大家好,又见面了,我是你们的朋友全栈君。
本文会完成BP神经网络的推导过程,先介绍BP神经网络的历史,然后介绍BP神经网络的结构,然后再开始推导,最后介绍BP神经网络的优缺点以及几个优化的方法。
目录
1 BP神经网络的历史
20世纪80年代中期,David Runelhart。Geoffrey Hinton和Ronald W-llians、DavidParker等人分别独立发现了误差反向传播算法(Error Back Propagation Training),简称BP,系统解决了多层神经网络隐含层连接权学习问题,并在数学上给出了完整推导。人们把采用这种算法进行误差校正的多层前馈网络称为BP网。
2 BP神经网络的结构
2.1 神经元
神经元是BP神经网络最基础的组成,是最基本的单元。一个神经元包括输入值,输出值,以及输出值与输入值之间的映射关系,即激励函数  常用的激励函数有 和 ,后者的性能要比前者好。
常用的激励函数有 和 ,后者的性能要比前者好。
除此之外,神经元还包含权值和偏置,这是网络的基础参数,也是训练的对象。
需要注意的是,这里的是指该神经元与下一层神经元的连接权值。
2.2 输入层
输入层是BP神经网络的第一层,由k1个神经元组成,k1是训练数据中输入数据的维度大小,输入层的激励函数一般为线性函数,即 ,(其实是其他函数也可以,只要相应地更改反向公式即可,区别是性能的问题了)。
输入层神经元的输入值 (表示输入层第i个神经元的输入值,表示一组训练数据中的输入数据的第i个值)。
输入层神经元的输出值 (表示输入层第i个神经元的输出值)。
2.3 隐含层
隐含层是神经网络的主要结构,神经网络的强大功能都是在隐含层得以实现的。隐含层主要的作用是构建训练数据的输入数据与输出数据之间的映射关系。隐含层并非一层,它可以有很多层,层数由自己决定,每一层的神经元个数也由自己决定。
隐含层神经元的输入值 (其中表示网络中第i层第j个神经元的输入值,表示第i-1层神经元个数,表示第i-1层第h个神经元的输出值, 表示第i-1层第h个神经元与第i层第j个神经元的权值,b是神经元的偏置)
隐含层神经元的输出值,f是神经元的激励函数,表示第i层第j个神经元的输入。
2.4 输出层
输出层是网络的最后一层,输出层由k2个神经元组成,k2是训练数据中输出数据的维度大小,神经元的输出值就是网络的预测值。
输出层神经元的输入与隐含层的输入层公式一样,都等于上一次所有神经元的输出值乘上相应权值的和。
输出层神经元的输出值直接等于输入值,即,即激励函数为 。
3 结构图及符号声明
3.1 结构图
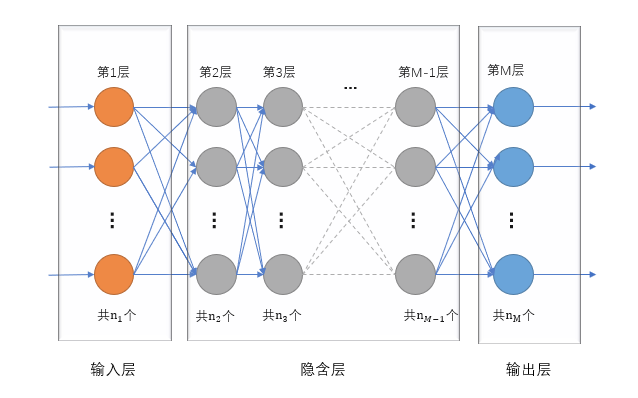
3.2 符号声明
| 符号 | 含义 |
|
神经网络的总层数,包括输入输出层,所以 (隐含层至少一层) |
|
第i层的神经元个数 |
|
变量,表示第i层网络,,i=0表示输入层,i=M表示输出层 |
|
变量,表示第i层的第j个神经元, |
|
变量,表示第i层第j个神经元与第i+1层第k个神经元, |
|
第i层第j个神经元和第i+1层第k个神经元之间的权值 |
|
神经元的偏置 |
|
第i层第j个神经元的输入值 |
|
第i层第j个神经元的输出值 |
|
激励函数,在下面推导中,使用 , |
|
一组训练数据的第j个输出数据 |
|
一组训练数据的第j个输入数据 |
|
输出层第j个神经元的误差,,是输出层第j个神经元的输出值 |
|
目标函数,,其中J是训练样本个数 |
|
学习速率,一般在0.001以下 |
4 BP神经网络的推导
BP神经网络可以分为两个过程。
一是正向过程,这个过程中,输入数据从输入层传入,然后经历各个隐含层,传到输出层,由输出层输出网络的预测值。
二是反向过程,在这个过程中,根据网络的误差,跟新隐含层和输入层的权值,以及隐含层的偏置值。反向过程也就是误差的反向传播,是BP神经网络的精髓所在。
4.1 前向过程
前向过程的主要任务就是计算出网络的预测值,即输出层神经元的输出值,由于除了输入层,其他层神经元的输出值都与其前一层的神经元的输出值有关,所以计算出每个神经元的输入输出值。
输入层神经元:
输入值 (输入层,i=1)
输出值
隐含层神经元:
输入值
输出值
输出层神经元:
输入值 (输入层,i=M)
输出值
4.2 反向过程
前向过程之后,为了减小网络的误差,即训练网络,需要根据误差来更新网络的权值与偏置值,反向过程就是完成这个的。
1、计算每个输出神经元误差
2、计算目标函数值
3、更新权值
输入层和输出层没有进行激励函数的计算,输入层的权值需要更新,输出层的权值不会用到,不需要更新。
首先,
令,则
然后分别计算和
3.1 计算
由于i+1>1,所以不会是输入层
对于隐含层和输出层,
3.2 计算
a.计算
如果i+1为输出层,
否则,i+1为隐含层,
b.计算
如果i+1为输出层,则,
如果i+1为隐含层,
综上,可得
所以,
4、更新偏置值
输入层和输出层的偏置不需要进行更新,对于隐含层:
如果i+1层为输出层:
如果i+1层为输出层:
所以,
5 更新公式
5.1 权值更新公式
5.2 偏置值更新公式
6、BP神经网络的优缺点
6.1 优点
BP神经网络是全局逼近的,所以它的整体性能比较好,另外,它的隐含层层数以及每一层的神经元数可以无限增加,这让BP神经网络的能力没有上限,不过一般都不会使用很多层,因为计算机的算力有限。
6.2 缺点
收敛慢,精度不够高,可能陷入局部最小(几乎所有智能算法的通病,只可改善,不可消除)。
7 BP神经网络的改进
7.1 增加动量项
即在更新公式后面加上前一次的变化量,公式如下
是上一次迭代的变动量。
偏置值的更新也是如此。
7.2 学习速率的自适应调节
学习速率在一定程度上决定了网络预测的精度,学习速率太大,则精度差,甚至不收敛,如果学习速率太小,则收敛缓慢。
学习速率自适应调节就是为了解决这个问题:
如果本次迭代使得误差函数的值E下降,则增大学习速率:
如果本次迭代使得误差函数的值E上升,则此次调整无效,且减小学习速率:
需要注意的是,由于学习速率在自己调节,所以会出现误差变大的现象,这是正常操作。
8 BP神经网络结构设计原则
8.1 隐含层层数的设计
对于函数拟合,理论上,只含一层隐含层的BP神经网络即可拟合出任意连续函数,只有当函数不连续时,才需要增加隐含层的层数。
8.2 隐含层神经元个数的设计
可由经验公式决定:
或者
m即神经元个数,n是输入节点数,l是输出节点数,是常数,在1-10之间
9 参考文献
人工神经网络原理及应用/朱大奇,史慧编著.
——北京:科学出版社,2006
10 最后
其实在2018年4月左右我为了在单片机上做一个3输入2输出的函数拟合,才写的神经网络,后来写完之后,没有将原理记录下来,这里隔了近1年的时间才重新记录,真是汗颜。如果大家需要BP神经网络C语言的实现,可以查看下面的链接,里面有代码以及每个函数的讲解,可以直接在单片机上使用,进行函数拟合或者预测。
链接:
https://blog.csdn.net/qq_39545674/article/details/82495569
如果文章对你有用,请关注我的微信公众号 “ 山人彤 ”,里面有BP神经网络C语言代码,回复“ BP神经网络C语言 ”即可获取!
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/162099.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
