大家好,又见面了,我是你们的朋友全栈君。
#SQL之视图与索引
- 视图的定义、修改、使用
- 索引的创建、查看
##视图
人们在使用数据库时,并不是直接对数据源表进行操作,通常人们只关心源表的部分数据,因此为了使得用户在查询时方便,用不着在每次查询时都编写复杂的代码(比如连接等),可以事先将用户要使用的查询结果通过视图定义在数据库中,这样人们在进行查询时只需查看视图即可,简化了用户的操作,同时使得数据同源数据分离,提高了安全性。
1.视图的创建
语法:
create view view_name
as
select_states
[with check option]
视图创建注意事项:
1.视图的名称必须唯一,不能与表名重复
2.视图通常只能定义在当前数据库中,分区视图除外
3.可以在视图上定义视图
4.视图中的select定义部分不能包含order by,compute、compute by、default语句
5.不能创建临时视图,也不能创建临时表上的视图
6.当视图中的某一列是计算列等,或者有重名列,则视图必须为每个列名命一个唯一的名称
例子:
创建一个查询student表中人员所选课程成绩大于80分的视图
代码:
use student
go
create view score_gt_80
as
select student.no,name,age,department,identityid,sc.classid,score
from student inner join sc
on student.no=sc.no
where score>80
效果:

2.修改视图
创建好的视图可以修改
语法:
alter view view_name
as
select_states
[with check option]
用法与create view类似,这里不再赘述
3.使用视图
1.一般简单的查询(只读查询)
可以利用已经建好的视图直接进行专门的功能查询,由于建立的视图是针对专门用户的,因此在该用户进行查询时,直接对视图进行查询即可,不必通过源表进行,方便快捷。
例子:
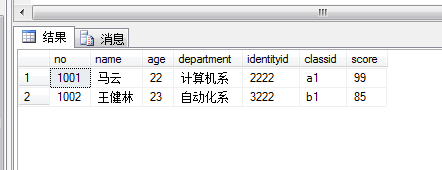
利用刚建好的score_gt_80视图查询student表中学生课程成绩大于80分的人员信息
代码:
select *
from score_gt_80
效果:

2.利用视图对源表进行修改
可以利用视图对源表进行修改,但必须满足以下条件:
1.若视图是源表行列的子集且不含不能为空且没有默认值得列,则
可以通过视图对源表进行插入、删除、更新操作。
2.若视图来源于几个源表,则不能通过视图对源表进行删除、插入
操作。但可以对源表的单个列进行更新操作。
3.能通过视图进行修改源表的视图必须引用的是源表而不是聚合函
数、计算列等。
4.被修改的列不应受having、group by、distinct、top n
控制
例子:
定义视图查询studnet表中学生年龄的student_age视图,包括
学生学号、姓名、年龄属性,视图中只包含年龄在22岁以上的成员
通过student_age视图将student表中所有22岁以上成员的年龄
都加1岁。
代码:
create view student_age ---创建视图
as
select no,name,age
from student
where age>22
update student_age ---通过视图修改
set age=age+1
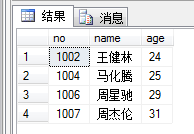
select * ---查看视图修改
from student_age
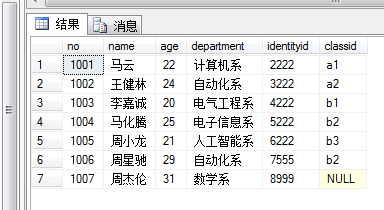
select * ----查看基本表修改
from student
效果:
修改后查询视图:
修改后查询基本表:
3.删除视图
语法:
drop view view_name
##索引
为了加快检索速度,sql引入了索引,如果没有引入索引,那么每次查询sql都会遍历这个基本表,效率低下。引入索引之后,索引将表中的某个列或几个列的值进行排序,为每个列建立索引,在查找时直接通过索引就可找到所要的值,效率较高。
索引按其列值分为:
1.唯一索引:索引所在的列中的值是不可重复的
2.非唯一索引:索引所在的列可以重复
unique、primary key约束的索引为唯一索引
索引按组织方式分为:
1.聚集索引:索引中的顺序和实际列在数据库中的物理存储顺序一致
2.非聚集索引:与上面相反,sql默认情况下的配置
索引的定义及使用:
对于索引的使用,只需要知道在哪些情况下定义索引即可,定义之后,系统自动维护索引,不需人为干预。
索引使用情况:
1.有大量记录且查询频繁但更新很少的列
2.值较多的属性列
3.有大量记录的聚集函数列
索引的定义:
语法:
create [unique|clustered|nonclustered]index index_name
on table|view_name(column1 desc|asc,column2 ...)
例子:
为student表的name属性创建非唯一非聚集索引
代码:
use student
go
create index name_index
on student(name)
效果:
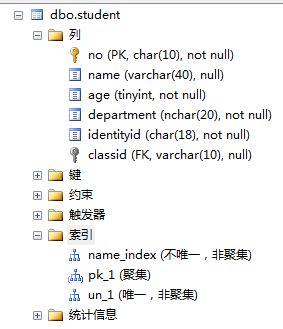
索引的查看:
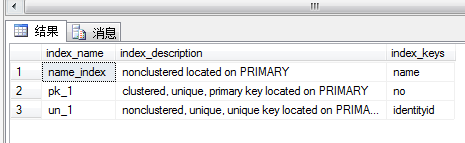
使用系统存储过程sp_index 表名 即可查看index相关信息
代码:
use student
go
exec sp_helpindex student
效果:
索引的删除:
语法:
drop index table_name.index_name
代码:
use student
go
drop index student.name_index
效果:
您的赞助将是我不断创作的最大动力,谢谢支持!!!
如果您觉得我的文章对您有帮助,可以通过以下方式进行赞赏:

发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/163047.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...