大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
什么是记忆化搜索呢?搜索的低效在于没有能够很好地处理重叠子问题;动态规划虽然比较好地处理了重叠子问题,但是在有些拓扑关系比较复杂的题目面前,又显得无奈。记忆化搜索正是在这样的情况下产生的,它采用搜索的形式和动态规划中递推的思想将这两种方法有机地综合在一起,扬长避短,简单实用,在信息学中有着重要的作用。
用一个公式简单地说:记忆化搜索=搜索的形式+动态规划的思想。
动态规划:就是一个最优化问题,先将问题分解为子问题,并且对于这些分解的子问题自身就是最优的才能在这个基础上得出我们要解决的问题的最优方案,要不然的话就能找到一个更优的解来替代这个解,得出新的最优自问题,这当然是和前提是矛盾的。动态规划不同于 贪心算法,因为贪心算法是从局部最优来解决问题,而动态规划是全局最优的。用动态规划的时候不可能在子问题还没有得到最优解的情况下就做出决策,而是必须等待子问题得到了最优解之后才对当下的情况做出决策,所以往往动态规划都可以用 一个或多个递归式来描述。而贪心算法却是先做出一个决策,然后在去解决子问题。这就是贪心和动态规划的不同。
一般遇到一个动态规划类型的问题,都先要确定最优子结构,还有重叠子问题,这两个是动态规划最大的特征,然后就是要写 动态规划的状态方程,这个步骤十分十分的重要的,写动归方程是需要一定的经验的,这可以通过训练来达到目的。接着就是要自底向上的求解问题的,先将最小规模的子问题的最优解求出,一般都用一张表来记录下求得的解,到后来遇到同样的子问题的时候就可以直接查表得到答案,最后就是通过一步一步的迭代得出最后问题的答案了。
我的理解最重要的东西就是一定会要一个数组或者其他的存储结构存储得到的子问题的解。这样就可以省很多时间,也就是典型的空间换时间
动态规划的一种变形就是记忆化搜索,就是根据动归方程写出递归式,然后在函数的开头直接返回以前计算过的结果,当然这样做也需要一个存储结构记下前面计算过的结果,所以又称为记忆化搜索。
记忆化搜索递归式动态规划
1.记忆化搜索的思想
记忆化搜索的思想是,在搜索过程中,会有很多重复计算,如果我们能记录一些状态的答案,就可以减少重复搜索量
2、记忆化搜索的适用范围
根据记忆化搜索的思想,它是解决重复计算,而不是重复生成,也就是说,这些搜索必须是在搜索扩展路径的过程中分步计算的题目,也就是“搜索答案与路径相关”的题目,而不能是搜索一个路径之后才能进行计算的题目,必须要分步计算,并且搜索过程中,一个搜索结果必须可以建立在同类型问题的结果上,也就是类似于动态规划解决的那种。
也就是说,他的问题表达,不是单纯生成一个走步方案,而是生成一个走步方案的代价等,而且每走一步,在搜索树/图中生成一个新状态,都可以精确计算出到此为止的费用,也就是,可以分步计算,这样才可以套用已经得到的答案
3、记忆化搜索的核心实现
a. 首先,要通过一个表记录已经存储下的搜索结果,一般用哈希表实现
b.状态表示,由于是要用哈希表实现,所以状态最好可以用数字表示,常用的方法是把一个状态连写成一个p进制数字,然后把这个数字对应的十进制数字作为状态
c.在每一状态搜索的开始,高效的使用哈希表搜索这个状态是否出现过,如果已经做过,直接调用答案,回溯
d.如果没有,则按正常方法搜索
4、记忆化搜索是类似于动态规划的,不同的是,它是倒做的“递归式动态规划”。
【Poj1579】Function Run Fun
【在线测试提交传送门】
【问题描述】
自定义函数w(a,b,c)。 如果 a ≤ 0 或b ≤ 0 或 c ≤ 0, 则返回结果: 1; 如果 a > 20 或 b > 20 或 c > 20, 则返回结果: w(20, 20, 20); 如果 a < b 且 b < c, 则返回结果: w(a, b, c-1) + w(a, b-1, c-1) - w(a, b-1, c) 否则返回结果: w(a-1, b, c) + w(a-1, b-1, c) + w(a-1, b, c-1) - w(a-1, b-1, c-1)
【输入格式】
输入包含若干个测试数据,每个测试数据一行,分别表示a,b和c的值。 输入以-1 -1 -1表示结束。
【输出格式】
若干行,每行依次输出一个测试数据对应的函数的返回结果。
【输入样例1】
1 1 1 2 2 2 10 4 6 50 50 50 -1 7 18 -1 -1 -1
【输出样例1】
2 4 523 1048576 1
//参考代码:
#include <bits/stdc++.h>
using namespace std;
int dp[25][25][25];
int dfs(int a,int b,int c)
{
if(a<=0 || b<=0 || c<=0)
return 1;
if(a>20 || b>20 || c>20)
return dfs(20,20,20);
if(dp[a][b][c]) //避免重复计算
return dp[a][b][c];
if(a<b && b<c)
dp[a][b][c] = dfs(a,b,c-1)+dfs(a,b-1,c-1)-dfs(a,b-1,c);
else
dp[a][b][c] = dfs(a-1,b,c)+dfs(a-1,b-1,c)+dfs(a-1,b,c-1)-dfs(a-1,b-1,c-1);
return dp[a][b][c];
}
int main()
{
int a,b,c;
memset(dp,0,sizeof(dp));
while(~scanf("%d%d%d",&a,&b,&c))
{
if(a == -1 && b == -1 && c == -1)
break;
printf("%d\n",dfs(a,b,c));
}
return 0;
}【Tyvj1004】滑雪
【在线测试提交传送门】
【问题描述】
trs喜欢滑雪。他来到了一个滑雪场,这个滑雪场是一个矩形,为了简便,我们用r行c列的矩阵来表示每块地形。为了得到更快的速度,滑行的路线必须向下倾斜(即高度递减)。
例如样例中的那个矩形,可以从某个点滑向上下左右四个相邻的点之一。例如24-17-16-1,其实25-24-23…3-2-1更长,事实上这是最长的一条。
【输入格式】
第1行: 两个数字r,c(1≤r,c≤100),表示矩阵的行列。 第2..r+1行:每行c个数,表示这个矩阵。
【输出格式】
仅一行: 输出1个整数,表示可以滑行的最大长度。
【输入样例】
5 5 1 2 3 4 5 16 17 18 19 6 15 24 25 20 7 14 23 22 21 8 13 12 11 10 9
【输出样例】
25
#include<cstdio>
#include<cstring>
#include<algorithm>
using namespace std;
const int dx[4] = {
1,0,-1,0};
const int dy[4] = {
0,1,0,-1};
const int maxrc = 100 + 5;
int r,c;
int m[maxrc][maxrc];
int f[maxrc][maxrc];
//设f[i][j]为到达[i,j]时最优值
//f[i][j] = max{f[i+a][i+b] | a和b是4个坐标增量,m[i][j]<m[i+a][i+b]}
int dfs (int x, int y)
{
if (f[x][y]!=0) return f[x][y];//已经计算过
int maxt = 1;
int t;
for (int i=0;i<4;i++)
{
int tx = x + dx[i], ty = y + dy[i];
if (tx>0&&ty>0&&tx<=r&&ty<=c&&m[tx][ty]>m[x][y])
{
t = dfs(tx,ty)+1;
maxt = max(t, maxt);
}
}
f[x][y] = maxt;//记忆化
return maxt;
}
int main ()
{
scanf("%d%d", &r, &c);
for (int i=1;i<=r;i++)
for (int j=1;j<=c;j++)
scanf("%d", &m[i][j]);
memset(f, 0, sizeof(f));
int ans = 0;
for (int i=1;i<=r;i++)
for (int j=1;j<=c;j++)
{
f[i][j] = dfs(i,j);
ans = max(ans, f[i][j]);
}
printf("%d\n", ans);
return 0;
}【Hdu1501】Zippe
【在线测试提交传送门】
【问题描述】
给定三个字符串,判断第三个字符串能否由前两个字符串构成。前两个字符串可以任意组成,但单个字符串内的字符的相对顺序不能改变。 例如前两个字符串为:cat,tree。 字符串tcraete和catrtee都可以有这两个字符串构成,但字符串cttaree不能。
【输入格式】
第一行,一个整数n(1≤n≤1000),表示测试数据的个数,对于每个测试数据: 占一行,由三个用空格隔开的字符串,每个字符串由小写字母构成。前两个字符串的长度均不超过200,第三个字符串的长度为前两个字符串的长度和。
【输出格式】
对于每个测试数据输出一行,一个字符串,“yes”表示可以构成,"no"表示不可以。
【输入样例1】
3 cat tree tcraete cat tree catrtee cat tree cttaree
【输出样例1】
yes yes no
//记忆化搜索
#include<bits/stdc++.h>
using namespace std;
string str1, str2, str;
bool pos;
int vis[205][205];
void dfs(int s1, int s2, int s)
{
if(s1 == str1.length() && s2 == str2.length())
{
pos = true;
return;
}
if(str1[s1] != str[s] && str2[s2] != str[s]) return;
if(vis[s1][s2]) return;
vis[s1][s2] = 1;
if(str1[s1] == str[s]) dfs(s1 + 1, s2, s + 1);
if(str2[s2] == str[s]) dfs(s1, s2 + 1, s + 1);
}
int main()
{
int t, n;
scanf("%d", &t);
while(t --)
{
cin >> str1 >> str2 >> str;
pos = false;
memset(vis, 0, sizeof(vis));
dfs(0, 0, 0);
if(pos) printf("yes\n");
else printf("no\n");
}
return 0;
}
//动态规划
#include<bits/stdc++.h>
using namespace std;
const int N = 205;
const int INF = 1e8;
char str1[N], str2[N], str[N * 2];
int dp[N][N];
int main()
{
int t, n;
scanf("%d", &t);
while(t --)
{
scanf("%s%s%s", str1 + 1, str2 + 1, str + 1);
str[0] = str1[0] = str2[0] = '0';
for(int i = 1; i < strlen(str1); i ++)
{
if(str1[i] == str[i]) dp[i][0] = 1;
else break;
}
for(int i = 1; i < strlen(str2); i ++)
{
if(str2[i] == str[i]) dp[0][i] = 1;
else break;
}
for(int i = 1; i < strlen(str1); i ++)
{
for(int j = 1; j < strlen(str2); j ++)
{
dp[i][j] = ((dp[i - 1][j] && str1[i] == str[i + j]) || (dp[i][j - 1] && str2[j] == str[i + j]));
}
}
if(dp[strlen(str1) - 1][strlen(str2) - 1]) printf("yes\n");
else printf("no\n");
}
return 0;
}
【UVA10118】Free Candies
【在线测试提交传送门】
【问题描述】
有4根竖直的管子,每个管子里有n颗糖果叠成一堆,有一个篮子,最多可以放5颗糖果。每次可以取走任意一个管子的最上方的一颗糖果放到篮子里,若篮子里有两颗糖的颜色相同,可以将这一对糖果放进口袋。求最多可以放多少对糖果到口袋里。
【输入格式】
输入有若干组(不超过10组)测试数据,对于每组测试数据: 第一行一个整数n(1≤n≤40),表示每根管子有多少糖果,接下来n行,每行4个整数,第i行第j列表示第j根管子的第i颗糖果的颜色。糖果的颜色不超过20种,分别编号为1到n。 输入最后一行,用一个0表示结束。
【输出格式】
输出共若干行,对每组测试数据依次输出答案,各占一行。
【输入样例1】
5 1 2 3 4 1 5 6 7 2 3 3 3 4 9 8 6 8 7 2 1 1 1 2 3 4 3 1 2 3 4 5 6 7 8 1 2 3 4 0
【输出样例1】
8 0 3
#include <bits/stdc++.h>
using namespace std;
const int MAXN = 42;
int dp[MAXN][MAXN][MAXN][MAXN]; //当每堆剩下多少时口袋的数量
int n,arr[5],a[5][MAXN];
int dfs(int basket,int candy){
if (dp[arr[1]][arr[2]][arr[3]][arr[4]] != -1)
return dp[arr[1]][arr[2]][arr[3]][arr[4]];
else {
int sum,t;
int ans = 0;
for (int i = 1; i <= 4; i++){
sum = 0;
++arr[i];
if (arr[i] <= n){
if ((t = 1<<a[i][arr[i]]) & basket) //判断是否在篮子里
sum = dfs((~t)&basket,candy-1) + 1;
else if (candy < 4)
sum = dfs(t|basket,candy+1); //将这颗糖加进篮子
}
--arr[i]; //回溯
ans = max(ans,sum);
}
return dp[arr[1]][arr[2]][arr[3]][arr[4]] = ans;
}
}
int main(){
while (scanf("%d",&n) != EOF && n){
for (int i = 1; i <= n; i++)
for (int j = 1; j <= 4; j++)
scanf("%d",&a[j][i]);
memset(dp,-1,sizeof(dp));
memset(arr,0,sizeof(arr));
printf("%d\n",dfs(0,0));
}
return 0;
}
[Hdu1428] 漫步校园
【在线测试提交传送门】
【问题描述】
LL最近沉迷于AC不能自拔,每天寝室、机房两点一线。由于长时间坐在电脑边,缺乏运动。他决定充分利用每次从寝室到机房的时间,在校园里散散步。整个HDU校园呈方形布局,可划分为n*n个小方格,代表各个区域。例如LL居住的18号宿舍位于校园的西北角,即方格(1,1)代表的地方,而机房所在的第三实验楼处于东南端的(n,n)。因有多条路线可以选择,LL希望每次的散步路线都不一样。另外,他考虑从A区域到B区域仅当存在一条从B到机房的路线比任何一条从A到机房的路线更近(否则可能永远都到不了机房了…)。 现在他想知道的是,所有满足要求的路线一共有多少条。
【输入格式】
第一行一个整数n(2≤n≤50); 接下来n行每行有n个数,代表经过每个区域所花的时间t(0<t≤50)(由于寝室与机房均在三楼,故起点与终点也得费时)。
【输出格式】
针对每组测试数据,输出总的路线数(小于2^63)。
【输入样例】
3 1 2 3 1 2 3 1 2 3 3 1 1 1 1 1 1 1 1 1
【输出样例】
1 6
【解题思路】
“他考虑从A区域到B区域仅当存在一条从B到机房的路线比任何一条从A到机房的路线更近(否则可能永远都到不了机房了…”这句话一定要理解清楚。就是说,对于当前位置,如果下一个状态与终点的最短距离大于或者等于当前位置到终点的最短距离,那么这个下一个状态是不可取的!到此,就能明白,此题就是求出所有点与终点的最短距离,然后再从起点进行记忆化搜索。
#include<iostream>
#include<queue>
#include<cstdio>
#include<cstring>
using namespace std;
const int N=60;
const int INF=99999999;
int map[N][N];
int dir[4][2]={
{
1,0},{
0,1},{-1,0},{
0,-1}};
struct node{
int x,y;
};
int n;
int dis[N][N],visited[N][N];
long long res[N][N];
void BFS(){ //BFS求最短路
queue<node> myqueue;
while(!myqueue.empty())
myqueue.pop();
int i,j,k;
for(i=0;i<N;i++)
for(j=0;j<N;j++)
dis[i][j]=INF;
memset(visited,0,sizeof(visited));
dis[n][n]=map[n][n];
node cur,next;
cur.x=n;cur.y=n;
myqueue.push(cur);
visited[cur.x][cur.y]=1;
int x,y;
while(!myqueue.empty()){
cur=myqueue.front();
myqueue.pop();
visited[cur.x][cur.y]=0;
for(k=0;k<4;k++){
next.x=x=cur.x+dir[k][0];
next.y=y=cur.y+dir[k][1];
if(x>=1 && x<=n && y>=1 && y<=n && dis[x][y]>dis[cur.x][cur.y]+map[x][y]){
dis[x][y]=dis[cur.x][cur.y]+map[x][y];
if(!visited[x][y]){
visited[x][y]=1;
myqueue.push(next);
}
}
}
}
}
long long DFS(int x,int y){ //DFS求路径数量,使用记忆搜索优化。
if(x==n && y==n)
return 1;
if(res[x][y]!=-1)
return res[x][y];
res[x][y]=0;
int si,sj,k;
for(k=0;k<4;k++){
si=x+dir[k][0];
sj=y+dir[k][1];
if(si>=1 && si<=n && sj>=1 && sj<=n && dis[si][sj]<dis[x][y])
res[x][y]+=DFS(si,sj);
}
return res[x][y];
}
int main(){
scanf("%d",&n);
for(int i=1;i<=n;i++)
for(int j=1;j<=n;j++)
scanf("%d",&map[i][j]);
BFS();
memset(res,-1,sizeof(res));
printf("%lld\n",DFS(1,1));
return 0;
}[Nkoj3699] 送披萨
【在线测试提交传送门】
【问题描述】
何老板开了一家披萨店,有一天突然收到了n个客户的订单。 何老板所在的城市只有一条笔直的大街,我们可以将它想象成数轴,其中位置0是何老板的披萨店,第i个客户所在的位置为Pi,每个客户的位置都不同。如果何老板给第i个客户送披萨,客户会支付Ei-Ti块钱,其中Ti是何老板到达他家的时刻。当然,如果到得太晚,会使得Ei-Ti<0,这时,何老板可以选择不给他送餐,免得他反过来找何老板要钱。 何老板店里面只有一个送餐车(单位时间行驶单位长度的距离),因此只能往返送餐,如下图所示就是一条线路,图中第一行的数字是位置Pi,第二行是Ei。 你的任务是帮助何老板计算出最大的收益。

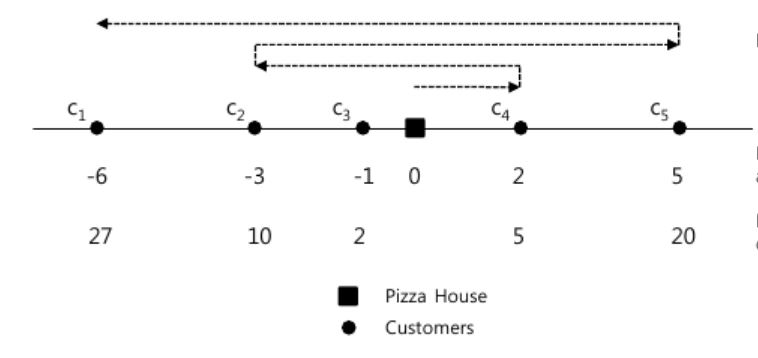
【输入格式】
第一行,一个整数n 第二行,n个空格间隔的整数,从左往右给出了每个客户的位置Pi,即P1,P2,......,Pn 第三行,n个空格间隔的整数,从左往右给出了每个客户对应的Ei,即E1,E2,......,En
【输出格式】
一行,一个整数,表示所求的最佳收益。
【输入样例1】
5 -6 -3 -1 2 5 27 10 2 5 20
【输出样例1】
32
【输入样例2】
6 1 2 4 7 11 14 3 6 2 5 18 10
【输出样例2】
13
【输入样例3】
11 -14 -13 -12 -11 -10 1 2 3 4 5 100 200 200 200 200 200 200 200 200 200 200 200
【输出样例3】
1937
【数据范围】
1 ≤ n ≤ 100 -100,000 ≤ Pi ≤ 100,000 且Pi!=0 0< Ei ≤ 100,000
【解题思路】
#include<cstdio>
#include<iostream>
#include<algorithm>
#include<cstdlib>
#include<cstring>
using namespace std;
int f[205][205][205][2];
bool mark[205][205][205][2];
int n;
int pos[205],e[205],start;
int dp(int l,int r,int cnt,int p){
int i;
if(mark[l][r][cnt][p])return f[l][r][cnt][p];
mark[l][r][cnt][p]=true;
if(cnt==0)return f[l][r][cnt][p]=0;
if(p==0){
for(i=1;i<l;i++){
f[l][r][cnt][p]=max(f[l][r][cnt][p],dp(i,r,cnt-1,0)+e[i]-cnt*abs(pos[l]-pos[i]));
}
for(i=r+1;i<=n+1;i++){
f[l][r][cnt][p]=max(f[l][r][cnt][p],dp(l,i,cnt-1,1)+e[i]-cnt*abs(pos[l]-pos[i]));
}
}
else{
for(i=1;i<l;i++){
f[l][r][cnt][p]=max(f[l][r][cnt][p],dp(i,r,cnt-1,0)+e[i]-cnt*abs(pos[r]-pos[i]));
}
for(i=r+1;i<=n+1;i++){
f[l][r][cnt][p]=max(f[l][r][cnt][p],dp(l,i,cnt-1,1)+e[i]-cnt*abs(pos[r]-pos[i]));
}
}
return f[l][r][cnt][p];
}
int main(){
int i,j,ans=0;
start=0;
cin>>n;
for(i=1;i<=n+1;i++){
cin>>pos[i];
if(pos[i]>0&&start==0){
start=i;
pos[i+1]=pos[i];
pos[i]=0;
i++;
}
}
for(i=1;i<=n+1;i++){
cin>>e[i];
if(start==i){
e[i+1]=e[i];
e[i]=0;
i++;
}
}
for(i=0;i<=n;i++){
ans=max(ans,dp(start,start,i,0));
}
cout<<ans;
}发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/164438.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
