大家好,又见面了,我是你们的朋友全栈君。
Oracle数据恢复顾问用于当数据发生错误或故障时,进行自动收集数据故障信息,并生成恢复脚本,用于完成数据恢复。数据恢复顾问也可以主动检查故障。 在这种模式下,它可以在数据库进程发现数据损坏并发出错误之前进行潜在的检测并分析数据故障。数据故障可能非常严重。 例如,如果您当前的日志文件丢失,则无法启动你的数据库。 一些数据故障(如数据文件中的块损坏)不是灾难性的他们不会将数据库关闭或阻止您启动Oracle实例。 数据恢复顾问处理这两种情况:当您无法启动数据库时(因为某些情况)所需的数据库文件丢失,不一致或损坏)以及文件损坏时的数据库文件在运行时发现。
一、数据恢复顾问特性
特性描述
– 快速检测,分析和修复故障
– 最大限度地减少用户的中断
– 减少停机和运行时故障
支持的用户接口
– EM GUI界面
– RMAN命令行
支持的数据库配置:
– 单实例
– 不是RAC
– 支持故障转移到待机状态,但不能分析和修复备用数据库
二、数据故障的情形
不可访问的组件,例如:
– 在操作系统级丢失数据文件
– 访问权限不正确
– 离线表空间等等
物理损坏,如块校验故障或无效的块头字段值
逻辑损坏,如不一致的字典,损坏的行,损坏的索引条目或失败事务
不一致,如控制文件过旧或过新于数据文件和联机重做日志
I/O 失败,例如对打开的文件数量的限制超出,通道无法访问,网络或I / O错误
三、数据恢复顾问流程
如下图:

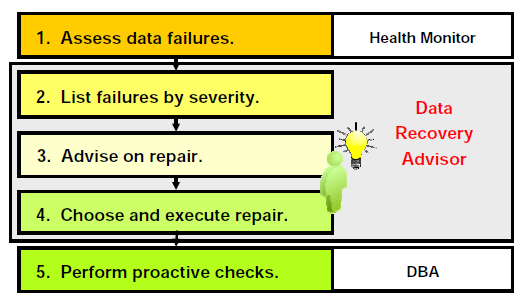
Oracle Database 11g中的自动诊断工作流程如下。 使用数据恢复顾问,您只需要启动一个建议和恢复。
1、健康监视器会自动执行检查并记录失败及其症状,将其作为一个“findings”,存放到自动诊断存储库(ADR)。
2、数据恢复顾问将调查结果整合到失败中。 并列出之前执行故障严重性评估级别
3、当您要求维修建议失败时,数据恢复顾问将失败映射到自动和手动修复选项,检查基本可行性,并提供修复建议。
4、您可以选择手动执行修复或请求Data Recovery Advisor进行修复(OEM)
5、对于数据监测,首选的为“反应性”健康检查及数据恢复恢复顾问,Oracle也建议使用VALIDATE命令作为“主动”检查。
四、数据恢复顾问RMAN接口命令及相关视图
1、RMAN命令
- LIST FAILURE (列出之前执行的故障评估 )
LIST FAILURE [ ALL | CRITICAL | HIGH | LOW | CLOSED | failnum[,failnum,…] ] [ EXCLUDE FAILURE failnum[,failnum,…] ] [ DETAIL ]- ADVISE FAILURE (显示推荐的恢复选项)
ADVISE FAILURE
[ ALL | CRITICAL | HIGH | LOW | failnum[,failnum,…] ]
[ EXCLUDE FAILURE failnum [,failnum,…] ]- REPAIR FAILURE (修复和关闭故障,在同一个RMAN会话中的ADVISE之后)
REPAIR FAILURE
[USING ADVISE OPTION integer]
[ { {NOPROMPT | PREVIEW}}...]- CHANGE FAILURE (更改或关闭一个或多个故障)
CHANGE FAILURE
{ ALL | CRITICAL | HIGH | LOW | failnum[,failnum,…] }
[ EXCLUDE FAILURE failnum[,failnum,…] ]
{ PRIORITY {CRITICAL | HIGH | LOW} |
CLOSE } – change status of the failure(s) to closed
[ NOPROMPT ] – do not ask user for a confirmation2、相关视图
V$IR_FAILURE:列出所有故障,包括已关闭故障(等同于list failure命令获得的结果)
V$IR_MANUAL_CHECKLIST:列出手动修复的建议(等同于advise failure命令的结果)
V$IR_REPAIR:恢复清单(等同于advise failure命令的结果 )
V$IR_FAILURE_SET:失败的交叉引用建议标识符
五、基于RMAN演示数据恢复顾问
1、数据文件丢失恢复
SQL> select * from v$version where rownum=1;
BANNER --------------------------------------------------------------------------------
Oracle Database 11g Enterprise Edition Release 11.2.0.3.0 - 64bit Production
SQL> select open_mode,log_mode from v$database;
OPEN_MODE LOG_MODE
-------------------- ------------
READ WRITE ARCHIVELOG
SQL> select 'Leshami' Author,'http://blog.csdn.net/leshami' Blog,
2 '645746311' QQ from dual;
AUTHOR BLOG QQ
------- ---------------------------- ---------
Leshami http://blog.csdn.net/leshami 645746311
RMAN> backup database plus archivelog;
List of Backups
===============
Key TY LV S Device Type Completion Time #Pieces #Copies Compressed Tag
------- -- -- - ----------- --------------- ------- ------- ---------- ---
9 B A A DISK 26-JUN-17 1 1 NO TAG20170626T112044
10 B F A DISK 26-JUN-17 1 1 NO TAG20170626T112048
11 B A A DISK 26-JUN-17 1 1 NO TAG20170626T112245
12 B F A DISK 26-JUN-17 1 1 NO TAG20170626T112247
SQL> conn scott/tiger;
SQL> create table tb_obj as select * from all_objects;
SQL> select table_name,tablespace_name from user_tables where table_name='TB_OBJ';
TABLE_NAME TABLESPACE_NAME
------------------------------ ------------------------------
TB_OBJ USERS SQL> select count(*) from tb_obj; COUNT(*) ----------
72907
SQL> ho rm -rf /app/oracle/ora11g/oradata/ora11g/users01.dbf
$ tail -fn 50 /app/oracle/ora11g/diag/rdbms/ora11g/ora11g/trace/alert_ora11g.log Mon Jun 26 11:34:44 2017
ALTER SYSTEM: Flushing buffer cache
Mon Jun 26 11:36:58 2017
Errors in file /app/oracle/ora11g/diag/rdbms/ora11g/ora11g/trace/ora11g_m000_21094.trc:
ORA-01116: error in opening database file 4
ORA-01110: data file 4: '/app/oracle/ora11g/oradata/ora11g/users01.dbf'
ORA-27041: unable to open file
Linux-x86_64 Error: 2: No such file or directory Additional information: 3 Mon Jun 26 11:37:01 2017 Checker run found 1 new persistent data failures RMAN> list failure; --该命令执行后列出了failureID号,以及优先级别,具体信息等
List of Database Failures =========================
Failure ID Priority Status Time Detected Summary
---------- -------- --------- ------------- -------
107442 HIGH OPEN 26-JUN-17 One or more non-system datafiles are missing
RMAN> advise failure; --该命令执行后会针对list failure后的故障生成恢复脚本
List of Database Failures =========================
Failure ID Priority Status Time Detected Summary
---------- -------- --------- ------------- -------
107442 HIGH OPEN 26-JUN-17 One or more non-system datafiles are missing
analyzing automatic repair options; this may take some time
using channel ORA_DISK_1
analyzing automatic repair options complete
Mandatory Manual Actions ========================
no manual actions available
Optional Manual Actions =======================
1. If file /app/oracle/ora11g/oradata/ora11g/users01.dbf was unintentionally renamed or moved, restore it
Automated Repair Options ========================
Option Repair Description
------ ------------------
1 Restore and recover datafile 4
Strategy: The repair includes complete media recovery with no data loss
Repair script: /app/oracle/ora11g/diag/rdbms/ora11g/ora11g/hm/reco_1718882889.hm
RMAN> repair failure; --执行恢复,即执行上一步骤生成的脚本
Strategy: The repair includes complete media recovery with no data loss
Repair script: /app/oracle/ora11g/diag/rdbms/ora11g/ora11g/hm/reco_1718882889.hm contents of repair script:
# restore and recover datafile
sql 'alter database datafile 4 offline'; #此处是先将数据文件执行offline,然后还原数据文件,恢复数据文件
restore datafile 4;
recover datafile 4;
sql 'alter database datafile 4 online';
Do you really want to execute the above repair (enter YES or NO)? yes
executing repair script
sql statement: alter database datafile 4 offline
Starting restore at 26-JUN-17
using channel ORA_DISK_1
channel ORA_DISK_1: starting datafile backup set restore
channel ORA_DISK_1: specifying datafile(s) to restore from backup set
channel ORA_DISK_1: restoring datafile 00004 to /app/oracle/ora11g/oradata/ora11g/users01.dbf
channel ORA_DISK_1: reading from backup piece /app/oracle/ora11g/fast_recovery_area/ORA11G
/backupset/2017_06_26/o1_mf_nnndf_TAG20170626T112048_do0zdnkj_.bkp
channel ORA_DISK_1: piece handle=/app/oracle/ora11g/fast_recovery_area/ORA11G
/backupset/2017_06_26/o1_mf_nnndf_TAG20170626T112048_do0zdnkj_.bkp tag=TAG20170626T112048
channel ORA_DISK_1: restored backup piece 1
channel ORA_DISK_1: restore complete, elapsed time: 00:00:07
Finished restore at 26-JUN-17
Starting recover at 26-JUN-17
using channel ORA_DISK_1
starting media recovery
media recovery complete, elapsed time: 00:00:05
Finished recover at 26-JUN-17
sql statement: alter database datafile 4 online
repair failure complete
SQL> select count(*) from tb_obj; --验证成功性 COUNT(*) ----------
729072、联机重做日志文件丢失恢复
SQL> delete from tb_obj where owner='SCOTT';
SQL> commit;
SQL> select count(*) from tb_obj;
COUNT(*)
----------
72899
SQL> select member from v$logfile;
MEMBER
--------------------------------------------------------------------------------
/app/oracle/ora11g/oradata/ora11g/redo03.log
/app/oracle/ora11g/oradata/ora11g/redo02.log
/app/oracle/ora11g/oradata/ora11g/redo01.log
SQL> ho rm -rf /app/oracle/ora11g/oradata/ora11g/redo* --删除全部联机日志
SQL> conn / as sysdba
Connected.
SQL> shutdown immediate;
SQL> startup --启动后报错,实例被强制终止
ORACLE instance started.
Total System Global Area 730714112 bytes
Fixed Size 2231952 bytes
Variable Size 532676976 bytes
Database Buffers 188743680 bytes
Redo Buffers 7061504 bytes
Database mounted.
ORA-03113: end-of-file on communication channel
Process ID: 21655
Session ID: 96 Serial number: 3
--查看alert的告警日志
Mon Jun 26 11:57:09 2017
ARC3 started with pid=23, OS id=21663
ARC1: Archival started
ARC2: Archival started
ARC1: Becoming the 'no FAL' ARCH
ARC1: Becoming the 'no SRL' ARCH
ARC2: Becoming the heartbeat ARCH
Errors in file /app/oracle/ora11g/diag/rdbms/ora11g/ora11g/trace/ora11g_lgwr_21606.trc:
ORA-00313: open failed for members of log group 1 of thread 1
ORA-00312: online log 1 thread 1: '/app/oracle/ora11g/oradata/ora11g/redo01.log'
ORA-27037: unable to obtain file status
Linux-x86_64 Error: 2: No such file or directory
Additional information: 3
Errors in file /app/oracle/ora11g/diag/rdbms/ora11g/ora11g/trace/ora11g_lgwr_21606.trc:
ORA-00313: open failed for members of log group 1 of thread 1
ORA-00312: online log 1 thread 1: '/app/oracle/ora11g/oradata/ora11g/redo01.log'
ORA-27037: unable to obtain file status
Linux-x86_64 Error: 2: No such file or directory
Additional information: 3
Errors in file /app/oracle/ora11g/diag/rdbms/ora11g/ora11g/trace/ora11g_ora_21655.trc:
ORA-00313: open failed for members of log group 1 of thread
ORA-00312: online log 1 thread 1: '/app/oracle/ora11g/oradata/ora11g/redo01.log'
USER (ospid: 21655): terminating the instance due to error 313
Mon Jun 26 11:57:09 2017
Errors in file /app/oracle/ora11g/diag/rdbms/ora11g/ora11g/trace/ora11g_m000_21665.trc:
ORA-00313: open failed for members of log group 1 of thread 1
ORA-00312: online log 1 thread 1: '/app/oracle/ora11g/oradata/ora11g/redo01.log'
ORA-27037: unable to obtain file status
Linux-x86_64 Error: 2: No such file or directory
Additional information: 3
System state dump requested by (instance=1, osid=21655), summary=[abnormal instance termination].
System State dumped to trace file /app/oracle/ora11g/diag/rdbms/ora11g/ora11g/trace/ora11g_diag_21596.trc
Dumping diagnostic data in directory=[cdmp_20170626115709], requested by
(instance=1, osid=21655), summary=[abnormal instance termination]. --实例异常终止
Instance terminated by USER, pid = 21655
SQL> startup mount; --将数据库启动到mount状态
$ rman target /
Recovery Manager: Release 11.2.0.3.0 - Production on Mon Jun 26 11:59:55 2017
Copyright (c) 1982, 2011, Oracle and/or its affiliates. All rights reserved.
connected to target database: ORA11G (DBID=42938845, not open)
RMAN> list failure;
using target database control file instead of recovery catalog
List of Database Failures
=========================
Failure ID Priority Status Time Detected Summary
---------- -------- --------- ------------- -------
107519 CRITICAL OPEN 26-JUN-17 Redo log group 3 is unavailable
107513 CRITICAL OPEN 26-JUN-17 Redo log group 2 is unavailable
107507 CRITICAL OPEN 26-JUN-17 Redo log group 1 is unavailable
107522 HIGH OPEN 26-JUN-17 Redo log file /app/oracle/ora11g/oradata/ora11g/redo03.log is missing
107516 HIGH OPEN 26-JUN-17 Redo log file /app/oracle/ora11g/oradata/ora11g/redo02.log is missing
107510 HIGH OPEN 26-JUN-17 Redo log file /app/oracle/ora11g/oradata/ora11g/redo01.log is missing
RMAN> advise failure;
List of Database Failures
=========================
Failure ID Priority Status Time Detected Summary
---------- -------- --------- ------------- -------
107519 CRITICAL OPEN 26-JUN-17 Redo log group 3 is unavailable
107513 CRITICAL OPEN 26-JUN-17 Redo log group 2 is unavailable
107507 CRITICAL OPEN 26-JUN-17 Redo log group 1 is unavailable
107522 HIGH OPEN 26-JUN-17 Redo log file /app/oracle/ora11g/oradata/ora11g/redo03.log is missing
107516 HIGH OPEN 26-JUN-17 Redo log file /app/oracle/ora11g/oradata/ora11g/redo02.log is missing
107510 HIGH OPEN 26-JUN-17 Redo log file /app/oracle/ora11g/oradata/ora11g/redo01.log is missing
analyzing automatic repair options; this may take some time
allocated channel: ORA_DISK_1
channel ORA_DISK_1: SID=189 device type=DISK
analyzing automatic repair options complete
Mandatory Manual Actions
========================
no manual actions available
Optional Manual Actions
=======================
1. If file /app/oracle/ora11g/oradata/ora11g/redo03.log was unintentionally renamed or moved, restore it
2. If file /app/oracle/ora11g/oradata/ora11g/redo02.log was unintentionally renamed or moved, restore it
3. If file /app/oracle/ora11g/oradata/ora11g/redo01.log was unintentionally renamed or moved, restore it
Automated Repair Options
========================
Option Repair Description
------ ------------------
1 Open resetlogs
Strategy: The repair includes complete media recovery with no data loss
Repair script: /app/oracle/ora11g/diag/rdbms/ora11g/ora11g/hm/reco_4276184973.hm
RMAN> repair failure;
Strategy: The repair includes complete media recovery with no data loss
Repair script: /app/oracle/ora11g/diag/rdbms/ora11g/ora11g/hm/reco_4276184973.hm
contents of repair script:
# recover database until cancel and open resetlogs
sql 'alter database recover database until cancel'; --使用until cancel方式恢复数据库
alter database open resetlogs; --不完全恢复后,只能基于resetlogs方式打开数据库
Do you really want to execute the above repair (enter YES or NO)? yes
executing repair script
sql statement: alter database recover database until cancel
database opened
repair failure complete
SQL> conn scott/tiger;
Connected.
SQL> select count(*) from tb_obj;
COUNT(*)
----------
72899 发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/160811.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
