大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
编程过程中经常会遇到各类字符的编码方式,经常会混淆,在此总结下常用的编码方式以及其原理。
Ascii:
因为对于计算机来说只能识别0、1这两种字符(0表示低电平,1表示高电平),所有的数据都是通过二进制来表示,对于其他的比如说3、4、s、z、#等字符用二进制表示就需要一个约定的规范,这就是ascii的由来。
Ascii码表是用1个字节来表示128种字符(一个字节8位,可以组成256种字符,首位默认为0,所以ASCII最多就128个字符,当首位为1的时候我们后面再讨论),其中0-31和127表示控制字符,他们是不可见字符。
32-126是可见字符,48-57表示0-9,65-90为26个大写英文字母,97-122是26个小写英文字母。
GBK:
现在英文和数字都有了,但是我们中国汉字怎么表示呢?此时GBK应运而生,上面我们得知ASCII首位为0,假如把它改成1,就表示中文。GBK由2个字节来表示,第一个字节的最高位是0则表示字母和数字,假如是1则表示中文。
Unicode:
Unicode则是收录了世界上所有的语言, 但是在运用过程种会出现很多问题,比如一个3个字节的字符,如何区分他是1个unicode还是3个asicii,还有假如使用unicode,英文字母高位都会设置成0,这就造成了很大的浪费。因此UTF-8、UTF-16、UTF-32就出现来解决这些问题,主要讲当前互联网上常用的UTF-8
UTF-8:
UTF-8的规则很简单就两条:
1、 对于单字节的字符,最高位为0,其实跟ascii表示一致
2、 对于n个字节的字符,第一个字节的最高位为n个1,第n+1设为0,后面每个字节的前两位都为10,剩下的用字符对应的unicode来表示,如下图
Unicode符号范围 | UTF-8编码方式
(十六进制) | (二进制)
——————–+———————————————
0000 0000-0000 007F | 0xxxxxxx
0000 0080-0000 07FF | 110xxxxx 10xxxxxx
0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx
0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
BCD:
BCD编码主要用于数字0-9的压缩,因为0-9二进制表示为0000 0000到0000 1001,它们的前4位都是0,把他们合并就生成一个新的字符。
比如2个字符’1’,’9’,他们对应的Ascii为0x31和0x39,因此表示形式则为2个字节0x31 0x39
假如用BCD格式来表示则将其数字对应的二进制前4位去掉,然后合并,即将00000001和00001001前4位去掉得到0001 1001,得到新的1个字节0x19,这样看起来就跟十进制一样,这就是BCD压缩码的原理。
Base64编码:
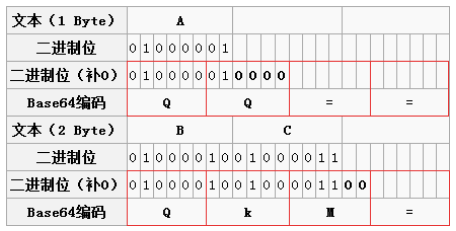
Base64编码的作用是将ascii里面的不可见字符变成可见字符来传输。Base64编码的最小使用单元是4个字节,每个字节使用6位,假如不足6的整数倍,则后面补0,剩下的字符补=,因为计算机存储字节是8位,所以计算字符值时在前面补2个0。
可能说的有些绕,看下一张图就了解了
(借用网上的一张图片 http://www.cnblogs.com/caoyc/p/5794720.html)
以A为例补位之后第一个字节为010000,前面补0得到00010000,对应10进制为16,对照字符表得到Q,第二个字节一样,也是Q,然后base64编码最小是4个字节,后面两个字节补=,最终得到QQ==

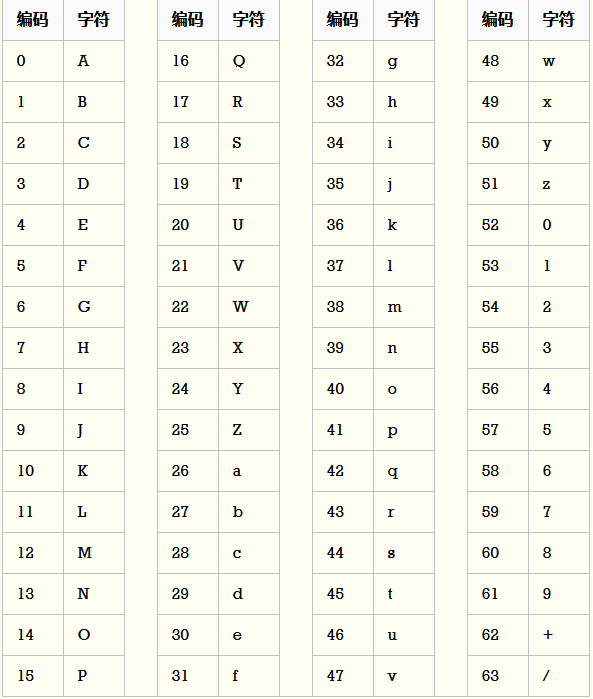
下面是一个Base64字符集,它包含大写字母、小写字母和数字,以及“+”和“/”符号。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/166851.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
