %in% range(r))
#> # A tibble: 770 x 20
#> # Groups: year, month, day [365]
#> year month day dep_time sched_dep_time dep_delay arr_time
#> <int> <int> <int> <int> <int> <dbl> <int>
#> 1 2013 1 1 517 515 2 830
#> 2 2013 1 1 2356 2359 -3 425
#> 3 2013 1 2 42 2359 43 518
#> 4 2013 1 2 2354 2359 -5 413
#> 5 2013 1 3 32 2359 33 504
#> 6 2013 1 3 2349 2359 -10 434
#> # … with 764 more rows, and 13 more variables: sched_arr_time <int>,
#> # arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
#> # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
#> # minute <dbl>, time_hour <dttm>, r <int>
- 计数和逻辑值的比例:
sum(x > 10),mean(y == 0)。 当与数字函数一起使用时,TRUE转换为1,FALSE转换为0。这使得sum()和mean()非常有用:sum(x)给出x中的TRUE数,而mean(x)给出比例。
# How many flights left before 5am? (these usually indicate delayed
# flights from the previous day)
not_cancelled %>%
group_by(year, month, day) %>%
summarise(n_early = sum(dep_time < 500))
#> # A tibble: 365 x 4
#> # Groups: year, month [?]
#> year month day n_early
#> <int> <int> <int> <int>
#> 1 2013 1 1 0
#> 2 2013 1 2 3
#> 3 2013 1 3 4
#> 4 2013 1 4 3
#> 5 2013 1 5 3
#> 6 2013 1 6 2
#> # … with 359 more rows
# What proportion of flights are delayed by more than an hour?
not_cancelled %>%
group_by(year, month, day) %>%
summarise(hour_perc = mean(arr_delay > 60))
#> # A tibble: 365 x 4
#> # Groups: year, month [?]
#> year month day hour_perc
#> <int> <int> <int> <dbl>
#> 1 2013 1 1 0.0722
#> 2 2013 1 2 0.0851
#> 3 2013 1 3 0.0567
#> 4 2013 1 4 0.0396
#> 5 2013 1 5 0.0349
#> 6 2013 1 6 0.0470
#> # … with 359 more rows
5.6.5 对多个变量分组
当您按多个变量分组时,每个概括都会剥离一个分组级别。 这样可以轻松逐步汇总数据集:
daily <- group_by(flights, year, month, day)
(per_day <- summarise(daily, flights = n()))
#> # A tibble: 365 x 4
#> # Groups: year, month [?]
#> year month day flights
#> <int> <int> <int> <int>
#> 1 2013 1 1 842
#> 2 2013 1 2 943
#> 3 2013 1 3 914
#> 4 2013 1 4 915
#> 5 2013 1 5 720
#> 6 2013 1 6 832
#> # … with 359 more rows
(per_month <- summarise(per_day, flights = sum(flights)))
#> # A tibble: 12 x 3
#> # Groups: year [?]
#> year month flights
#> <int> <int> <int>
#> 1 2013 1 27004
#> 2 2013 2 24951
#> 3 2013 3 28834
#> 4 2013 4 28330
#> 5 2013 5 28796
#> 6 2013 6 28243
#> # … with 6 more rows
(per_year <- summarise(per_month, flights = sum(flights)))
#> # A tibble: 1 x 2
#> year flights
#> <int> <int>
#> 1 2013 336776
逐步汇总时要小心:总和和计数都可以,但是需要考虑加权平均值和方差,并且不可能完全按照基于排名的统计数据(如中位数)进行。 换句话说,分组总和的总和是总和,但分组中位数的中位数不是总体中位数。
5.6.6 取消组合
如果需要删除分组,并返回对未分组数据的操作,使用ungroup()。
daily %>%
ungroup() %>% # no longer grouped by date
summarise(flights = n()) # all flights
#> # A tibble: 1 x 1
#> flights
#> <int>
#> 1 336776
5.6.7 练习
1. Brainstorm at least 5 different ways to assess the typical delay characteristics of a group of flights. Consider the following scenarios:
- A flight is 15 minutes early 50% of the time, and 15 minutes late 50% of the time.
- A flight is always 10 minutes late.
- A flight is 30 minutes early 50% of the time, and 30 minutes late 50% of the time.
- 99% of the time a flight is on time. 1% of the time it’s 2 hours late.
Which is more important: arrival delay or departure delay?
2. Come up with another approach that will give you the same output as not_cancelled %>% count(dest) and not_cancelled %>% count(tailnum, wt = distance) (without using count()).
3. Our definition of cancelled flights (is.na(dep_delay) | is.na(arr_delay) ) is slightly suboptimal. Why? Which is the most important column?
4. Look at the number of cancelled flights per day. Is there a pattern? Is the proportion of cancelled flights related to the average delay?
5. Which carrier has the worst delays? Challenge: can you disentangle the effects of bad airports vs. bad carriers? Why/why not? (Hint: think about flights %>% group_by(carrier, dest) %>% summarise(n()))
6. What does the sort argument to count() do. When might you use it?
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/167191.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
