大家好,又见面了,我是你们的朋友全栈君。
建立数据库连接耗时耗费资源,一个数据库服务器能够同时建立的连接数也是有限的,在大型的Web应用中,可能同时会有成百上千的访问数据库的请求,如果Web应用程序为每一个客户请求分配一个数据库连接,将导致性能的急剧下降。
数据库连接池的意义在于,能够重复利用数据库连接(有点类似线程池的部分意义),提高对请求的响应时间和服务器的性能。
连接池中提前预先建立了多个数据库连接对象,然后将连接对象保存到连接池中,当客户请求到来时,直接从池中取出一个连接对象为客户服务,当请求完成之后,客户程序调用close()方法,将连接对象放回池中。
其他几个连接池
Spring 推荐使用dbcp;
Hibernate 推荐使用c3p0和proxool
1、 DBCP:apache
DBCP(DataBase connection pool)数据库连接池。是apache上的一个 java连接池项目,也是 tomcat使用的连接池组件。单独使用dbcp需要3个包:common-dbcp.jar,common-pool.jar,common-collections.jar由于建立数据库连接是一个非常耗时耗资源的行为,所以通过连接池预先同数据库建立一些连接,放在内存中,应用程序需要建立数据库连接时直接到连接池中申请一个就行,用完后再放回去。dbcp没有自动的去回收空闲连接的功能。
2、 C3P0:
C3P0是一个开源的jdbc连接池,它实现了数据源和jndi绑定,支持jdbc3规范和jdbc2的标准扩展。c3p0是异步操作的,缓慢的jdbc操作通过帮助进程完成。扩展这些操作可以有效的提升性能。目前使用它的开源项目有Hibernate,Spring等。c3p0有自动回收空闲连接功能。
3、 Proxool:Sourceforge
Proxool是一种Java数据库连接池技术。是sourceforge下的一个开源项目,这个项目提供一个健壮、易用的连接池,最为关键的是这个连接池提供监控的功能,方便易用,便于发现连接泄漏的情况。
综合来说,稳定性是Spring 推荐使用dbcp;
Hibernate 推荐使用c3p0和proxool
1、 DBCP:apache
DBCP(DataBase connection pool)数据库连接池。是apache上的一个 java连接池项目,也是 tomcat使用的连接池组件。单独使用dbcp需要3个包:common-dbcp.jar,common-pool.jar,common-collections.jar由于建立数据库连接是一个非常耗时耗资源的行为,所以通过连接池预先同数据库建立一些连接,放在内存中,应用程序需要建立数据库连接时直接到连接池中申请一个就行,用完后再放回去。dbcp没有自动的去回收空闲连接的功能。
2、 C3P0:
C3P0是一个开源的jdbc连接池,它实现了数据源和jndi绑定,支持jdbc3规范和jdbc2的标准扩展。c3p0是异步操作的,缓慢的jdbc操作通过帮助进程完成。扩展这些操作可以有效的提升性能。目前使用它的开源项目有Hibernate,Spring等。c3p0有自动回收空闲连接功能。
3、 Proxool:Sourceforge
Proxool是一种Java数据库连接池技术。是sourceforge下的一个开源项目,这个项目提供一个健壮、易用的连接池,最为关键的是这个连接池提供监控的功能,方便易用,便于发现连接泄漏的情况。
综合来说,稳定性是dbcp>=c3p0>proxool
Druid介绍
druid为阿里巴巴的数据源,(数据库连接池),集合了c3p0、dbcp、proxool等连接池的优点,还加入了日志监控,有效的监控DB池连接和SQL的执行情况。
DRUID的DataSource类为:com.alibaba.druid.pool.DruidDataSource。
其他配置参数如下:
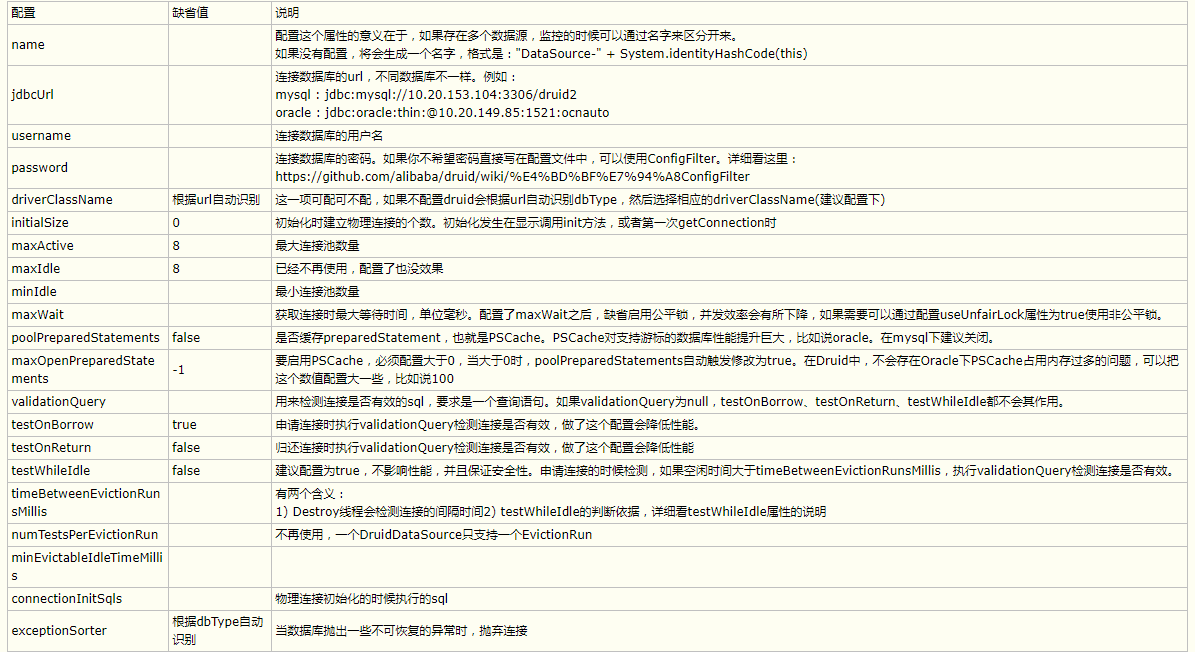

Druid数据源的使用
- 在Spring配置中使用阿里巴巴的数据源。
注意要先引入druid依赖。
在Spring中直接写配置文件即可:
<!-- 配置Druid数据源 -->
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close">
<!-- 基本属性 url、user、password -->
<property name="url" value="${jdbc.url}" />
<property name="username" value="${jdbc.username}" />
<property name="password" value="${jdbc.password}" />
<!-- 配置初始化大小、最小、最大 -->
<property name="initialSize" value="5" />
<property name="minIdle" value="5" />
<property name="maxActive" value="100" />
<!-- 配置获取连接等待超时的时间 -->
<property name="maxWait" value="60000" />
<!-- 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒 -->
<property name="timeBetweenEvictionRunsMillis" value="60000" />
<!-- 配置一个连接在池中最小生存的时间,单位是毫秒 -->
<property name="minEvictableIdleTimeMillis" value="300000" />
<property name="validationQuery" value="SELECT 'x'" />
<property name="testWhileIdle" value="true" />
<property name="testOnBorrow" value="false" />
<property name="testOnReturn" value="false" />
<!-- 打开PSCache,并且指定每个连接上PSCache的大小 -->
<property name="poolPreparedStatements" value="false" />
<property name="maxPoolPreparedStatementPerConnectionSize" value="20" />
<!-- 配置监控统计拦截的filters -->
<property name="filters" value="stat,wall" />
</bean>
要想使用druid的数据监控功能需要在web.xml里面配置servlet
<!-- 配置 Druid 监控信息显示页面 -->
<servlet>
<servlet-name>DruidStatView</servlet-name>
<servlet-class>com.alibaba.druid.support.http.StatViewServlet</servlet-class>
<init-param>
<!-- 允许清空统计数据 -->
<param-name>resetEnable</param-name>
<param-value>true</param-value>
</init-param>
<init-param>
<!-- 用户名 -->
<param-name>loginUsername</param-name>
<param-value>druid</param-value>
</init-param>
<init-param>
<!-- 密码 -->
<param-name>loginPassword</param-name>
<param-value>druid</param-value>
</init-param>
</servlet>
<servlet-mapping>
<servlet-name>DruidStatView</servlet-name>
<url-pattern>/druid/*</url-pattern>
</servlet-mapping>
对于资源的拦截配置:(可以在web.xml,也可以在Spring里面配置)
<!-- 用于采集web-jdbc关联监控的数据。 -->
<filter>
<filter-name>DruidWebStatFilter</filter-name>
<filter-class>com.alibaba.druid.support.http.WebStatFilter</filter-class>
<init-param>
<param-name>exclusions</param-name>
<param-value>*.js,*.gif,*.jpg,*.png,*.css,*.ico,/druid/*</param-value>
</init-param>
<init-param>
<param-name>sessionStatMaxCount</param-name>
<param-value>1000</param-value>
</init-param>
<init-param>
<param-name>sessionStatEnable</param-name>
<param-value>false</param-value>
</init-param>
</filter>
<filter-mapping>
<filter-name>DruidWebStatFilter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
扩展:druid是可以配置输出日志的。这样,可以在控制台里面,看到我们程序里面编写的sql语句,还可以看到可执行的sql。
只需要在spring的配置文件里面配置:
<bean id="log-filter" class="com.alibaba.druid.filter.logging.Log4jFilter">
<!--日志打印可执行的sql -->
<property name="statementExecutableSqlLogEnable" value="true" />
<property name="dataSourceLogEnabled" value="true" />
<property name="connectionLogEnabled" value="true" />
<property name="statementLogEnabled" value="true" />
<property name="resultSetLogEnabled" value="true" />
</bean>
<!-- 配置Druid数据源 -->
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close">
<!-- 基本属性 url、user、password -->
<property name="url" value="${jdbc.url}" />
<property name="username" value="${jdbc.username}" />
<property name="password" value="${jdbc.password}" />
<!-- 配置初始化大小、最小、最大 -->
<property name="initialSize" value="5" />
<property name="minIdle" value="5" />
<property name="maxActive" value="100" />
<!-- 配置获取连接等待超时的时间 -->
<property name="maxWait" value="60000" />
<!-- 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒 -->
<property name="timeBetweenEvictionRunsMillis" value="60000" />
<!-- 配置一个连接在池中最小生存的时间,单位是毫秒 -->
<property name="minEvictableIdleTimeMillis" value="300000" />
<property name="validationQuery" value="SELECT 'x'" />
<property name="testWhileIdle" value="true" />
<property name="testOnBorrow" value="false" />
<property name="testOnReturn" value="false" />
<!-- 打开PSCache,并且指定每个连接上PSCache的大小 -->
<property name="poolPreparedStatements" value="false" />
<property name="maxPoolPreparedStatementPerConnectionSize" value="20" />
<!-- 配置监控统计拦截的filters -->
<property name="filters" value="stat,wall" />
<property name="proxyFilters">
<list>
<ref bean="log-filter"/>
</list>
</property>
</bean>
- 在Springboot 中使用Druid。
首先,Springboot中,1.5版本之前的默认的数据库连接池是tomcat的JDBC连接池(Tomcat JDBC Pool)。
1.添加pom依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.0.20</version>
</dependency>
2.配置application.properties文件,配置相关信息
########################## mysql ##########################
spring.datasource.url=jdbc:mysql://localhost/db_boot?useUnicode=true&characterEncoding=utf-8
spring.datasource.username=root
spring.datasource.password=
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
logging.level.com.shyroke.mapper=debug
########################## mybatis ##########################
mybatis.mapper-locations=classpath:mybatis/*.xml
########################## druid配置 ##########################
spring.datasource.type=com.alibaba.druid.pool.DruidDataSource
# 初始化大小,最小,最大
spring.datasource.initialSize=5
spring.datasource.minIdle=5
spring.datasource.maxActive=20
# 配置获取连接等待超时的时间
spring.datasource.maxWait=60000
# 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒
spring.datasource.timeBetweenEvictionRunsMillis=60000
# 配置一个连接在池中最小生存的时间,单位是毫秒
spring.datasource.minEvictableIdleTimeMillis=300000
# 校验SQL,Oracle配置 spring.datasource.validationQuery=SELECT 1 FROM DUAL,如果不配validationQuery项,则下面三项配置无用
spring.datasource.validationQuery=SELECT 'x'
spring.datasource.testWhileIdle=true
spring.datasource.testOnBorrow=false
spring.datasource.testOnReturn=false
# 打开PSCache,并且指定每个连接上PSCache的大小
spring.datasource.poolPreparedStatements=true
spring.datasource.maxPoolPreparedStatementPerConnectionSize=20
# 配置监控统计拦截的filters,去掉后监控界面sql无法统计,'wall'用于防火墙
spring.datasource.filters=stat,wall,log4j
# 通过connectProperties属性来打开mergeSql功能;慢SQL记录
spring.datasource.connectionProperties=druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000
# 合并多个DruidDataSource的监控数据
spring.datasource.useGlobalDataSourceStat=true
3.配置WebFilter
package com.example.durid.filter;
import com.alibaba.druid.support.http.WebStatFilter;
import javax.servlet.annotation.WebFilter;
import javax.servlet.annotation.WebInitParam;
/**
* 配置监控拦截器
* druid监控拦截器
* @ClassName: DruidStatFilter
* @author 16437
* @date
*/
@WebFilter(filterName = "druidWebStatFilter",
urlPatterns = "/*",
initParams =
// 忽略资源
{ @WebInitParam(name = "exclusions", value = "*.js,*.gif,*.jpg,*.bmp,*.png,*.css,*.ico,/druid/*")}
)
public class DruidStatFilter extends WebStatFilter {
}
4.配置WebServlet
package com.example.durid.base;
import com.alibaba.druid.support.http.StatViewServlet;
import javax.servlet.annotation.WebInitParam;
import javax.servlet.annotation.WebServlet;
/**
* druid监控视图配置
* @ClassName: DruidStatViewServlet
* @author Martina
* @date 2019
*/
@WebServlet(urlPatterns = "/druid/*", initParams={
@WebInitParam(name="allow",value=""),// IP白名单 (没有配置或者为空,则允许所有访问)
@WebInitParam(name="deny",value="192.168.16.111"),// IP黑名单 (存在共同时,deny优先于allow)
@WebInitParam(name="loginUsername",value="admin"),// 用户名
@WebInitParam(name="loginPassword",value="admin"),// 密码
@WebInitParam(name="resetEnable",value="true")// 禁用HTML页面上的“Reset All”功能
})
public class DruidStatViewServlet extends StatViewServlet {
}
5.扫描Servlet
注意要启动类中加上@ServletComponentScan注解,否则Servlet无法生效 。
package com.example.durid;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.boot.web.servlet.ServletComponentScan;
@SpringBootApplication
@ServletComponentScan
public class DuridApplication {
public static void main(String[] args) {
SpringApplication.run(DuridApplication.class, args);
}
}
6.手动初始化DataSource
有些版本存在自动初始化数据,SQL监控显示不出任何的内容问题,如果版本不存在bug可以跳过这一步。
package com.example.durid;
import com.alibaba.druid.pool.DruidDataSource;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Primary;
import java.sql.SQLException;
@Configuration
public class DruidConfiguration {
@Value("${spring.datasource.url}")
private String dbUrl;
@Value("${spring.datasource.username}")
private String username;
@Value("${spring.datasource.password}")
private String password;
@Value("${spring.datasource.driverClassName}")
private String driverClassName;
@Value("${spring.datasource.initialSize}")
private int initialSize;
@Value("${spring.datasource.minIdle}")
private int minIdle;
@Value("${spring.datasource.maxActive}")
private int maxActive;
@Value("${spring.datasource.maxWait}")
private int maxWait;
@Value("${spring.datasource.timeBetweenEvictionRunsMillis}")
private int timeBetweenEvictionRunsMillis;
@Value("${spring.datasource.minEvictableIdleTimeMillis}")
private int minEvictableIdleTimeMillis;
@Value("${spring.datasource.validationQuery}")
private String validationQuery;
@Value("${spring.datasource.testWhileIdle}")
private boolean testWhileIdle;
@Value("${spring.datasource.testOnBorrow}")
private boolean testOnBorrow;
@Value("${spring.datasource.testOnReturn}")
private boolean testOnReturn;
@Value("${spring.datasource.poolPreparedStatements}")
private boolean poolPreparedStatements;
@Value("${spring.datasource.maxPoolPreparedStatementPerConnectionSize}")
private int maxPoolPreparedStatementPerConnectionSize;
@Value("${spring.datasource.filters}")
private String filters;
@Value("${spring.datasource.connectionProperties}")
private String connectionProperties;
@Value("${spring.datasource.useGlobalDataSourceStat}")
private boolean useGlobalDataSourceStat;
@Bean //声明其为Bean实例
@Primary //在同样的DataSource中,首先使用被标注的DataSource
public DruidDataSource dataSource(){
DruidDataSource datasource = new DruidDataSource();
datasource.setUrl(this.dbUrl);
datasource.setUsername(username);
datasource.setPassword(password);
datasource.setDriverClassName(driverClassName);
//configuration
datasource.setInitialSize(initialSize);
datasource.setMinIdle(minIdle);
datasource.setMaxActive(maxActive);
datasource.setMaxWait(maxWait);
datasource.setTimeBetweenEvictionRunsMillis(timeBetweenEvictionRunsMillis);
datasource.setMinEvictableIdleTimeMillis(minEvictableIdleTimeMillis);
datasource.setValidationQuery(validationQuery);
datasource.setTestWhileIdle(testWhileIdle);
datasource.setTestOnBorrow(testOnBorrow);
datasource.setTestOnReturn(testOnReturn);
datasource.setPoolPreparedStatements(poolPreparedStatements);
datasource.setMaxPoolPreparedStatementPerConnectionSize(maxPoolPreparedStatementPerConnectionSize);
datasource.setUseGlobalDataSourceStat(useGlobalDataSourceStat);
try {
datasource.setFilters(filters);
} catch (SQLException e) {
System.err.println("druid configuration initialization filter: "+ e);
}
datasource.setConnectionProperties(connectionProperties);
return datasource;
}
}
配置完成之后,启动应用程序,可以再浏览器中的SQL监控中查看SQL的执行数、时间、事务等情况。

部分转自:https://www.cnblogs.com/zfding/p/7821967.html
以及 https://www.cnblogs.com/shyroke/p/8045077.html
附上github上,druid的托管地址:https://github.com/alibaba/druid
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/163563.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
