大家好,又见面了,我是你们的朋友全栈君。
1. 神经元概述
神经网络是由一个个的被称为“神经元”的基本单元构成,单个神经元的结构如下图所示:


对于上述的神经元,其输入为 x 1 x_1 x1, x 2 x_2 x2, x 3 x_3 x3以及截距 + 1 +1 +1,其输出为:
h W , b ( x ) = f ( W T x ) = f ( ∑ i = 1 3 W i x i + b ) h_{\mathbf{W},b}\left ( \mathbf{x} \right )=f\left ( \mathbf{W}^T\mathbf{x} \right )=f\left ( \sum_{i=1}^{3}W_ix_i+b \right ) hW,b(x)=f(WTx)=f(i=1∑3Wixi+b)
其中, W \mathbf{W} W表示的是向量,代表的是权重,函数 f f f称为激活函数,通常激活函数可以选择为Sigmoid函数,或者tanh双曲正切函数,其中,Sigmoid函数的形式为:
f ( z ) = 1 1 + e − z f\left ( z \right )=\frac{1}{1+e^{-z}} f(z)=1+e−z1
双曲正切函数的形式为:
f ( z ) = t a n h ( z ) = e z − e − z e z + e − z f\left ( z \right )=tanh\left ( z \right )=\frac{e^{z}-e^{-z}}{e^z+e^{-z}} f(z)=tanh(z)=ez+e−zez−e−z
以下分别是Sigmoid函数和tanh函数的图像,左边为Sigmoid函数的图像,右边为tanh函数的图像:

Sigmoid函数的区间为 [ 0 , 1 ] \left [ 0,1 \right ] [0,1],而tanh函数的区间为 [ − 1 , 1 ] \left [ -1,1 \right ] [−1,1]。
若是使用sigmoid作为神经元的激活函数,则当神经元的输出为 1 1 1时表示该神经元被激活,否则称为未被激活。同样,对于激活函数是tanh时,神经元的输出为 1 1 1时表示该神经元被激活,否则称为未被激活。
2. 神经网络
2.1. 神经网络的结构
神经网络是由很多的神经元联结而成的,一个简单的神经网络的结构如下图所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2kBGVAsn-1650777194062)(http://i.imgur.com/370RBZK.jpg)]
其中一个神经元的输出是另一个神经元的输入, + 1 +1 +1项表示的是偏置项。上图是含有一个隐含层的神经网络模型, L 1 L_1 L1层称为输入层, L 2 L_2 L2层称为隐含层, L 3 L_3 L3层称为输出层。
2.2. 神经网络中的参数说明
在神经网络中,主要有如下的一些参数标识:
- 网络的层数 n 1 n_1 n1。在上述的神经网络中 n l = 3 n_l=3 nl=3,将第 l l l层记为 L l L_l Ll,则上述的神经网络,输入层为 L 1 L_1 L1,输出层为 L 3 L_3 L3。
- 网络权重和偏置 ( W , b ) = ( W ( 1 ) , b ( 1 ) , W ( 2 ) , b ( 2 ) ) \left ( \mathbf{W},\mathbf{b} \right )=\left ( \mathbf{W}^{(1)},\mathbf{b}^{(1)},\mathbf{W}^{(2)},\mathbf{b}^{(2)} \right ) (W,b)=(W(1),b(1),W(2),b(2)),其中 W i j ( l ) W^{(l)}_{ij} Wij(l)表示的是第 l l l层的第 j j j个神经元和第 l + 1 l+1 l+1层的第 i i i个神经元之间的连接参数, b i ( l ) b^{(l)}_i bi(l)标识的是第 l + 1 l+1 l+1层的第 i i i个神经元的偏置项。在上图中, W ( 1 ) ∈ ℜ 3 × 3 \mathbf{W}^{(1)}\in \Re ^{3\times 3} W(1)∈ℜ3×3, W ( 2 ) ∈ ℜ 1 × 3 \mathbf{W}^{(2)}\in \Re ^{1\times 3} W(2)∈ℜ1×3。
2.3. 神经网络的计算
在神经网络中,一个神经元的输出是另一个神经元的输入。假设 z i ( l ) z^{(l)}_i zi(l)表示的是第 l l l层的第 i i i个神经元的输入,假设 a i ( l ) a^{(l)}_i ai(l)表示的是第 l l l层的第 i i i个神经元的输出,其中,当 l = 1 l=1 l=1时, a i ( 1 ) = x i a^{(1)}_i=x_i ai(1)=xi。根据上述的神经网络中的权重和偏置,就可以计算神经网络中每一个神经元的输出,从而计算出神经网络的最终的输出 h W , b h_{\mathbf{W},\mathbf{b}} hW,b。
对于上述的神经网络结构,有下述的计算:
z 1 ( 2 ) = W 11 ( 1 ) x 1 + W 12 ( 1 ) x 2 + W 13 ( 1 ) x 3 + b 1 ( 1 ) z^{(2)}_1=W^{(1)}_{11}x_1+W^{(1)}_{12}x_2+W^{(1)}_{13}x_3+b^{(1)}_1 z1(2)=W11(1)x1+W12(1)x2+W13(1)x3+b1(1)
a 1 ( 2 ) = f ( W 11 ( 1 ) x 1 + W 12 ( 1 ) x 2 + W 13 ( 1 ) x 3 + b 1 ( 1 ) ) a^{(2)}_1=f\left ( W^{(1)}_{11}x_1+W^{(1)}_{12}x_2+W^{(1)}_{13}x_3+b^{(1)}_1 \right ) a1(2)=f(W11(1)x1+W12(1)x2+W13(1)x3+b1(1))
z 2 ( 2 ) = W 21 ( 1 ) x 1 + W 22 ( 1 ) x 2 + W 23 ( 1 ) x 3 + b 2 ( 1 ) z^{(2)}_2=W^{(1)}_{21}x_1+W^{(1)}_{22}x_2+W^{(1)}_{23}x_3+b^{(1)}_2 z2(2)=W21(1)x1+W22(1)x2+W23(1)x3+b2(1)
a 2 ( 2 ) = f ( W 21 ( 1 ) x 1 + W 22 ( 1 ) x 2 + W 23 ( 1 ) x 3 + b 2 ( 1 ) ) a^{(2)}_2=f\left ( W^{(1)}_{21}x_1+W^{(1)}_{22}x_2+W^{(1)}_{23}x_3+b^{(1)}_2 \right ) a2(2)=f(W21(1)x1+W22(1)x2+W23(1)x3+b2(1))
z 3 ( 2 ) = W 31 ( 1 ) x 1 + W 32 ( 1 ) x 2 + W 33 ( 1 ) x 3 + b 3 ( 1 ) z^{(2)}_3=W^{(1)}_{31}x_1+W^{(1)}_{32}x_2+W^{(1)}_{33}x_3+b^{(1)}_3 z3(2)=W31(1)x1+W32(1)x2+W33(1)x3+b3(1)
a 3 ( 2 ) = f ( W 31 ( 1 ) x 1 + W 32 ( 1 ) x 2 + W 33 ( 1 ) x 3 + b 3 ( 1 ) ) a^{(2)}_3=f\left ( W^{(1)}_{31}x_1+W^{(1)}_{32}x_2+W^{(1)}_{33}x_3+b^{(1)}_3 \right ) a3(2)=f(W31(1)x1+W32(1)x2+W33(1)x3+b3(1))
从而,上述神经网络结构的最终的输出结果为:
h W , b ( x ) = f ( W 11 ( 2 ) a 1 ( 2 ) + W 12 ( 2 ) a 2 ( 2 ) + W 13 ( 2 ) a 3 ( 2 ) + b 1 ( 2 ) ) h_{\mathbf{W},\mathbf{b}}\left ( \mathbf{x} \right )=f\left ( W^{(2)}_{11}a_1^{(2)}+W^{(2)}_{12}a_2^{(2)}+W^{(2)}_{13}a_3^{(2)}+b^{(2)}_1 \right ) hW,b(x)=f(W11(2)a1(2)+W12(2)a2(2)+W13(2)a3(2)+b1(2))
上述的步骤称为前向传播,指的是信号从输入层,经过每一个神经元,直到输出神经元的传播过程。
2.4. 其他形式的神经网络模型
上述以单隐层神经网络为例介绍了神经网络的基本结构,在神经网络的结构中,可以包含多个隐含层,神经网络的输出神经单元也可以是多个,如下面的含多隐层多输出单元的神经网络模型:
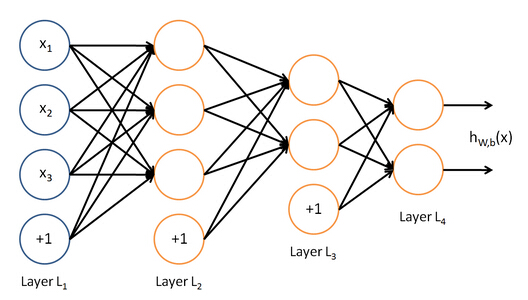
2.5. 神经网络中参数的求解
对于上述神经网络模型,假设有 m m m个训练样本 { ( x ( 1 ) , y ( 1 ) ) , ⋯ , ( x ( m ) , y ( m ) ) } \left \{ \left (\mathbf{x}^{(1)},y^{(1)} \right ),\cdots , \left (\mathbf{x}^{(m)},y^{(m)} \right )\right \} {
(x(1),y(1)),⋯,(x(m),y(m))},对于一个训练样本 ( x , y ) \left ( \mathbf{x},y \right ) (x,y),其损失函数为:
J ( W , b ; x , y ) = 1 2 ∥ h W , b ( x ) − y ∥ 2 J\left ( \mathbf{W},\mathbf{b};\mathbf{x},y \right )=\frac{1}{2}\left \| h_{\mathbf{W},\mathbf{b}}\left ( \mathbf{x} \right )-y \right \|^2 J(W,b;x,y)=21∥hW,b(x)−y∥2
为了防止模型的过拟合,在损失函数中会加入正则项,即:
J = l o s s + R J = loss + R J=loss+R
其中, l o s s loss loss表示的是损失函数, R R R表示的是正则项。则对于上述的含有 m m m个样本的训练集,其损失函数为:
J ( W , b ) = [ 1 m ∑ i = 1 m J ( W , b ; x ( i ) , y ( i ) ) ] + λ 2 ∑ l = 1 n l − 1 ∑ i = 1 s l ∑ j = 1 s l + 1 ( W i j ( l ) ) 2 J\left ( \mathbf{W},\mathbf{b} \right )=\left [ \frac{1}{m}\sum_{i=1}^{m}J\left ( \mathbf{W},\mathbf{b};\mathbf{x}^{(i)},y^{(i)} \right ) \right ]+\frac{\lambda }{2}\sum_{l=1}^{n_l-1}\sum_{i=1}^{s_l}\sum_{j=1}^{s_{l+1}}\left ( W^{(l)}_{ij} \right )^2 J(W,b)=[m1i=1∑mJ(W,b;x(i),y(i))]+2λl=1∑nl−1i=1∑slj=1∑sl+1(Wij(l))2
通常,偏置项并不放在正则化中,因为在正则化中放入偏置项只会对神经网络产生很小的影响。
我们的目标是要求得参数 W \mathbf{W} W和参数 b \mathbf{b} b以使得损失函数 J ( W , b ) J\left ( \mathbf{W},\mathbf{b} \right ) J(W,b)达到最小值。首先需要对参数进行随机初始化,即将参数初始化为一个很小的接近 0 0 0的随机值。
参数的初始化有很多不同的策略,基本的是要在 0 0 0附近的很小的邻域内取得随机值。
在随机初始化参数后,利用前向传播得到预测值 h W , b ( x ) h_{\mathbf{W},\mathbf{b}}\left ( \mathbf{x} \right ) hW,b(x),进而可以得到损失函数,此时需要利用损失函数对其参数进行调整,可以使用梯度下降的方法,梯度下降对参数的调整如下:
W i j ( l ) = W i j ( l ) − α ∂ ∂ W i j ( l ) J ( W , b ) W^{(l)}_{ij}=W^{(l)}_{ij}-\alpha \frac{\partial }{\partial W^{(l)}_{ij}}J\left ( \mathbf{W},\mathbf{b} \right ) Wij(l)=Wij(l)−α∂Wij(l)∂J(W,b)
b i ( l ) = b i ( l ) − α ∂ ∂ b i ( l ) J ( W , b ) b^{(l)}_{i}=b^{(l)}_{i}-\alpha \frac{\partial }{\partial b^{(l)}_{i}}J\left ( \mathbf{W},\mathbf{b} \right ) bi(l)=bi(l)−α∂bi(l)∂J(W,b)
其中,$\alpha $称为学习率,在计算参数的更新公式中,需要使用到反向传播算法。
而 ∂ ∂ W i j ( l ) J ( W , b ) \frac{\partial }{\partial W^{(l)}_{ij}}J\left ( \mathbf{W},\mathbf{b} \right ) ∂Wij(l)∂J(W,b), ∂ ∂ b i ( l ) J ( W , b ) \frac{\partial }{\partial b^{(l)}_{i}}J\left ( \mathbf{W},\mathbf{b} \right ) ∂bi(l)∂J(W,b)的具体形式如下:
∂ ∂ W i j ( l ) J ( W , b ) = [ 1 m ∑ i = 1 m ∂ ∂ W i j ( l ) J ( W , b ; x ( i ) , y ( i ) ) ] + λ W i j ( l ) \frac{\partial }{\partial W^{(l)}_{ij}}J\left ( \mathbf{W},\mathbf{b} \right )=\left [ \frac{1}{m}\sum_{i=1}^{m}\frac{\partial }{\partial W^{(l)}_{ij}}J\left ( \mathbf{W},\mathbf{b};\mathbf{x}^{(i)},y^{(i)} \right ) \right ]+\lambda W_{ij}^{(l)} ∂Wij(l)∂J(W,b)=[m1i=1∑m∂Wij(l)∂J(W,b;x(i),y(i))]+λWij(l)
∂ ∂ b i ( l ) J ( W , b ) = 1 m ∑ i = 1 m ∂ ∂ b i ( l ) J ( W , b ; x ( i ) , y ( i ) ) \frac{\partial }{\partial b^{(l)}_{i}}J\left ( \mathbf{W},\mathbf{b} \right )=\frac{1}{m}\sum_{i=1}^{m}\frac{\partial }{\partial b^{(l)}_{i}}J\left ( \mathbf{W},\mathbf{b};\mathbf{x}^{(i)},y^{(i)} \right ) ∂bi(l)∂J(W,b)=m1i=1∑m∂bi(l)∂J(W,b;x(i),y(i))
反向传播算法的思路如下:对于给定的训练数据 ( x , y ) \left ( \mathbf{x},y \right ) (x,y),通过前向传播算法计算出每一个神经元的输出值,当所有神经元的输出都计算完成后,对每一个神经元计算其“残差”,如第 l l l层的神经元 i i i的残差可以表示为 δ i ( l ) \delta ^{(l)}_i δi(l)。该残差表示的是该神经元对最终的残差产生的影响。这里主要分为两种情况,一是神经元为输出神经元,第二是神经元为非输出神经元。这里假设 z i ( l ) z^{(l)}_i zi(l)表示第 l l l层上的第 i i i个神经元的输入加权和,假设 a i ( l ) a^{(l)}_i ai(l)表示的是第 l l l层上的第 i i i个神经元的输出, 即 a i ( l ) = f ( z i ( l ) ) a^{(l)}_i=f\left ( z^{(l)}_i \right ) ai(l)=f(zi(l))。
- 对于输出层 n l n_l nl上的神经元 i i i,其残差为:
δ i ( n l ) = ∂ ∂ z i n l J ( W , b ; x , y ) = ∂ ∂ z i n l 1 2 ∥ y − h W , b ( x ) ∥ 2 = ∂ ∂ z i n l 1 2 ∑ i = 1 s n l ∥ y i − a i n l ∥ 2 = ( y i − a i n l ) ⋅ ( − 1 ) ⋅ ∂ ∂ z i n l a i n l = − ( y i − a i n l ) ⋅ f ′ ( z i n l ) \begin{matrix} \delta _i^{(n_l)}=\frac{\partial }{\partial z_i^{n_l}}J\left ( \mathbf{W},\mathbf{b};\mathbf{x},y \right )\\ =\frac{\partial }{\partial z_i^{n_l}}\frac{1}{2}\left \| y-h_{\mathbf{W},\mathbf{b}}\left ( \mathbf{x} \right ) \right \|^2\\ =\frac{\partial }{\partial z_i^{n_l}}\frac{1}{2}\sum_{i=1}^{s_{n_l}}\left \| y_i-a_i^{n_l} \right \|^2\\ =\left ( y_i-a_i^{n_l} \right )\cdot \left ( -1 \right )\cdot \frac{\partial}{\partial z_i^{n_l}}a_i^{n_l}\\ =-\left ( y_i-a_i^{n_l} \right )\cdot {f}’\left ( z_i^{n_l} \right ) \end{matrix} δi(nl)=∂zinl∂J(W,b;x,y)=∂zinl∂21∥y−hW,b(x)∥2=∂zinl∂21∑i=1snl∥yi−ainl∥2=(yi−ainl)⋅(−1)⋅∂zinl∂ainl=−(yi−ainl)⋅f′(zinl)
-对于非输出层,即对于 l = n l − 1 , n l − 2 , ⋯ , 2 l=n_{l-1},n_{l-2},\cdots ,2 l=nl−1,nl−2,⋯,2各层,第 l l l层的残差的计算方法如下(以第 n l − 1 n_{l-1} nl−1层为例):
δ i ( n l − 1 ) = ∂ ∂ z i n l − 1 J ( W , b ; x , y ) = ∂ ∂ z i n l − 1 1 2 ∥ y − h W , b ( x ) ∥ 2 = ∂ ∂ z i n l − 1 1 2 ∑ j = 1 s n l ∥ y j − a j n l ∥ 2 = 1 2 ∑ j = 1 s n l ∂ ∂ z i n l − 1 ∥ y j − a j n l ∥ 2 = 1 2 ∑ j = 1 s n l ∂ ∂ z j n l ∥ y j − a j n l ∥ 2 ⋅ ∂ ∂ z i n l − 1 z j n l = ∑ j = 1 s n l δ j ( n l ) ⋅ ∂ ∂ z i n l − 1 z j n l = ∑ j = 1 s n l ( δ j ( n l ) ⋅ ∂ ∂ z i n l − 1 ∑ k = 1 s n l − 1 f ( z k n l − 1 ) ⋅ W j k n l − 1 ) = ∑ j = 1 s n l ( δ j ( n l ) ⋅ W j i n l − 1 ⋅ f ′ ( z i n l − 1 ) ) = ( ∑ j = 1 s n l δ j ( n l ) ⋅ W j i n l − 1 ) ⋅ f ′ ( z i n l − 1 ) \begin{matrix} \delta _i^{(n_{l-1})}=\frac{\partial }{\partial z_i^{n_{l-1}}}J\left ( \mathbf{W},\mathbf{b};\mathbf{x},y \right )\\ =\frac{\partial }{\partial z_i^{n_{l-1}}}\frac{1}{2}\left \| y-h_{\mathbf{W},\mathbf{b}}\left ( \mathbf{x} \right ) \right \|^2\\ =\frac{\partial }{\partial z_i^{n_{l-1}}}\frac{1}{2}\sum_{j=1}^{s_{n_l}}\left \| y_j-a_j^{n_l} \right \|^2\\ =\frac{1}{2}\sum_{j=1}^{s_{n_l}}\frac{\partial }{\partial z_i^{n_{l-1}}}\left \| y_j-a_j^{n_l} \right \|^2\\ =\frac{1}{2}\sum_{j=1}^{s_{n_l}}\frac{\partial }{\partial z_j^{n_{l}}}\left \| y_j-a_j^{n_l} \right \|^2\cdot \frac{\partial }{\partial z_i^{n_{l-1}}}z_j^{n_{l}}\\ =\sum_{j=1}^{s_{n_l}}\delta _j^{(n_l)}\cdot \frac{\partial }{\partial z_i^{n_{l-1}}}z_j^{n_{l}}\\ =\sum_{j=1}^{s_{n_l}}\left ( \delta _j^{(n_l)}\cdot \frac{\partial }{\partial z_i^{n_{l-1}}}\sum_{k=1}^{s_{n_{l-1}}}f\left ( z_k^{n_{l-1}} \right )\cdot W_{jk}^{n_{l-1}} \right )\\ =\sum_{j=1}^{s_{n_l}}\left ( \delta _j^{(n_l)}\cdot W_{ji}^{n_{l-1}}\cdot {f}’\left ( z_i^{n_{l-1}} \right )\right )\\ =\left (\sum_{j=1}^{s_{n_l}} \delta _j^{(n_l)}\cdot W_{ji}^{n_{l-1}}\right )\cdot {f}’\left ( z_i^{n_{l-1}} \right ) \end{matrix} δi(nl−1)=∂zinl−1∂J(W,b;x,y)=∂zinl−1∂21∥y−hW,b(x)∥2=∂zinl−1∂21∑j=1snl∥∥yj−ajnl∥∥2=21∑j=1snl∂zinl−1∂∥∥yj−ajnl∥∥2=21∑j=1snl∂zjnl∂∥∥yj−ajnl∥∥2⋅∂zinl−1∂zjnl=∑j=1snlδj(nl)⋅∂zinl−1∂zjnl=∑j=1snl(δj(nl)⋅∂zinl−1∂∑k=1snl−1f(zknl−1)⋅Wjknl−1)=∑j=1snl(δj(nl)⋅Wjinl−1⋅f′(zinl−1))=(∑j=1snlδj(nl)⋅Wjinl−1)⋅f′(zinl−1)
因此有:
δ i ( l ) = ( ∑ j = 1 s l + 1 δ j ( l + 1 ) ⋅ W j i ( l ) ) ⋅ f ′ ( z i ( l ) ) \delta _i^{(l)}=\left (\sum_{j=1}^{s_{l+1}} \delta _j^{(l+1)}\cdot W_{ji}^{(l)}\right )\cdot {f}’\left ( z_i^{(l)} \right ) δi(l)=(j=1∑sl+1δj(l+1)⋅Wji(l))⋅f′(zi(l))
对于神经网络中的权重和偏置的更新公式为:
∂ ∂ W i j ( l ) J ( W , b ; x , y ) = a j ( l ) δ i ( l + 1 ) \frac{\partial }{\partial W_{ij}^{(l)}}J\left ( \mathbf{W},\mathbf{b};\mathbf{x},y \right )=a_j^{(l)}\delta _i^{(l+1)} ∂Wij(l)∂J(W,b;x,y)=aj(l)δi(l+1)
∂ ∂ b i ( l ) J ( W , b ; x , y ) = δ i ( l + 1 ) \frac{\partial }{\partial b_{i}^{(l)}}J\left ( \mathbf{W},\mathbf{b};\mathbf{x},y \right )=\delta _i^{(l+1)} ∂bi(l)∂J(W,b;x,y)=δi(l+1)
2.6. 神经网络的学习过程
对于神经网络的学过程,大致分为如下的几步:
- 初始化参数,包括权重、偏置、网络层结构,激活函数等等
- 循环计算
- 正向传播,计算误差
- 反向传播,调整参数
- 返回最终的神经网络模型
参考文献
[1] 英文版:UFLDL Tutorial
[2] 中文版:UFLDL教程
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/162091.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
