大家好,又见面了,我是你们的朋友全栈君。
LK光流法可用来跟踪特征点的位置。
比如在img1中的特征点,由于相机或物体的运动,在img2中来到了不同的位置。后面会称img1为Template(T),img2为I。
光流法有个假设:
灰度不变假设:同一个空间点的像素灰度值,在各图像中是不变的,也就是说T中特征点处的灰度,到了I中仍然是一样的灰度。
这就要求光照恒定,物体反射恒定,是个很强的假设。
现在要估计的是运动偏移量[dx, dy],也就是光流。仅用一个点无法解,一般会取一个窗口内的像素,考虑它们具有相同的运动。
用最小二乘法来解像素的运动如下:
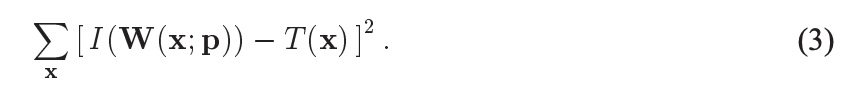

这里的W表示对图像 I 进行像素变换,把它变到T所在的时间,即运动前的图像,看跟T有多大误差。这里假设对窗口内的像素进行变换。
p是运动位移量(dx, dy)。
这是个非线性优化问题,因为像素是跟坐标不是线性关系。
这时可以假设p已经知道了(假设就是运动前的点坐标,或者给定一个值),在它的基础上不断加上增量进行调整。
于是变成了优化如下问题,把它叫做error:
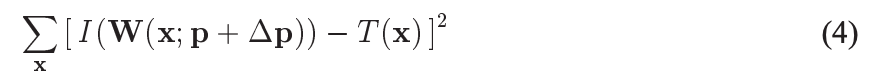
每次估计出增量 Δ p \Delta p Δp
更新p,

(4)(5)两步反复迭代直到达到收敛条件,收敛条件可以是
Δ p \Delta p Δp 小于一个阈值,或者(4)中的cost比前一次大(理论上cost是逐渐减小的)
上面就是最小二乘法求光流的大概步骤,具体如何求 Δ p \Delta p Δp,下面是高斯牛顿法解 Δ p \Delta p Δp,及迭代出光流(dx, dy)的步骤:
-
把上面的(4)式,也就是cost函数,对 I ( W ( x ; p + Δ p ) ) I(W(x;p+\Delta p)) I(W(x;p+Δp))进行一阶泰勒展开,得到:
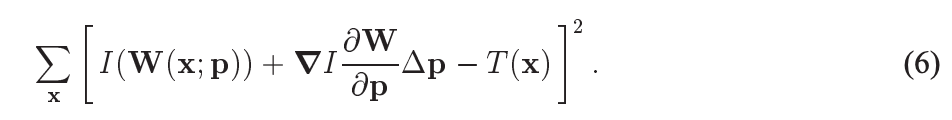
这里的 ▽ I \bigtriangledown I ▽I指在图像 I,也就是img2中对特征点处求x,y方向上的梯度,然后通过W变换回T的坐标中。
∂ W / ∂ p \partial W/ \partial p ∂W/∂p指W对p求偏导。
举个例子吧,假如W如下
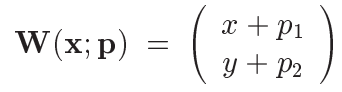
那么 [ ∂ W x / ∂ p 1 ∂ W x / ∂ p 2 ∂ W y ∂ p 1 ∂ W y / ∂ p 2 ] = [ 1 0 0 1 ] \left[ \begin{matrix} \partial W_x/ \partial p1 & \partial W_x/ \partial p2 \\ \partial W_y \partial p1 & \partial W_y/ \partial p2 \\ \end{matrix} \right] = \left[ \begin{matrix} 1 &0 \\ 0 & 1 \\ \end{matrix} \right] [∂Wx/∂p1∂Wy∂p1∂Wx/∂p2∂Wy/∂p2]=[1001]
上面的(p1, p2)就是我们要求的光流(dx, dy), 这个 ∂ W / ∂ p \partial W/ \partial p ∂W/∂p就是雅可比矩阵 J J J -
上面(6)式对 Δ p \Delta p Δp求偏导,得到:
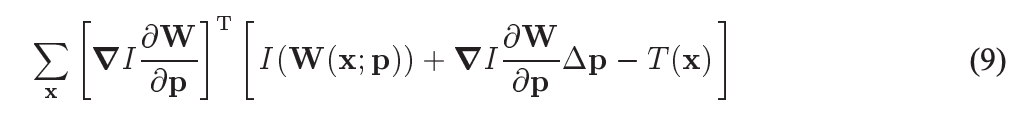
先解释一下 Δ p \Delta p Δp和上面p的关系,上面的p是我们要求的光流(dx, dy),而直接求比较困难,现在假设已经知道初始的(dx, dy), 比如(0, 0),要通过每次求(dx, dy)的增量( Δ d x , Δ d y ) \Delta dx, \Delta dy) Δdx,Δdy), 也就是 Δ p \Delta p Δp,来不断修正(dx, dy), 直到收敛。
另上面(9)式偏导为0,可求得:
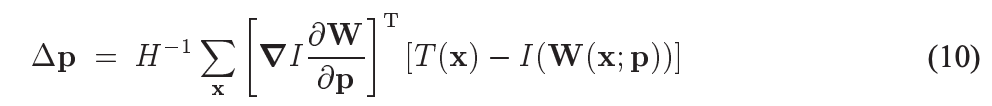
这就是最小二乘法的解,
其实可以想到最小二乘法解增量问题的形式一般是
H Δ x = b H \Delta x = b HΔx=b, 其中
H = J J T , b = − J e H = JJ^{T}, b = -Je H=JJT,b=−Je, e e e即为error函数。
同样地,上面的 H = J J T H = JJ^{T} H=JJT,
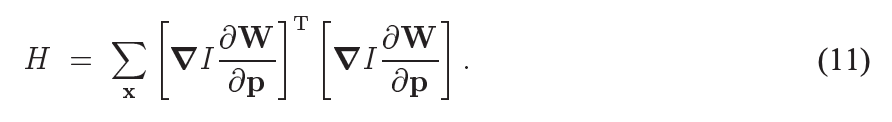
Δ p \Delta p Δp一旦求出,就可以不断迭代,得到最终的光流(dx, dy), 也就是p了。
下面通过一个例子说明如何追踪特征点的光流。
先在img1,也就是T里提取特征点kp1
Mat img1 = imread("../imgs/LK1.png", 0); //T
Mat img2 = imread("../imgs/LK2.png", 0); //I
//key points
vector<KeyPoint> kp1;
FAST(img1, kp1, 40); //可以用其他特征点
对每个特征点kp1[i], 设初始(dx, dy) = (0, 0)
auto kp = kp1[i];
double dx = 0, dy = 0; //需要估计
要用到的几个矩阵
Eigen::Matrix2d H = Eigen::Matrix2d::Zero(); //Hessian
Eigen::Vector2d b = Eigen::Vector2d::Zero(); //bias
Eigen::Vector2d J; //Jacobian
前面说了,不能只计算一个点,要计算一个小窗口内的点,并假设它们的运动是一样的。
代码中出现了逆向光流法,这个后面解释。
下面的代码中求出了H, b, 而 Δ p = H − 1 b \Delta p = H^{-1}b Δp=H−1b
//计算cost和jacobian
for(int x = -half_patch_size; x < half_patch_size; x++) {
for(int y = -half_patch_size; y < half_patch_size; y++) {
double error = GetPixelValue(img1, kp.pt.x + x, kp.pt.y + y) -
GetPixelValue(img2, kp.pt.x + x + dx, kp.pt.y + y + dy);
if(inverse == false) {
//error分别对dx, dy求导,因为是离散的,所以用dx+1,dx-1的位移差,dy同样
//x, y是窗口内的偏移量
//img1中没有dx, dy的变量,所以只有img2
J = -1.0 * Eigen::Vector2d(
0.5 * (GetPixelValue(img2, kp.pt.x + x + dx + 1, kp.pt.y + y + dy) -
GetPixelValue(img2, kp.pt.x + x + dx - 1, kp.pt.y + y + dy)),
0.5 * (GetPixelValue(img2, kp.pt.x + x + dx, kp.pt.y + y + dy + 1) -
GetPixelValue(img2, kp.pt.x + x + dx, kp.pt.y + y + dy - 1))
);
}else if (iter == 0) {
//反向光流法,只需计算第一次的H,后面H固定
J = -1.0 * Eigen::Vector2d(
0.5 * (GetPixelValue(img1, kp.pt.x + x + 1, kp.pt.y + y) -
GetPixelValue(img1, kp.pt.x + x - 1, kp.pt.y + y)),
0.5 * (GetPixelValue(img1, kp.pt.x + x, kp.pt.y + y + 1) -
GetPixelValue(img1, kp.pt.x + x, kp.pt.y + y - 1))
);
}
//计算H, b and set cost
b += -error * J;
cost += error * error;
//正向光流法每次迭代都要更新H
if(inverse == false || iter == 0) {
H += J * J.transpose();
}
}
Δ p = H − 1 b \Delta p = H^{-1}b Δp=H−1b
Eigen::Vector2d update = H.ldlt().solve(b); //避免求矩阵的逆
//最小二乘收敛
if(iter > 0 && cost > lastCost) {
break;
}
迭代更新(dx, dy)
dx += update[0];
dy += update[1];
lastCost = cost;
最后(dx, dy)就是我们要求的光流,根据img1中的keypoint kp1, 可以追踪到img2中的keypoint坐标为
kp2[i].pt = kp.pt + Point2f(dx, dy);
以上是单层光流,下面说说金字塔的多层光流
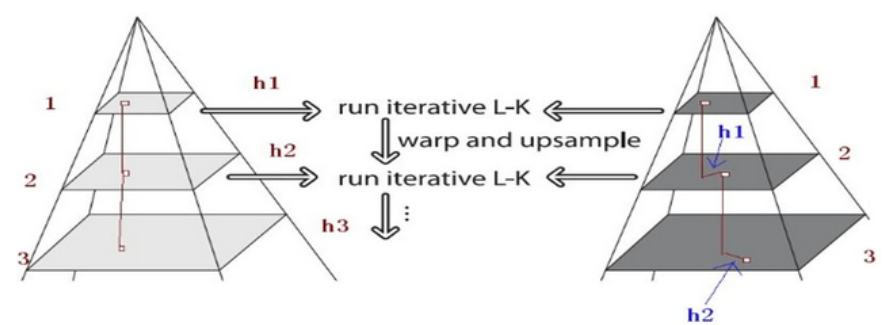 假设左边最下面一层(3号)是原图像img1 (T), 那么往上(2号,1号)就是对img1的缩放,右边最下面一层是img2, 往上是对img2的缩放。
假设左边最下面一层(3号)是原图像img1 (T), 那么往上(2号,1号)就是对img1的缩放,右边最下面一层是img2, 往上是对img2的缩放。
double pyramid_scale = 0.5;
//create pyramids
vector<Mat> pyr1, pyr2; //image pyramids
for(int i = 0; i < pyramids; i++) {
if(i == 0) {
pyr1.push_back(img1);
pyr2.push_back(img2);
} else {
Mat img1_pyr, img2_pyr;
//cv::Size(列,行)
resize(pyr1[i - 1], img1_pyr,
Size(pyr1[i-1].cols * pyramid_scale, pyr1[i-1].rows * pyramid_scale));
resize(pyr2[i - 1], img2_pyr,
Size(pyr2[i-1].cols * pyramid_scale, pyr2[i-1].rows * pyramid_scale));
pyr1.push_back(img1_pyr);
pyr2.push_back(img2_pyr);
}
}
计算光流时,从最上面一层(1号)计算。
左边1号缩放的img1为T,右边1号缩放的img2为I,以img1的keypoint kp1计算光流,得到kp2。
到计算下面两层的时候,以上一层光流的结果作为下一层的初始假设,而不是像最上层那样假设(dx, dy) = (0, 0)。
double dx = 0, dy = 0; //需要估计
if(has_initial) {
dx = kp2[i].pt.x - kp.pt.x; //x位移
dy = kp2[i].pt.y - kp.pt.y; //y位移
}
这样做有什么好处呢?假设移动了20个像素,直接求光流可能由于变化太大而陷入局部极值;但是缩放之后可能就只移动了5个像素,这就是一种coarse to fine的思想。
现在来说逆向光流法,
前面正向光流每迭代一次都要计算一次H,计算量很大。考虑有没有一种方法可以只计算一次H,然后后面都用这个H。
逆向光流法是前面正向光流的逆向,也就是交换一下方向,现在是从I 反向回到T,也就是从运动之后的 I 变换回运动前的T。
引用一个图方便理解
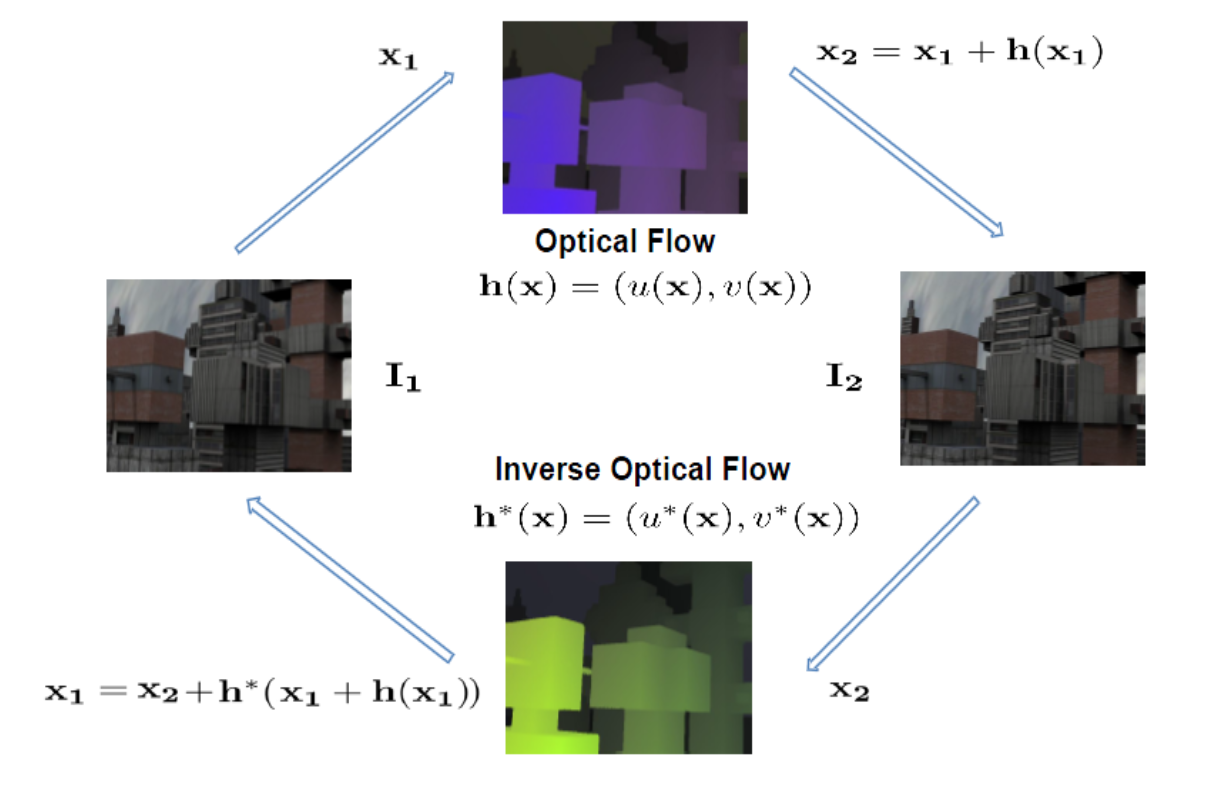
error函数如下,只需要交换T 和 I
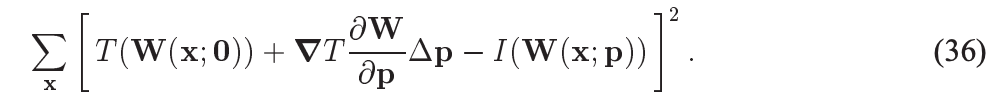
计算得到:
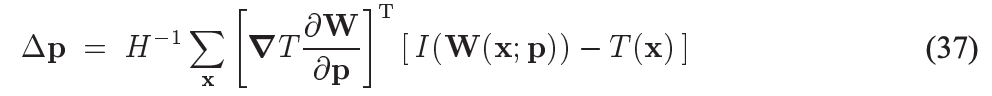
其中
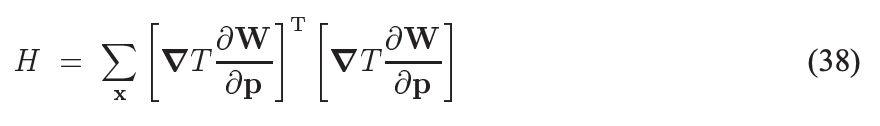
可以看到由于T 是运动前的img,并没有移动p=(dx, dy),因此H和p无关,每次迭代计算 Δ p \Delta p Δp时H是恒定的,只需要在第一次迭代时计算一次即可。对应了上面代码的如下部分:
}else if (iter == 0) {
//反向光流法,只需计算第一次的H,后面H固定
//H只和T,也就是img1有关
J = -1.0 * Eigen::Vector2d(
0.5 * (GetPixelValue(img1, kp.pt.x + x + 1, kp.pt.y + y) -
GetPixelValue(img1, kp.pt.x + x - 1, kp.pt.y + y)),
0.5 * (GetPixelValue(img1, kp.pt.x + x, kp.pt.y + y + 1) -
GetPixelValue(img1, kp.pt.x + x, kp.pt.y + y - 1))
);
}
每次迭代中H不需再更新
if(inverse == false || iter == 0) {
H += J * J.transpose();
}
上面就是正向光流,反向光流,如果想了解更加详细的资料,请参考paper
完整版代码请参考链接
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/163541.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
