大家好,又见面了,我是你们的朋友全栈君。
CNN卷积神经网络原理详解(上)
前言
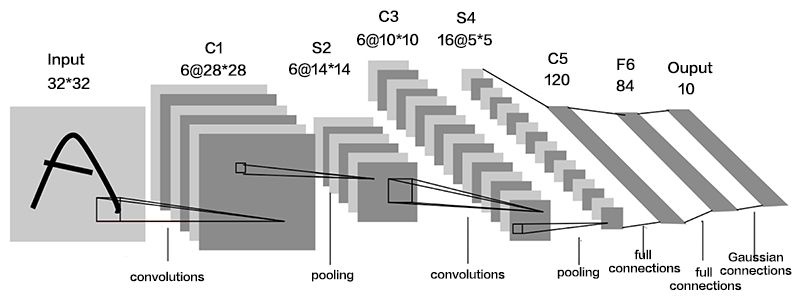
卷积网络(convolutional network),也叫作卷积神经网络(convolutional neural network,CNN),是一种专门用来处理具有类似网格结构的数据的神经网络。卷积网络在诸多应用领域都表现优异。‘卷积神经网络’一词表明该网络使用了卷积(convolutional)这种数学运算。卷积神经网络的运作模式如下图所示:
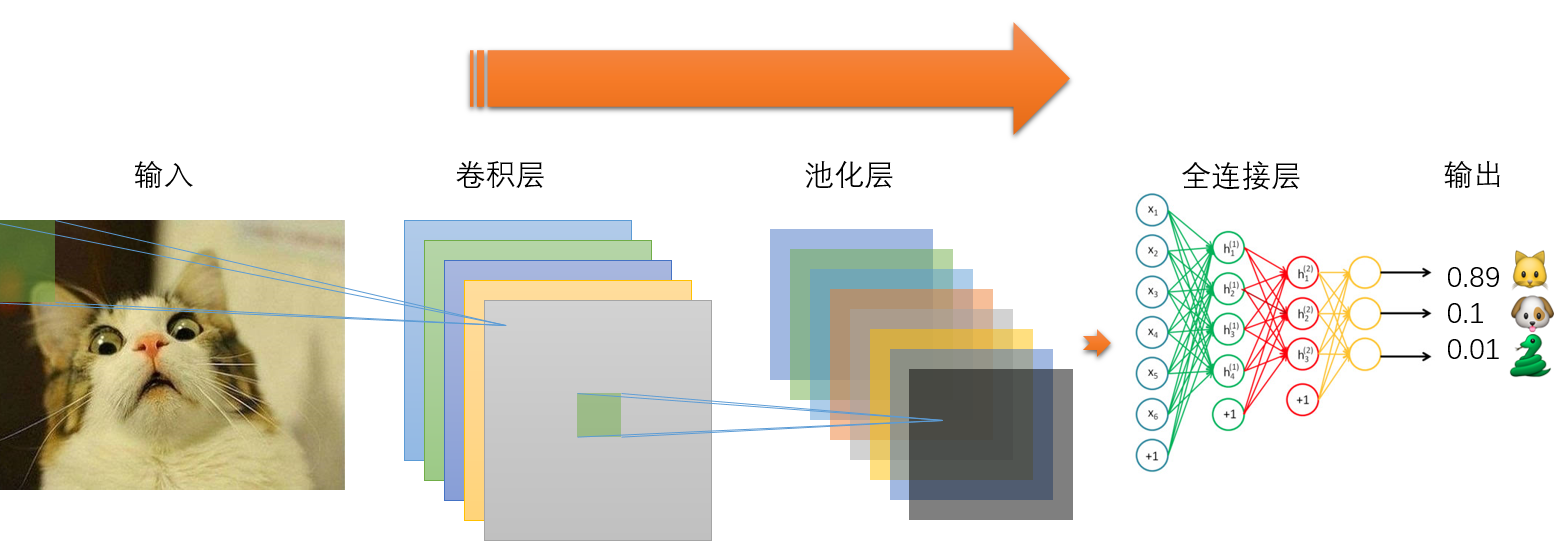

上图只是一个卷积神经网络的基本构成,其中卷积层和池化层可以根据实际情况任意增加。当前卷积神经网络的应用场合非常广泛,比如图像识别,自然语言处理,灾难性气候预测甚至围棋人工智能等,但是最主要的应用领域还是图像识别领域。
那么问题来了,为什么要用卷积神经网络来做这个事情呢?
卷积神经网络的生物背景
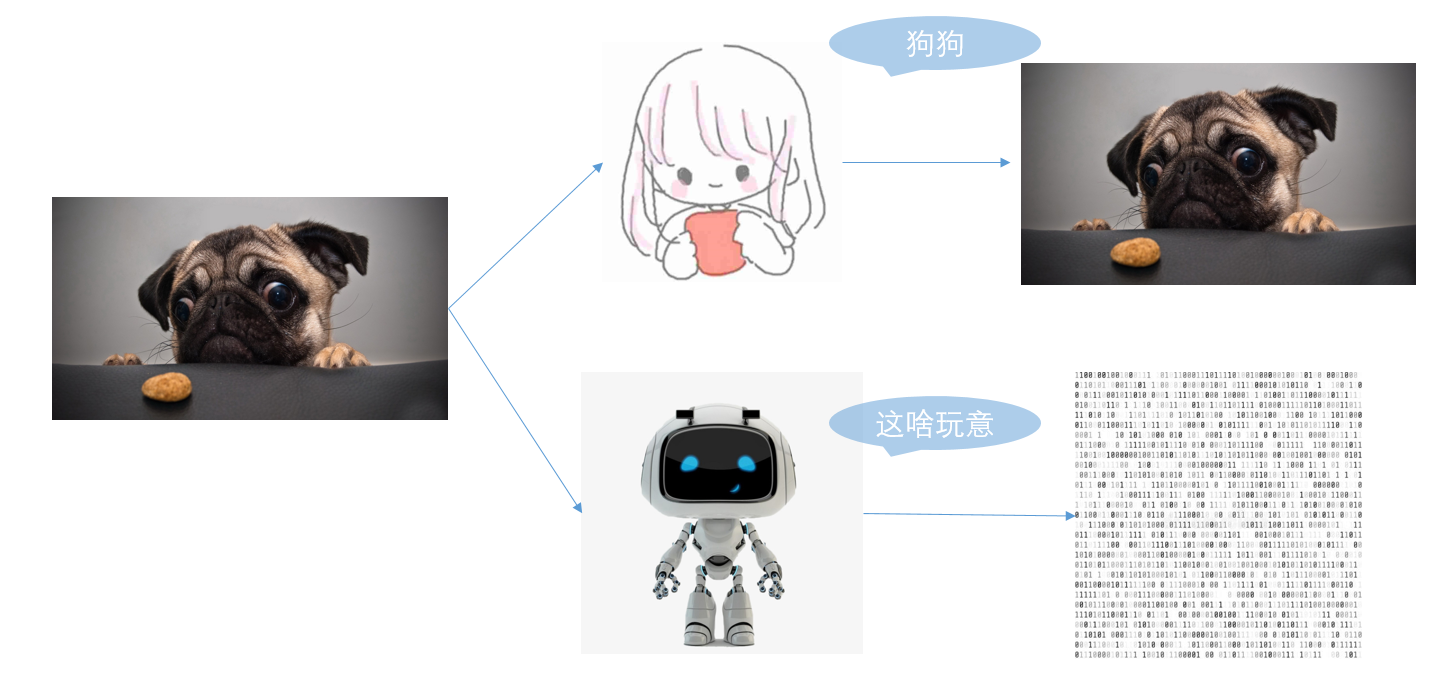
如上图所示,人看到的图像,经过大脑的处理,最后呈现给我们的就是这个图像本身,而电脑看到的图像,实际上是一堆像素点的集合。面对这堆像素点,电脑并不知道这是个什么东西。那么我们需要电脑做什么呢?当然是让电脑辨认出这堆像素点所代表的那个图像。怎么做呢?伟大的科学家们这里借鉴了神经生物学家对猫在观察事物时候大脑皮层的工作原理提出了神经网络的概念。
关于这个实验,网上和参考书上有详细介绍,这里总结就是,大脑皮层不同部位对外界刺激的敏感程度、反应程度不同。这就很好的启发了神经网络的计算核心,不断的寻找特征点,最终得出输入的到底是什么图像这个问题。
我们要让计算机做什么?
我们以图像为例,假定当我们的计算机看到一幅图片的时候,它实际上看到的是一组像素值。根据图像的分辨率和大小,假定它看到的是32x32x3的数组,这里的3代表这是一幅RGB的彩色图像。其中每一个数字的值都是0到255不等,代表了像素值的强弱。这些数字对于我们进行图像分类时毫无意义,这是计算机唯一可用的输入。这个想法是,你给计算机这个数组的输入,它最终会输出数字,描述了图像是一个类的概率(0.85为猫,0.1为狗,0.05为鸟等)。
现在我们知道这个问题以及输入和输出了,我们来思考如何解决这个问题。我们希望计算机做的是能够区分所有的图像,并找出使狗成为狗或使猫成为猫的独特功能。这也是下意识地在我们的脑海中继续的过程。当我们看一张狗的照片时,如果照片具有可识别的特征,例如爪子或四条腿,我们可以将其分类。以类似的方式,计算机能够通过查找诸如边缘和曲线等低级特征来执行图像分类,然后通过一系列卷积层来构建更抽象的概念。这是一个CNN的一般概述。我们来详细说明一下。
回到具体细节。有关CNN做的更详细的概述是,您将图像传递给一系列卷积,非线性,汇聚(下采样)和完全连接的图层,并获得输出。正如我们前面所说的那样,输出可以是一个类或者一个最能描述图像的类的概率。那么问题来了,每一层计算机都做了什么呢?
卷积网络第一层
这一层的理论意义
卷积网络的第一层一定是一个卷积层,在研究卷积层是干啥的之前我们首先要明确的是这一层我们的输入是上文提到的图像的像素数值组。现在回到我们的问题,卷积层是干啥的。卷积层就是从这个像素数值组中提取最基本的特征。如何提取呢?我们假定输入的图像是一个32x32x3的数组,我们用一个5x5x3(最后乘以3是为了在深度上保持和输入图像一致,否则数学上无法计算)的模板沿着图像的左上角一次移动一个格子从左上角一直移动到右下角。输入的图像数组我们称为接受域,我们使用的模板叫做滤波器(也叫卷积核)。滤波器也是由数组组成,其中每个数字称为权重。输入的数组经过这一轮卷积输出的数组大小为28×28(32-5+1),深度由卷积核的数量决定。这个过程如下图所示:
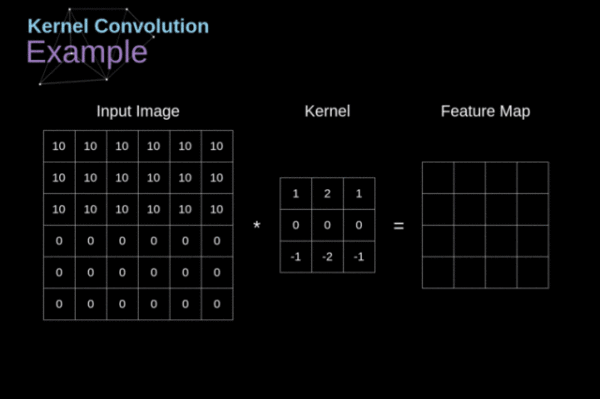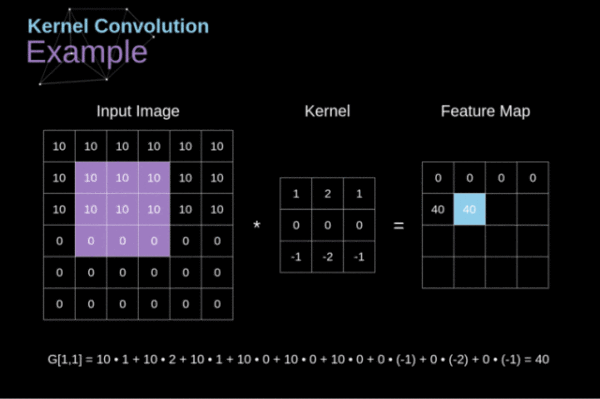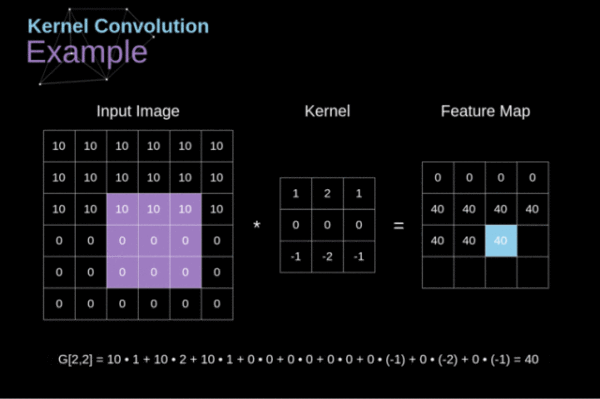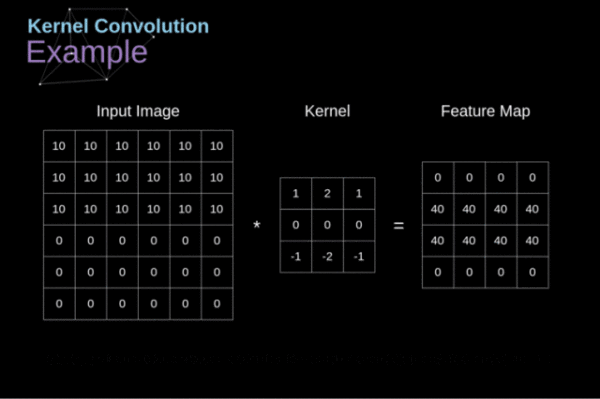
这一层的实际意义
但是,让我们从高层次谈论这个卷积实际上在做什么。每个这些过滤器都可以被认为是功能标识符。当我说功能时,我正在谈论的是直线边缘,简单的颜色和曲线。想想所有图像的共同点,最简单的特点。假设我们的第一个过滤器是5 x 5 x 3并且将成为曲线检测器。(在本节中,为了简单起见,让我们忽略过滤器深度为3单位的事实,并且只考虑过滤器和图像的顶部深度切片)。作为曲线检测器,过滤器将具有像素结构,沿曲线形状的区域是更高的数值(请记住,我们正在讨论的这些滤波器只是数字!)。
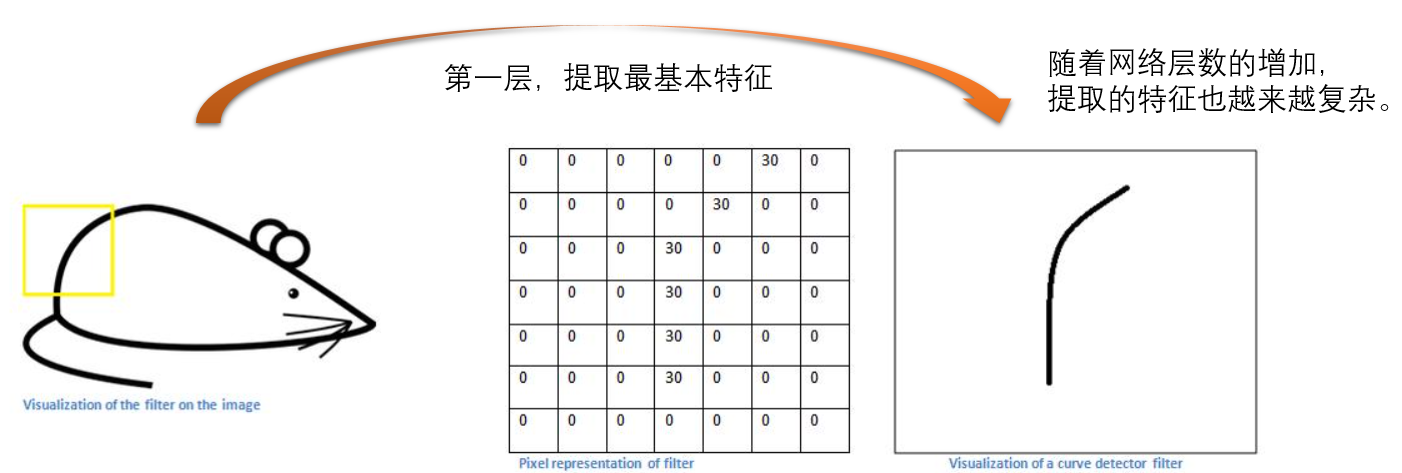
全连接层
这个图层基本上需要一个输入量(无论输出是在其之前的conv或ReLU还是pool层),并输出一个N维向量,其中N是程序必须从中选择的类的数量。例如,如果你想要一个数字分类程序,N将是10,因为有10个数字。这个N维向量中的每个数字表示某个类别的概率。例如,如果用于数字分类程序的结果向量是[0.1.175 0 0 0 0 0 .05],那么这代表10%的概率,即图像是1,10%的概率图像是2,图像是3的概率是75%,图像是9的概率是5%(注意:还有其他方法可以表示输出,但我只是展示了softmax方法)。完全连接图层的工作方式是查看上一层的输出(我们记得它应该代表高级特征的激活图),并确定哪些特征与特定类最相关。例如,如果程序预测某些图像是狗,则在激活图中将具有高值,例如爪子或4条腿等的高级特征。类似地,如果程序预测某图像是鸟,它将在激活地图中具有很高的价值,代表像翅膀或喙等高级特征。基本上,FC层看着什么高级特征与特定类最强关联,并具有特定的权重,以便当你计算权重与上一层之间的乘积。
训练
在我们搭建完毕神经网络的结构之后,我们需要对这个网络进行训练。训练的过程就是给这个网络模型不断的提供任务,让模型在执行任务的过程中积累经验,最终对类似的事件可以做出正确的判断。通俗的解释就是,假设我们教导一个小孩子认识狗,我们会给他看各种各样的狗,并告诉他,这是狗时间长了之后,当小孩见到狗这个物种的时候,就自然而然的知道是狗了。当然有时候也会有例外。比如来了一只狼,也许就会被误认为也是狗(狼狗)。造成这个误差的原因也许是我们给小孩看的狗的样本还不够多(可以理解为数据量不够,欠拟合),也有可能是我们教的方式不是最好的(选用的模型不是最优的)
现在回到我们的网络模型问题上,第一个conv层中的过滤器如何知道要查找边和曲线?完全连接的图层如何知道要查看的激活图?每层中的过滤器如何知道有什么值?计算机能够调整其过滤值(或权重)的方式是通过称为反向传播的训练过程。
在我们进入反向传播之前,我们必须先退后一步,讨论神经网络的工作需求。现在我们都出生了,我们的思想是新鲜的(神经网络搭建好了,但是还未训练)。我们不知道什么是猫,狗或鸟。以类似的方式,在CNN开始之前,权重或筛选值是随机的。过滤器不知道寻找边缘和曲线。在更高层的过滤器不知道寻找爪子和喙。然而,随着年龄的增长,我们的父母和老师向我们展示了不同的图片和图片,并给了我们相应的标签。被赋予形象和标签的想法是CNN经历的培训过程。在深入研究之前,我们假设我们有一套训练集,其中包含成千上万的狗,猫和鸟的图像,每个图像都有一个这个图像是什么动物的标签。
反向传播可以分为4个不同的部分,正向传递,丢失函数,反向传递和权重更新。在正向传球过程中,您将会看到一张训练图像,我们记得这是一个32 x 32 x 3的数字数组,并将其传递给整个网络。在我们的第一个训练样例中,由于所有的权值或过滤值都是随机初始化的,因此输出结果可能类似[.1.1.1.1.1.1.1.1.1.1],基本上是输出不了任何准确数字。网络以其当前的权重无法查找这些低级特征,因此无法就分类的可能性作出任何合理的结论。这转到损失功能反向传播的一部分。请记住,我们现在使用的是训练数据。这个数据有一个图像和一个标签。例如,假设输入的第一个训练图像是3,图像的标签是[0 0 0 1 0 0 0 0 0 0]。损失函数可以用许多不同的方式来定义,但常见的是MSE(均方误差)。
假设变量L等于该值。正如你可以想象的那样,第一对训练图像的损失将非常高。现在,让我们直观地思考这个问题。我们希望达到预测的标签(ConvNet的输出)与训练标签相同的点(这意味着我们的网络得到了预测权)。为了达到这个目的,我们希望最小化损失量我们有。将这看作是微积分中的一个优化问题,我们想要找出哪些输入(权重在我们的情况下)是最直接导致网络损失(或错误)的因素。
tips
关于卷积神经网络的数学含义,我会在CNN卷积神经网络原理详解(下)里面详细解释。
传送门:
CNN卷积神经网络原理详解(中)
CNN卷积神经网络原理详解(下)
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/162105.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
