大家好,又见面了,我是你们的朋友全栈君。
数据挖掘之关联规则挖掘
关联规则挖掘(Association Rule Mining)最早是由Agrawal等人提出。最初的动机是解决购物篮分析(Basket Analysis)问题,目的是发现交易数据库(Transaction Database)中不同商品之间的联系规则。
1. 定义
关联规则是描述在一个交易中物品之间同时出现的规律的知识模式,更确切的说,关联规则是通过量化的数字描述物品X的出现对物品Y的出现有多大的影响。
关联分析 association analysis:关联分析用于发现隐藏在大型数据集中的令人感兴趣的联系,所发现的模式通常用关联规则或频繁项集的形式表示。


形式化描述
• 关联规则挖掘的交易数据集记为D
• D ={T1,T2,…,Tk,…,Tn},Tk(k=1,2,…,n)称为交易,每个交易有唯一的标识,记作TID。
• 元素 im(m=1,2,…,p)称为项。在交易数据集中,每个项 ik 代表一种商品的编号或名称。
• 设 I = { i1,i2,…,im}是 D 中全体项组成的集合。D 中的每个事务Tk都是 I 的一个子集,即 Tk ⊆ I ( j=1,2,…,n)。
• 由 I 中部分或全部项构成的一个集合称为项(itemset),任何非空项集中均不含有重复项。若 I 包含m个项,那么可以产生2m个非空项集。
• 设 X 是一个 I 中项的集合,如果 X ⊆ Tk,那么称交易 Tk 包含项集 X。
◆ 若X,Y为项集,X⊂I, Y⊂I,并且X∩Y=Ø,则形如X→Y的表达式称为关联规则。
度量
- 支持度(support)
支持度是对关联规则重要性的衡量,反映关联是否是普遍存在的规律,体现这条规则在所有交易中有多大的代表性。记为:support(X→Y)

- 置信度(confidence)
置信度(或可信度、信任度)是对关联规则准确度的衡量,度量关联规则的强度。即在所有出现了X的活动中出现Y的频率,说明规则X→Y的必然性有多大。记为confidence(X→Y)。

基本概念
- 挖掘关联规则
在给定一个交易数据集D上,挖掘关联规则问题就是产生支持度和置信度分别大于等于用户给定的最小支持度阈值和最小置信度阈值的关联规则。 - 支持度计数
一般地,项集支持度是一个0~1的数值,由于在计算项集支持度时,所有分母是相同的,所以可以用分子即该项集出现的次数来代表支持度,称为支持度计数。 - 频繁项集
给定全局项集 I 和交易数据集 D,对于 I 的非空项集 I1,若其支持度大于或等于最小支持度阈值min_sup,则称 I1 为频繁项集(Frequent Itemsets)。 - k-项集和频繁 k-项集
对于I的非空子集 I1,若项集 I1 中包含有 I 中的 k 个项,称 I1 为 k-项集。若 k-项集 I1 是频繁项集,称为频繁 k-项集。 - 超集
如果一个集合S2中的每一个元素都在集合S1中,且集合S1中可能包含S2中没有的元素,则集合S1就是S2的一个超集,反过来,S2是S1的子集。 S1是S2的超集,若S1中一定有S2中没有的元素,则S1是S2的真超集,反过来S2是S1的真子集。
2. 基本过程
① 找频繁项集:通过用户给定最小支持度阈值min_sup,寻找所有频繁项集,即仅保留大于或等于最小支持度阈值的项集。
② 生成强关联规则:通过用户给定最小置信度阈值min_conf,在每个最大频繁项集中寻找关联规则,即删除不满足最小置信度阈值的规则。
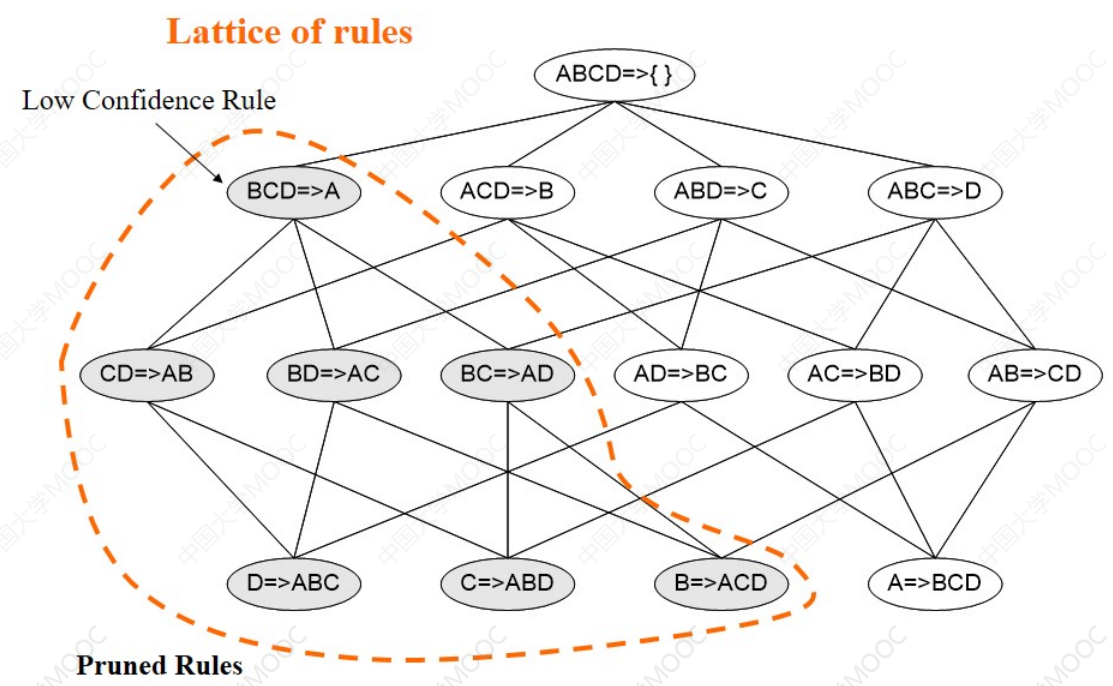
注意:一个频繁X项集能够生成2X-2个候选关联规则
3. 原始方法
蛮力法(brute-force approach):计算每个可能的规则的支持度和置信度
计算代价过高(可能提取的规则的数量达指数级)
4. Apriori
先验原理:
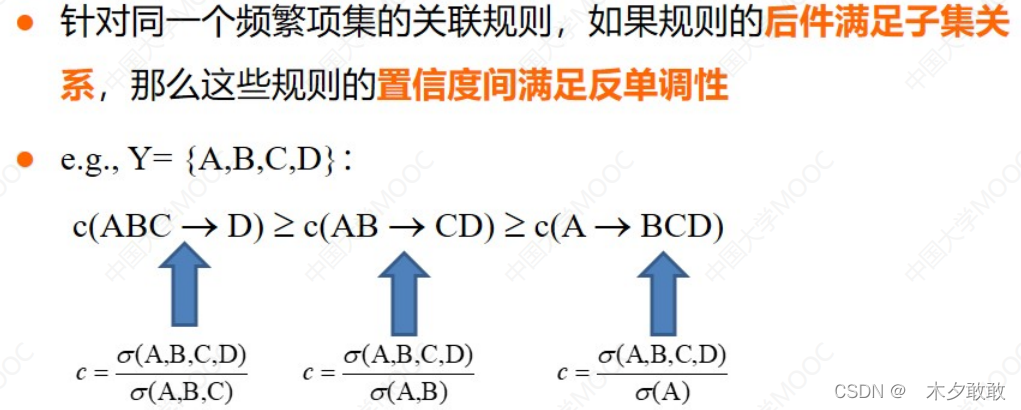
· 如果一个项集是频繁的,则它的所有子集一定也是频繁的;相反,如果一个项集是非频繁的,则它的所有超集也一定是非频繁的。→提前剪枝
注意事项:
- 项的字典序:尽管集合具有无序性,但为了快速连接操作,通常对所有商品做一个默认的排序(类似于建立一个字典索引)。
- 项的连接:可以降低候选项的生成

例子:
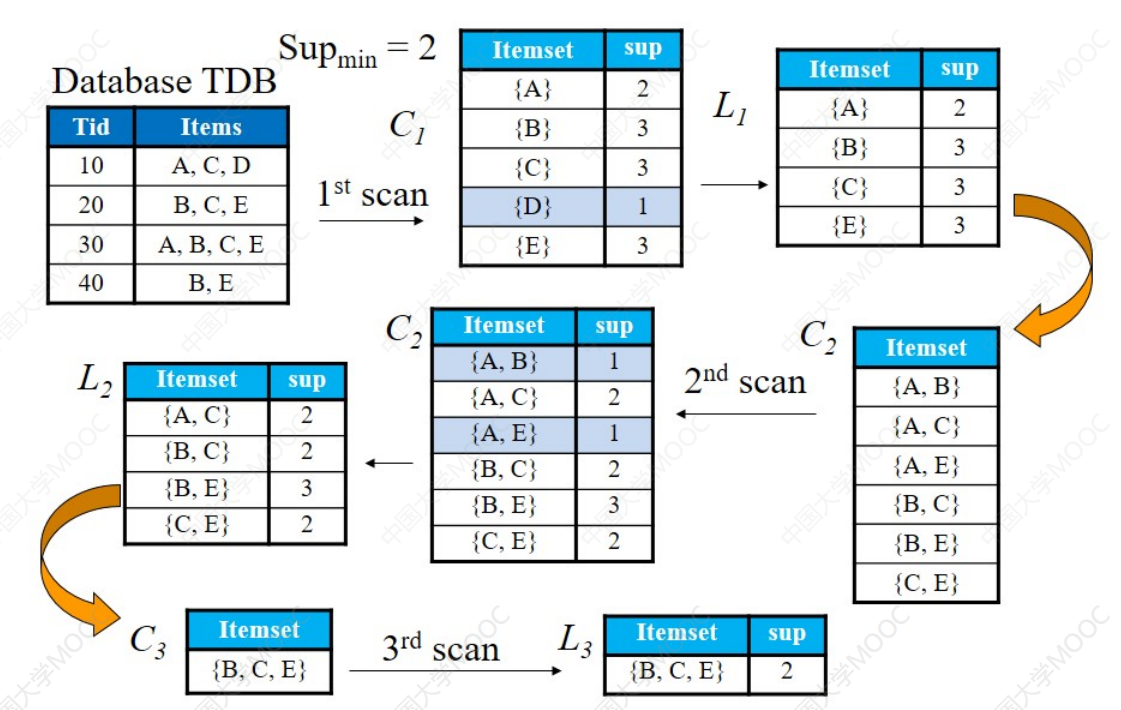
算法特点: - 多次扫描数据库
- 候选项规模庞大
- 计算支持度开销大
提高算法性能的方法: - 散列项集计数 Hash-based itemset counting
- 事务压缩 Transaction reduction
- 划分 Partitioning
- 采样 Sampling
FPGrowth
基本思想:
- 只扫描数据库两遍,构造频繁模式树(FP-Tree)
- 自底向上递归产生频繁项集
- FP树是一种输入数据的压缩表示,它通过逐个读入事务,并把每个事务映射到FP树中的一条路径来构造。
构造FP树: - 扫描数据库,得到频繁1-项集,并把项按支持度递减排序
- 再一次扫描数据库,建立FP-tree(遍历每一个事务,构造成一条路径,并给项计数)

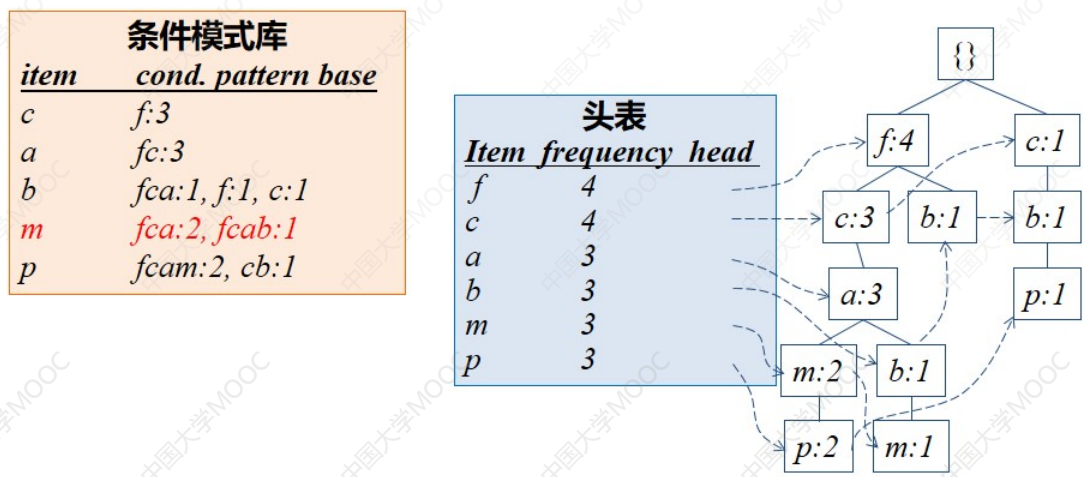
生成条件模式: - 从FP-tree的头表开始
- 按照每个频繁项的连接遍历FP-tree
- 列出能够到达此项的所有前缀路径,得到条件模式基
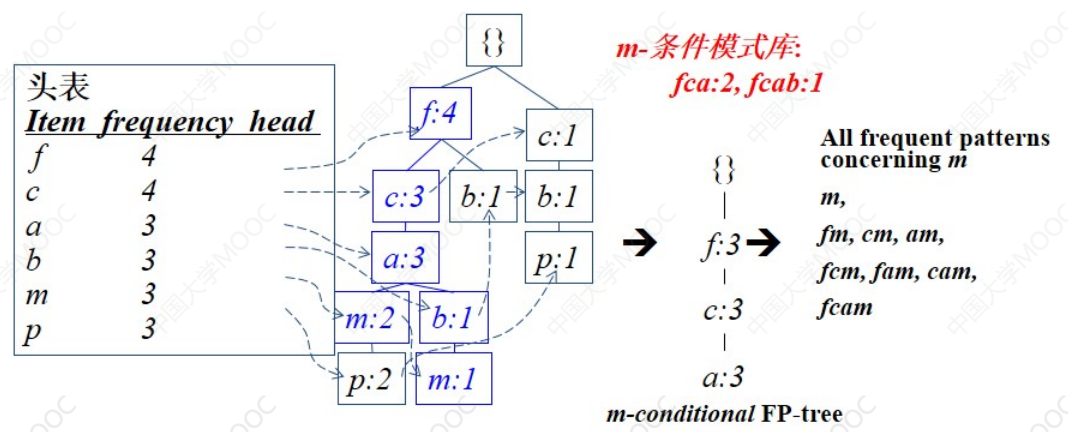
递归生成FP树:
对每个模式库,计算库中每个项的支持度,用模式库中的频繁项建立FP-tree
优点: - 完备性:不会打破交易中的任何模式,包含了频繁模式挖掘所需的全部信息
- 紧密性:支持度降序排列,支持度高的项在FP-tree中共享的机会也高;绝不会比原数据库大
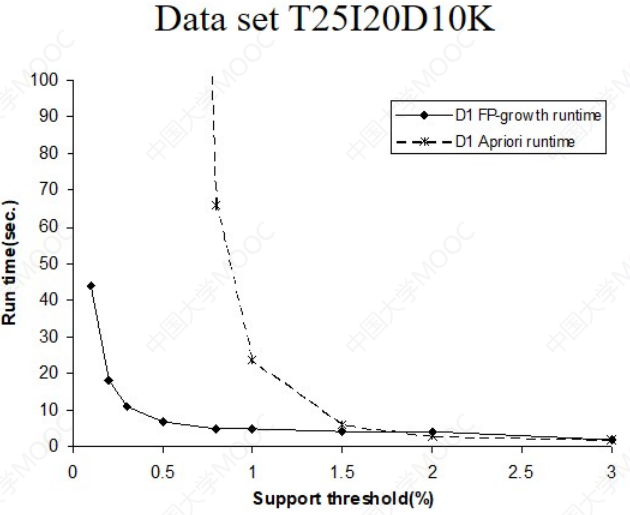
Apriori和FP-tree性能对比
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/160718.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...

{kind=link}