大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
本文知识点较多,篇幅较长,请耐心学习
题记:
文章内容输出来源:拉勾教育Java高薪训练营。
本篇文章是 MySQL 学习课程中的一部分笔记。
MySQL集群架构
一、集群架构设计
1、架构设计理念
在集群架构设计时,主要遵从下面三个维度:
- 可用性
- 扩展性
- 一致性
2、可用性设计
- 站点高可用,冗余站点
- 服务高可用,冗余服务
- 数据高可用,冗余数据
保证高可用的方法是冗余。但是数据冗余带来的问题是数据一致性问题。
实现高可用的方案有以下几种架构模式:
- 主从模式
简单灵活,能满足多种需求。比较主流的用法,但是写操作高可用需要自行处理。 - 双主模式
互为主从,有双主双写、双主单写两种方式,建议使用双主单写
3、扩展性设计
扩展性主要围绕着读操作扩展和写操作扩展展开。
- 如何扩展以提高读性能
- 加从库
简单易操作,方案成熟。
从库过多会引发主库性能损耗。建议不要作为长期的扩充方案,应该设法用良好的设计避免持续加从库来缓解读性能问题。 - 分库分表
可以分为垂直拆分和水平拆分,垂直拆分可以缓解部分压力,水平拆分理论上可以无限扩展。
- 加从库
- 如何扩展以提高写性能
- 分库分表
4、一致性设计
一致性主要考虑集群中各数据库数据同步以及同步延迟问题。可以采用的方案如下:
- 不使用从库
扩展读性能问题需要单独考虑,否则容易出现系统瓶颈。 - 增加访问路由层
可以先得到主从同步最长时间t,在数据发生修改后的t时间内,先访问主库。
二、主从模式
1、适用场景
MySQL主从模式是指数据可以从一个MySQL数据库服务器主节点复制到一个或多个从节点。MySQL 默认采用异步复制方式,这样从节点不用一直访问主服务器来更新自己的数据,从节点可以复制主数据库中的所有数据库,或者特定的数据库,或者特定的表。
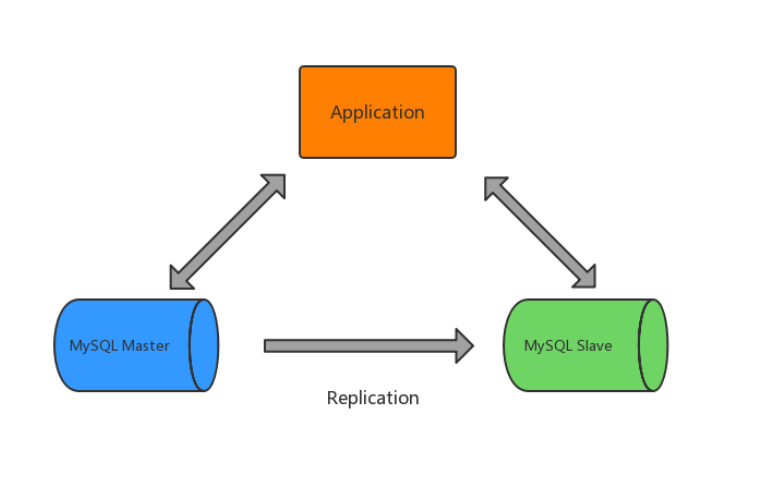

mysql主从复制用途:
- 实时灾备,用于故障切换(高可用)
- 读写分离,提供查询服务(读扩展)
- 数据备份,避免影响业务(高可用)
主从部署必要条件:
- 从库服务器能连通主库
- 主库开启binlog日志(设置log-bin参数)
- 主从server-id不同
2、实现原理
-
主从复制
下图是主从复制的原理图。
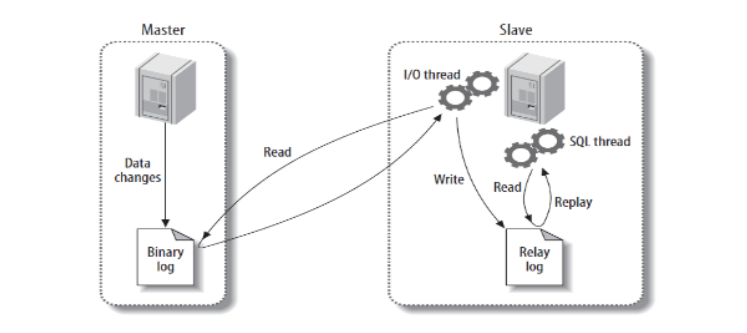
主从复制整体分为以下三个步骤:- 主库将数据库的变更操作记录到Binlog日志文件中
- 从库读取主库中的Binlog日志文件信息写入到从库的Relay Log中继日志中
- 从库读取中继日志信息在从库中进行Replay,更新从库数据信息
在上述三个过程中,涉及了Master的BinlogDump Thread和Slave的I/O Thread、SQL Thread,它们的作用如下:
- Master服务器对数据库更改操作记录在Binlog中,BinlogDump Thread接到写入请求后,读取Binlog信息推送给Slave的I/O Thread。
- Slave的I/O Thread将读取到的Binlog信息写入到本地Relay Log中。
- Slave的SQL Thread检测到Relay Log的变更请求,解析relay log中内容在从库上执行。
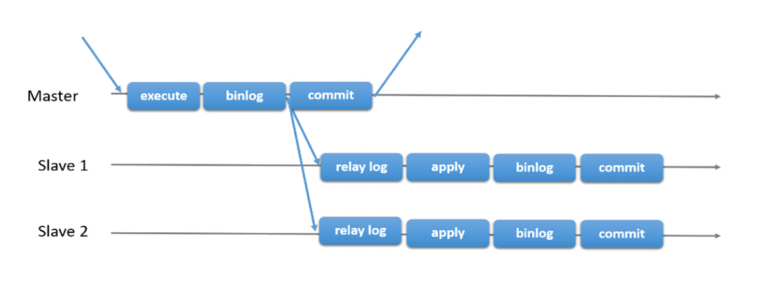
上述过程都是异步操作,俗称异步复制,存在数据延迟现象。
下图是异步复制的时序图。
mysql主从复制存在的问题:
- 主库宕机后,数据可能丢失
- 从库只有一个SQL Thread,主库写压力大,复制很可能延时
解决方法:
- 半同步复制—解决数据丢失的问题
- 并行复制—-解决从库复制延迟的问题
-
半同步复制
为了提升数据安全,MySQL让Master在某一个时间点等待Slave节点的 ACK(Acknowledgecharacter)消息,接收到ACK消息后才进行事务提交,这也是半同步复制的基础,MySQL从5.5版本开始引入了半同步复制机制来降低数据丢失的概率。
介绍半同步复制之前先快速过一下 MySQL 事务写入碰到主从复制时的完整过程,主库事务写入分为 4个步骤:- InnoDB Redo File Write (Prepare Write)
- Binlog File Flush & Sync to Binlog File
- InnoDB Redo File Commit(Commit Write)
- Send Binlog to Slave
当Master不需要关注Slave是否接受到Binlog Event时,即为传统的主从复制。
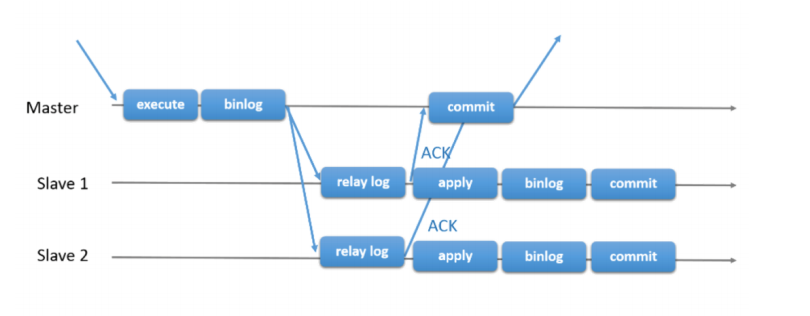
当Master需要在第三步等待Slave返回ACK时,即为 after-commit,半同步复制(MySQL 5.5引入)。
当Master需要在第二步等待 Slave 返回 ACK 时,即为 after-sync,增强半同步(MySQL 5.7引入)。
下图是 MySQL 官方对于半同步复制的时序图,主库等待从库写入 relay log 并返回 ACK 后才进行Engine Commit。
3、并行复制
MySQL的主从复制延迟一直是受开发者最为关注的问题之一,MySQL从5.6版本开始追加了并行复制功能,目的就是为了改善复制延迟问题,并行复制称为enhanced multi-threaded slave(简称MTS)。
在从库中有两个线程IO Thread和SQL Thread,都是单线程模式工作,因此有了延迟问题,我们可以采用多线程机制来加强,减少从库复制延迟。(IO Thread多线程意义不大,主要指的是SQL Thread多线程)
在MySQL的5.6、5.7、8.0版本上,都是基于上述SQL Thread多线程思想,不断优化,减少复制延迟。
-
MySQL 5.6并行复制原理
MySQL 5.6版本也支持所谓的并行复制,但是其并行只是基于库的。如果用户的MySQL数据库中是多个库,对于从库复制的速度的确可以有比较大的帮助。
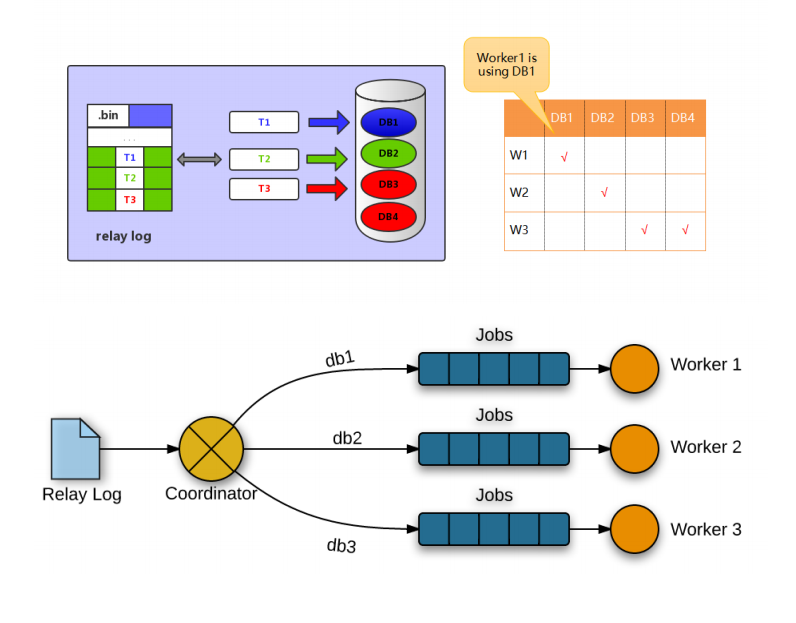
基于库的并行复制,实现相对简单,使用也相对简单些。基于库的并行复制遇到单库多表使用场景就发挥不出优势了,另外对事务并行处理的执行顺序也是个大问题。 -
MySQL 5.7并行复制原理
MySQL 5.7是基于组提交的并行复制,MySQL 5.7才可称为真正的并行复制,这其中最为主要的原因就是slave服务器的回放与master服务器是一致的,即master服务器上是怎么并行执行的slave上就怎样进行并行回放。不再有库的并行复制限制。
MySQL 5.7中组提交的并行复制究竟是如何实现的?
MySQL 5.7是通过对事务进行分组,当事务提交时,它们将在单个操作中写入到二进制日志中。如果多个事务能同时提交成功,那么它们意味着没有冲突,因此可以在Slave上并行执行,所以通过在主库上的二进制日志中添加组提交信息。
MySQL 5.7的并行复制基于一个前提,即所有已经处于prepare阶段的事务,都是可以并行提交的。这些当然也可以在从库中并行提交,因为处理这个阶段的事务都是没有冲突的。在一个组里提交的事务,一定不会修改同一行。这是一种新的并行复制思路,完全摆脱了原来一直致力于为了防止冲突而做的分发算法,等待策略等复杂的而又效率底下的工作。
InnoDB事务提交采用的是两阶段提交模式。一个阶段是prepare,另一个是commit。
为了兼容MySQL5.6基于库的并行复制,5.7引入了新的变量slave-parallel-type,其可以配置的值有:DATABASE(默认值,基于库的并行复制方式)、LOGICAL_CLOCK(基于组提交的并行复制方式)。
那么如何知道事务是否在同一组中,生成的Binlog内容如何告诉Slave哪些事务是可以并行复制的?
在MySQL 5.7版本中,其设计方式是将组提交的信息存放在GTID中。为了避免用户没有开启GTID功能(gtid_mode=OFF),MySQL 5.7又引入了称之为Anonymous_Gtid的二进制日志event类型ANONYMOUS_GTID_LOG_EVENT。
通过mysqlbinlog工具分析binlog日志,就可以发现组提交的内部信息。
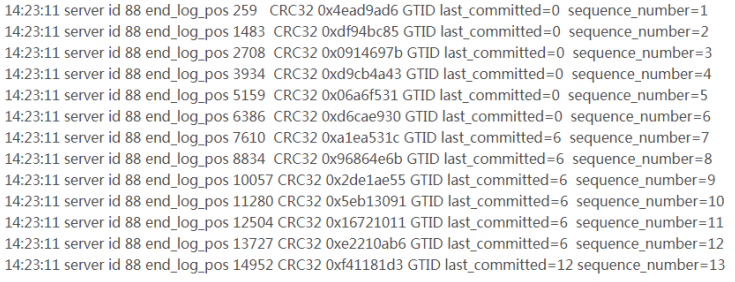
可以发现MySQL 5.7二进制日志较之原来的二进制日志内容多了last_committed和sequence_number,last_committed表示事务提交的时候,上次事务提交的编号,如果事务具有相同的last_committed,表示这些事务都在一组内,可以进行并行的回放。 -
MySQL8.0 并行复制
MySQL8.0 是基于write-set的并行复制。MySQL会有一个集合变量来存储事务修改的记录信息(主键哈希值),所有已经提交的事务所修改的主键值经过hash后都会与那个变量的集合进行对比,来判断改行是否与其冲突,并以此来确定依赖关系,没有冲突即可并行。这样的粒度,就到了 row级别了,此时并行的粒度更加精细,并行的速度会更快。 -
并行复制配置与调优
- binlog_transaction_dependency_history_size
用于控制集合变量的大小。 - binlog_transaction_depandency_tracking
用于控制binlog文件中事务之间的依赖关系,即last_committed值。- COMMIT_ORDERE: 基于组提交机制
- WRITESET: 基于写集合机制
- WRITESET_SESSION: 基于写集合,比writeset多了一个约束,同一个session中的事务last_committed按先后顺序递增
- transaction_write_set_extraction
用于控制事务的检测算法,参数值为:OFF、 XXHASH64、MURMUR32 - master_info_repository
开启MTS功能后,务必将参数master_info_repostitory设置为TABLE,这样性能可以有50%~80%的提升。这是因为并行复制开启后对于元master.info这个文件的更新将会大幅提升,资源的竞争也会变大。 - slave_parallel_workers
若将slave_parallel_workers设置为0,则MySQL 5.7退化为原单线程复制,但将slave_parallel_workers设置为1,则SQL线程功能转化为coordinator线程,但是只有1个worker线程进行回放,也是单线程复制。然而,这两种性能却又有一些的区别,因为多了一次coordinator线程的转发,因此slave_parallel_workers=1的性能反而比0还要差。 - slave_preserve_commit_order
MySQL 5.7后的MTS可以实现更小粒度的并行复制,但需要将slave_parallel_type设置为LOGICAL_CLOCK,但仅仅设置为LOGICAL_CLOCK也会存在问题,因为此时在slave上应用事务的顺序是无序的,和relay log中记录的事务顺序不一样,这样数据一致性是无法保证的,为了保证事务是按照relay log中记录的顺序来回放,就需要开启参数slave_preserve_commit_order。
- binlog_transaction_dependency_history_size
要开启enhanced multi-threaded slave其实很简单,只需根据如下设置:
slave-parallel-type=LOGICAL_CLOCK
slave-parallel-workers=16
slave_pending_jobs_size_max = 2147483648
slave_preserve_commit_order=1
master_info_repository=TABLE
relay_log_info_repository=TABLE
relay_log_recovery=ON
- 并行复制监控
在使用了MTS后,复制的监控依旧可以通过SHOW SLAVE STATUS\G,但是MySQL 5.7在performance_schema库中提供了很多元数据表,可以更详细的监控并行复制过程。
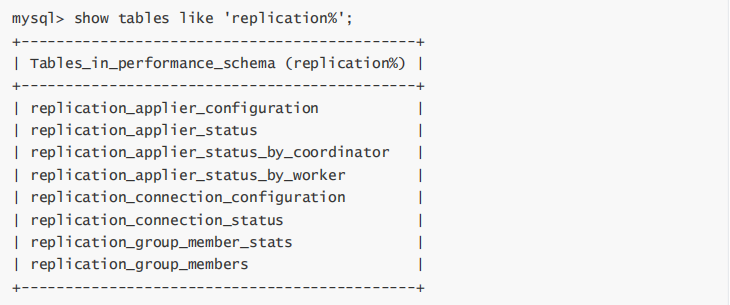
通过replication_applier_status_by_worker可以看到worker进程的工作情况:
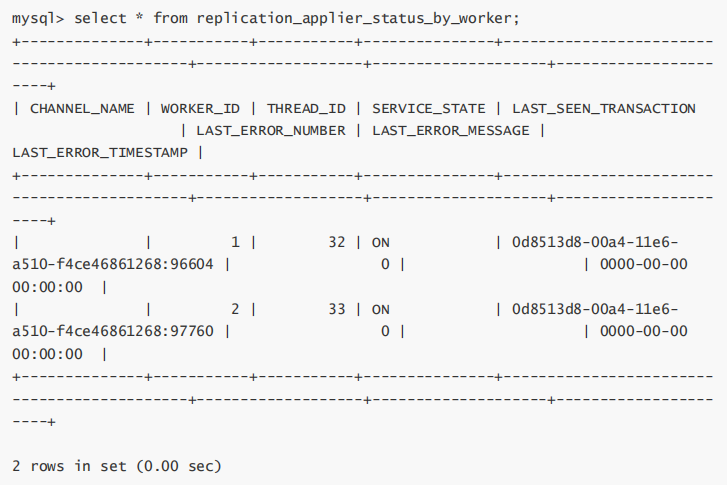
最后,如果MySQL 5.7要使用MTS功能,建议使用新版本,最少升级到5.7.19版本,修复了很多Bug。
4、读写分离
-
读写分离引入时机
大多数互联网业务中,往往读多写少,这时候数据库的读会首先成为数据库的瓶颈。如果我们已经优化了SQL,但是读依旧还是瓶颈时,这时就可以选择“读写分离”架构了。
读写分离首先需要将数据库分为主从库,一个主库用于写数据,多个从库完成读数据的操作,主从库之间通过主从复制机制进行数据的同步,如图所示。
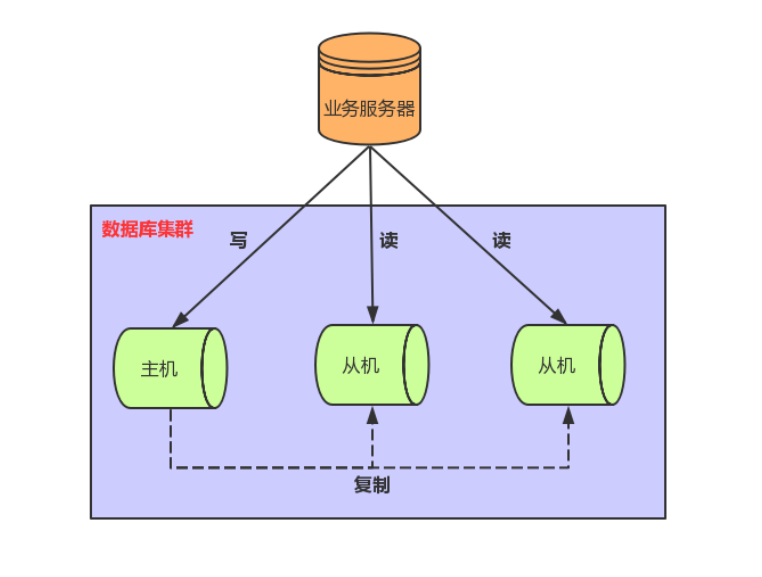
在应用中可以在从库追加多个索引来优化查询,主库这些索引可以不加,用于提升写效率。
读写分离架构也能够消除读写锁冲突从而提升数据库的读写性能。使用读写分离架构需要注意:主从同步延迟和读写分配机制问题 -
主从同步延迟
使用读写分离架构时,数据库主从同步具有延迟性,数据一致性会有影响,对于一些实时性要求比较高的操作,可以采用以下解决方案。- 写后立刻读
在写入数据库后,某个时间段内读操作就去主库,之后读操作访问从库。 - 二次查询
先去从库读取数据,找不到时就去主库进行数据读取。该操作容易将读压力返还给主库,为了避免恶意攻击,建议对数据库访问API操作进行封装,有利于安全和低耦合。 - 根据业务特殊处理
根据业务特点和重要程度进行调整,比如重要的,实时性要求高的业务数据读写可以放在主库。对于次要的业务,实时性要求不高可以进行读写分离,查询时去从库查询。
- 写后立刻读
-
读写分离落地
读写路由分配机制是实现读写分离架构最关键的一个环节,就是控制何时去主库写,何时去从库读。目前较为常见的实现方案分为以下两种:- 基于编程和配置实现(应用端)
程序员在代码中封装数据库的操作,代码中可以根据操作类型进行路由分配,增删改时操作主库,查询时操作从库。这类方法也是目前生产环境下应用最广泛的。优点是实现简单,因为程序在代码中实现,不需要增加额外的硬件开支,缺点是需要开发人员来实现,运维人员无从下手,如果其中一个数据库宕机了,就需要修改配置重启项目。 - 基于服务器端代理实现(服务器端)
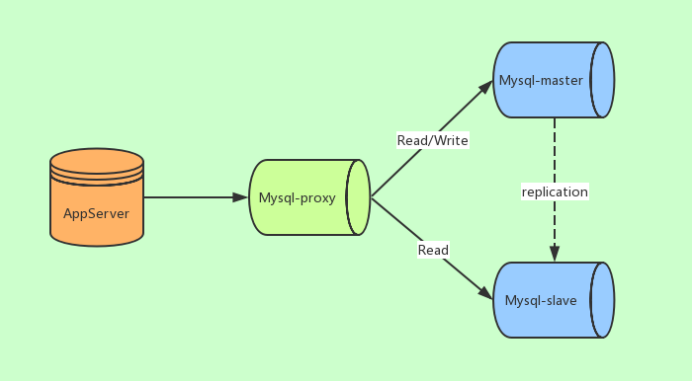
中间件代理一般介于应用服务器和数据库服务器之间,从图中可以看到,应用服务器并不直接进入到master数据库或者slave数据库,而是进入MySQL proxy代理服务器。代理服务器接收到应用服务器的请求后,先进行判断然后转发到后端master和slave数据库。
目前有很多性能不错的数据库中间件,常用的有MySQL Proxy、MyCat以及Shardingsphere等等。
- MySQL Proxy:是官方提供的MySQL中间件产品可以实现负载平衡、读写分离等。
- MyCat:MyCat是一款基于阿里开源产品Cobar而研发的,基于 Java 语言编写的开源数据库中间件。
- ShardingSphere:ShardingSphere是一套开源的分布式数据库中间件解决方案,它由ShardingJDBC、Sharding-Proxy和Sharding-Sidecar(计划中)这3款相互独立的产品组成。已经在2020年4月16日从Apache孵化器毕业,成为Apache顶级项目。
- Atlas:Atlas是由 Qihoo 360公司Web平台部基础架构团队开发维护的一个数据库中间件。
- Amoeba:变形虫,该开源框架于2008年开始发布一款 Amoeba for MySQL软件。
- 基于编程和配置实现(应用端)
三、双主模式
1、适用场景
很多企业刚开始都是使用MySQL主从模式,一主多从、读写分离等。但是单主如果发生单点故障,从库切换成主库还需要作改动。因此,如果是双主或者多主,就会增加MySQL入口,提升了主库的可用性。因此随着业务的发展,数据库架构可以由主从模式演变为双主模式。双主模式是指两台服务器互为主从,任何一台服务器数据变更,都会通过复制应用到另外一方的数据库中。
使用双主双写还是双主单写?
建议大家使用双主单写,因为双主双写存在以下问题:
- ID冲突
在A主库写入,当A数据未同步到B主库时,对B主库写入,如果采用自动递增容易发生ID主键的冲突。
可以采用MySQL自身的自动增长步长来解决,例如A的主键为1,3,5,7…,B的主键为2,4,6,8… ,但是对数据库运维、扩展都不友好。 - 更新丢失
同一条记录在两个主库中进行更新,会发生前面覆盖后面的更新丢失。
高可用架构如下图所示,其中一个Master提供线上服务,另一个Master作为备胎供高可用切换,Master下游挂载Slave承担读请求。
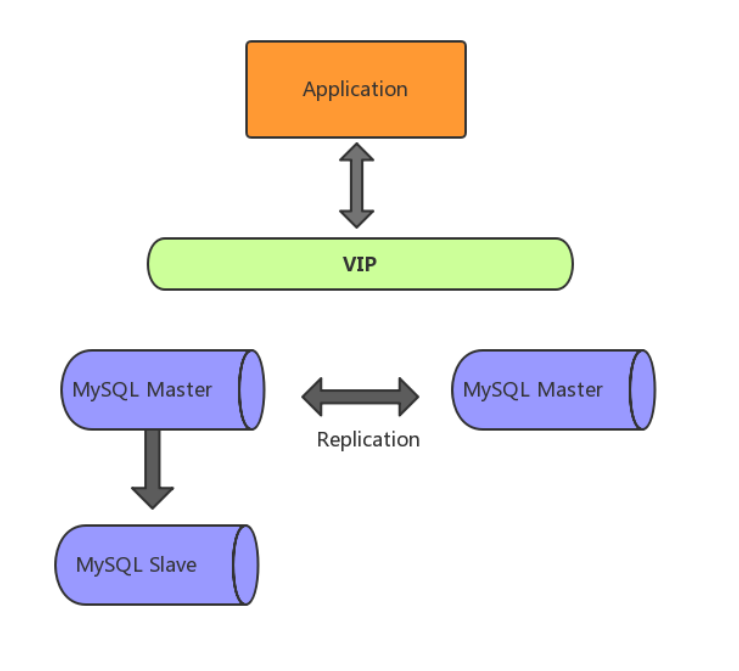
随着业务发展,架构会从主从模式演变为双主模式,建议用双主单写,再引入高可用组件,例如Keepalived和MMM等工具,实现主库故障自动切换。
2、MMM架构
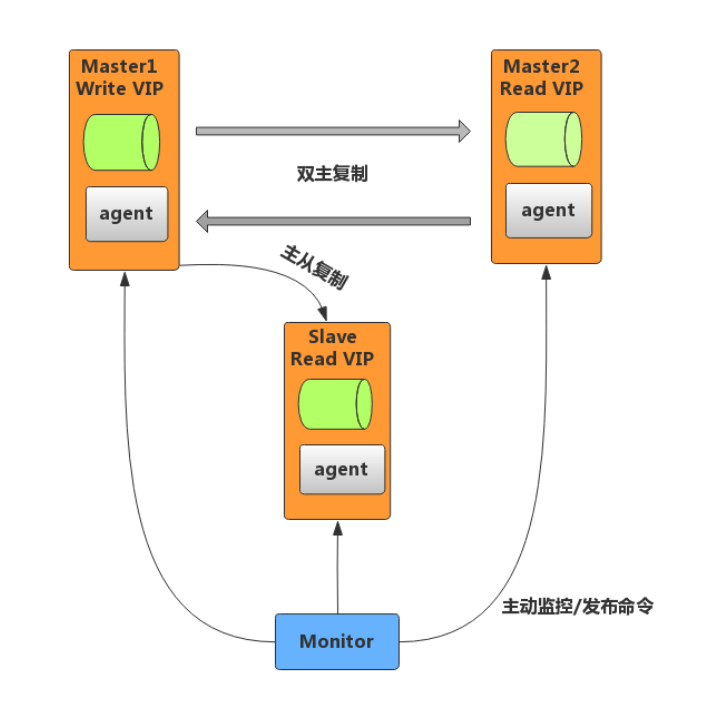
MMM(Master-Master Replication Manager for MySQL)是一套用来管理和监控双主复制,支持双主故障切换 的第三方软件。MMM 使用Perl语言开发,虽然是双主架构,但是业务上同一时间只允许一个节点进行写入操作。下图是基于MMM实现的双主高可用架构。
-
MMM故障处理机制
MMM 包含writer和reader两类角色,分别对应写节点和读节点。- 当 writer节点出现故障,程序会自动移除该节点上的VIP
- 写操作切换到 Master2,并将Master2设置为writer
- 将所有Slave节点会指向Master2
除了管理双主节点,MMM 也会管理 Slave 节点,在出现宕机、复制延迟或复制错误,MMM 会移除该节点的 VIP,直到节点恢复正常。
-
MMM监控机制
MMM 包含monitor和agent两类程序,功能如下:- monitor:监控集群内数据库的状态,在出现异常时发布切换命令,一般和数据库分开部署。
- agent:运行在每个 MySQL 服务器上的代理进程,monitor 命令的执行者,完成监控的探针工作和具体服务设置,例如设置 VIP(虚拟IP)、指向新同步节点。
3、MHA架构
MHA(Master High Availability)是一套比较成熟的 MySQL 高可用方案,也是一款优秀的故障切换和主从提升的高可用软件。在MySQL故障切换过程中,MHA能做到在30秒之内自动完成数据库的故障切换操作,并且在进行故障切换的过程中,MHA能在最大程度上保证数据的一致性,以达到真正意义上的高可用。MHA还支持在线快速将Master切换到其他主机,通常只需0.5-2秒。
目前MHA主要支持一主多从的架构,要搭建MHA,要求一个复制集群中必须最少有三台数据库服务器。
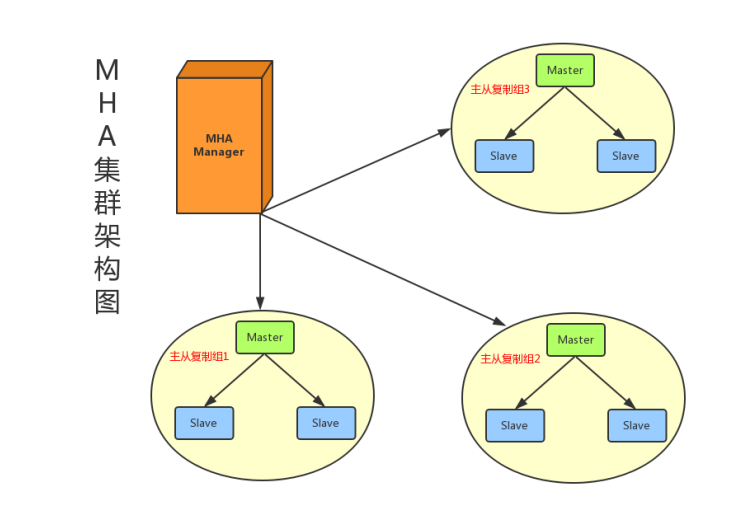
MHA由两部分组成:MHA Manager(管理节点)和MHA Node(数据节点)。
- MHA Manager可以单独部署在一台独立的机器上管理多个master-slave集群,也可以部署在一台slave节点上。负责检测master是否宕机、控制故障转移、检查MySQL复制状况等。
- MHA Node运行在每台MySQL服务器上,不管是Master角色,还是Slave角色,都称为Node,是被监控管理的对象节点,负责保存和复制master的二进制日志、识别差异的中继日志事件并将其差异的事件应用于其他的slave、清除中继日志。
MHA Manager会定时探测集群中的master节点,当master出现故障时,它可以自动将最新数据的slave提升为新的master,然后将所有其他的slave重新指向新的master,整个故障转移过程对应用程序完全透明。
MHA故障处理机制:
- 把宕机master的binlog保存下来
- 根据binlog位置点找到最新的slave
- 用最新slave的relay log修复其它slave
- 将保存下来的binlog在最新的slave上恢复
- 将最新的slave提升为master
- 将其它slave重新指向新提升的master,并开启主从复制
MHA优点:
- 自动故障转移快
- 主库崩溃不存在数据一致性问题
- 性能优秀,支持半同步复制和异步复制
- 一个Manager监控节点可以监控多个集群
4、主备切换
主备切换是指将备库变为主库,主库变为备库,有可靠性优先和可用性优先两种策略。
-
主备延迟问题
主备延迟是由主从数据同步延迟导致的,与数据同步有关的时间点主要包括以下三个:- 主库 A 执行完成一个事务,写入 binlog,我们把这个时刻记为 T1;
- 之后将binlog传给备库 B,我们把备库 B 接收完 binlog 的时刻记为 T2;
- 备库 B 执行完成这个binlog复制,我们把这个时刻记为 T3。
所谓主备延迟,就是同一个事务,在备库执行完成的时间和主库执行完成的时间之间的差值,也就是 T3-T1。
在备库上执行show slave status命令,它可以返回结果信息,seconds_behind_master表示当前备库延迟了多少秒。
同步延迟主要原因如下:- 备库机器性能问题
机器性能差,甚至一台机器充当多个主库的备库。 - 分工问题
备库提供了读操作,或者执行一些后台分析处理的操作,消耗大量的CPU资源。 - 大事务操作
大事务耗费的时间比较长,导致主备复制时间长。比如一些大量数据的delete或大表DDL操作都可能会引发大事务。
-
可靠性优先
主备切换过程一般由专门的HA高可用组件完成,但是切换过程中会存在短时间不可用,因为在切换过程中某一时刻主库A和从库B都处于只读状态。如下图所示:
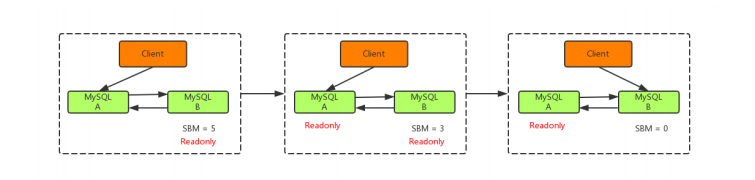
主库由A切换到B,切换的具体流程如下:- 判断从库B的Seconds_Behind_Master值,当小于某个值才继续下一步
- 把主库A改为只读状态(readonly=true)
- 等待从库B的Seconds_Behind_Master值降为 0
- 把从库B改为可读写状态(readonly=false)
- 把业务请求切换至从库B
-
可用性优先
不等主从同步完成, 直接把业务请求切换至从库B ,并且让 从库B可读写 ,这样几乎不存在不可用时间,但可能会数据不一致。
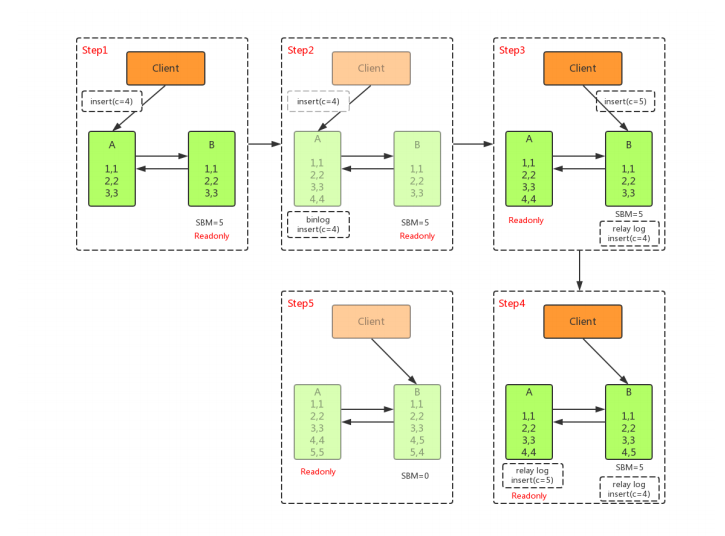
如上图所示,在A切换到B过程中,执行两个INSERT操作,过程如下:- 主库A执行完 INSERT c=4 ,得到 (4,4) ,然后开始执行 主从切换
- 主从之间有5S的同步延迟,从库B会先执行 INSERT c=5 ,得到 (4,5)
- 从库B执行主库A传过来的binlog日志 INSERT c=4 ,得到 (5,4)
- 主库A执行从库B传过来的binlog日志 INSERT c=5 ,得到 (5,5)
- 此时主库A和从库B会有 两行 不一致的数据
通过上面介绍了解到,主备切换采用可用性优先策略,由于可能会导致数据不一致,所以大多数情况下,优先选择可靠性优先策略。在满足数据可靠性的前提下,MySQL的可用性依赖于同步延时的大小,同步延时越小,可用性就越高。
小总结
综上所述,在我们项目初期数据量小的时候,MySQL可以简单搭建一个主从模式,当随着业务量增长,再逐渐改进为MMM架构、MHA架构等。
最后
在这个知识付费的时代,每一位热爱技术分享、奋笔直书的人,都值得我们尊敬!所以,请不要吝啬您手中的鼠标,按下左键,为小编点个赞吧。
更多内容,请关注微信公众号:架构视角
特别鸣谢
感谢启源老师风趣幽默的讲解,让我对所学知识点记忆深刻!
感谢木槿导师的认真和负责,每一次作业点评都是我前进的动力!
感谢班主任毕老师的负责和耐心,每次不厌其烦的上课通知都是我不忘初心,保持良好学习状态的精神支柱!
感谢拉勾教育平台,给我这次花少量的钱就能报名第一期拉钩训练营,就能学习到很多深层次的技术精华的机会。而且,在学习过程中还认识了很多技术大佬,可以请教他们一些问题,比如张大佬、卢大佬、雨生大佬等等。。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/164629.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
