大家好,又见面了,我是你们的朋友全栈君。
研究Lucene分析器的实现。
Analyzer抽象类
所有的分析器的实现,都是继承自抽象类Analyzer ,它的源代码如下所示:
这里,tokenStream()的作用非常大。它返回一个TokenStream类对象 ,这个TokenStream类对象应该是已经经过分词器处理过的 。
与Analyzer抽象类有关的其他类
TokenStream也是一个抽象类:
TokenStream类的方法表明,它最基本的是对分词流的状态进行管理。具体地,它如何对分析的对象处理,应该从继承该抽象类的子类的构造来看。
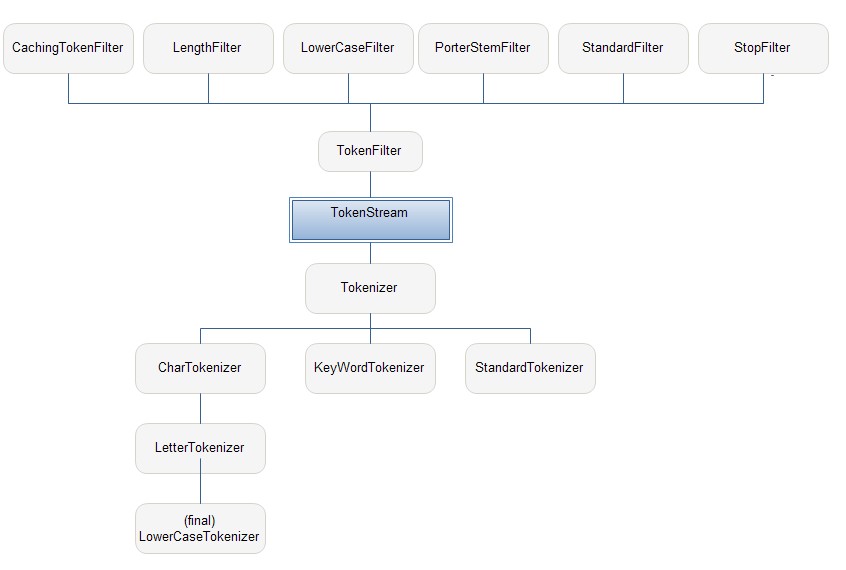
在包org.apache.lucene.analysis下可以看到有两个TokenStream的子类 :Tokenizer 和TokenFilter ,它们还都是抽象类 ,从这两个抽象类可以看出,是在TokenStream的基础上,按照功能进行分类实现:处理分词、过滤分词 。
Tokenizer类在Lucene中定义如下所示:
接着,看看TokenFilter类的实现,TokenFilter类在Lucene中定义如下 所示:
TokenFilter是可以嵌套Tokenizer的:
当一个Tokenizer对象不为null时,如果需要对其进行过滤,可以构造一个TokenFilter来对分词的词条进行过滤。
同样地,在包org.apache.lucene.analysis下可以找到继承自Tokenizer类的具体实现类。
很明显了,实现Tokenizer类的具体类应该是分词的核心所在 了。
对指定文本建立索引之前,应该(1) 先构造Field对象 ,在此基础上(2) 再构造Document对象 ,然后(3) 添加到IndexWriter中进行分析处理 。在(4) 这个分析处理过程中,包含对其进行分词(Tokenizer) ,而(5) 经过分词处理以后 ,返回的是一个Token 对象 (经过分词器得到的词条),它可能是Field中的一个Term的一部分 。
看一看Token类都定义了哪些内容:
最后 一个关系图 不太会画,里边的所有关系均为继承…

发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/163104.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
