大家好,又见面了,我是你们的朋友全栈君。
BP神经网络原理
经典的BP神经网络通常由三层组成: 输入层, 隐含层与输出层.通常输入层神经元的个数与特征数相关,输出层的个数与类别数相同, 隐含层的层数与神经元数均可以自定义.


每个神经元代表对数据的一次处理:

每个隐含层和输出层神经元输出与输入的函数关系为:
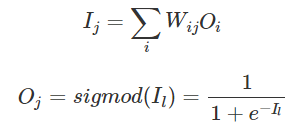
其中Wij表示神经元i与神经元j之间连接的权重,Oj代表神经元j的输出, sigmod是一个特殊的函数用于将任意实数映射到(0,1)区间.
上文中的sigmod函数称为神经元的激励函数(activation function), 除了sigmod函数1/1+e^-IL外, 常用还有tanh和ReLU函数.
我们用一个完成训练的神经网络处理回归问题, 每个样本拥有n个输入.相应地,神经网络拥有n个输入神经元和1个输出神经元.
实际应用中我们通常在输入层额外增加一个偏置神经元, 提供一个可控的输入修正;或者为每个隐含层神经元设置一个偏置参数.
我们将n个特征依次送入输入神经元, 隐含层神经元获得输入层的输出并计算自己输出值, 输出层的神经元根据隐含层输出计算出回归值.
上述过程一般称为前馈(Feed-Forward)过程, 该过程中神经网络的输入输出与多维函数无异.
现在我们的问题是如何训练这个神经网络.
作为监督学习算法,BP神经网络的训练过程即是根据前馈得到的预测值和参考值比较, 根据误差调整连接权重Wij的过程.
训练过程称为反向传播过程(BackPropagation), 数据流正好与前馈过程相反.
首先我们随机初始化连接权重Wij, 对某一训练样本进行一次前馈过程得到各神经元的输出.
首先计算输出层的误差:
Ej=sigmod′(Oj)∗(Tj−Oj)=Oj(1−Oj)(Tj−Oj)
其中Ej代表神经元j的误差,Oj表示神经元j的输出, Tj表示当前训练样本的参考输出, sigmod′(x)是上文sigmod函数的一阶导数.
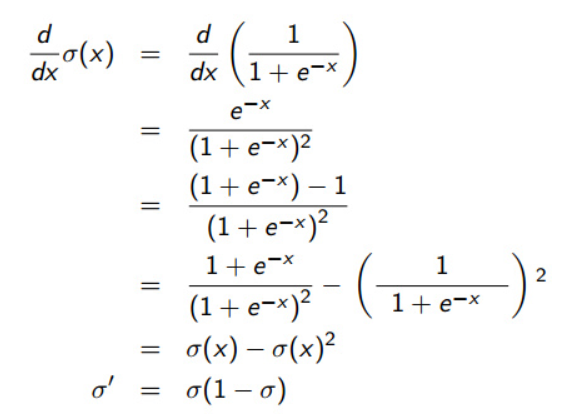
计算隐含层误差:
Ej=sigmod′(Oj)∗∑kEkWjk=Oj(1−Oj)∑kEkWjk
隐含层输出不存在参考值, 使用下一层误差的加权和代替(Tj−Oj).
计算完误差后就可以更新Wij和θj:
Wij=Wij+λEjOi
其中λ是一个称为学习率的参数,一般在(0,0.1)区间上取值.
实际上为了加快学习的效率我们引入称为矫正矩阵的机制, 矫正矩阵记录上一次反向传播过程中的EjOi值, 这样Wj更新公式变为:
Wij=Wij+λEjOi+μCij
μ是一个称为矫正率的参数.随后更新矫正矩阵:
Cij=EjOi
每一个训练样本都会更新一次整个网络的参数.我们需要额外设置训练终止的条件.
最简单的训练终止条件为设置最大迭代次数, 如将数据集迭代1000次后终止训练.
单纯的设置最大迭代次数不能保证训练结果的精确度, 更好的办法是使用损失函数(loss function)作为终止训练的依据.
损失函数可以选用输出层各节点的方差:
L=∑j(Tj−Oj)2
为了避免神经网络进行无意义的迭代, 我们通常在训练数据集中抽出一部分用作校验.当预测误差高于阈值时提前终止训练.
Python实现BP神经网络
首先实现几个工具函数:
def rand(a, b):
return (b - a) * random.random() + a
def make_matrix(m, n, fill=0.0): # 创造一个指定大小的矩阵
mat = []
for i in range(m):
mat.append([fill] * n)
return mat
定义sigmod函数和它的导数:
def sigmoid(x):
return 1.0 / (1.0 + math.exp(-x))
def sigmod_derivate(x):
return x * (1 - x)
定义BPNeuralNetwork类, 使用三个列表维护输入层,隐含层和输出层神经元, 列表中的元素代表对应神经元当前的输出值.使用两个二维列表以邻接矩阵的形式维护输入层与隐含层, 隐含层与输出层之间的连接权值, 通过同样的形式保存矫正矩阵.
定义setup方法初始化神经网络:
def setup(self, ni, nh, no):
self.input_n = ni + 1 # 因为需要多加一个偏置神经元,提供一个可控的输入修正
self.hidden_n = nh
self.output_n = no
# 初始化神经元
self.input_cells = self.input_n * [1.0]
self.hidden_cells = self.hidden_n * [1.0]
self.output_cells = self.output_n * [1.0]
# 初始化权重矩阵
self.input_weights = make_matrix(self.input_n, self.hidden_n)
self.output_weights = make_matrix(self.hidden_n, self.output_n)
# 权重矩阵随机激活
for i in range(self.input_n):
for h in range(self.hidden_n):
self.input_weights[i][h] = rand(-0.2, 0.2)
for h in range(self.hidden_n):
for o in range(self.output_n):
self.output_weights[h][o] = rand(-0.2, 0.2)
# 初始化矫正矩阵
self.input_correction = make_matrix(self.input_n, self.hidden_n)
self.output_correction = make_matrix(self.hidden_n, self.output_n)
定义predict方法进行一次前馈, 并返回输出:
def predict(self, inputs):
# 激活输入层
for i in range(self.input_n - 1):
self.input_cells[i] = inputs[i]
# 激活隐藏层
for j in range(self.hidden_n):
total = 0.0
for i in range(self.input_n):
total += self.input_cells[i] * self.input_weights[i][j]
self.hidden_cells[j] = sigmoid(total)
for k in range(self.output_n):
total = 0.0
for j in range(self.hidden_n):
total += self.hidden_cells[j] * self.output_weights[j][k]
self.output_cells[k] = sigmoid(total)
return self.output_cells[:]
定义back_propagate方法定义一次反向传播和更新权值的过程, 并返回最终预测误差:
def back_propagate(self, case, label, learn, correct):
# 前馈
self.predict(case)
# 获取输出层误差
output_deltas = [0.0] * self.output_n
for o in range(self.output_n):
error = label[o] - self.output_cells[o]
output_deltas[o] = sigmod_derivate(self.output_cells[o]) * error
# 获取隐藏层误差
hidden_deltas = [0.0] * self.hidden_n
for h in range(self.hidden_n):
error = 0.0
for o in range(self.output_n):
error += output_deltas[o] * self.output_weights[h][o]
hidden_deltas[h] = sigmod_derivate(self.hidden_cells[h]) * error
# 更新输出权重
for h in range(self.hidden_n):
for o in range(self.output_n):
# Wij=Wij+λEjOi+μCij
change = output_deltas[o] * self.hidden_cells[h]
self.output_weights[h][o] += learn * change + correct * self.output_correction[h][o]
# 更新输入权重
for i in range(self.input_n):
for h in range(self.hidden_n):
# Wij=Wij+λEjOi+μCij
change = hidden_deltas[h] * self.input_cells[i]
self.input_weights[i][h] += learn * change + correct * self.input_correction[i][h]
self.input_correction[i][h] = change
# 获取全局误差
error = 0.0
for o in range(len(label)):
error += 0.5 * (label[o] - self.output_cells[o]) ** 2
return error
定义train方法控制迭代, 该方法可以修改最大迭代次数, 学习率λ, 矫正率μ三个参数.
def train(self, cases, labels, limit=10000, learn=0.05, correct=0.1):
for i in range(limit):
error = 0.0
for i in range(len(cases)):
label = labels[i]
case = cases[i]
error += self.back_propagate(case, label, learn, correct)
编写test方法,演示如何使用神经网络学习异或逻辑:
def test(self):
cases = [
[0, 0],
[0, 1],
[1, 0],
[1, 1],
]
labels = [[0], [1], [1], [0]]
self.setup(2, 5, 1) # 设置各层的神经元数量
self.train(cases, labels, 10000, 0.5, 0.1)
for case in cases:
print(self.predict(case))
运行结果:

总结
BP神经网络的理解主要难点在于各层误差和权重的更新上面,涉及到一系列数学公式,只要把数学公式弄懂就会理解代码为什么这样做.
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/162096.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
