大家好,又见面了,我是你们的朋友全栈君。
找到这个教程
https://www.cnblogs.com/OliverQin/p/8966321.html
我要导入CSV文件,已经放在相同目录之下。
import pandas as pd
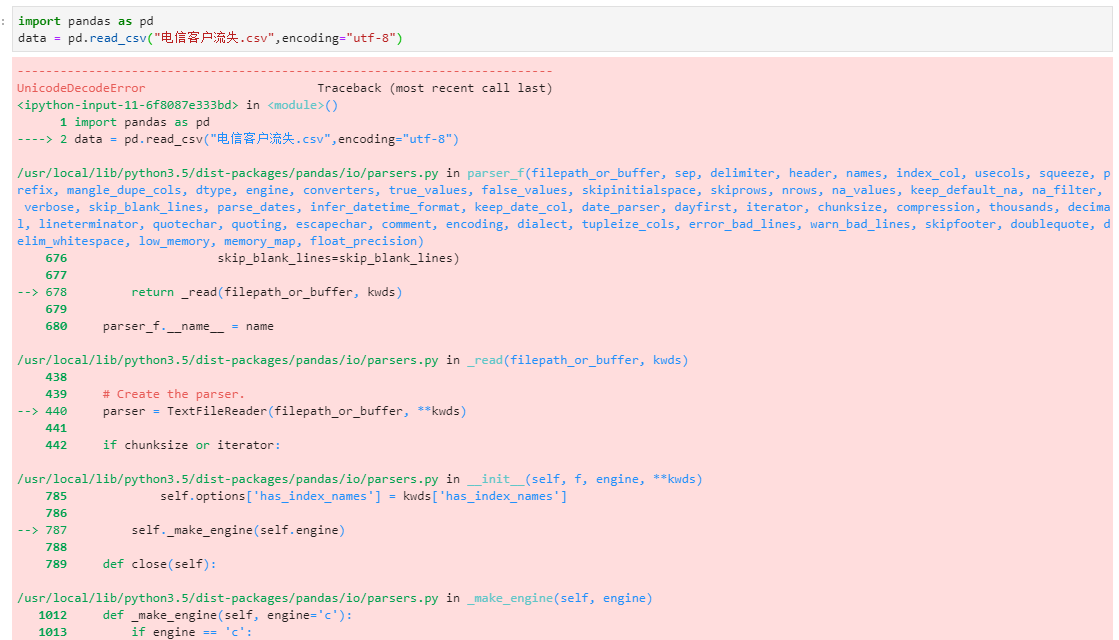
data = pd.read_csv("电信客户流失.csv",encoding="utf8")报错如下
---------------------------------------------------------------------------
UnicodeDecodeError Traceback (most recent call last)
<ipython-input-5-6f8087e333bd> in <module>()
1 import pandas as pd
----> 2 data = pd.read_csv("电信客户流失.csv",encoding="utf-8")
/usr/local/lib/python3.5/dist-packages/pandas/io/parsers.py in parser_f(filepath_or_buffer, sep, delimiter, header, names, index_col, usecols, squeeze, prefix, mangle_dupe_cols, dtype, engine, converters, true_values, false_values, skipinitialspace, skiprows, nrows, na_values, keep_default_na, na_filter, verbose, skip_blank_lines, parse_dates, infer_datetime_format, keep_date_col, date_parser, dayfirst, iterator, chunksize, compression, thousands, decimal, lineterminator, quotechar, quoting, escapechar, comment, encoding, dialect, tupleize_cols, error_bad_lines, warn_bad_lines, skipfooter, doublequote, delim_whitespace, low_memory, memory_map, float_precision)
676 skip_blank_lines=skip_blank_lines)
677
--> 678 return _read(filepath_or_buffer, kwds)
679
680 parser_f.__name__ = name
/usr/local/lib/python3.5/dist-packages/pandas/io/parsers.py in _read(filepath_or_buffer, kwds)
438
439 # Create the parser.
--> 440 parser = TextFileReader(filepath_or_buffer, **kwds)
441
442 if chunksize or iterator:
/usr/local/lib/python3.5/dist-packages/pandas/io/parsers.py in __init__(self, f, engine, **kwds)
785 self.options['has_index_names'] = kwds['has_index_names']
786
--> 787 self._make_engine(self.engine)
788
789 def close(self):
/usr/local/lib/python3.5/dist-packages/pandas/io/parsers.py in _make_engine(self, engine)
1012 def _make_engine(self, engine='c'):
1013 if engine == 'c':
-> 1014 self._engine = CParserWrapper(self.f, **self.options)
1015 else:
1016 if engine == 'python':
/usr/local/lib/python3.5/dist-packages/pandas/io/parsers.py in __init__(self, src, **kwds)
1706 kwds['usecols'] = self.usecols
1707
-> 1708 self._reader = parsers.TextReader(src, **kwds)
1709
1710 passed_names = self.names is None
pandas/_libs/parsers.pyx in pandas._libs.parsers.TextReader.__cinit__()
pandas/_libs/parsers.pyx in pandas._libs.parsers.TextReader._get_header()
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xb5 in position 0: invalid start byte
错误类型
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xb5 in position 0: invalid start byte过了一会儿突然可以了,真实奇怪
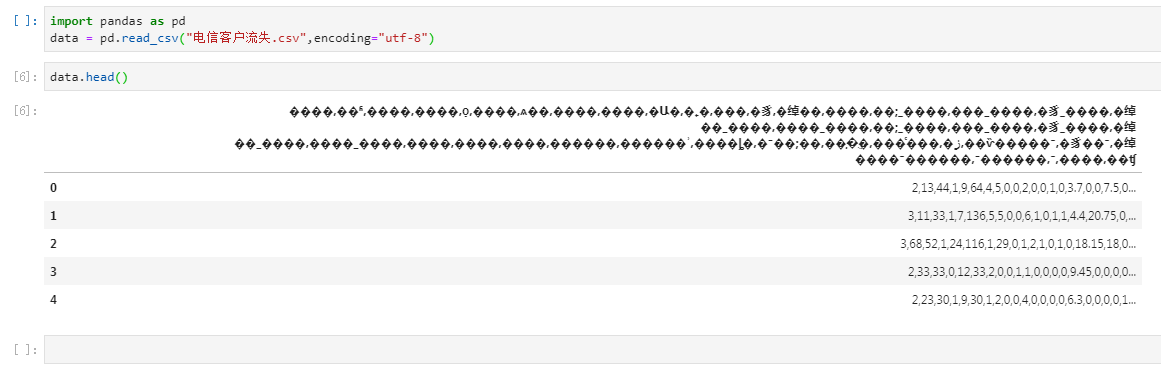
这时我在看这篇博客,
https://blog.csdn.net/xxceciline/article/details/80405129
然后我再次运行,又出现错误
使用这个链接的方法
https://www.cnblogs.com/pengei/p/6407077.html
==========解决方案============
第一种:
第一行加:# -*- coding: utf-8 -*-
第二种:
引用处设置默认编码格式
# coding: utf-8
第三种:
使用中文处将中文unicode编码
python3以后第二种方式。
还是一样的报错
#-*- coding : utf-8 -*-
# coding: utf-8
import pandas as pd
data = pd.read_csv("电信客户流失.csv",encoding="utf-8")
我尝试这个方法行不通
在百度上的方法都解决不了,我用谷歌搜索解决方案
我的最终解决方案,来自这里
#-*- coding : utf-8 -*-
# coding: utf-8
import pandas as pd
data = pd.read_csv("电信客户流失.csv",encoding="unicode_escape")
说明刚才的错误没有了
用read_csv之后,里面加上encoding=’gbk’就可以了。
现在是什么问题都没有了
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/160459.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...