大家好,又见面了,我是你们的朋友全栈君。
CSV 文件
CSV(comma-separated value,逗号分隔值)文件格式是一种非常简单的数据存储与分享方式。CSV 文件将数据表格存储为纯文本,表格(或电子表格)中的每个单元格都是一个数值或字符串。与 Excel 文件相比,CSV 文件的一个主要优点是有很多程序可以存储、转换和处理纯文本文件;相比之下,能够处理 Excel 文件的程序却不多。所有电子表格程序、文字处理程序或简单的文本编辑器都可以处理纯文本文件,但不是所有的程序都能处理 Excel 文件。尽管 Excel 是一个功能非常强大的工具,但是当你使用 Excel 文件时,还是会被局限在 Excel 提供的功能范围内。CSV 文件则为你提供了非常大的自由,使你在完成任务的时候可以选择合适的工具来处理数据——如果没有现成的工具,那就使用 Python 自己开发一个!
当你使用 CSV 文件时,确实会失去某些 Excel 功能:在 Excel 电子表格中,每个单元格都有一个定义好的“类型”(数值、文本、货币、日期等),CSV 文件中的单元格则只是原始数据。幸好,Python 在识别不同数据类型方面相当聪明。使用 CSV 文件的另一个问题是它只能保存数据,不能保存公式。但是,通过将数据存储(CSV 文件)和数据处理(Python 脚本)分离,你可以很容易地在不同数据集上进行加工处理。当数据存储和数据处理过程分开进行时,错误(不管是数据处理中的错误,还是数据存储中的错误)不但更容易被发现,而且更难扩散。
要使用 CSV 文件开始工作,需要先创建一个 CSV 文件,你可以从以下地址https://github.com/cbrownley/foundations-for-analytics-with-python/blob/master/csv/supplier_data.csv下载这个文件,步骤如下。
(1) 打开一个新的电子表格,向其中加入数据,如图 2-1 所示。
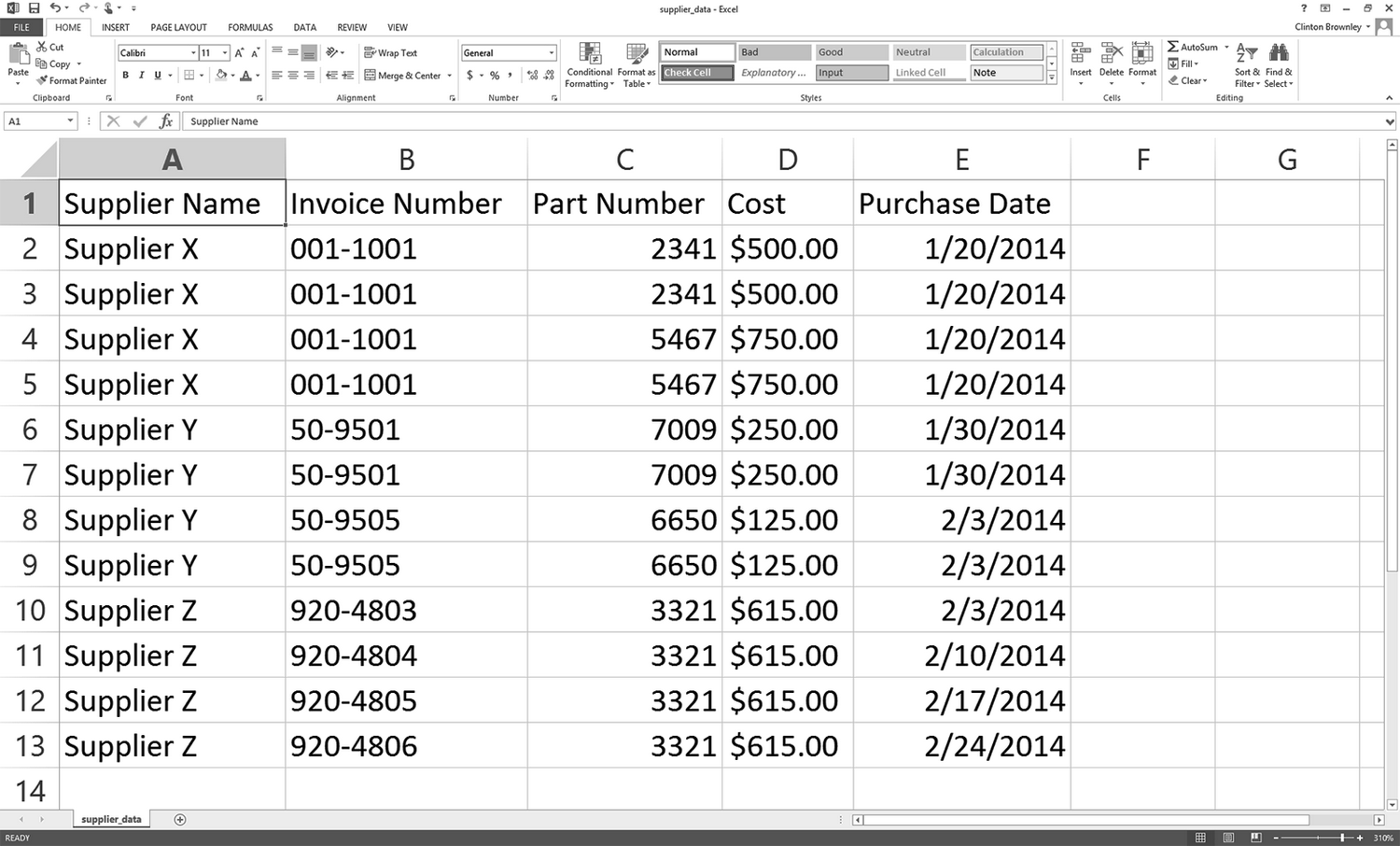

图 2-1:向 supplier_data.csv 文件中添加数据
(2) 将文件保存在桌面上,文件名为 supplier_data.csv。
要确认 supplier_data.csv 确实是纯文本文件。
(1) 将所有打开的窗口最小化,在桌面上找到 supplier_data.csv。
(2) 在文件上点击鼠标右键。
(3) 选择“Open with”,然后选择一个文本编辑器,如 Notepad、Notepad++ 或 Sublime Text。
当你在文本编辑器中打开这个文件时,它看上去应该如图 2-2 所示。
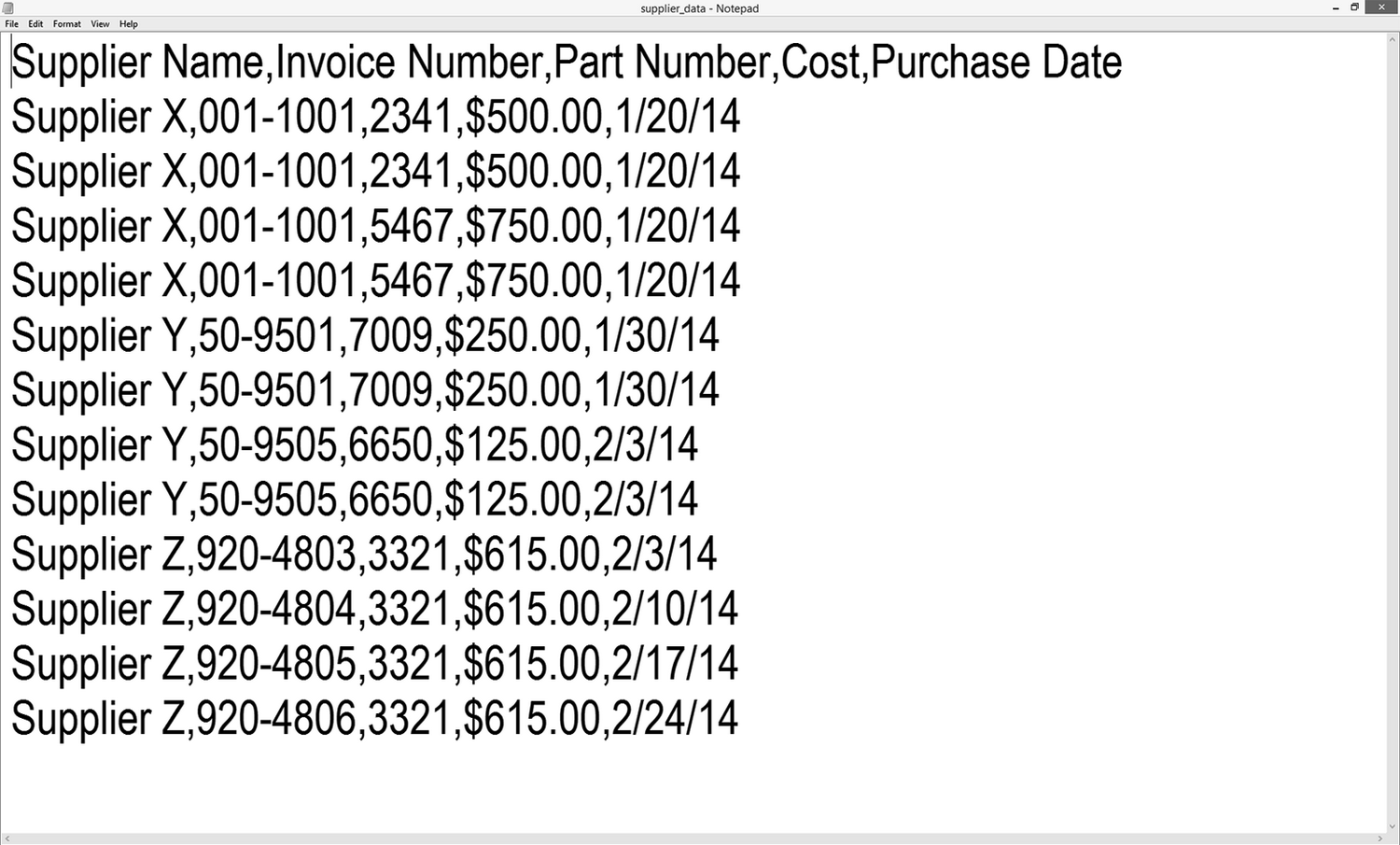
图 2-2:Notepad 中的 supplier_data.csv 文件
正如你所看到的,这个文件是一个简单的纯文本文件。每行包含 5 个由逗号分隔的值。对这种文件的另一种理解是由逗号划定了 Excel 电子表格中的 5 列。现在你可以关闭这个文件了。
基础Python与pandas
前言中曾提到过,提供两种版本的代码来完成具体的数据处理任务。第一种代码版本展示了如何使用基础 Python 来完成任务。第二种版本展示了如何使用 pandas 来完成任务。你会看到,使用 pandas 完成任务相对来说更容易,需要的代码更少。所以,如果你已经理解了 pandas 简化了的编程概念和操作,只是要简单完成任务的话,pandas 版的代码就非常有用。但是,先介绍基础 Python 版本的代码,以使你学会如何使用通用的编程概念和操作来完成任务。通过介绍两种代码版本,希望可以给你如下选择:一是使用 pandas 快速完成任务;二是学习通用的编程技能,并在提高编码能力的基础上获得解决问题的能力。
读写CSV文件
基础Python,不使用csv模块
现在开始学习如何使用基础 Python 代码来读写和处理 CSV 文件(不使用内置的 csv 模块)。先看看下面的示例代码,然后当你使用 csv 模块时,就会知道代码在幕后都做了些什么。
要处理 CSV 文件,先新建一个 Python 脚本,名为 1csv_read_with_simple_parsing_and_write.py。
在 Spyder 或一个文本编辑器中输入下列代码:
1 #!/usr/bin/env python3
2 import sys
3
4 input_file = sys.argv[1]
5 output_file = sys.argv[2]
6
7 with open(input_file, 'r', newline='') as filereader:
8 with open(output_file, 'w', newline='') as filewriter:
9 header = filereader.readline()
10 header = header.strip()
11 header_list = header.split(',')
12 print(header_list)
13 filewriter.write(','.join(map(str,header_list))+'\n')
14 for row in filereader:
15 row = row.strip()
16 row_list = row.split(',')
17 print(row_list)
18 filewriter.write(','.join(map(str,row_list))+'\n')
在桌面上,将程序保存为 1csv_read_with_simple_parsing_and_write.py。
图 2-3、图 2-4 和图 2-5 分别展示了使用 Anaconda Spyder、Notepad++(Windows)和 TextWrangler(macOS)编写脚本的界面。
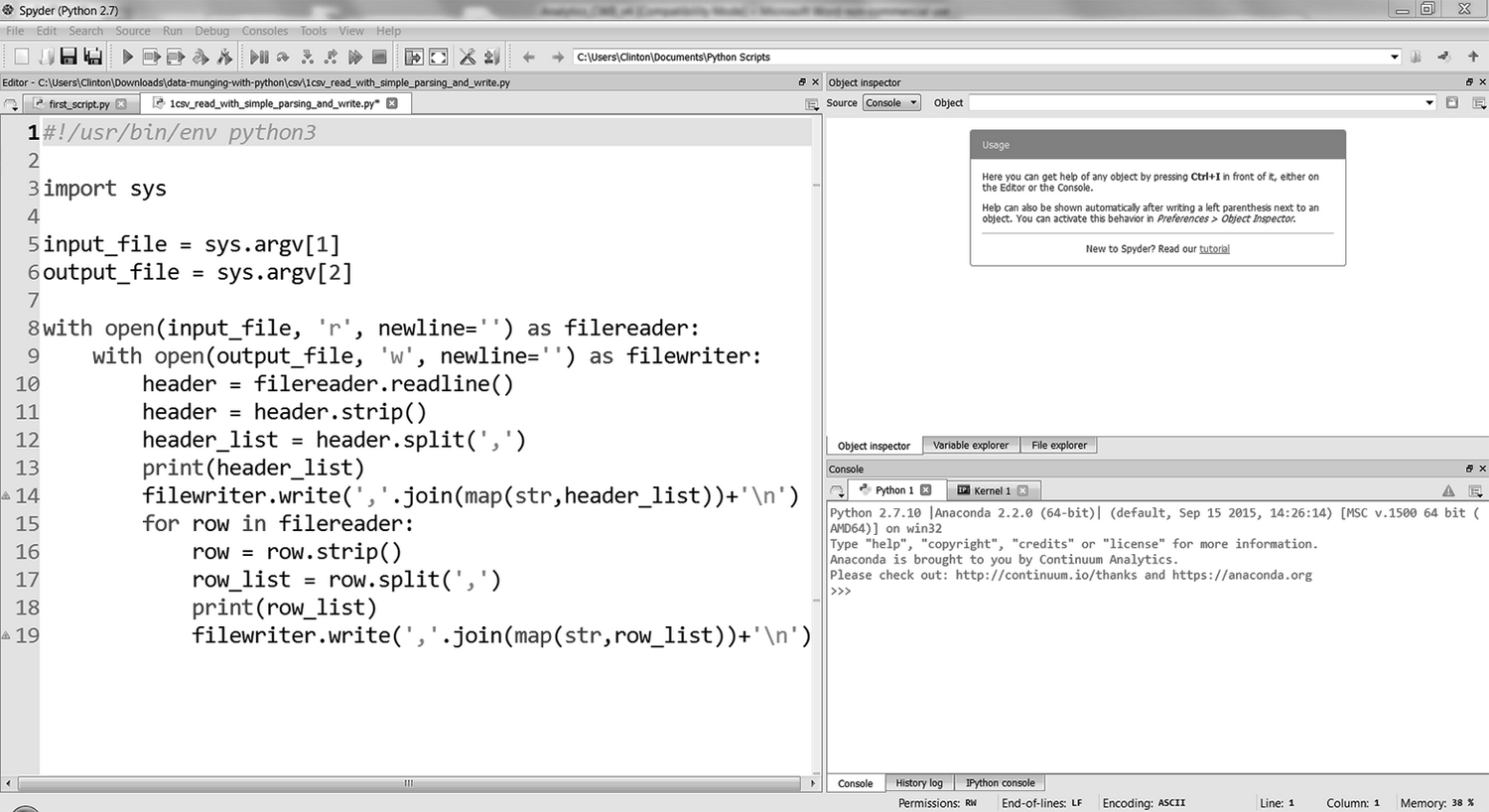
图 2-3:Anaconda Spyder 中的 Python 脚本 1csv_read_with_simple_parsing_and_write.py
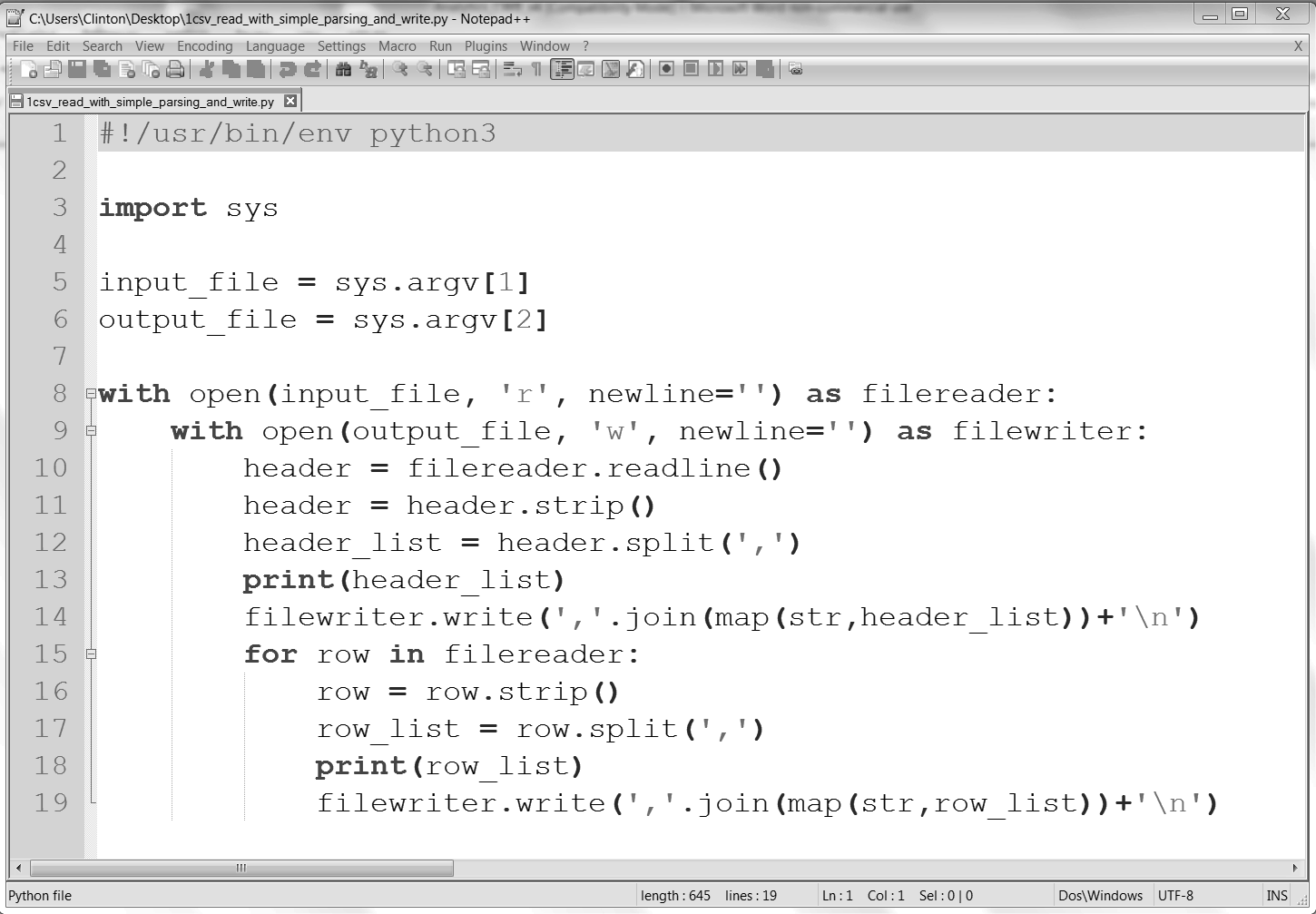
图 2-4:Notepad++(Windows)中的 Python 脚本 1csv_read_with_simple_parsing_and_write.py
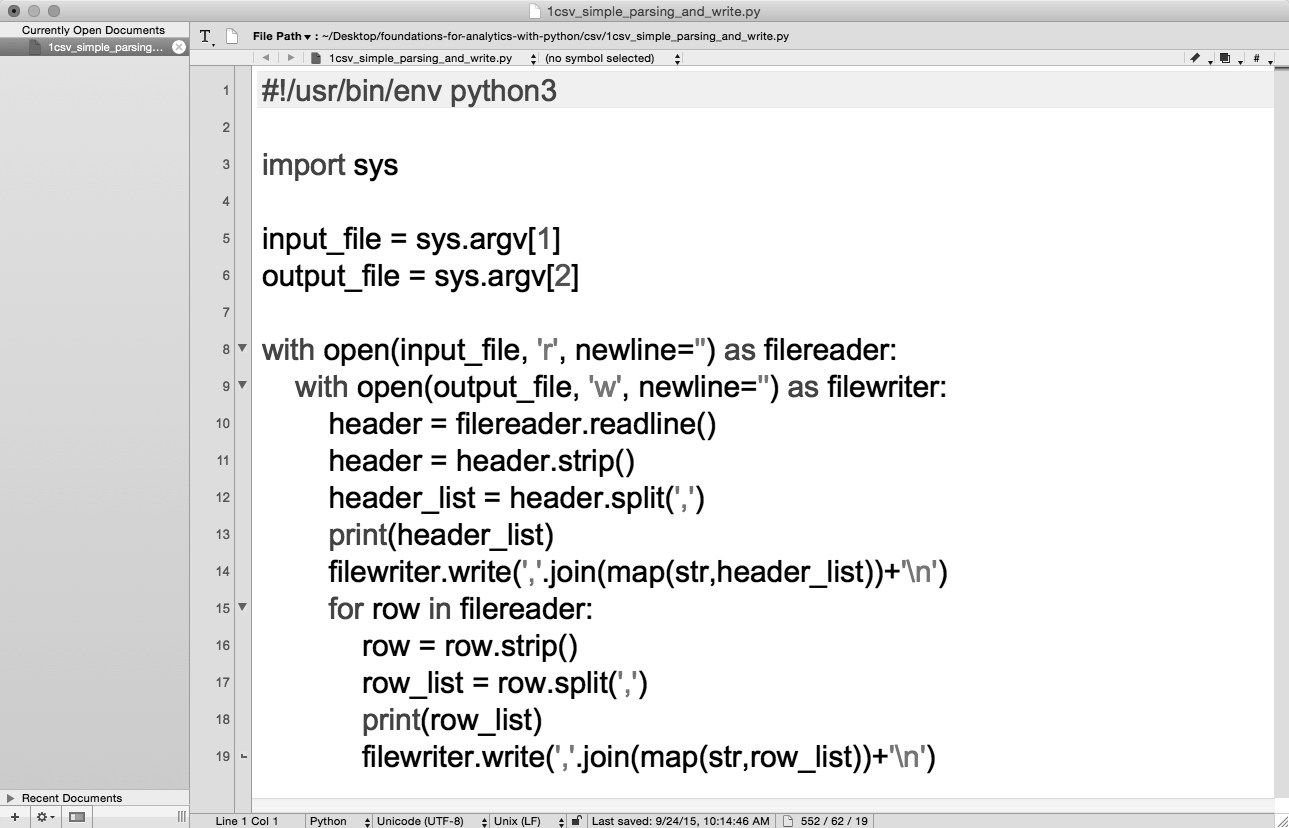
图 2-5:TextWrangler(macOS)中的 Python 脚本 1csv_read_with_simple_parsing_and_write.py
在运行脚本并查看输出之前,先研究一下脚本中的代码想做些什么。这里将按照顺序依次讨论每个代码块(下面提到的行编号指的是屏幕截图中的行编号)。
#!/usr/bin/env python3
import sys
第 1 行是注释行,可以使脚本在不同的操作系统之间具有可移植性。第 3 行代码导入 Python 内置的 sys 模块,可以使你在命令行窗口中向脚本发送附加的输入。
input_file = sys.argv[1]
output_file = sys.argv[2]
第 5 和 6 行代码使用 sys 模块的 argv 参数,它是一个传递给 Python 脚本的命令行参数列表,也就是当你运行脚本时在命令行中输入的内容。下面给出了一个在 Windows 系统中使用命令行参数读取 CSV 格式的输入文件和写入 CSV 格式的输出文件的例子:
python script_name.py "C:\path\to\input_file.csv" "C:\path\to\output_file.csv"
第一个词 python 告诉计算机使用 Python 程序来处理其余的命令行参数。Python 收集其余的参数,放入 argv 这个特殊的列表中。列表中的第一个元素 argv[0] 用作脚本名称,所以 argv[0] 表示 script_name.py。下一个命令行参数是 “C:\path\to\input_file.csv”,即 CSV 输入文件的路径和文件名。Python 将这个参数保存在 argv[1] 中,所以脚本第 5 行代码将这个值赋给变量 input_file。最后一个命令行参数是 “C:\path\to\output_file.csv”,即 CSV 输出文件的路径和文件名。Python 将这个参数保存在 argv[2] 中,第 6 行代码把这个值赋给了变量 output_file。
with open(input_file, 'r', newline='') as filereader:
with open(output_file, 'w', newline='') as filewriter:
第 8 行代码是一个 with 语句,将 input_file 打开为一个文件对象 filereader。‘r’ 表示只读模式,说明打开 input_file 是为了读取数据。第 9 行代码是另一个 with 语句,将 output_file 打开为一个文件对象 filewriter。‘w’ 表示可写模式,说明打开 output_file 是为了写入数据。with 语句非常有用,因为它可以在语句结束时自动关闭文件对象。
header = filereader.readline()
header = header.strip()
header_list = header.split(',')
第 10 行代码使用文件对象的 readline 方法读取输入文件中的第一行数据,在本例中,第一行是标题行,读入后将其作为字符串并赋给名为 header 的变量。第 11 行代码使用 string 模块中的 strip 函数去掉 header 中字符串两端的空格、制表符和换行符,并将处理过的字符串重新赋给 header。第 12 行代码使用 string 模块的 split 函数将字符串用逗号拆分成列表,列表中的每个值都是一个列标题,最后将列表赋给变量 header_list。
print(header_list)
filewriter.write(','.join(map(str,header_list))+'\n')
第 13 行代码是一个 print 语句,将 header_list 中的值(也就是列标题)打印到屏幕上。
第 14 行代码使用 filewriter 对象的 write 方法将 header_list 中的每个值写入输出文件。因为这行代码比较复杂,所以需要仔细说明一下。map 函数将 str 函数应用于 header_list 中的每个元素,确保每个元素都是字符串。然后,join 函数在 header_list 中的每个值之间插入一个逗号,将这个列表转换为一个字符串。在此之后,在这个字符串最后添加一个换行符。最后,filewriter 对象将这个字符串写入输出文件,作为输出文件的第一行。
for row in filereader:
row = row.strip()
row_list = row.split(',')
print(row_list)
filewriter.write(','.join(map(str,row_list))+'\n')
第 15 行代码创建了一个 for 循环,在输入文件剩余的各行中迭代。第 16 行代码使用 strip 函数除去每行字符串两端的空格、制表符和换行符,然后将处理过的字符串重新赋给变量 row。第 17 行使代码用 split 函数用逗号将字符串拆分成一个列表,列表中的每个值都是这行中某一列的值,然后,将列表赋给变量 row_list。第 18 行代码将 row_list 中的值打印到屏幕上。第 19 行代码将这些值写入输出文件。
脚本对输入文件中的每一行数据都执行第 16~19 行代码,因为这 4 行代码在第 15 行代码中的 for 循环下面是缩进的。
你可以在命令行窗口或终端窗口中通过运行脚本做一下测试。如下所示。
- 命令行窗口(Windows)
(1) 打开一个命令行窗口。
(2) 切换到桌面(你存放 Python 脚本的地方)。
要完成这个操作,输入以下命令,然后按回车键:
cd "C:\Users\[Your Name]\Desktop"
(3) 运行 Python 脚本。
要完成这个操作,输入以下命令,然后按回车键:
python 1csv_simple_parsing_and_write.py supplier_data.csv\
output_files\1output.csv
- 终端窗口(macOS)
(1) 打开一个终端窗口。
(2) 切换到桌面(你存放 Python 脚本的地方)。
要完成这个操作,输入以下命令,然后按回车键:
cd /Users/[Your Name]/Desktop
(3) 为 Python 脚本添加可执行权限。
要完成这个操作,输入以下命令,然后按回车键:
chmod +x 1csv_simple_parsing_and_write.py
(4) 运行 Python 脚本。
要完成这个操作,输入以下命令,然后按回车键:
./1csv_simple_parsing_and_write.py supplier_data.csv\
output_files/1output.csv
如图 2-6 所示,你会看到输出被打印到命令行窗口或终端窗口中。
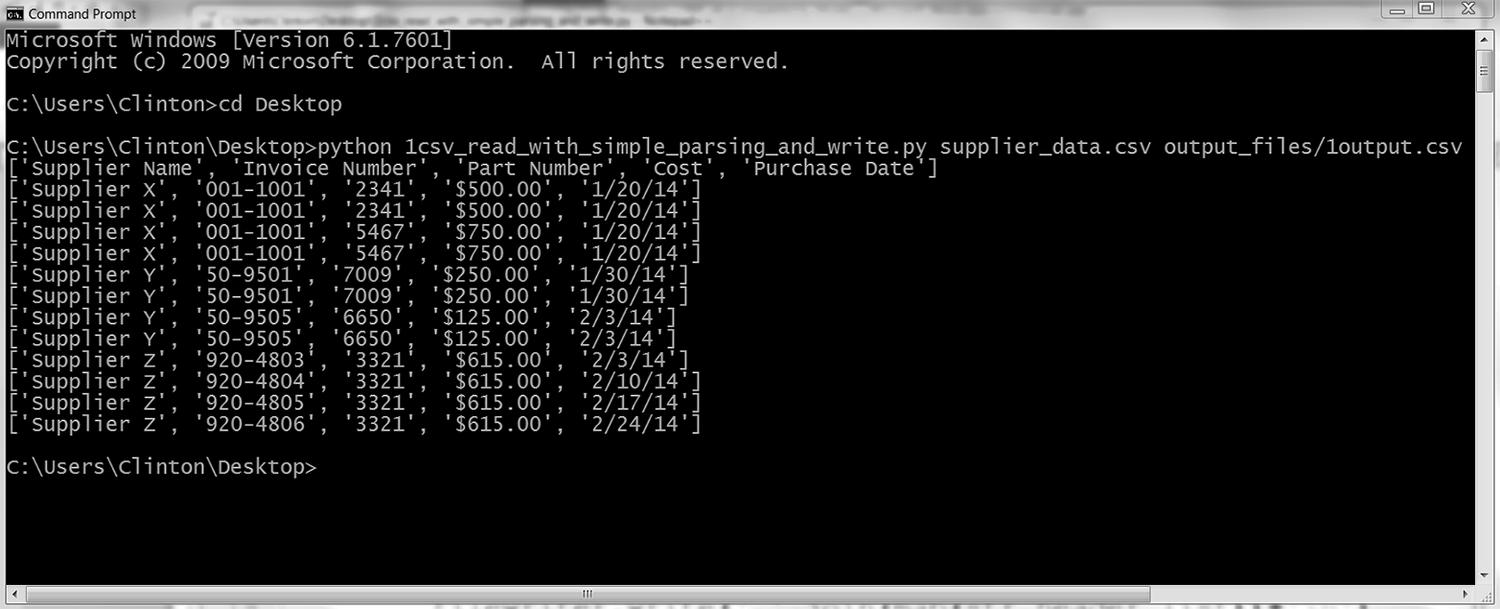
图 2-6:运行 Python 脚本 1csv_read_with_simple_parsing_and_write.py 的输出结果
输入文件中的所有行都被打印到了屏幕上,也被写入了输出文件。在多数情况下,你不需要将输入文件中的所有数据重新写到输出文件中,因为输入文件中就有所有的数据。但是这个例子仍然是非常有用的,因为你可以参考例子中的代码,将 filewriter.write 语句嵌入到带有判断条件的业务逻辑中,确保你只将需要的某些行写入输出文件。
pandas
要使用 pandas 处理 CSV 文件,在文本编辑器中输入下列代码,并将文件保存为 pandas_parsing_and_write.py(这个脚本读取 CSV 文件,在屏幕上打印文件内容,并将内容写入一个输出文件):
#!/usr/bin/env python3
import sys
import pandas as pd
input_file = sys.argv[1]
output_file = sys.argv[2]
data_frame = pd.read_csv(input_file)
print(data_frame)
data_frame.to_csv(output_file, index=False)
要运行这个脚本,在命令行中输入以下命令,命令在不同的操作系统中会有些差别。
- Windows 操作系统
python pandas_parsing_and_write.py supplier_data.csv\
output_files\pandas_output.csv
- macOS 操作系统
- chmod +x pandas_parsing_and_write.py ./pandas_parsing_and_write .py
supplier_data.csv\ output_files/pandas_output.csv
你会注意到在 pandas 版的脚本中,创建了一个变量 data_frame。同列表、字典与元组相似,数据框也是存储数据的一种方式。数据框中保留了“表格”这种数据组织方式,不需要使用列表套列表的方式来分析数据。数据框包含在 pandas 包中,如果你不在脚本中导入 pandas,就不能使用数据框。将变量命名为 data_frame,就像使用变量名 list 一样,在学习阶段,这样做是可以的,但是以后,你应该使用更有描述性的变量名。
- 脏数据
现实世界中,数据通常是“脏”的。有些值会因为某些原因而缺失,手工输入或传感器出错都可以造成数据错误。某些情况下,人们会故意记下错误的数据,因为只能这样做。我曾经见过在餐厅收据中,将乐啤露记为“可乐(加奶酪)”,因为结账系统中没有“乐啤露”这个选项,所以使用系统的店员就加入了这个订单选项,并告知了订餐员和打饮料的服务员。但是这样一来,负责跟踪库存和订货的管理人员就有一大堆奇怪的数据需要核实了。
在电子表格数据中,你也会遇到这样的问题,并想出解决的办法。示例代码时,也要注意这种情况。请记住每个人都会遇到“脏”数据的问题,这是数据分析工作中最令人头疼也是最令人兴奋的部分,通常也是工作量最大的部分,这是必须要做的工作!
基本字符串分析是如何失败的
基本的 CSV 分析失败的一个原因是列中包含额外的逗号。打开 supplier_data.csv,将 Cost 列中的最后两个成本数量分别改为 $6,015.00 和 $1,006,015.00。做完这两个修改之后,输入文件应如图 2-7 所示。
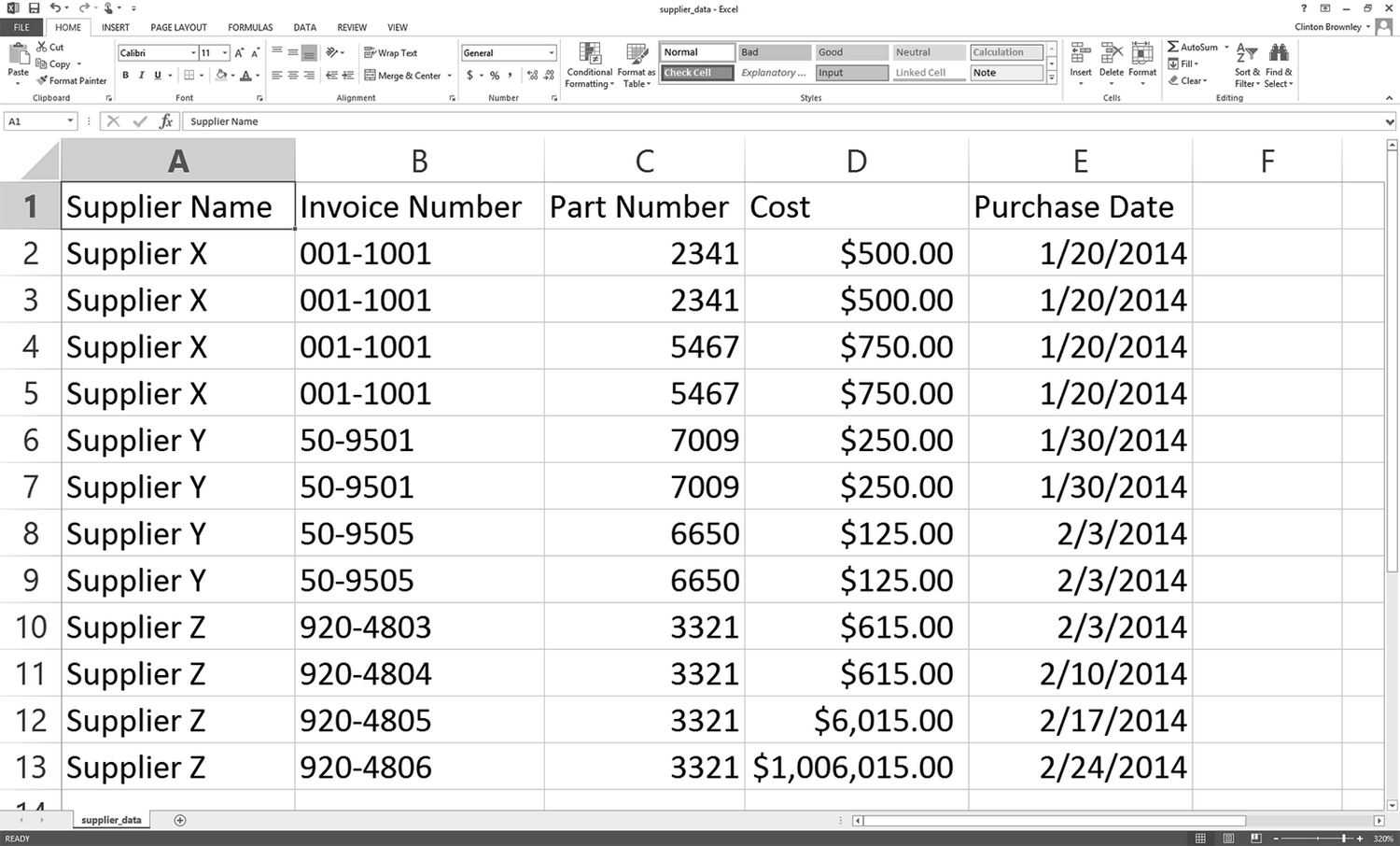
图 2-7:修改后的输入文件(supplier_data.csv)
修改了输入文件之后,要看看你的简单的分析脚本如何失败,需要在修改后的新输入文件上重新运行脚本。保存修改后的文件,然后按向上箭头键,找到之前运行过的命令,或者重新输入以下命令,然后按回车键:
python 1csv_simple_parsing_and_write.py supplier_data.csv\
output_files\1output.csv
你会看到输出被打印到屏幕上,如图 2-8 所示。
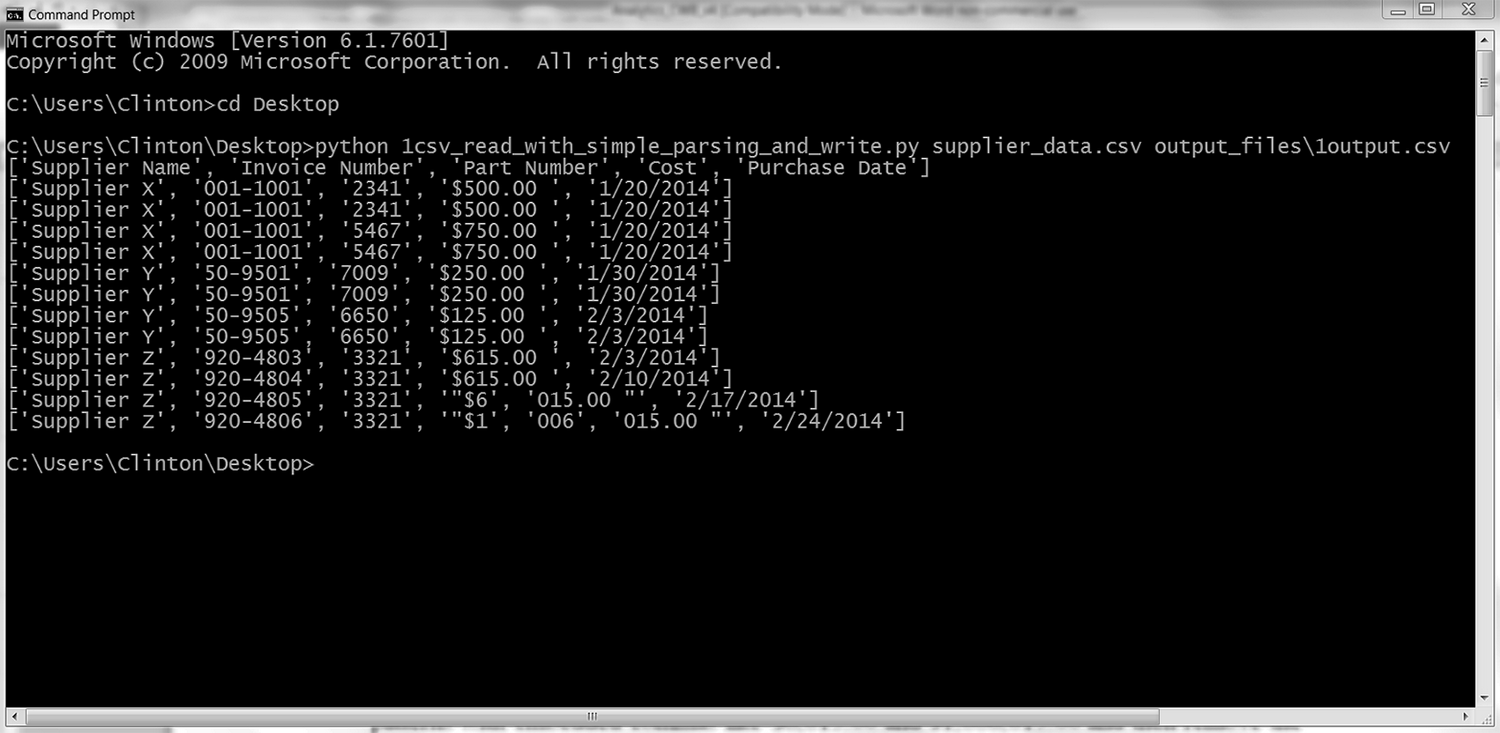
图 2-8:在修改后的 supplier_data.csv 上运行脚本
你可以看到,这里的脚本是按照行中的逗号分析每行数据的。此脚本对标题行和前 10 个数据行的处理都是正确的,因为它们没有嵌入到数据中的逗号。但是,脚本错误地拆分了最后两行,因为数据中有逗号。
有许多方法可以改进这个脚本中的代码,处理包含逗号的数值。例如,可以使用正则表达式来搜索带有嵌入逗号的模式,就像 $6,015.00 和 $1,006,015.00,然后删除这些值中的逗号,再使用余下的逗号来拆分行。但是,为了不使脚本复杂化,可以使用 Python 内置的 csv 模块,设计这个模块的目的就是为了方便灵活地处理复杂的 CSV 文件。
读写CSV文件(第2部分)
基础Python,使用csv模块
使用 Python 内置的 csv 模块处理 CSV 文件的一个优点是,这个模块就是被设计用于正确处理数据值中的嵌入逗号和其他复杂模式的。它可以识别出这些模式并正确地分析数据,所以你不需要仅仅为了正确处理数据而花费时间来设计正则表达式和条件逻辑,可以将节省的时间用来管理数据、执行计算和写入输出。
接下来导入 Python 内置的 csv 模块并用它来处理包含数值 $6,015.00 和 $1,006,015.00 的输入文件。你将学会如何使用 csv 模块,并理解它是如何处理数据中的逗号的。
在文本编辑器中输入以下代码,并将文件保存为 2csv_reader_parsing_and_write.py:
1 #!/usr/bin/env python3
2 import csv
3 import sys
4 input_file = sys.argv[1]
5 output_file = sys.argv[2]
6 with open(input_file, 'r', newline='') as csv_in_file:
7 with open(output_file, 'w', newline='') as csv_out_file:
8 filereader = csv.reader(csv_in_file, delimiter=',')
9 filewriter = csv.writer(csv_out_file, delimiter=',')
10 for row_list in filereader:
11 print(row_list)
12 filewriter.writerow(row_list)
你可以看到,上面大部分代码与前一个脚本中的代码非常相似。所以,这里只讨论那些有明显区别的代码。
第 2 行代码导入 csv 文件,以便可以使用其中的函数来分析输入文件,写入输出文件。
第 8 行代码,就是在第二个 with 语句下面的那行代码,使用 csv 模块中的 reader 函数创建了一个文件读取对象,名为 filereader,可以使用这个对象来读取输入文件中的行。同样,第 9 行代码使用 csv 模块的 writer 函数创建了一个文件写入对象,名为 filewriter,可以使用这个对象将数据写入输出文件。这些函数中的第二个参数(就是 delimiter=’,’)是默认分隔符,所以如果你的输入文件和输出文件都是用逗号分隔的,就不需要指定这个参数。这里指定了这个分隔符参数,是为了防备你处理的输入文件或要写入的输出文件具有不同的分隔符,例如,分号(;)或制表符(\t)。
第 12 行代码使用 filewriter 对象的 writerow 函数来将每行中的列表值写入输出文件。
假设输入文件和 Python 脚本都保存在你的桌面上,你也没有在命令行或终端行窗口中改变目录,在命令行中输入以下命令,然后按回车键运行脚本(如果你使用 Mac,需要对新的脚本先运行 chmod 命令,使它成为可执行的):
python 2csv_reader_parsing_and_write.py supplier_data.csv\
output_files\2output.csv
你可以看到输出被打印到屏幕上,如图 2-9 所示。
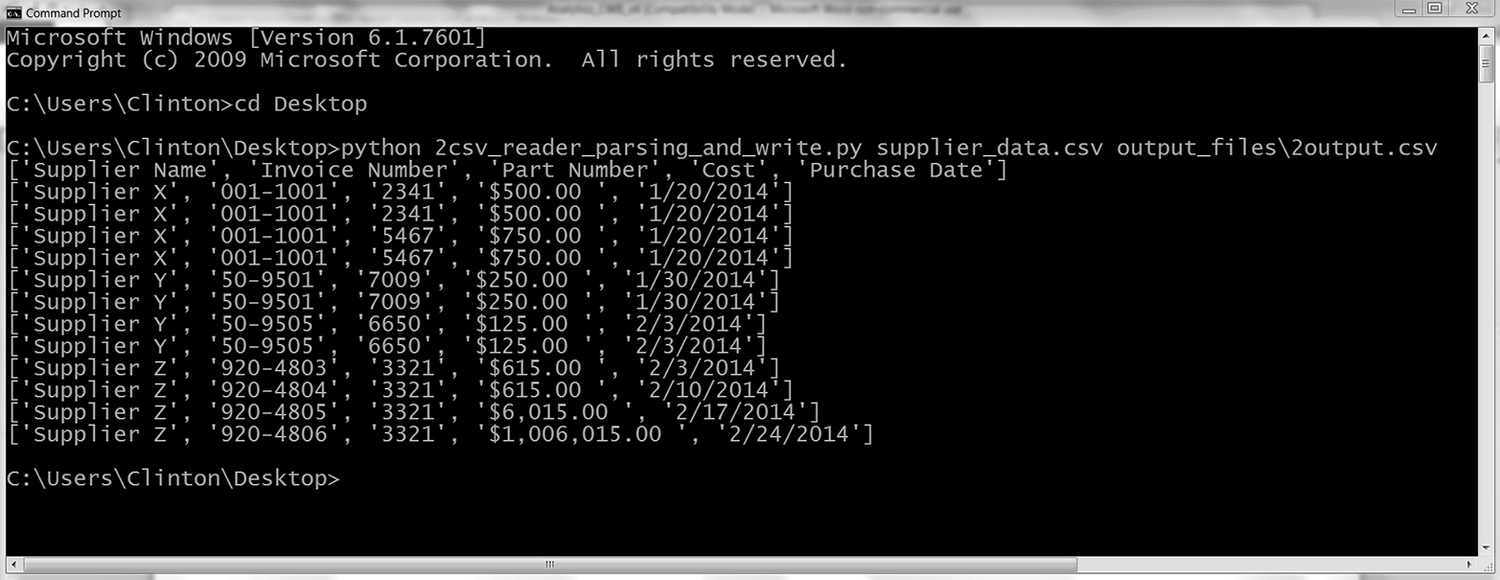
图 2-9:运行 Python 脚本得到的输出
输入文件中的所有行都被打印到了屏幕上,同时被写入到输出文件。你可以看到,Python 内置的 csv 模块处理了嵌入数据的逗号问题,正确地将每一行拆分成了 5 个值。
我们知道了如何使用 csv 模块来读取、处理和写入 CSV 文件,下面开始学习如何筛选出特定的行以及如何选择特定的列,以便可以有效地抽取出需要的数据。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/162506.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
