大家好,又见面了,我是你们的朋友全栈君。
目录
- 一、关于备份与恢复
- 二、逻辑备份(expdp和impdp)
- 三、物理备份
- 四、数据库日常备份计划及脚本参考
一、关于备份与恢复
1、备份定义
备份就是把数据库复制到转储设备的过程。其中,转储设备是指用于放置数据库副本的磁带或磁盘。通常也将存放于转储设备中的数据库的副本称为原数据库的备份或转储。备份是一份数据副本
2、备份分类
从物理与逻辑的角度来分类:
从物理与逻辑的,备份可以分为物理备份和逻辑备份。
物理备份:对数据库操作系统的物理文件(数据文件,控制文件和日志文件)的备份。物理备份又可以分为脱机备份(冷备份)和联机备份(热备份),前者是在关闭数据库的时候进行的,后者是以归档日志的方式对运行的数据库进行备份。可以使用oracle的恢复管理器(RMAN)或操作系统命令进行数据库的物理备份。
逻辑备份:对数据库逻辑组件(如表和存储过程等数据库对象)的备份。逻辑备份的手段很多,如传统的EXP,数据泵(EXPDP),数据库闪回技术等第三方工具,都可以进行数据库的逻辑备份。
从数据库的备份角度分类:
从数据库的备份角度,备份可以分为完全备份和增量备份和差异备份
完全备份:每次对数据库进行完整备份,当发生数据丢失的灾难时,完全备份无需依赖其他信息即可实现100%的数据恢复,其恢复时间最短且操作最方便。
增量备份:只有那些在上次完全备份或增量备份后被修改的文件才会被备份。优点是备份数据量小,需要的时间短,缺点是恢复的时候需要依赖以前备份记录,出问题的风险较大。
差异备份:备份那些自从上次完全备份之后被修改过的文件。从差异备份中恢复数据的时间较短,因此只需要两份数据—最后一次完整备份和最后一次差异备份,缺点是每次备份需要的时间较长。
3、恢复定义
恢复就是发生故障后,利用已备份的数据文件或控制文件,重新建立一个完整的数据库
4、恢复分类
实例恢复:当oracle实例出现失败后,oracle自动进行的恢复
介质恢复:当存放数据库的介质出现故障时所作的恢复。介质恢复又分为完全恢复和不完全恢复
完全恢复:将数据库恢复到数据库失败时的状态。这种恢复是通过装载数据库备份并应用全部的重做日志做到的。
不完全恢复:将数据库恢复到数据库失败前的某一时刻的状态。这种恢复是通过装载数据库备份并应用部分的重做日志做到的。进行不完全恢复后,必须在启动数据库时用resetlogs选项重设联机重做日志。
二、逻辑备份(expdp和impdp)
1、expdp/impdp和exp/imp的区别
- exp和imp是客户端工具程序,它们既可以在客户端使用,也可以在服务端使用。
- expdp和impdp是服务端的工具程序,他们只能在oracle服务端使用,不能在客户端使用。
- imp只适用于exp导出的文件,不适用于expdp导出文件;impdp只适用于expdp导出的文件,而不适用于exp导出文件。
- 对于10g以上的服务器,使用exp通常不能导出0行数据的空表,而此时必须使用expdp导出。
本节主要讲解的是expdp/impdp的用法,不涉及到exp和imp
2、导出数据
在准备要备份的数据库服务器上创建备份目录(在后面使用sql命令创建的逻辑目录并不是在OS上创建目录,所以我们先要在服务器上创建一个目录)
# su oracle
$ mkdir /home/oracle/oracle_bak
用管理员身份登录到sqlplus
$ sqlplys /nolog
SQL> conn sys/oracle as sysdba
创建逻辑目录
SQL> create directory data_dir as '/home/oracle/oracle_bak';
查看管理员目录是否存在
SQL> select * from dba_direcories;
使用管理员用户给指定的用户赋予在该目录的操作权限(比如该用户需要备份自己的数据)
SQL> grant read,write on directory data_dir to C##BAK_TEST_USER;
导出可有五种方式
1、“full=y”,全量导出数据库
$ expdp sys/oracle@orcl dumpfile=expdp.dmp directory=data_dir full=y logfile=expdp.log
2、schemas按用户导出
$ expdp user/passwd@orcl schemas=user dumpfile=expdp.dmp directory=data_dir logfile=expdp.log
3、按表空间导出
$ expdp sys/passwd@orcl tablespace=tbs1,tbs2 dumpfile=expdp.dmp directory=data_dir logfile=expdp.log
4、导出表
$ expdp user/passwd@orcl tables=table1,table2 dumpfile=expdp.dmp directory=data_dir logfile=expdp.log
5、按查询条件导出
$ expdp user/passwd@orcl tables=table1='where number=1234' dumpfile=expdp.dmp directory=data_dir logfile=expdp.log
2、导入数据
首先将需要导入的数据文件存放导需要导入的数据库服务器上
参照导出的时候的建立目录方式建立物理目录和逻辑目录(只是建目录即可,如果需要给用户权限则加上给用户权限的那步)
使用命令导入,同时,导入方式也可以分为五种,分别对应着导出的五种方式
1、“full=y”,全量导入数据库;
impdp user/passwd directory=data_dir dumpfile=expdp.dmp full=y
2、同名用户导入,从用户A导入到用户A;
impdp A/passwd schemas=A directory=data_dir dumpfile=expdp.dmp logfile=impdp.log;
3、
①从A用户中把表table1和table2导入到B用户中;
impdp B/passwdtables=A.table1,A.table2 remap_schema=A:B directory=data_dir dumpfile=expdp.dmp logfile=impdp.log;
②将表空间TBS01、TBS02、TBS03导入到表空间A_TBS,将用户B的数据导入到A,并生成新的oid防止冲突;
impdp A/passwd remap_tablespace=TBS01:A_TBS,TBS02:A_TBS,TBS03:A_TBS remap_schema=B:A FULL=Y transform=oid:n
directory=data_dir dumpfile=expdp.dmp logfile=impdp.log
4、导入表空间;
impdp sys/passwd tablespaces=tbs1 directory=data_dir dumpfile=expdp.dmp logfile=impdp.log
5、追加数据;
impdp sys/passwd directory=data_dir dumpfile=expdp.dmp schemas=system table_exists_action=replace logfile=impdp.log;
--table_exists_action:导入对象已存在时执行的操作。有效关键字:SKIP,APPEND,REPLACE和TRUNCATE
3、并行操作
可以通过 PARALLEL 参数为导出使用一个以上的线程来显著地加速作业。每个线程创建一个单独的转储文件,因此参数 dumpfile 应当拥有和并行度一样多的项目。您可以指定通配符作为文件名,而不是显式地输入各个文件名,例如:
expdp ananda/abc123 tables=CASES directory=DPDATA1 dumpfile=expCASES_%U.dmp parallel=4 job_name=Cases_Export
注意:dumpfile 参数拥有一个通配符 %U,它指示文件将按需要创建,格式将为expCASES_nn.dmp,其中nn 从 01 开始,然后按需要向上增加。
在并行模式下,状态屏幕将显示四个工作进程。(在默认模式下,只有一个进程是可见的)所有的工作进程同步取出数据,并在状态屏幕上显示它们的进度。
分离访问数据文件和转储目录文件系统的输入/输出通道是很重要的。否则,与维护 Data Pump 作业相关的开销可能超过并行线程的效益,并因此而降低性能。并行方式只有在表的数量多于并行值并且表很大时才是有效的。
数据库监控
您还可以从数据库视图获得关于运行的 Data Pump 作业的更多信息。监控作业的主视图是 DBA_DATAPUMP_JOBS,它将告诉您在作业上有多少个工作进程(列 DEGREE)在工作。
另一个重要的视图是 DBA_DATAPUMP_SESSIONS,当它与上述视图和 V$SESSION 结合时将给出主前台进程的会话 SID。
select sid, serial# from v$session s, dba_datapump_sessions d where s.saddr = d.saddr;
这条指令显示前台进程的会话。更多有用的信息可以从警报日志中获得。当进程启动时,MCP 和工作进程在警报日志中显示如下:
kupprdp:master process DM00 started with pid=23, OS id=20530 to execute - SYS.KUPM$MCP.MAIN('CASES_EXPORT', 'ANANDA'); kupprdp:worker process DW01 started with worker id=1, pid=24, OS id=20532 to execute - SYS.KUPW$WORKER.MAIN('CASES_EXPORT', 'ANANDA'); kupprdp:worker process DW03 started with worker id=2, pid=25, OS id=20534 to execute - SYS.KUPW$WORKER.MAIN('CASES_EXPORT', 'ANANDA');
它显示为数据泵操作启动的会话的 PID。您可以用以下查询找到实际的 SID:
select sid, program from v$session where paddr in (select addr from v$process where pid in (23,24,25));
PROGRAM 列将对应警报日志文件中的名称显示进程 DM (为主进程)或 DW (为工作进程)。如果一个工作进程使用了并行查询,比如说 SID 23,您可以在视图 V$PX_SESSION 中看到它,并把它找出来。它将为您显示从 SID 23 代表的工作进程中运行的所有并行查询会话:
select sid from v$px_session where qcsid = 23;
从视图 V$SESSION_LONGOPS
中可以获得其它的有用信息来预测完成作业将花费的时间。
select sid, serial#, sofar, totalwork from v$session_longops where opname = 'CASES_EXPORT' and sofar != totalwork;
列 totalwork 显示总工作量,该列的 sofar 数量被加和到当前的时刻 — 因而您可以用它来估计还要花多长时间。
4、不同版本数据库之间数据互导
如将11g数据库的数据导入导10g数据库的服务器上
首先在11g服务器上导出
EXPDP USERID='SYS/cuc2009@cuc as sysdba' schemas=sybj directory=DATA_PUMP_DIR dumpfile=aa.dmp logfile=aa.log version=10.2.0.1.0
然后在10g数据库服务器上导入
IMPDP USERID='SYS/cuc2009@cucf as sysdba' schemas=sybj directory=DATA_PUMP_DIR dumpfile=aa.dmp logfile=aa.log version=10.2.0.1.0
三、物理备份
1、使用rman工具备份及恢复
说明:
1. RMAN是 ORACLE提供的一个备份与恢复的工具,可以用来执行完全或不完全的数据库恢复。
2. RMAN不能用于备份初始化参数文件和口令文件。
3. 与传统工具相比,RMAN具有独特的优势:跳过未使用的数据块。当备份一个RMAN备份集时,RMAN不会备份从未被写入的数据块,而传统的方式无法获知那些是未被使用的数据块。
4. RMAN可以进行增量备份(增量备份是针对于上一次备份(无论是哪种备份):备份上一次备份后,所有发生变化的文件)
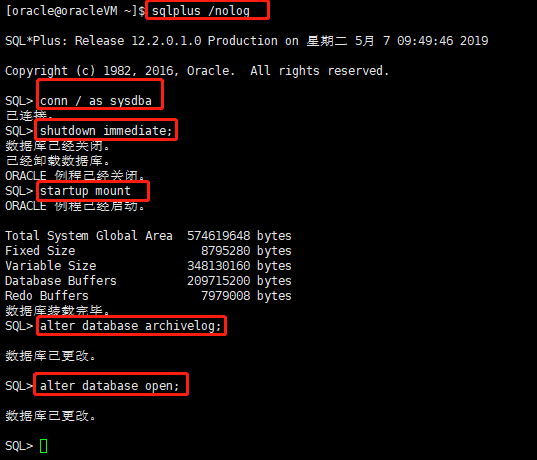
1、首先需要在将要备份的数据库服务器上切换服务器的归档模式,如果已经是归档模式了,那么可以跳过此步
# su oracle //切换到oracle用户
$ sqlplus /nolog //启动sqlplus
SQL> conn / as sysdba //以DBA的身份连接数据库
SQL> shutdown immediate; //立即关闭数据库
SQL> startup mount //启动实例并加载数据库,但不打开
SQL> alter database archivelog; //更改数据库为归档模式
SQL> alter database open; //打开数据库
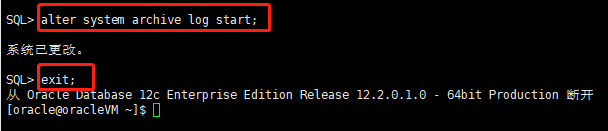
SQL> alter system archive log start; //启用自动归档
SQL> exit //退出
2、启动并连接到rman(恢复管理器)
可以开个专门用于备份的用户,不过这里使用了sys用户
$ rman target=sys/oracle@orcl
3、基本设置
具体路径可自己安装需求改,但是登录的用户需要对备份的目录有读写权限,目录建立方法可参考上面逻辑备份的备份目录建立
RMAN> configure default device type to disk; //设置默认的备份设备为磁盘
RMAN> configure device type disk parallelism 2; //设置备份的并行级别,通道数
RMAN> configure channel 1 device type disk format '/home/oracle/oracle_bak/bakup_%U'; //设置备份的文件格式,只适用于磁盘设备
RMAN> configure channel 2 device type disk format '/home/oracle/oracle_bak/bakup2_%U'; //设置备份的文件格式,只适用于磁盘设备
RMAN> configure controlfile autobackup on; //打开控制文件与服务器参数文件的自动备份
RMAN> configure controlfile autobackup format for device type disk to '/home/oracle/oracle_bak/ctl_%F'; //设置控制文件与服务器参数文件自动备份的文件格式

说明:
format:
%c:备份片的拷贝数(从1开始编号);
%d:数据库名称;
%D:位于该月中的天数(DD);
%M:位于该年中的月份(MM);
%F:一个基于DBID唯一的名称,这个格式的形式为c-xxx-YYYYMMDD-QQ,其中xxx位该数据库的DBID,YYYYMMDD为日期,QQ是一个1-256的序列;
%n:数据库名称,并且会在右侧用x字符进行填充,使其保持长度为8;
%u:是一个由备份集编号和建立时间压缩后组成的8字符名称。利用%u可以为每个备份集产生一个唯一的名称;
%p:表示备份集中的备份片的编号,从1开始编号;
%U:是%u_%p_%c的简写形式,利用它可以为每一个备份片段(既磁盘文件)生成一个唯一的名称,这是最常用的命名方式;
%t:备份集时间戳;
%T:年月日格式(YYYYMMDD);
channel的概念:一个channel是rman于目标数据库之间的一个连接,”allocate channel”命令在目标数据库启动一个服务器进程,同时必须定义服务器进程执行备份和恢复操作使用的I/O类型
通道控制命令可以用来:
- 控制rman使用的OS资源
- 影响并行度
- 指定I/O带宽的限制值(设置 limit read rate 参数)
- 指定备份片大小的限制(设置 limit kbytes)
- 指定当前打开文件的限制值(设置 limit maxopenfiles)
4、查看所有配置
RMAN> show all;
5、查看数据库方案报表
RMAN> report schema;
6、全量备份数据库及全量恢复
1、全量备份全库
RMAN> backup database plus archivelog delete input; //备份全库及控制文件、服务器参数文件与所有归档的重做日志,并删除旧的归档日志
2、备份表空间
这里也可以改为备份某个表空间,比如 back tablespace users;就是备份users的表空间
RMAN> backup tablespace system plus archivelog delete input; //备份指定表空间及归档的重做日志,并删除旧的归档日志
3、备份归档日志
RMAN> backup archivelog all delete input;
4、复制数据文件
RMAN> copy datafile 1 to '/home/oracle/oracle_bak/bak/system.copy';
说明一下,这里的数字1对应着命令report schema结果中的1
5、查看备份和文件副本
RMAN> list backup;
查看复制文件
RMAN> list copy
6、验证备份
RMAN> validate backupset 3;
这里说明一下,3这个数字代表的是备份集的编号,可以在list backup命令的结果中查看
7、从自动备份中恢复表空间
如果只丢失了特定的表空间的数据文件,那么可以选择只恢复这个表空间,而不是恢复整个数据库,表空间恢复可以在不关闭数据库的情况下进行,只需要将需要恢复的表空间offline
现在模拟某个表空间丢失或损坏
$ cd /database/oracle/oracle/oradata/orcl
$ mv users01.dbf users01_bak.dbf
现在开始恢复表空间users01
进入到rman
$ rman target=sys/oracle@orcl
使表空间脱机
RMAN> sql 'alter tablespace users offline immediate';
还原表空间
RMAN> restore tablespace users;
恢复表空间
RMAN> recover tablespace users;
将表空间联机
RMAN> sql 'alter tablespace users online';
8、恢复和复原全数据库
模拟数据文件丢失或损坏
$ cd /database/oracle/oracle/oradata/orcl
$ mv system01.dbf system01_bak.dbf
现在重新启动实例会报错
查看数据库当前状态
SQL> select status from v$instance;
登录到rman
$ rman target=sys/oracle@orcl
还原数据库
RMAN> restore database;
恢复数据库
RMAN> recover database;
打开数据库并登录数据库查看状态
RMAN> alter database open;
SQL> select status from v$instance;
此时数据文件已恢复了
9、某一个数据文件恢复
查看系统当前的数据文件
SQL> col file_name for a50
SQL> select file_id,file_name,status from dba_data_files;
查看文件状态
SQL> select file#,status from v$datafile;
模拟删除文件
$ mv sysaux01.dbf sysaux01_bak.dbf
将数据文件设置未offline状态
SQL> alter database datafile 3 offline;
此时数据文件状态未recover
现在来恢复数据文件
进入到rman
$ rman target=sys/oracle@orcl
还原和恢复数据文件
RMAN> restore datafile 3;
RMAN> recover datafile 3;
将数据文件设置为online并查看状态
SQL> alter database datafile 2 online;
SQL> select file#,status form v$datafile;
7、增量备份数据库及增量恢复
本节从一个例子来说明增量恢复,首先在数据库表中插入一条数据
接着用rman做一次全量备份(设置的参数可参考上面的设置)
RMAN> backup incremental level 0 database;
然后对数据库数据作更改,这里添加了一条数据
然后再做一次差异增量备份
RMAN> backup incremental level 1 database;
这里再添加一条数据
然后再进行一次备份
然后再做一次差异增量备份
RMAN> backup incremental level 1 database;
这里使用了scn的恢复方式
查看当前scn
SQL> select dbms_flashback.get_system_change_number from dual;
然后对数据进行删除
还有一种常用的获取到scn的方式就是执行下面语句,将删除的时间转换为scn
SQL> select timestamp_to_scn(to_timestamp('2011-08-03 10:00:00','YYYY-MM-DD HH:MI:SS')) from dual;
然后我们现在来进行恢复
关闭数据库实例,然后开启实例,单不打开数据库
SQL> shutdown immediate;
SQL> startup mount;
还原数据到指定scn的位置
RMAN> restore database until scn 2092046;
恢复数据到指定scn的位置
RMAN> recover database until scn 2092046;
因为是不完全恢复(指定了某个位置),所以在打开数据库的命令要加上resetlogs
SQL> alter database open resetlogs;
然后再看看数据库,发现数据已经恢复了
如果需要基于时间点的恢复,可以参考一下(参考网上资料,没实践过)
SQL> ALTER SESSION SET NLS_DATE_FORMAT='YYYY-MM-DD HH24:MI:SS';
SQL> shutdown immediate;
SQL> startup mount;
RMAN> restore database until time "to_date('2019-7-19 13:19:00','YYYY-MM-DD HH24:MI:SS')";
RMAN> recover database until time "to_date('2019-7-19 13:19:00','YYYY-MM-DD HH24:MI:SS')";
SQL> alter database open resetlogs;
基于日志序列的恢复(参考网上资料,没实践过):
SQL> shutdown immediate;
SQL> startup mount;
RMAN> restore database until SEQUENCE 100 thread 1; //100是日志序列
RMAN> recover database until SEQUENCE 100 thread 1;
SQL> alter database open resetlogs;
日志序列查看命令:
SQL>select * from v$log;
其中有一个sequence字段.resetlogs就会把sequence 置为1
8、删除备份文件
删除无效备份。首先执行CROSSCHECK命令核对备份集,如果发现备份无效(比如备份对应的数据文件损坏或丢失),RMAN会将该备份集标记为 EXPIRED状态。要删除相应的备份记录,可以执行DELETE EXPIRED BACKUP命令:
RMAN> DELETE EXPIRED BACKUP;
删除EXPIRED副本,如下所示:
RMAN> DELETE EXPIRED COPY;
删除特定备份集,如下所示:
RMAN> DELETE BACKUPSET 19;
删除特定备份片,如下所示:
RMAN> DELETE BACKUPPIECE 'd:/backup/DEMO_19.bak';
删除所有备份集,如下所示:
RMAN> DELETE BACKUP;
删除特定映像副本,如下所示:
RMAN> DELETE DATAFILE COPY 'd:/backup/DEMO_19.bak';
删除所有映像副本,如下所示:
RMAN> DELETE COPY;
2、冷备
冷备相对来说比较简单,基本原来就是手动将日志文件、数据文件、控制文件复制到备份的目录
基本步骤是:shutdown数据库—> copy文件—> start数据库
$ sqlplus sys/ as sysdba
SQL> shutdown immediate;
SQL> exit;
$ cd /database/oracle/oracle/oradata/orcl //数据库数据目录
$ cp -p * /home/oracle/oracle_bak //复制所有文件及目录到备份目录下
$ sqlplus sys/ as sysdba
SQL> startup;
说明:
*.dbf:数据文件
*.ctl:控制文件
*.log:日志文件
3、使用归档模式热备
说明:归档模式热备份的数据库是必须在归档模式下的(有点废话,但oracle默认安装是在非归档模式下)
将数据库转换为归档模式(注意数据库必须已装载到此实例并且不在任何实例中打开):
$ sqlplus / as sysdba //登录数据库
SQL> shutdown immediate;
SQL> startup mount;(startup nomount 启动实例;startup mount 启动实例加载数据库; startup 启动实例加载数据库打开数据库)
SQL> alter database archivelog;
一些归档的相关操作记录:
SQL> archive log list;--查看是否出于归档模式;
SQL> select name from v$archived_log; --查询归档日志
(10G之后)
SQL> alter database archivelog;
SQL> alter database noarchivelog;
(10G之前)
SQL> archive log stop;
SQL> archive log start;
SQL> alter system set log_archive_start =true scope =spfile;
SQL> alter system set log_achive_start=false scope=spfile;
热备的步骤如下:
SQL> shutdown immediate;
SQL> startup mount;
SQL> alter database archivelog;
SQL> alter database open;
SQL> alter tablespace users begin backup; --设置备份模式;
$ cp -Rp oracle/ /home/oracle/oracle_bak/;--拷贝
SQL> alter tablespace users end backup ;--结束备份状态
SQL> alter system switch logfile--切换日志,使用当前日志归档
四、数据库日常备份计划及脚本参考
1、如果是使用RMAN
备份计划可参考:
1.星期天晚上:全备份
2.星期一晚上:增量备份
3.星期二晚上:增量备份
4.星期三晚上:累积备份
5.星期四晚上:增量备份
6.星期五晚上:增量备份
7.星期六晚上:增量备份
如果星期二需要恢复的话,只需要1+2
如果星期四需要恢复的话,只需要1+4
如果星期五需要恢复的话,只需要1+4+5
如果星期六需要恢复的话,只需要1+4+5+6
如果需要自动备份,可使用备份脚本+crontab的方式执行
执行脚本命令:
rman target / msglog=bakl0.log cmdfile=bakl0 (/表示需要连接的目标数据库,msglog表示日志文件,cmdfile表示的是脚本文件)
如:rman target sys/oracle@orcl msglog=/home/oracle/oracle_bak/bakl1.log cmdfile=/home/oracle/oracle_bak
脚本内容为:
run{
allocate channel cha1 type disk;
backup
incremental level 0
format '/u01/rmanbak/inc0_%u_%T'(u表示唯一的ID,大T是日期,小t是时间)
tag monday_inc0 //标签可以顺便起,没关系
database;
release channel cha1;
}
改动以上的备份等级可弄出全量、增量、累积备份的脚本,然后使用crontab自动执行即可
2、如果是使用备份脚本
备份脚本内容如下:
#!/bin/sh
export ORACLE_BASE=/data/oracle
export ORACLE_HOME=$ORACLE_BASE/product/11.2.0/db_1
export ORACLE_SID=orcl
export ORACLE_TERM=xterm
export PATH=$ORACLE_HOME/bin:/usr/sbin:$PATH
export LD_LIBRARY_PATH=$ORACLE_HOME/lib:/lib:/usr/lib
export LANG=C
export NLS_LANG=AMERICAN_AMERICA.ZHS16GBK
#以上代码为Oracle数据库运行账号oracle的系统环境变量设置,必须添加,否则crontab任务计划不能执行。
# oracle用户的系统环境变量路径:/home/oracle/.bash_profile
date=date +%Y_%m_%d #获取系统当前日期时间
days=7 #设置删除7天之前的备份文件
orsid=192.168.0.198:1521/orcl #Oracle数据库服务器IP、端口、SID
orowner=OSYUNWEI #备份此用户下面的数据
bakuser=OSYUNWEI #用此用户来执行备份,必须要有备份操作的权限
bakpass=OSYUNWEI #执行备注的用户密码
bakdir=/backup/oracledata #备份文件路径,需要提前创建好
bakdata=$orowner"_"$date.dmp #备份数据库名称
baklog=$orowner"_"$date.log #备份执行时候生成的日志文件名称
ordatabak=$orowner"_"$date.tar.gz #最后保存的Oracle数据库备份文件
cd $bakdir #进入备份目录
mkdir -p $orowner #按需要备份的Oracle用户创建目录
cd $orowner #进入目录
exp $bakuser/$bakpass@$orsid grants=y owner=$orowner file=$bakdir/$orowner/$bakdata log=$bakdir/$orowner/$baklog #执行备份
tar -zcvf $ordatabak $bakdata $baklog #压缩备份文件和日志文件
find $bakdir/$orowner -type f -name "*.log" -exec rm {} \; #删除备份文件
find $bakdir/$orowner -type f -name "*.dmp" -exec rm {} \; #删除日志文件
find $bakdir/$orowner -type f -name "*.tar.gz" -mtime +$days -exec rm -rf {} \; #删除7天前的备份(注意:{} \中间有空格)
然后添加脚本执行权限:
chmod +x /backup/oracledata/ordatabak.sh #添加脚本执行权限
然后将脚本添加至crontab执行计划即可
参考资料:
逻辑备份:
https://www.cnblogs.com/promise-x/p/7477360.html(可作为expdp/impdp命令参考)
https://www.cnblogs.com/huacw/p/3888807.html
https://www.cnblogs.com/wishyouhappy/p/3700313.html
RMAN备份:
https://www.cnblogs.com/hllnj2008/p/4117792.html
https://www.cnblogs.com/wishyouhappy/p/3700313.html
https://blog.csdn.net/shudaqi2010/article/details/75300437
https://blog.csdn.net/weixin_41078837/article/details/80609077
https://blog.csdn.net/imliuqun123/article/details/79543378
备份脚本:
http://www.ttlsa.com/oracle/linux-auto-backup-oracle-database/
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/160790.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...