大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
数据结构与算法_Python_C完整教程目录:https://www.cnblogs.com/nickchen121/p/11407287.html
更新、更全的《数据结构与算法》的更新网站,更有python、go、人工智能教学等着你:https://www.cnblogs.com/nickchen121/p/11407287.html
一、集合的表示
集合运算:交、并、补、差,判定一个元素是否属于某一集合
在上述集合运算中,我们只关心两个集合运算,为并查集:集合并和查某元素属于什么集合。因此有一个问题——并查集问题中集合存储如何实现?
对于上述问题,我们可以用树结构表示集合,树的每个结点代表一个集合元素
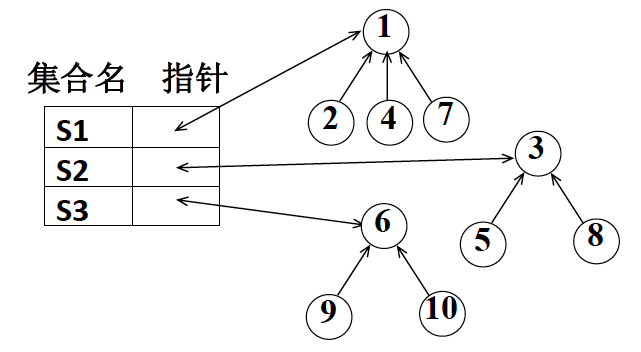
例如:有以下三个整数集合
- S1 = {1, 2, 4, 7}
- S2 = {3, 5, 8}
- S3 = {6, 9, 10}
对于上述三个集合,我们可以使用双亲表示法(孩子指向双亲)来构造下图所示树结构:

对于上述的树结构,我们可以考虑使用数组存储,存储形式如下图所示:
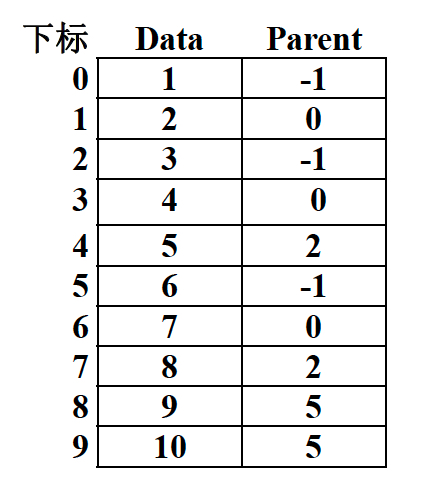
负数表示根结点;非负数表示双亲结点的下标。
对于数组中的每个元素,我们可以使用如下所示的代码描述:
/* c语言实现 */
typedef struct{
ElementType Data;
int Parent;
} SetType;
# python语言实现
class TreeNode:
def __init__(self, x):
self.data = None
self.parent = None
二、集合运算
2.1 集合的查运算
查找某个元素所在的集合(用根结点表示)
/* c语言实现 */
int Find(SetType S[], ElementType X)
{
// 在数组S中查找值为X的元素所属的集合
// MaxSize是全局变量,为数组S的最大长度
int i;
for (i = 0; i < MaxSize && S[i].Data != X; i++);
if (i >= MaxSize) return -1; // 未找到X,返回-1
for (; S[i].Parent >= 0; i = S[i].Parent);
return i; // 找到X所属集合,返回树根结点在数组S中的下标
}
2.2 集合的并运算
分别找到X1和X2两个元素所在集合树的根结点
如果它们不同根,则将其中一个根结点的父结点指针设置成另个一个根结点的数组下标
/* c语言实现 */
void Union(SetType S[], ElementType X1, ElementType X2)
{
int Root1, Root2;
Root1 = Find(S, X1);
Root2 = Find(S, X2);
if (Root1 != Root2) S[Root2].Parent = Root1; // 当X1和X2不属于同一个子集时,才需要合并
}
下图所示为集合 {1, 2, 4, 7} 和 集合 {3, 5, 8}的并运算:
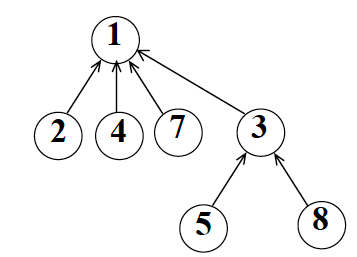
对于上述的两个小集合,随意选择一个根结点并无太大影响,但是对于如下图所示的两个集合,随意选择根结点则会增加未来并集的查找效率:
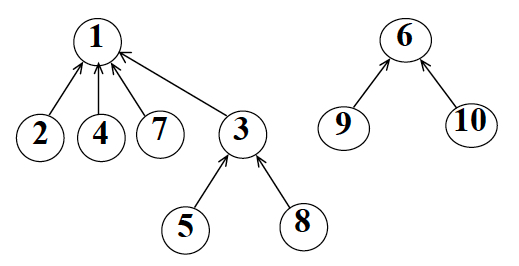
对于上图所示的两个集合,如果要增加未来两个集合并集的查找效率,应该尽量采用小的集合合并到相对大的集合中,但是我们如何判断哪一个集合元素更多呢?
为了更高效的判断那个集合元素更多,我们可以把根结点的-1改成-7或-3,用根结点的绝对值表示集合元素的个数,即数组更改为如下图所示:
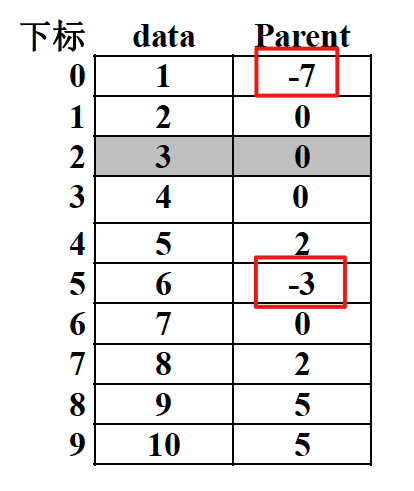
其中-7表示根结点数据为1的集合有7个元素;其中-3表示根结点数据为6的集合有3个元素。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/166941.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
