大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
1 总体介绍
在以下主题中,我们将回顾有助于分析时间序列数据的技术,即遵循非随机顺序的测量序列。与在大多数其他统计数据的上下文中讨论的随机观测样本的分析不同,时间序列的分析基于数据文件中的连续值表示以等间隔时间间隔进行的连续测量的假设。
本节描述的方法的详细讨论可以在Anderson(1976),Box and Jenkins(1976),Kendall(1984),Kendall and Ord(1990),Montgomery,Johnson和Gardiner(1990),Pankratz(1983)中找到。 ),Shumway(1988),Vandaele(1983),Walker(1991)和Wei(1989)。
2 两个主要目标
时间序列分析有两个主要目标:
(a)确定观察序列所代表的现象的性质。
(b)预测(预测时间序列变量的未来值)。
这两个目标都要求识别观察到的时间序列数据的模式,并且或多或少地正式描述。一旦模式建立,我们就可以将其与其他数据进行解释和整合(即,在我们的调查现象理论中使用它,例如季节性商品价格)。无论我们的理解深度和我们对该现象的解释(理论)的有效性,我们都可以推断出已识别的模式以预测未来事件。
3 识别时间序列数据中的模式
3.1系统模式和随机噪声
与大多数其他分析一样,在时间序列分析中,假设数据由系统模式(通常是一组可识别组件)和随机噪声(错误)组成,这通常使模式难以识别。大多数时间序列分析技术涉及过滤噪声的某种形式,以使图案更加突出。
3.2时间序列模式的两个一般方面
大多数时间序列模式可以用两个基本类别的组件来描述:趋势和季节性。前者代表一般的系统线性或(最常见)非线性成分,其随时间变化并且在我们的数据捕获的时间范围内不重复或至少不重复(例如,平台随后是指数生长期)。后者可能具有正式相似的性质(例如,平稳期随后呈指数增长期),然而,随着时间的推移,它在系统间隔中重复。这两个通用类别的时间序列组件可以共存于现实数据中。例如,公司的销售额可以快速增长多年,但仍然遵循一致的季节性模式(例如,12月份每年销售额的25%,而8月份仅为4%)。


这种一般模式在“经典” G系列数据集(Box和Jenkins,1976,第531页)中有很好的说明,代表了从1949年到1960年连续12年的月度国际航空公司乘客总数(以千计)(见示例数据文件)G.sta和上图)。如果绘制航空公司乘客总数的连续观测值(月份),则会出现明显的线性趋势,表明航空业多年来保持稳定增长(1960年乘客人数比1949年增加约4倍)。同时,每月的数字将遵循几乎相同的模式(例如,假期期间旅行的人数比一年中的任何其他时间都多)。该示例数据文件还示出了时间序列数据中非常常见的一般类型的模式,其中季节变化的幅度随着总体趋势而增加(即,方差与系列的片段上的平均值相关)。这种模式称为乘法季节性表明季节变化的相对幅度随时间变化是恒定的,因此它与趋势有关。
3.3趋势分析
没有经过验证的“自动”技术来识别时间序列数据中的趋势分量; 然而,只要趋势是单调的(持续增加或减少),那么部分数据分析通常不是很困难。如果时间序列数据包含相当大的误差,那么趋势识别过程的第一步就是平滑。
平滑。平滑总是涉及某种形式的局部数据平均,使得各个观察的非系统成分相互抵消。最常见的技术是移动平均平滑,它用n个周围元素的简单或加权平均值替换系列的每个元素,其中n平滑“窗口”的宽度(见Box&Jenkins,1976; Velleman&Hoaglin,1981)。可以使用中位数而不是手段。与移动平均平滑相比,中值的主要优点是其结果不受异常值的偏差(在平滑窗口内)。因此,如果数据中存在异常值(例如,由于测量误差),则中值平滑通常比基于相同窗口宽度的移动平均产生更平滑或至少更“可靠”的曲线。中值平滑的主要缺点是,在没有明显的异常值的情况下,它可能产生比移动平均值更多的“锯齿状”曲线,并且不允许加权。
在相对较不常见的情况下(在时间序列数据中),当测量误差非常大时,可以使用距离加权最小二乘平滑或负指数加权平滑技术。所有这些方法都会滤除噪声并将数据转换为相对不受异常值影响的平滑曲线(有关详细信息,请参阅每个方法的相应章节)。具有相对较少且系统分布的点的系列可以用双三次样条平滑。
适合功能。许多单调的时间序列数据可以通过线性函数充分近似; 如果存在明显的单调非线性分量,则首先需要对数据进行变换以消除非线性。通常可以使用对数,指数或(不太常见)多项式函数。
3.4季节性分析
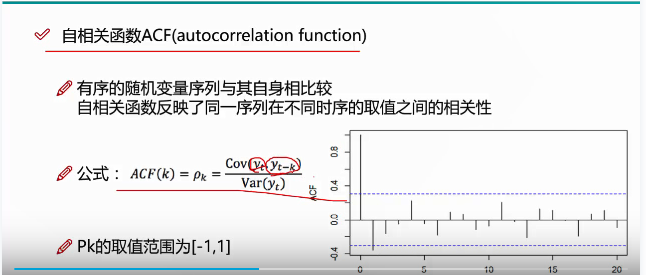
季节依赖性(季节性)是时间序列模式的另一个通用组成部分。上述航空公司乘客数据的例子说明了这个概念。它被正式定义为系列的每个第i个元素和第(ik)个元素(Kendall,1976)之间的阶数k的相关依赖性,并且通过自相关(即,两个术语之间的相关性)来测量; k通常称为滞后。如果测量误差不是太大,则可以在系列中视觉识别季节性,作为重复每个k元素的模式。
自相关相关图。可以通过相关图检查时间序列的季节性模式。相关图(自相关图)以图形和数字方式显示自相关函数(ACF),即,在指定的滞后范围(例如,1到30)内的连续滞后的串行相关系数(及其标准误差)。每个滞后的两个标准误差的范围通常在相关图中标出,但通常自相关的大小比其可靠性更有意义(参见基本概念),因为我们通常只对非常强(因此非常重要)的自相关感兴趣。
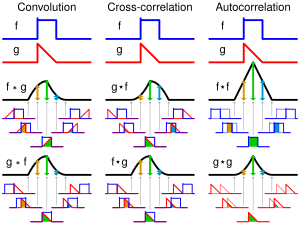
检查相关图。在检查相关图时,您应该记住,连续滞后的自相关正式依赖。请考虑以下示例。如果第一个元素与第二个元素密切相关,第二个元素与第二个元素密切相关,那么第一个元素也必须与第三个元素有些相关,等等。这意味着在删除第一个元素后,序列依赖关系的模式可能会发生很大变化自相关(即差分系列后滞后为1)。

偏自相关。检查序列依赖关系的另一个有用方法是检查偏自相关函数(PACF) – 自相关的扩展,其中依赖于中间元素(内部元素)滞后)被删除。换句话说,偏自相关类似于自相关,除了在计算它时,与滞后内所有元素的(自动)相关性被偏离(Box&Jenkins,1976;另见McDowall,McCleary,Meidinger,&Hay, 1980年)。如果指定滞后1(即,滞后内没有中间元素),则偏自相关等效于自相关。从某种意义上说,偏自相关为各个滞后提供了“更清晰”的串行依赖关系图(不会被其他串行依赖关系混淆)。
删除串行依赖。可以通过对系列进行差分来消除对k的特定滞后的串行依赖性,即将该系列的每个第i个元素转换为与第(ik)个元素的差异。这种转变有两个主要原因。
首先,我们可以确定系列中季节性依赖的隐藏性质。请记住,正如前一段所述,连续滞后的自相关是相互依赖的。因此,删除一些自相关将改变其他自动相关性,也就是说,它可能会消除它们,或者它可能使其他一些季节性更明显。
消除季节性依赖性的另一个原因是使系列稳定,这是ARIMA和其他技术所必需的。
4 ARIMA
可以拆分成AR MA I三个部分来讲,首先是AR(自回归模型)

P阶其实就是当前值和历史前几个值有关,如果p等于1就有前一个值有关,等于2与前两个值有关,然后进行累加,求解参数。
MA

ARMA
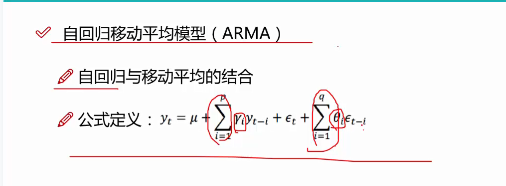
I
表示差分,通过差分来平稳化

4.1总体介绍
在识别时间序列数据模式中讨论的建模和预测程序涉及过程数学模型的知识。然而,在现实生活中的研究和实践中,数据模式尚不清楚,个别观察涉及相当大的误差,我们仍然需要不仅揭示数据中隐藏的模式,还需要生成预测。Box和Jenkins(1976)开发的ARIMA方法允许我们这样做; 它在许多领域获得了极大的普及,研究实践证实了它的力量和灵活性(Hoff,1983; Pankratz,1983; Vandaele,1983)。然而,由于其强大的功能和灵活性,ARIMA是一项复杂的技术; 它不易使用,需要大量的经验,虽然它经常产生令人满意的结果,但这些结果取决于研究人员的专业水平(Bails&Peppers,1982)。以下部分将介绍此方法的基本概念。对于那些对应用导向(非数学),ARIMA方法介绍感兴趣的人,我们推荐McDowall,McCleary,Meidinger和Hay(1980)。
4.2两个常见的过程
自回归过程。大多数时间序列由连续依赖的元素组成,在这种意义上,您可以从特定的,时间滞后的(先前的)元素中估计描述系列的连续元素的系数或系数集。这可以总结在等式中:x t =  +
+  1 * x (t-1) + 2 * x (t-2) + 3 * x (t-3) + … +
1 * x (t-1) + 2 * x (t-2) + 3 * x (t-3) + … +
是一个常数(截距),和
1,2,3 是自回归模型参数。
用语言来说,每个观察由随机误差分量(随机冲击)和先前观察的线性组合组成。
可变性要求。没有太多细节,移动平均过程和自回归过程之间存在“二元性”(例如,参见Box&Jenkins,1976; Montgomery,Johnson,&Gardiner,1990),即上面的移动平均方程可以被重写(反转)成自回归形式(无限次序)。然而,类似于上述平稳性条件,这只能在移动平均参数遵循某些条件时,即,如果模型是可逆的情况下才能进行。否则,序列将不会稳定。
4.3ARIMA方法论
自回归移动平均模型。Box和Jenkins(1976)引入的一般模型包括自回归和移动平均参数,并明确包括模型公式中的差分。具体而言,模型中的三种参数是:自回归参数(p),差分通过次数(d)和移动平均参数(q)。在Box和Jenkins介绍的符号中,模型总结为ARIMA(p,d,q); 因此,例如,描述为(0,1,2)的模型意味着它包含0(零)自回归(p)参数和2个移动平均值(q)在一次差异之后为该系列计算的参数。
识别。如前所述,ARIMA的输入序列需要是固定的,也就是说,它应该具有恒定的均值,方差和随时间变化的自相关性。因此,通常首先需要对系列进行区分,直到它静止为止(这通常还需要对数据进行对数转换以稳定方差)。为了实现平稳性,系列需要区分的次数反映在d中参数(见前一段)。为了确定必要的差分水平,您应该检查数据和自相关图的图。水平的显着变化(强烈的向上或向下变化)通常需要一阶非季节性(滞后= 1)差异; 坡度的强烈变化通常需要二阶非季节差分。季节性模式需要各自的季节差异(见下文)。如果估计的自相关系数在较长的滞后处缓慢下降,则通常需要一阶差分。但是,您应该记住,某些时间序列可能需要很少或不需要差分,并且差异系列会产生较不稳定的系数估计值。
在这个阶段(通常称为识别阶段,见下文),我们还需要确定有多少自回归(p)和移动平均(q)参数是必要的,以产生一个有效但仍然简约的过程模型(简约意味着它在所有适合数据的模型中具有最少的参数和最大的自由度。在实践中,p或q参数的数量很少需要大于2(更具体的建议见下文)。
估计和预测。在下一步(估计),估计参数(使用函数最小化过程,见下文;有关最小化过程的更多信息,请参见非线性估计),以便最小化残差平方和。在最后阶段(预测)中使用参数的估计来计算序列的新值(超出输入数据集中包括的那些值)和那些预测值的置信区间。对变换(差分)数据执行估计过程; 在生成预测之前,需要整合该系列(积分是差分的倒数),以便预测以与输入数据兼容的值表示。该自动积分特征由方法名称中的字母I表示(ARIMA =自动回归综合移动平均值)。
ARIMA模型中的常量。除了标准的自回归和移动平均参数之外,ARIMA模型还可以包括常数,如上所述。(统计上显着的)常数的解释取决于适合的模型。具体来说,(1)如果模型中没有自回归参数,则常数的期望值是 系列的均值; (2)如果序列中存在自回归参数,则常数表示截距。如果序列不同,则常数表示差异序列的均值或截距; 例如,如果序列差异一次,并且模型中没有自回归参数,则常量表示差异序列的均值,因此无差别序列的线性趋势斜率。
系列的均值; (2)如果序列中存在自回归参数,则常数表示截距。如果序列不同,则常数表示差异序列的均值或截距; 例如,如果序列差异一次,并且模型中没有自回归参数,则常量表示差异序列的均值,因此无差别序列的线性趋势斜率。
4.4识别阶段


要估计的参数数量。 在估计开始之前,我们需要决定(确定)要估算的ARIMA参数的具体数量和类型。识别阶段使用的主要工具是系列图,自相关(ACF)和部分自相关(PACF)的相关图。这个决定并不简单,在不太典型的情况下,不仅需要经验,还需要对替代模型(以及ARIMA的技术参数)进行大量实验。然而,大多数经验时间序列模式可以使用基于自相关图(ACF)和部分自相关图(PACF)的形状识别的5个基本模型中的一个来充分近似。以下简要总结基于Pankratz(1983)的实际建议; 有关其他实用建议,另见Hoff(1983),McCleary和Hay(1980),McDowall,McCleary,Meidinger和Hay(1980),以及Vandaele(1983)。另外,请注意,由于每种参数(待估计)的数量几乎不会大于2,因此在相同数据上尝试替代模型通常是切实可行的。
- 一个自回归(p)参数:ACF – 指数衰减; PACF – 滞后1的峰值,其他滞后没有相关性。
- 两个自回归(p)参数:ACF – 正弦波形状图案或一组指数衰减; PACF – 滞后1和2,与其他滞后没有相关性。
- 一个移动平均(q)参数:ACF – 滞后1时的尖峰,其他滞后没有相关性; PACF – 呈指数衰减。
- 两个移动平均(q)参数:ACF – 滞后1和2的尖峰,其他滞后没有相关性; PACF – 正弦波形状图案或一组指数衰减。
- 一个自回归(p)和一个移动平均(q)参数:ACF – 从滞后1开始的指数衰减; PACF – 从滞后1开始的指数衰减。
季节性模特。乘法季节性ARIMA是前面段落中引入的方法的推广和扩展,其中一个模式随着时间的推移在季节性重复。除了非季节性参数之外,还需要估算指定滞后的季节性参数(在识别阶段确定)。类似于简单的ARIMA参数,它们是:季节性自回归(ps),季节性差分(ds)和季节性移动平均参数(qs)。例如,模型(0,1,2)(0,1,1)描述了一个不包含自回归参数,2个常规移动平均参数和1个季节性移动平均参数的模型,并且这些参数是在它与滞后1差异一次后计算的,并且一度是季节性差异。用于季节性参数的季节性滞后通常在识别阶段确定,并且必须明确指定。
有关选择待估计参数的一般建议(基于ACF和PACF)也适用于季节性模型。主要区别在于,在季节性系列中,ACF和PACF将在季节性滞后的倍数处显示相当大的系数(除了反映系列非季节性成分的整体模式)。
4.5参数估计
有几种不同的方法来估计参数。所有这些都应该产生非常相似的估计,但对于任何给定的模型可能或多或少都有效。通常,在参数估计阶段期间使用函数最小化算法(所谓的准牛顿法;参考非线性估计的描述) 方法)在给定参数值的情况下最大化观察到的序列的似然性(概率)。实际上,这需要在给定相应参数的情况下计算残差的(条件)平方和(SS)。已经提出了不同的方法来计算残差的SS:(1)根据McLeod和Sales(1983)的近似最大似然法,(2)具有反向的近似最大似然法,以及(3)精确的最大似然法根据Melard(1984)。
比较方法。通常,所有方法都应该产生非常相似的参数估计。此外,在大多数现实世界的时间序列应用中,所有方法都具有相同的效率。然而,上面的方法1(近似最大似然,没有后向)是最快的,并且应该特别用于非常长的时间序列(例如,具有超过30,000个观测值)。Melard的精确最大似然法(数字3当用于估计具有长季节性滞后的季节性模型(例如,每年滞后365天)的参数时,上述)也可能变得低效。另一方面,您应该首先使用近似最大似然法,以便建立非常接近实际最终值的初始参数估计; 因此,通常只需要几次具有精确最大似然法(3,以上)的迭代来完成参数估计。
参数标准错误。对于所有参数估计,您将计算所谓的渐近标准误差。这些是通过有限差分近似的二阶偏导数矩阵计算的(另请参见非线性估计中的相应讨论)。
罚款价值。如上所述,估计过程要求最小化ARIMA残差的(条件)平方和。如果模型不合适,则在迭代估计过程期间可能发生参数估计变得非常大,并且实际上无效。在这种情况下,它将为SS 分配一个非常大的值(所谓的惩罚值)。这通常会“诱导”迭代过程以使参数远离无效范围。但是,在某些情况下,甚至此策略也会失败,您可能会在屏幕上看到(在估算过程中))连续迭代中SS的非常大的值。在这种情况下,请仔细评估模型的适用性。如果您的模型包含许多参数,并且可能包含干预组件(请参见下文),则可以尝试使用不同的参数起始值。
4.6评估模型
参数估计。您将报告从参数标准误差计算的近似t值(参见上文)。如果不显着,则在大多数情况下可以从模型中删除相应参数而基本上不影响模型的整体拟合。
其他质量标准。对模型可靠性的另一个直接和常见的衡量标准是基于部分数据生成的预测的准确性,以便可以将预测与已知(原始)观测结果进行比较。

然而,一个好的模型不仅应该提供足够准确的预测,它还应该是简约的并且产生仅包含噪声且没有系统组件的统计独立残差(例如,残差的相关图不应该揭示任何序列依赖性)。对模型的一个很好的测试是(a)绘制残差并检查它们是否存在任何系统趋势,以及(b)检查残差的自相关图(残差之间不应存在序列依赖性)。
残差分析。这里主要关注的是残差系统地分布在整个系列中(例如,它们在序列的第一部分可能是负的,在第二部分中可能接近零)或者它们包含一些序列依赖性,这可能表明ARIMA模型是不够的。对ARIMA残差的分析构成了该模型的重要检验。估计过程假设残差不是(自动)相关的并且它们是正态分布的。
限制。ARIMA方法仅适用于静止的时间序列(即,其平均值,方差和自相关应在时间上近似恒定),并且建议输入数据中至少有50个观测值。还假设估计参数的值在整个系列中是恒定的。
5 指数平滑
5.1总体介绍
指数平滑作为各种时间序列数据的预测方法已经变得非常流行。历史上,该方法由Brown和Holt独立开发。布朗在第二次世界大战期间为美国海军工作,他的任务是设计一个火控信息跟踪系统来计算潜艇的位置。后来,他将这种技术应用于备件需求预测(库存控制问题)。他在1959年关于库存控制的书中描述了这些想法。霍尔特的研究由海军研究办公室赞助; 他独立地为恒定过程,线性趋势过程和季节性数据开发了指数平滑模型。
Gardner(1985)提出了指数平滑方法的“统一”分类。在Makridakis,Wheelwright和McGee(1983),Makridakis和Wheelwright(1989),Montgomery,Johnson和Gardiner(1990)中也可以找到优秀的介绍。
5.2简单的指数平滑
时间序列的简单和实用模型是将每个观察视为由常数(b)和误差分量 (epsilon)组成,即:X t = b + t。常数b在该系列的每个片段中相对稳定,但可能随时间缓慢变化。如果合适,那么一种方法来隔离b的真值因此系列的系统性或可预测部分是计算一种移动平均值,其中当前和紧接在前(“较年轻”)的观测值被分配比相应的较旧观测值更大的权重。简单的指数平滑完成了这样的加权,其中指数较小的权重被分配给较旧的观察。简单指数平滑的具体公式是:
(epsilon)组成,即:X t = b + t。常数b在该系列的每个片段中相对稳定,但可能随时间缓慢变化。如果合适,那么一种方法来隔离b的真值因此系列的系统性或可预测部分是计算一种移动平均值,其中当前和紧接在前(“较年轻”)的观测值被分配比相应的较旧观测值更大的权重。简单的指数平滑完成了这样的加权,其中指数较小的权重被分配给较旧的观察。简单指数平滑的具体公式是:
S t =  * X t +(1- )* S t-1
* X t +(1- )* S t-1
当递归地应用于该系列中的每个连续观察时,每个新的平滑值(预测)被计算为当前观察和先前平滑观察的加权平均值; 先前的平滑观察依次从先前观察值和前一次观察之前的平滑值计算,依此类推。因此,实际上,每个平滑值是先前观察的加权平均值,其中权重根据参数(α)的值指数地减小。如果等于1(一),则完全忽略先前的观察; 如果等于0(零),然后完全忽略当前观察,平滑值完全由先前的平滑值组成(其依次是从平滑后的观察计算出来的,依此类推;因此所有平滑的值将是等于初始平滑值S 0)。中间值将产生中间结果。
尽管已经做了大量工作来研究(简单和复杂)指数平滑的理论性质(例如,参见Gardner,1985; Muth,1960;另见McKenzie,1984,1985),该方法已经大受欢迎,主要是因为它作为预测工具的有用性。例如,Makridakis 等人的实证研究。(1982,Makridakis,1983),已经表明简单的指数平滑是一个时期预测的最佳选择,从24种其他时间序列方法和使用各种精确度测量(参见Gross和Craig,1974,for额外的经验证据)。因此,无论观察时间序列的基础过程的理论模型如何,简单的指数平滑通常会产生非常准确的预测。
5.3选择参数的最佳值 (ALPHA)
(ALPHA)
Gardner(1985)讨论了选择适当平滑参数的各种理论和经验论证。显然,看看上面给出的公式, 应该落入0(零)和1之间的区间(尽管如此,参见Brenner 等,1968,ARIMA的观点,暗示0 << 2)。Gardner(1985)报道,在从业者中,通常建议小于.30。然而,在Makridakis 等人的研究中。(1982),高于.30的值经常产生最佳预测。在回顾了有关该主题的文献后,Gardner(1985)得出结论,最好从数据中估算出最优值(见下文),而不是“猜测”并设定人为的低值。
应该落入0(零)和1之间的区间(尽管如此,参见Brenner 等,1968,ARIMA的观点,暗示0 << 2)。Gardner(1985)报道,在从业者中,通常建议小于.30。然而,在Makridakis 等人的研究中。(1982),高于.30的值经常产生最佳预测。在回顾了有关该主题的文献后,Gardner(1985)得出结论,最好从数据中估算出最优值(见下文),而不是“猜测”并设定人为的低值。
估算数据的最佳价值。实际上,平滑参数通常通过参数空间的网格搜索来选择; 也就是说,尝试不同的解决方案,例如,使用= 0.1到= 0.9,增量为0.1。然后选择以便产生残差的最小平方和(或均方)(即,观测值减去一步预测;这个均方误差也称为事后平均误差,事后 MSE简称)。
5.4缺乏适应指数(错误)
基于特定值评估预测准确性的最直接方法是简单地绘制观测值和一步预测。该图还可以包括残差(针对右Y轴缩放),从而也可以容易地识别更好或最差拟合的区域。

这种对预测准确性的目视检查通常是确定当前指数平滑模型是否适合数据的最有效方法。此外,除了事后 MSE标准(见前一段),还有其他可用于确定最佳参数的误差统计量度(见Makridakis,Wheelwright和McGee,1983):
平均误差:平均误差(ME)值简单地计算为平均误差值(观察到的减去一步预测的平均值)。显然,这种措施的一个缺点是正负误差值可以相互抵消,因此这个指标并不是整体拟合的非常好的指标。
平均绝对误差:平均绝对误差(MAE)值被计算为平均绝对误差值。如果此值为0(零),则拟合(预测)是完美的。与均方误差值相比,这种拟合度量将“去强调”异常值,即,独特或罕见的大误差值将影响MAE小于MSE值。
平方误差之和(SSE),均方误差。这些值被计算为平方误差值的和(或平均值)。这是统计拟合程序中最常用的缺乏拟合指标。
百分比误差(PE)。所有上述措施都依赖于实际误差值。从一步提前预测与观测值的相对偏差(即相对于观测值的大小)来表示缺乏拟合似乎是合理的。例如,当试图预测月度销售可能会逐月波动(例如,季节性地)时,如果我们的预测“达到目标”的准确度大约为±10%,我们可能会感到满意。换句话说,绝对误差可能与预测中的相对误差不太相关。为了评估相对误差,已经提出了各种指数(参见Makridakis,Wheelwright和McGee,1983)。第一个,百分比误差值,计算如下:
PE t = 100 *(X t -F t)/ X t
其中X t是时间t的观测值,F t是预测值(平滑值)。
平均百分比误差(MPE)。该值计算为PE值的平均值。
平均绝对百分比误差(MAPE)。与平均误差值(ME,见上文)的情况一样,0(零)附近的平均百分比误差可以通过相互抵消的大的正和负百分比误差产生。因此,相对总体拟合的更好度量是平均绝对百分比误差。此外,此度量通常比均方误差更有意义。例如,知道平均预测“偏离”±5%本身就是一个有用的结果,而30.8的均方误差不能立即解释。
自动搜索最佳参数。准牛顿函数最小化过程(与ARIMA中相同,用于最小化均方误差,平均绝对误差或平均绝对百分误差。在大多数情况下,此过程比网格搜索更有效(特别是当更多时)必须确定一个参数,并且可以快速识别最佳参数。
第一个平滑值S 0。到目前为止我们忽略的最后一个问题是初始值的问题,或者如何开始平滑过程。如果您回顾上面的公式,很明显您需要一个S 0值来计算系列中第一个观测值的平滑值(预测值)。取决于参数的选择(即,何时接近零),平滑过程的初始值会影响许多观测的预测质量。与指数平滑的大多数其他方面一样,建议选择产生最佳预测的初始值。另一方面,在实践中,当在关键的实际预测之前有许多主要观察结果时,初始值不会对该预测产生太大影响,因为其影响将长期从平滑系列中“淡化”(由于指数增长)减少权重,观察越老,它对预测的影响就越小。
5.5有或没有趋势的季节性和非季节性模型
以上在简单指数平滑的背景下的讨论引入了用于识别平滑参数以及用于评估模型的拟合优度的基本过程。除了简单的指数平滑之外,还开发了更复杂的模型来适应具有季节性和趋势分量的时间序列。这里的一般想法是,预测不仅根据连续的先前观察计算(如在简单指数平滑中),而且可以添加独立(平滑)趋势和季节性分量。Gardner(1985)根据季节性(无,加法或乘法)和趋势(无,线性,指数或阻尼)讨论了不同的模型。
添加和乘法季节性。许多时间序列数据遵循重复的季节性模式。例如,玩具的年销售量可能会在11月和12月的几个月达到峰值,也许在夏季(峰值小得多)儿童夏季休假时可能达到峰值。这种模式可能每年都会重复,但12月份销售额的相对增长量可能会逐年变化。因此,可能是有用的一个额外的参数独立地平滑季节性成分,通常表示为 (增量)。
(增量)。
季节性成分本质上可以是加成的或可以是乘法的。例如,在12月期间,特定玩具的销售额每年可能增加100万美元。因此,我们可以增加我们的预测为每年十二月为100万美元(在相应的年平均)来解释这种季节性波动。在这种情况下,季节性是附加的。
或者,在12月期间,特定玩具的销售额可能会增加40%,即增加1.4 倍。因此,当玩具的销售普遍疲软时,12月份的绝对(美元)销售增长将相对较弱(但百分比将保持不变); 如果玩具的销售强劲,那么销售的绝对(美元)增长将相应地增加。同样,在这种情况下,销售额增加一定的因素,而季节性因素本质上是乘法的(即,在这种情况下,乘法季节性成分将是1.4)。
在该系列的图中,这两种季节性成分之间的区别特征是,在附加情况下,无论系列的总体水平如何,该系列都表现出稳定的季节性波动; 在乘法情况下,季节性波动的大小会有所不同,具体取决于系列的总体水平。
季节性平滑参数。一般而言,一步提前预测计算为(对于没有趋势模型,对于线性和指数趋势模型,趋势分量被添加到模型中;见下文):
添加剂模型:
预测t = S t + I t-p
乘法模型:
预测t = S t * I t-p
在该公式中,S t代表在时间t的系列的(简单)指数平滑值,并且I t -p代表在时间t减去p(季节的长度)的平滑季节因子。因此,与简单指数平滑相比,通过将简单平滑值与预测季节性分量相加或相乘来“增强”预测。这个季节性成分的推导类似于简单指数平滑的S t值:
添加剂模型:
我t = I t-p +  *(1- )* e t
*(1- )* e t
乘法模型:
I t = I t -p + *(1- )* e t / S t
换句话说,时间t处的预测季节分量被计算为上一季节周期中的相应季节分量加上误差的一部分(e t ;观察到的减去时间t处的预测值)。考虑到上面的公式,很明显参数可以假设0到1之间的值。如果它是零,则预测特定时间点的季节性分量与前一个时间段的预测季节性分量相同。季节周期,反过来预计与前一周期相同,依此类推。因此,如果为零,则使用恒定不变的季节性分量来生成一步预测。如果参数等于1,然后在每个步骤通过相应的预测误差(时间(1- )“最大限度地”修改季节性分量,为了本简要介绍,我们将忽略该时间。在大多数情况下,当时间序列中存在季节性时,最佳参数将介于0(零)和1(一)之间。
线性,指数和阻尼趋势。 为了保持上述玩具示例,玩具的销售额可呈线性上升趋势(例如,每年销售额增加100万美元),呈指数增长(例如,每年,销售额增加1.3倍),或阻尼趋势(第一年销售额增加100万美元;第二年增长仅比上一年增加80%,即80万美元;明年再次减少80%,比上一年减少80%,即800,000美元* .8 = 640,000美元;等等)。每种类型的趋势都留下了明确的“签名”,通常可以在系列中识别出来; 下面在不同模型的简要讨论中显示的是说明一般模式的图标。一般而言,趋势因子可能会随着时间的推移而缓慢变化,同样,使用单独的参数平滑趋势分量可能是有意义的(表示 [ 伽马 ]的线性和指数趋势模型,以及
[ 伽马 ]的线性和指数趋势模型,以及 [ 披用于阻尼趋势模型])。
[ 披用于阻尼趋势模型])。
趋势平滑参数(线性和指数趋势)和(阻尼趋势)。类似于季节性分量,当趋势分量包括在指数平滑过程中时,每次计算独立趋势分量,并根据预测误差和相应参数进行修改。如果参数为0(零),则趋势分量在时间序列的所有值(以及所有预测)中保持不变。如果参数为1,则趋势分量通过相应的预测误差从观察到观察“最大”地修改。介于其间的参数值表示这两个极端的混合。参数 是一个趋势修改参数,它会影响趋势的变化有多大会影响后续预测趋势的估计,即趋势将被“抑制”或增加的速度。
6 经典季节性分解(人口普查方法1)
总体介绍
假设您在国际航班上记录了12年的每月载客量(见Box&Jenkins,1976)。如果您绘制这些数据,很明显(1)多年来乘客负荷似乎呈线性上升趋势,(2)每年内有一个反复出现的模式或季节性(即大多数旅行发生在夏季,在12月假期期间出现小高峰。季节性分解方法的目的是隔离这些组成部分,即将系列组合成趋势效应,季节效应和剩余可变性。旨在实现这种分解的“经典”技术被称为人口普查I方法。在Makridakis,Wheelwright和McGee(1983)以及Makridakis和Wheelwright(1989)中详细描述和讨论了该技术。
一般模型。季节性分解的一般概念很简单。通常,可以认为如上所述的时间序列由四个不同的分量组成:(1)季节性分量(表示为S t,其中t代表特定时间点)(2)趋势分量(T t),(3)循环分量(C t),和(4)随机,误差或不规则分量(I t))。周期性和季节性成分之间的差异在于后者以规则(季节性)间隔发生,而周期性因素通常具有较长的周期,周期不同。在人口普查I方法中,趋势和周期成分通常组合成趋势周期成分(TC t)。这些组件之间的特定功能关系可以采用不同的形式。然而,两个直接的可能性是它们以加法或乘法方式组合:
添加剂模型:
X t = TC t + S t + I t
乘法模型:
X t = T t * C t * S t * I t
这里X t代表在时间t的时间序列的观测值。鉴于一些关于影响系列的周期性因素(例如,商业周期)的先验知识,可以使用不同组件的估计来计算未来观测的预测。(但是,指数平滑方法,也可以包含季节性和趋势分量,是预测目的的首选技术。)
添加和乘法季节性。让我们考虑一个例子中的加性和乘法季节性成分之间的差异:玩具的年销售量可能在11月和12月的几个月达到峰值,也许在夏季(峰值小得多)儿童夏季休息时。这种季节性模式可能每年重复一次。季节性成分本质上可以是加成的或可乘的。例如,在12月份,特定玩具的销售额每年可能增加300万美元。因此,我们可以增加我们的预测为每年十二月的300万量,占这种季节性波动。在这种情况下,季节性是附加的。或者,在12月期间,特定玩具的销售额可能会增加40%,即增加1.4倍。因此,当玩具的销售普遍疲软时,12月份的销售绝对(美元)增长将相对较弱(但百分比将保持不变); 如果玩具的销售强劲,那么销售的绝对(美元)增长将成比例地增加。同样,在这种情况下,销售额增加一定的因素,因此季节性因素是乘法的在本质上(即,在这种情况下,乘法季节性成分将是1.4)。在系列图中,这两种季节性成分之间的区别特征是,在附加情况下,无论系列的总体水平如何,该系列都表现出稳定的季节性波动; 在乘法情况下,季节性波动的大小会有所不同,具体取决于系列的总体水平。
加法和乘法趋势周期。我们可以扩展前面的例子来说明加法和乘法趋势周期分量。就我们的玩具示例而言,这是一种“时尚” 趋势可能会导致销售额稳步增长(例如,一般趋向于更多教育玩具); 与季节性因素一样,这种趋势可能是附加的(销售额每年增加300万美元)或乘数(销售额增加30%,或每年增加1.3倍)。此外,周期性组件可能会影响销售; 重申一下,周期性成分与季节性成分的不同之处在于它通常具有较长的持续时间,并且它以不规则的间隔发生。例如,特定玩具在夏季期间可能特别“热”(例如,与主要儿童电影的发行相关联的特定玩偶,并且通过广泛的广告促销)。同样,这种循环组件可以以附加方式或乘法方式实现销售。
计算
的季节性分解(人口普查I)标准公式示于Makridakis,惠尔赖特,和麦基(1983),和Makridakis和车匠(1989)。

移动平均线。首先计算该系列的移动平均值,移动平均窗口宽度等于一个季节的长度。如果季节的长度是均匀的,那么用户可以选择使用相等的权重用于移动平均值,或者可以使用不等权重,其中移动平均窗口中的第一个和最后一个观察值被平均。
比率或差异。在移动平均值系列中,将消除所有季节性(季节内)变化; 因此,观察和平滑系列的差异(在加性模型中)或比率(在乘法模型中)将隔离季节性成分(加上不规则成分)。具体地,从观察到的系列中减去移动平均值(对于加法模型)或者将观察到的序列除以移动平均值(对于乘法模型)。
季节性成分。然后将季节性成分计算为季节中每个点的平均值(对于加性模型)或中间平均值(对于乘法模型)。

(一组值的中间平均值是排除最小值和最大值后的平均值)。结果值表示系列的(平均)季节性组件。
经季节性调整的系列。原始系列可以通过从中减去(加法模型)或除以(乘法模型)季节性成分来进行调整。

由此产生的系列是经过季节性调整的系列(即季节性成分将被删除)。
趋势周期组件。请记住,周期性成分与季节性成分的不同之处在于它通常比一个季节长,不同的周期可能有不同的长度。通过对季节性调整的系列应用权重为1,2,3,2,1的5点(居中)加权移动平均平滑变换,可以近似组合趋势和周期分量。
随机或不规则的组件。最后,可以通过从经季节性调整的系列(加法模型)中减去或将调整后的系列除以(乘法模型)趋势周期分量来分离随机或不规则(误差)分量。
注:本文翻译于网站http://www.statsoft.com/textbook/time-series-analysis
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/167102.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
