大家好,又见面了,我是你们的朋友全栈君。
简介
mysql是一个TCP/IP协议的网络程序,如果我们每次都从数据库获取新的连接,那么:
- 每获取一次新的连接的成本很高,需要“三次握手”,断开需要“四次挥手”等过程
- 每一个客户端都有单独的线程来维护它的通信
这样每次高成本获取的连接只用一次,太奢侈了;另外,如果有很多的客户端同时去连接mysql服务器,会造成mysql的并发量就有风险,如果太多就会挂了。特别是遇到一些程序员,获取完连接,没有关闭的情况。
数据库连接池的技术的原理:先创建一个连接池pool,然后在池中初始化少量的连接对象,当程序获取连接对象时,用池中已有的对象,会快很多。等用户并发量上来后,会增加连接数,直到最高连接数为止。之前conn.close()真正的与服务器断开连接,现在从连接池中拿的连接对象,关闭时是还给连接池。可以设置连接池的最大连接数量,如果池中的所有连接都在使用的话,那么可以让“客户端”等待,虽然有等待的现象,但是总比每次使用都创建之后销毁了性能高。
针对这个问题,我们可以采用“数据库连接池”来解决。连接池技术有很多,Druid是其中比较优秀的,它是阿里推出的,它不仅仅为数据源,还能sql拦截等功能。
本博客示例中用到的Dept类,请参考:Dept源代码
示例
-
第一步:创建一个Maven Web项目,添加依赖
<dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>8.0.13</version> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>druid</artifactId> <version>1.1.17</version> </dependency> -
第二步:在resources下创建mysql.properties文件
driverClassName=com.mysql.cj.jdbc.Driver
url=jdbc:mysql://localhost:3306/test?useSSL=false&serverTimezone=GMT%2B8&useUnicode=true&characterEncoding=UTF8&autoReconnect=true&failOverReadOnly=false
username=root
password=root
#检测数据库链接是否有效,必须配置
validationQuery=SELECT 'x'
#初始连接数
initialSize=3
#最大连接池数量
maxActive=10
#去掉,配置文件对应去掉
#maxIdle=20
#配置0,当线程池数量不足,自动补充。
minIdle=0
#获取链接超时时间为1分钟,单位为毫秒。
maxWait=60000
#获取链接的时候,不校验是否可用,开启会有损性能。
testOnBorrow=false
#归还链接到连接池的时候校验链接是否可用。
testOnReturn=false
#此项配置为true即可,不影响性能,并且保证安全性。意义为:申请连接的时候检测,如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效。
testWhileIdle=true
#1.Destroy线程会检测连接的间隔时间
#2.testWhileIdle的判断依据
timeBetweenEvictionRunsMillis=60000
#一个链接生存的时间(之前的值:25200000,这个时间有点BT,这个结果不知道是怎么来的,换算后的结果是:25200000/1000/60/60 = 7个小时)
minEvictableIdleTimeMillis=300000
#链接使用超过时间限制是否回收
removeAbandoned=false
#超过时间限制时间(单位秒),目前为5分钟,如果有业务处理时间超过5分钟,可以适当调整。
removeAbandonedTimeout=300
#链接回收的时候控制台打印信息,测试环境可以加上true,线上环境false。会影响性能。
logAbandoned=false
-
第三步:写基于Druid的数据库访问工具类
因为Connection是不线程安全的,为了保证同一个线程(客户端)共享同一个Connection对象,可以使用LocalThread来限制Connection。import com.alibaba.druid.pool.DruidDataSourceFactory; import javax.sql.DataSource; import java.io.InputStream; import java.sql.Connection; import java.sql.ResultSet; import java.sql.SQLException; import java.sql.Statement; import java.util.Properties; public class DBUtil { private static final ThreadLocal<Connection> threadLocal = new ThreadLocal<>(); private static DataSource dataSource = null; static { //配置文件加载,只执行一次 try (InputStream is = DBUtil.class.getResourceAsStream("/mysql.properties");) { Properties properties = new Properties(); properties.load(is); dataSource = DruidDataSourceFactory.createDataSource(properties); } catch (Exception e1) { throw new RuntimeException("读取配置文件异常", e1); } } public static Connection getConnection() { //获取连接 Connection conn = null; try { conn = threadLocal.get();//从当前线程获得conn if (conn == null || conn.isClosed()) { //重点,需要注意conn.isClosed()条件的判断 conn = dataSource.getConnection(); threadLocal.set(conn); } } catch (Exception e) { throw new RuntimeException("连接数据库异常", e); } return conn; } public static QueryRunner getQueryRunner(){ return new QueryRunner(dataSource); } public static void release(ResultSet rs, Statement stmt, Connection conn) { try { // 建议采用这种形式来释放资源,因为finally里面的一定会被释放 if (rs != null) { rs.close(); } } catch (SQLException e) { e.printStackTrace(); } finally { try { if (stmt != null) { stmt.close(); } } catch (SQLException e) { e.printStackTrace(); } finally { if (conn != null) { try { conn.close(); } catch (SQLException e) { e.printStackTrace(); } } } } } } -
第四步:测试连接
public static void main(String[] args) throws SQLException { for(int i=0;i<5;i++){ //开启5个线程 new Thread(()->{ //在每个线程中获取Connection对象,并输出 Connection conn = getConnection(); System.out.println(conn); }).start(); } }运行程序,结果如下:

修改mysql.properties,设置的值如下:
initialSize=3 maxActive=4再次运行测试代码,结果如下:
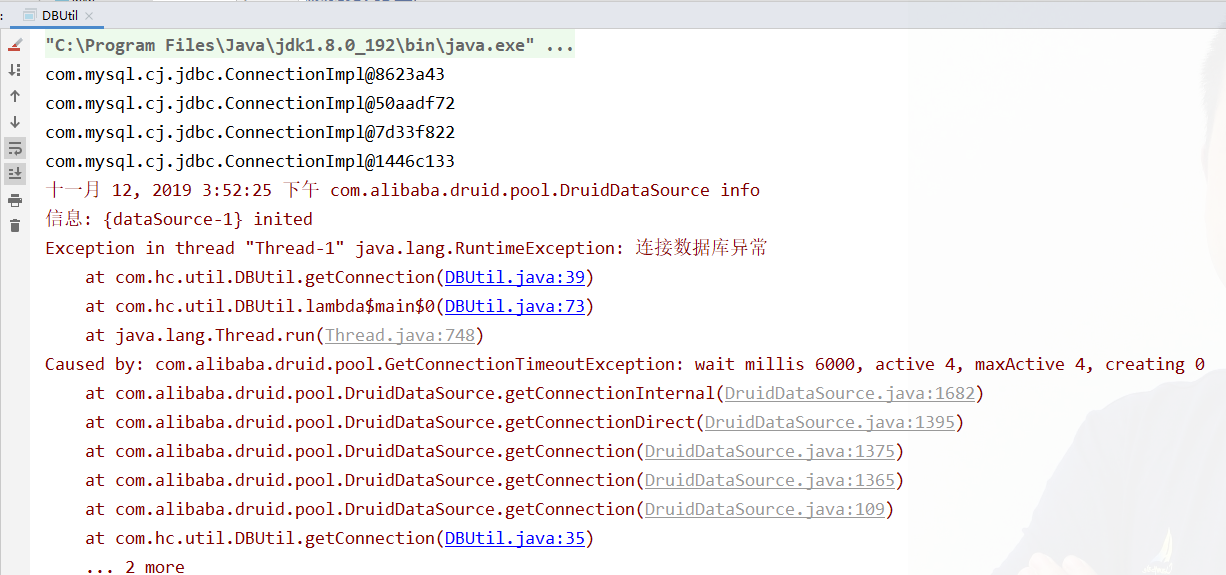
-
第五步: CRUD测试
public class DemoTest { @Test public void insert() throws SQLException { String sql ="insert into tb_dept values (?,?,?)"; Connection conn = DBUtil.getConnection(); PreparedStatement ps = conn.prepareStatement(sql); ps.setInt(1,11); ps.setString(2,"aa"); ps.setString(3,"aaaaa"); ps.executeUpdate(); DBUtil.release(null,ps,conn); } @Test public void update() throws SQLException { String sql ="update tb_dept set dname=?,loc =? where deptno =?"; Connection conn = DBUtil.getConnection(); PreparedStatement ps = conn.prepareStatement(sql); ps.setString(1,"b"); ps.setString(2,"bbbbb"); ps.setInt(3,11); ps.executeUpdate(); DBUtil.release(null,ps,conn); } @Test public void delete() throws SQLException { String sql ="delete from tb_dept where deptno =?"; Connection conn = DBUtil.getConnection(); PreparedStatement ps = conn.prepareStatement(sql); ps.setInt(1,11); ps.executeUpdate(); DBUtil.release(null,ps,conn); } @Test public void select() throws SQLException { String sql ="select * from tb_dept where deptno =?"; Connection conn = DBUtil.getConnection(); PreparedStatement ps = conn.prepareStatement(sql); ps.setInt(1,10); ResultSet res = ps.executeQuery(); while (res.next()){ Dept dept = new Dept(res.getInt("deptno"),res.getString("dname"),res.getString("loc")); System.out.println(dept); } DBUtil.release(res,ps,conn); } }
附:druid 配置参考
| 配置 | 缺省值 | 说明 |
|---|---|---|
| name | 配置这个属性的意义在于,如果存在多个数据源,监控的时候可以通过名字来区分开来。如果没有配置,将会生成一个名字,格式是:“DataSource-” + System.identityHashCode(this). 另外配置此属性至少在1.0.5版本中是不起作用的,强行设置name会出错。详情-点此处。 | |
| url | 连接数据库的url,不同数据库不一样。例如: mysql : jdbc:mysql://10.20.153.104:3306/druid2 oracle : jdbc:oracle:thin:@10.20.149.85:1521:ocnauto | |
| username | 连接数据库的用户名 | |
| password | 连接数据库的密码。如果你不希望密码直接写在配置文件中,可以使用ConfigFilter。详细看这里 | |
| driverClassName | 根据url自动识别 | 这一项可配可不配,如果不配置druid会根据url自动识别dbType,然后选择相应的driverClassName |
| initialSize | 0 | 初始化时建立物理连接的个数。初始化发生在显示调用init方法,或者第一次getConnection时 |
| maxActive | 8 | 最大连接池数量 |
| maxIdle | 8 | 已经不再使用,配置了也没效果 |
| minIdle | 最小连接池数量 | |
| maxWait | 获取连接时最大等待时间,单位毫秒。配置了maxWait之后,缺省启用公平锁,并发效率会有所下降,如果需要可以通过配置useUnfairLock属性为true使用非公平锁。 | |
| poolPreparedStatements | false | 是否缓存preparedStatement,也就是PSCache。PSCache对支持游标的数据库性能提升巨大,比如说oracle。在mysql下建议关闭。 |
| maxPoolPreparedStatementPerConnectionSize | -1 | 要启用PSCache,必须配置大于0,当大于0时,poolPreparedStatements自动触发修改为true。在Druid中,不会存在Oracle下PSCache占用内存过多的问题,可以把这个数值配置大一些,比如说100 |
| validationQuery | 用来检测连接是否有效的sql,要求是一个查询语句,常用select ‘x’。如果validationQuery为null,testOnBorrow、testOnReturn、testWhileIdle都不会其作用。 | |
| validationQueryTimeout | 单位:秒,检测连接是否有效的超时时间。底层调用jdbc Statement对象的void setQueryTimeout(int seconds)方法 | |
| testOnBorrow | true | 申请连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能。 |
| testOnReturn | false | 归还连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能。 |
| testWhileIdle | false | 建议配置为true,不影响性能,并且保证安全性。申请连接的时候检测,如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效。 |
| timeBetweenEvictionRunsMillis | 1分钟(1.0.14) | 有两个含义: 1) Destroy线程会检测连接的间隔时间,如果连接空闲时间大于等于minEvictableIdleTimeMillis则关闭物理连接。 2) testWhileIdle的判断依据,详细看testWhileIdle属性的说明 |
| numTestsPerEvictionRun | 30分钟(1.0.14) | 不再使用,一个DruidDataSource只支持一个EvictionRun |
| minEvictableIdleTimeMillis | 连接保持空闲而不被驱逐的最长时间 | |
| connectionInitSqls | 物理连接初始化的时候执行的sql | |
| exceptionSorter | 根据dbType自动识别 | 当数据库抛出一些不可恢复的异常时,抛弃连接 |
| filters | 属性类型是字符串,通过别名的方式配置扩展插件,常用的插件有: 监控统计用的filter:stat 日志用的filter:log4j 防御sql注入的filter:wall | |
| proxyFilters | 类型是List,如果同时配置了filters和proxyFilters,是组合关系,并非替换关系 |
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/163560.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
