大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
前言
如果需要满足前端各种筛选条件查询,我们使用drf自带的会比较麻烦,比如查询书名中包含“国”字,日期大于“2020-1-1”等等诸如此类的请求,Django-filter这个组件就是要解决这样的问题。
1.安装
Django-filter支持的Python版本和Django版本、DRF版本如下:
- Python: 3.5, 3.6, 3.7, 3.8
- Django: 1.11, 2.0, 2.1, 2.2, 3.0
- DRF: 3.10+
在虚拟环境中安装
pip3 install django-filter
在Django的settings.py文件中安装并配置django_filters应用:
INSTALLED_APPS = [
...
'django_filters',
]
REST_FRAMEWORK = {
# 过滤器默认后端
'DEFAULT_FILTER_BACKENDS': (
'django_filters.rest_framework.DjangoFilterBackend',),
}
2.使用流程
我们通过一个简单的图书查询来说明如果在DRF中使用Django-filter过滤器。图书模型如下:
# models.py
class BookInfo(models.Model):
title = models.CharField(max_length=200,verbose_name='标题')
pub_date = models.DateField(blank=True, null=True,verbose_name='出版日期')
read = models.IntegerField(null=True,verbose_name='阅读数量')
comment = models.IntegerField(null=True,verbose_name='评论数量')
image = models.CharField(max_length=200, blank=True, null=True,verbose_name='图片')
class Meta:
db_table = 'bookInfo'
verbose_name = "图书"
序列化类:
# serializers.py
class BookSerializer(serializers.ModelSerializer):
class Meta:
model = BookInfo
fields = '__all__'
自定义过滤器类:
# filters.py
from django_filters import rest_framework as filters
from . models import BookInfo
class BookFilter(filters.FilterSet):
min_read = filters.NumberFilter(field_name="read", lookup_expr='gte')
max_read = filters.NumberFilter(field_name="read", lookup_expr='lte')
class Meta:
model = BookInfo
fields = ['read']
在视图中
# views.py
class BookView(ListAPIView):
queryset = BookInfo.objects.all()
serializer_class = BookSerializer
filter_class = BookFilter
url配置中
app_name = "api"
urlpatterns = [
path('books/', views.BookView.as_view()),
]
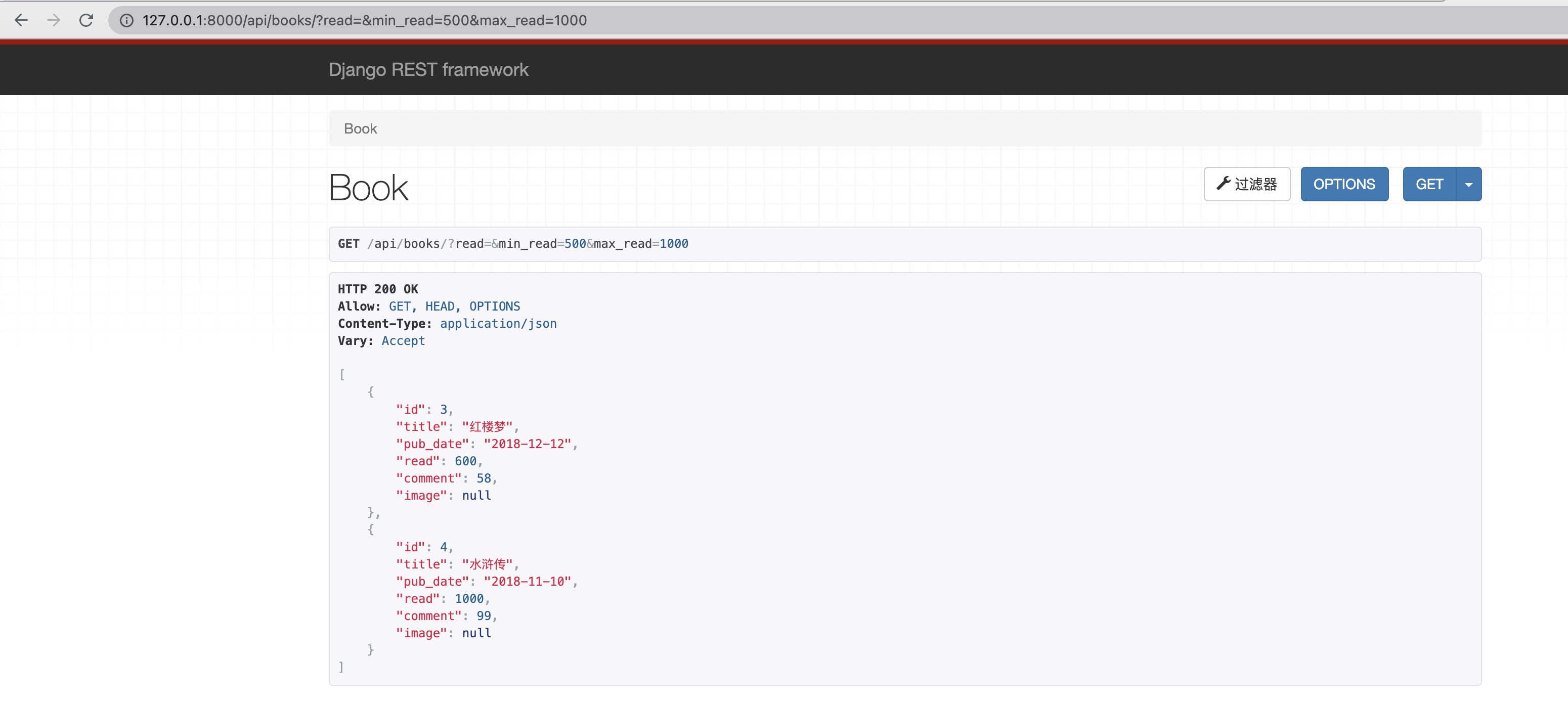
现在我们想筛选阅读数为500-1000的图书,测试结果如下

详解过滤器类
过滤器类和Django中表单类极其类似,写法基本一样,目的是指明过滤的时候使用哪些字段进行过滤,每个字段可以使用哪些运算。运算符的写法基本参照Django的ORM中查询的写法,比如:大于等于,小于等于用"gte","lte"等等
可以通过模型快速构建过滤器类
from django_filters import rest_framework as filters
class BookFilter(filters.FilterSet):
class Meta:
model = BookInfo # 模型名
fields = ['title','comment'] # 可以使用的过滤字段
Meta中出现的fields是指过滤条件中可以出现的字段,默认是精确判断相等,查询的时候可以这样用:
http://127.0.0.1:8000/api/books/?comment=20&title=
以上代表查询的是评论条数为20条的书本
如果不是判断相等,可以自定义过滤字段进行过滤:
- 过滤器中常用的字段类型,这些类型要输模型中对应字段类型兼容
CharFilter 字符串类型
BooleanFilter 布尔类型
DateTimeFilter 日期时间类型
DateFilter 日期类型
DateRangeFilter 日期范围
TimeFilter 时间类型
NumberFilter 数值类型,对应模型中IntegerField, FloatField, DecimalField
- 过滤字段参数说明:
field_name: 过滤字段名,一般应该对应模型中字段名
lookup_expr: 查询时所要进行的操作,和ORM中运算符一致
- Meta字段说明
model: 引用的模型,不是字符串
fields:指明过滤字段,可以是列表,列表中字典可以过滤,默认是判断相等;也可以字典,字典可以自定义操作
exclude = ['password'] 排除字段,不允许使用列表中字典进行过滤
自定义过滤字段:
class BookFilter(filters.FilterSet):
title = filters.CharFilter(field_name='title',lookup_expr='icontains') # 标题中包含
pub_year = filters.CharFilter(field_name='pub_date',lookup_expr='year') # 过滤年份相等
pub_year__gt = filters.CharFilter(field_name='pub_date',lookup_expr='year__gt') # 过滤大于年份
read__gt = filters.NumberFilter(field_name='read',lookup_expr="gt") # 最大阅读数
read__lt = filters.NumberFilter(field_name='read',lookup_expr="lt") # 最小阅读数
class Meta:
model = BookInfo
fields = ['title','read','comment']
自定义字段名可以和模型中不一致,但一定要用参数field_name指明对应模型中的字段名
日期查询
定义按年查询
pub_year = filters.CharFilter(field_name='pub_date',lookup_expr='year')
年份应该大于某值
pub_year__gt = filters.CharFilter(field_name='pub_date',lookup_expr='year__gt')
年份应该小于某值
read__lt = filters.NumberFilter(field_name='read',lookup_expr="lt")
查询出版年份大于2019年的书本
http://127.0.0.1:8000/api/books/?title=&read=&comment=&pub_year=&pub_year__gt=2019&read__gt=&read__lt=
查询结果:
[
{
"id": 1,
"title": "钢铁是怎样练成的",
"pub_date": "2020-10-09",
"read": 100,
"comment": 3,
"image": null
}
]
标题查询
title查询的时候可以进行包含查询,icontains在ORM中表示不区分大小的包含
title = filters.CharFilter(field_name='btitle',lookup_expr='icontains')
查询标题中包含三国演义的书籍
http://127.0.0.1:8000/api/books/?title=%E4%B8%89%E5%9B%BD%E6%BC%94%E4%B9%89&read=&comment=&pub_year=&pub_year__gt=&read__gt=&read__lt=
查询结果:
[
{
"id": 2,
"title": "三国演义",
"pub_date": "2019-11-12",
"read": 200,
"comment": 20,
"image": null
}
]
阅读数查询
阅读数大于
read__gt = filters.NumberFilter(field_name='read',lookup_expr="gt")
阅读数小于
read__lt = filters.NumberFilter(field_name='read',lookup_expr="lt")
查询阅读数在100-300之间的书籍
http://127.0.0.1:8000/api/books/?title=&read=&comment=&pub_year=&pub_year__gt=&read__gt=100&read__lt=300
查询结果:
[
{
"id": 2,
"title": "三国演义",
"pub_date": "2019-11-12",
"read": 200,
"comment": 20,
"image": null
}
]
官方文档:https://django-filter.readthedocs.io/en/stable/guide/install.html
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/165754.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
