大家好,又见面了,我是你们的朋友全栈君。
【初识及基本操作】
一、什么是Git?
定义:Git是分布式版本控制系统。
1.1什么是版本控制
我们可以回想以下,在我们上学毕业要写论文或是准备一份演讲稿的时候,都会用文件去保存和管理一些文档之类的东西,当我们对一个文档进行了无数次的修改,同时为了区分保存,也绞尽脑汁想了了很多有乐趣的名字,就像下图这样!
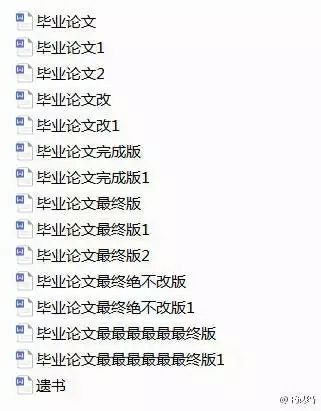

以上是使用文件或文件夹进行版本管理,以上方式有缺点:
- 多个文件,保留所有版本时,需要将多个文件保存在本地
- 协同操作,多人协同操作时,需要将文件发来发去…
- 容易丢失,被删除意味着永远失去(有人会说,可以选择网盘,孺子可教也,但是能确定网盘安全么?!或是没网你也能下载?)
为了解决上述问题,应运而生了版本管理工具:
- VSS– Visual Source Safe 【已经摒弃不用】
此工具是Microsoft提供的,是使用的相当普遍的工具之一,他可以与VS.net进行无缝集成,成为了独立开发人员和小型开发团队所适合的工具,基本上Window平台上开发的中小型企业,当规模较大后,其性能通常是无法忍受的,对分支与并行开发支持的比较有限。 - CVS–Concurrent Versions System
此工具是一个开源工具,与后面提到的SVN是同一个厂家:Collab.Net提供的。CVS是源于unix的版本控制工具,对于CVS的安装和使用最好对unix的系统有所了解能更容易学习,CVS的服务器管理需要进行各种命令行操作。目前,CVS的客户端有winCVS的图形化界面,服务器端也有CVSNT的版本,易用性正在提高。 - SVN –CollabNet Subversion 【集中式版本控制系统;服务端有所有版本;客户端只有一个版本】
此工具是在CVS 的基础上,由CollabNet提供开发的,也是开源工具,应用比较广泛。他修正cvs的一些局限性,适用范围同cvs,目前有一些基于SVN的第三方工具,如TortoiseSVN,是其客户端程序,使用的也相当广泛。在权限管理,分支合并等方面做的很出色,他可以与Apache集成在一起进行用户认证。不过在权限管理方面目前还没有个很好用的界面化工具,SVNManger对于已经使用SVN进行配置的项目来说,基本上是无法应用的,但对于从头开始的项目是可以的,功能比较强大,但是搭建svnManger比较麻烦。是一个跨平台的软件,支持大多数常见的操作系统。作为一个开源的版本控制系统,Subversion 管理着随时间改变的数据。 这些数据放置在一个中央资料档案库中。 这个档案库很像一个普通的文件服务器, 不过它会记住每一次文件的变动。 这样你就可以把档案恢复到旧的版本, 或是浏览文件的变动历史。Subversion 是一个通用的系统, 可用来管理任何类型的文件, 其中包括了程序源码。 - BitKeeper
是由BitMover公司提供的,BitKeeper自称是“分布式”可扩缩SCM系统。不是采用C/S结构,而是采用P2P结构来实现的,同样支持变更任务,所有变更集的操作都是原子的,与svn,cvs一致。 - GIT
Git是一个开源的分布式版本控制系统,用以有效、高速的处理从很小到非常大的项目版本管理.Git 是 Linus Torvalds 为了帮助管理 Linux 内核开发而开发的一个开放源码的版本控制软件。Torvalds 开始着手开发 Git 是为了作为一种过渡方案来替代 BitKeeper,后者之前一直是 Linux 内核开发人员在全球使用的主要源代码工具。开放源码社区中的有些人觉得 BitKeeper 的许可证并不适合开放源码社区的工作,因此 Torvalds 决定着手研究许可证更为灵活的版本控制系统。尽管最初 Git 的开发是为了辅助 Linux 内核开发的过程,但是我们已经发现在很多其他自由软件项目中也使用了 Git。例如 最近就迁移到 Git 上来了,很多 Freedesktop 的项目也迁移到了 Git 上。
版本管理工具都一般包含客户端和服务端,他们的共同点是:
- 客户端(用户):本地编写内容,向服务端获取或提交内容
- 服务端(网盘):保存所有版本的文件
集中式版本控制系统 VS 分布式版本控制系统
先说集中式版本控制系统,版本库是集中存放在中央服务器的,而干活的时候,用的都是自己的电脑,所以每次都要先从中央服务器取得最新的版本,然后开始干活,干完活了,再把自己的活推送给中央服务器。每次提交之前,都需要先查看别人有没有修改过,如果SVN文档被修改了,你就需要先更新别人修改过的文件更新到自己的电脑上,再把自己更改的上传!如果未更新而直接提交的话就会因为库内文件比对不一致的问题而报错!!!中央服务器就好比是一个图书馆,你要改一本书,必须先从图书馆借出来,然后回到家自己改,改完了,再放回图书馆。
集中式版本控制系统最大的毛病就是必须联网才能工作,如果在局域网内还好,带宽够大,速度够快,可如果在互联网上,遇到网速慢的话,可能提交一个10M的文件就需要5分钟,这还不得把人给憋死啊。
那分布式版本控制系统与集中式版本控制系统有何不同呢?首先,分布式版本控制系统根本没有“中央服务器”,每个人的电脑上都是一个完整的版本库,这样,你工作的时候,就不需要联网了,因为版本库就在你自己的电脑上。既然每个人电脑上都有一个完整的版本库,那多个人如何协作呢?比方说你在自己电脑上改了文件A,你的同事也在他的电脑上改了文件A,这时,你们俩之间只需把各自的修改推送给对方,就可以互相看到对方的修改了。
和集中式版本控制系统相比,分布式版本控制系统的安全性要高很多,因为每个人电脑里都有完整的版本库,某一个人的电脑坏掉了不要紧,随便从其他人那里复制一个就可以了。而集中式版本控制系统的中央服务器要是出了问题,所有人都没法干活了。
在实际使用分布式版本控制系统的时候,其实很少在两人之间的电脑上推送版本库的修改,因为可能你们俩不在一个局域网内,两台电脑互相访问不了,也可能今天你的同事病了,他的电脑压根没有开机。因此,分布式版本控制系统通常也有一台充当“中央服务器”的电脑,但这个服务器的作用仅仅是用来方便“交换”大家的修改,没有它大家也一样干活,只是交换修改不方便而已。
当然,Git的优势不单是不必联网这么简单,后面我们还会看到Git极其强大的分支管理,把SVN等远远抛在了后面。分布式版本控制系统除了Git外,还有很对不同的软件。这些分布式版本控制系统各有特点,但最快、最简单也最流行的依然是Git!
二、Git安装(windows下)
1、我们需要在官网上下载Windows版的Git:msysgit;官方下载地址:http://msysgit.github.io,安装选定要安装的目录(路径杜绝中文),剩下的按照默认安装即可!奉上网上搜到的GIt安装教程!大家参考着安装!可能会有版本诧异但大体无妨!
2、安装完成后,在开始菜单里找到“Git”->“Git Bash”,弹出一个类似命令行的窗口;或是在CMD命令提示符下,输入git回车可以看到很多提示,就说明Git安装成功!
3、安装完成后,还需要最后一步设置,在命令行输入:
|
1
2
3
|
$ git config --global user.name "zh_book"
$ git config --global user.email "zh_book@live.com"
zh_book与zh_book@live.com是我测试用的用户名和Email地址,大家执行时请换成自己的。
|
因为Git是分布式版本控制系统,所以,每个机器都必须自报家门:你的名字和Email地址。你也许会担心,如果有人故意冒充别人怎么办?这个不必担心,首先我们相信大家都是善良无知的群众,其次,真的有冒充的也是有办法可查的。
注意git config命令的--global参数,用了这个参数,表示你这台机器上所有的Git仓库都会使用这个配置,当然也可以对某个仓库指定不同的用户名和Email地址。
三、创建版本库
版本库又名仓库,英文名repository,你可以简单理解成一个目录,这个目录里面的所有文件都可以被Git管理起来,每个文件的修改、删除,Git都能跟踪,以便任何时刻都可以追踪历史,或者在将来某个时刻可以“还原”。
所以,创建一个版本库非常简单,首先,选择一个合适的地方,创建一个空目录:
|
1
2
3
|
$ mkdir learngit
$ cd learngit
$ pwd pwd命令用于显示当前目录。
|
当然,并不是非要创建一个空目录才能进行git相关的操作,也可以是某个要管理的程序目录下,右击选择 git bash here 打开git的ide窗口操作模式,然后通过git init命令把这个目录变成Git可以管理的仓库:
|
1
|
$ git init
|
注意:执行初始化命令后,会生成一个.Git文件夹(默认为隐藏的),用于保存git相关所有信息,这个目录是Git来跟踪管理版本库的,没事一般不要随便修改这个目录里面的文件,不然改乱了,就把Git仓库给破坏了。
四、把文件添加到版本库
既然我们初始化了版本库,那就可以使用git来管理当前文件夹下所有文件,具体操作命令请往下看。
1、查看工作区状态及修改详细:
|
1
2
|
$ git status //查看工作区状态
$ git diff //若git status提示有文件被修改,则可执行此命令查看修改的内容
|
注意:执行git status命令会看到两部分,上边是文件提交的暂存区,下边是文件所在的工作区;在当前工作区,而没有提交到暂存区的文件颜色是红色的,提交到暂存区的文件是绿色的,如果工作台面是干净的话,证明所有文件已提交到仓库!
2、用命令git add告诉Git,把文件(文件夹)添加到仓库:(可以反复执行多次) –把文件修改添加到暂存区;
|
1
2
3
4
|
语法:git add 文件名
例如:我在当前git仓库的文件下创建一个readme.txt文件,里边写一些内容,然后把这个添加到暂存区
$ git add readme.txt 也可以执行$ git add . 把当前文件下的所有文件都提交到暂存区
|
注意点:
千万不要使用Windows自带的记事本编辑任何文本文件。原因是Microsoft开发记事本的团队使用了一个非常弱智的行为来保存UTF-8编码的文件,他们自作聪明地在每个文件开头添加了0xefbbbf(十六进制)的字符,你会遇到很多不可思议的问题,比如,网页第一行可能会显示一个“?”,明明正确的程序一编译就报语法错误,等等,都是由记事本的弱智行为带来的。建议你下载Notepadz++代替记事本,不但功能强大,而且免费!
3、用命令 git commit 告诉Git,把文件提交到仓库:【语法:git commit -m ‘自定义提交信息’】
|
1
|
$ git commit -m "first file readme.txt"
|
–把暂存区的所有内容提交到当前分支(仓库)
简单解释一下git commit命令,-m后面输入的是本次提交的说明,可以输入任意内容,当然最好是有意义的,这样你就能从历史记录里方便地找到改动记录。git commit命令执行成功后会告诉你,1个文件被改动(我们新添加的readme.txt文件),插入了两行内容(readme.txt有两行内容)。为什么Git添加文件需要add,commit一共两步呢?因为commit可以一次提交很多文件,所以你可以多次add不同的文件。
4、其他操作命令:
|
1
2
3
|
git ls-tree head 查看版本(分支)中所有的文件
git ls-files -s 查看暂存区和版本中所有文件的详细信息
git ls-files 仅查看所有的文件名
|
五、版本回退
在上边我们既然学会了往版本库中提交文件的方法,何不防多提交几次熟练下操作!现在有个问题,我想回到你上一次提交的版本状态下,怎么办?别急咱慢慢说!
1、我们可以先看看这几次提交的历史记录,使用 git log命令!
git log命令显示从最近到最远所有的提交日志,如果嫌输出信息太多,看得眼花缭乱的,可以试试加上--pretty=oneline参数,以显示精简信息!
同时 Git 提供了一个命令git reflog用来记录你的每一次命令!
|
1
2
3
|
$ git log //显示所有操作日志
$ git log --pretty=oneline //显示精简信息
$ git reflog //查看所有的命令历史
|
此处需要说一下:在查看日志的时候,我们发现每次提交的版本都会对应的有一大串数字和字母组成的很长的一段,这个是当前的版本号!它是一个SHA1计算出来的一个非常大的数字,用十六进制表示且唯一。每提交一个新版本,实际上Git就会把它们自动串成一条时间线。如果使用可视化工具查看Git历史,就可以更清楚地看到提交历史的时间线。
2、回退版本:
首先,Git必须知道当前版本是哪个版本。在Git中,用HEAD表示当前版本,也就是最新的提交的版本,上一个版本就是HEAD^,上上一个版本就是HEAD^^,当然往上100个版本写100个^比较容易数不过来,所以写成HEAD~100。如果我们要回退到上一个版本,就可以使用git reset命令:
|
1
|
$ git reset --hard HEAD^
|
但是这个命令虽然可以回到上一次版本,但是如果是要回到多个之前的版本,就有些不现实。我们上边说过有他的版本号且唯一,为什么不用查到的版本号呢?这个多方便!
|
1
2
|
例如:我上一个版本号是:92dea56e57466115efab904a5f1d9adc361111e8
回滚命令:git reset --hard 92dea56e57466115efab904a5f1d9adc361111e8
|
所以,我们可以使用命令:git reset –hard 版本唯一ID 回退到指定的版本,可以是之后的版本。然后我们就可以查看下工作区的文件,会很神奇的发现回到了上一次的版本。荣们可以通过 git log 查看会发现最新的那个版本记录已经不见了!突然之间,我跟你提了个要求,我想再回到之初最新的那个版本上,你怎么做?是不是傻眼了,上一个版本的记录都没有了!还怎么回去?哪儿有卖后悔药的?
别担心,还真有卖后悔药的,身边最近的,git就提供了一个方法!上边不是说过有个 git reflog 方法可以查看所有操作命令记录,我们可以通过这条命令查到所有操作的首位都有一段字母或数字混合的一段,他就是你相关操作执行所产生的相对应的唯一版本号,找到你要回滚的版本,执行命令:git reset –head 该版本号,等执行完成查看会发现,又回到之前最新的那个版本!!
注意点:Git的版本回退速度非常快,因为Git在内部有个指向当前版本的HEAD指针,当你回退版本的时候,Git仅仅是把HEAD从指向当前版本改为指向上一个版本,然后顺便把工作区的文件更新了。所以你让HEAD指向哪个版本号,你就把当前版本定位在哪。
六、工作区与暂存区
工作区(Working Directory):就是你在电脑里能看到的目录(也就是你安装Git时初始化的目录),比如我的wheekygit文件夹就是一个工作区
版本库(Repository):工作区有一个隐藏目录“.git”,这个不算工作区,而是Git的版本库。Git的版本库里存了很多东西,其中最重要的就是称为stage(或者叫index)的暂存区,还有Git为我们自动创建的第一个分支master,以及指向master的一个指针叫HEAD。
七、撤销和修改
1、使用git checkout命令丢弃工作区的修改,比如我误修改的CCheckBox源文件,现需要撤消,代码如下:
|
1
|
语法:git checkout 文件名 -----> git checkout readme.txt
|
命令git checkout — file 意思就是,把file文件在工作区的修改全部撤销,这里有两种情况:
一种是file自修改后还没有被放到暂存区,现在,撤销修改就回到和版本库一模一样的状态;
一种是file已经添加到暂存区后,又作了修改,现在,撤销修改就回到添加到暂存区后的状态。
总之,就是让这个文件回到最近一次git commit或git add时的状态。
2、当已将文件添加到暂存区但未提交到版本库时,可使用git reset HEAD file命令把暂存区的修改撤销掉(unstage),重新放回工作区,然后再执行上面的命令:
|
1
2
|
$ git reset HEAD ZControls/CCheckBox.cs //放回工作区
$ git checkout -- ZControls/CCheckBox.cs //撤消修改
|
3、若已经提交了不合适的修改到版本库时,想要撤销本次提交,可使用git reset –hard Head^命令来退回到上一版本,不过前提是没有推送到远程库。
八、删除文件
1、确实要从版本库中删除该文件,那就用命令git rm删掉,并且执行git commit命令:
|
1
2
|
$ git rm test.txt
$ git commit -m "remove test.txt"
|
2.若误删除了文件,因为版本库里还有,所以可以使用git checkout命令把误删的文件恢复到最新版本:
|
1
|
$ git checkout -- test.txt
|
git checkout其实是用版本库里的版本替换工作区的版本,无论工作区是修改还是删除,都可以“一键还原”。
命令git rm用于删除一个文件。如果一个文件已经被提交到版本库,那么你永远不用担心误删,但是要小心,你只能恢复文件到最新版本,你会丢失最近一次提交后你修改的内容。
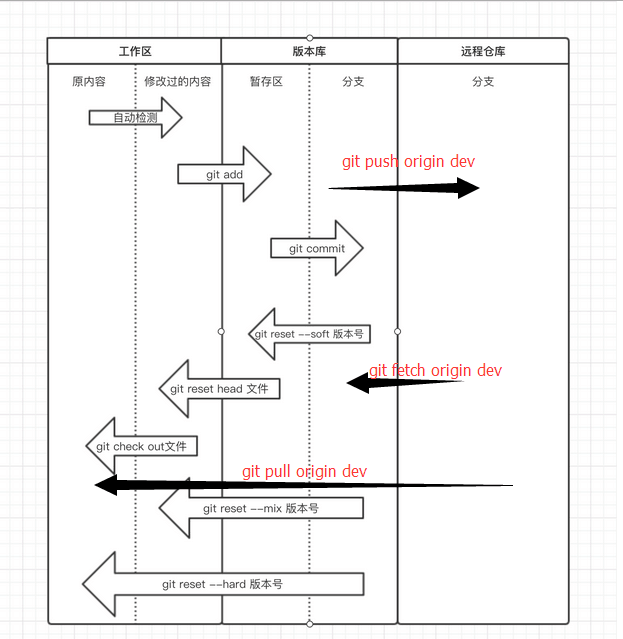
九、一张图坦白Git的所有操作!
【分支管理与合并及Bug分支】
一、分支管理
1、什么是分支
分支就相当于我们看科幻片里的平行宇宙,如果两个平行宇宙互不干扰,那铁定是啥事儿没有。不过,在某个时间点,两个平行宇宙合并了呢?假如两个宇宙中都有你的影子,
合并之后相当于你们两个合二为一,所有的技能都合并在一个人的身上!
分支在实际中有什么用呢?
假设你准备开发一个新功能,但是需要两周才能完成,第一周你写了50%的代码,如果立刻提交,由于代码还没写完,不完整的代码库会导致别人不能干活了。如果等代码全部写完再一次提交,又存在丢失每天进度的巨大风险。现在有了分支,就不用怕了。你创建了一个属于你自己的分支,别人看不到,还继续在原来的分支上正常工作,而你在自己的分支上干活,想提交就提交,直到开发完毕后,再一次性合并到原来的分支上,这样,既安全,又不影响别人工作。
2、分支的创建与合并
我们已经清楚的知道版本的每次提交,Git都把它们串成一条时间线,这条时间线就是一个分支。截止到目前,只有一条时间线,在Git里,这个分支叫主分支,即master分支。HEAD严格来说不是指向提交,而是指向master,master才是指向提交的,所以,HEAD指向的就是当前分支。一开始的时候,master分支是一条线,Git用master指向最新的提交,再用HEAD指向master,就能确定当前分支,以及当前分支的提交点(只要不回滚,一定是在最新的版本上),每次提交,master分支都会向前移动一步,这样,随着你不断提交,master分支的线也越来越长,如图所示!

创建
1)当我们创建新的分支,例如dev时,Git新建了一个指针叫dev,指向master相同的提交,再把HEAD指向dev,就表示当前在dev分支上;不过有一点需要特别注意:从现在开始,对工作区的修改和提交就是针对dev分支了,比如新提交一次后,dev分支的版本就会更新一次(git log 可以查看到更新日志),而master分支是不会改变的。
|
1
2
3
4
|
创建分支:
$ git branch dev #创建dev分支
$ git checkout dev #切换到dev分支
$ git checkout -b dev //git checkout命令加上-b参数表示创建并切换,相当于上边两条命令
|
注意:创建的时候,一定要注意所在分支的位置!分支的创建相当于是在当分支的最新版本为起始生成的一个旁支,这个分支上最基础的版本一定是这个起点(可以理解为克隆了一份放到了其他的旁支上)!同时你现在也应该甚至必须知道,分支之间的关系是平行的互不干扰!!!也就是说你在当前分支更新了一次版本只是这个分支的时间线往前走了一步,而另一个分支的版本是丝毫不变的!
2)用git branch命令查看当前分支,git branch命令会列出所有分支,当前分支前面会标一个*号。
|
1
2
3
|
$ git branch
* dev
master
|
PS:我们也可以通过git status 查看当前工作区所在的分支【代码中第二行】,会有相应的提示!!!再或者是在当前git的窗口下,$提示符上一行(当前仓库的绝对路径最后会有当前分支的标记,括号内)
3)用git checkout命令切换分支,如下代码,切换到master分支:
|
1
2
3
4
5
|
$ git checkout master
用 git branch命令查看当前分支
$ git branch
dev
* master
|
既然学会了创建分支和切换,我们可以尝试着在dev分支上做一次版本更新!在dev版本的工作区仓库下,我们可以创建一个readme2.txt文件,在这个文件中随意添加点儿内容,保存。然后我们通过命令提交到版本库。
|
1
2
3
|
$ git add .
$ git commit -m "branch test"
$ git status //看下工作区是否干净!
|
所有工作完成,我们切换到master分支 命令:$ git checkout master此时你会惊奇的发现,工作区内我刚刚新创建的readme2.txt文件不见了!心里甚是惶恐!怎么办?怎么
办?是不是我的git仓库瓦特了?!
别急,咱再切换到dev分支去看看,到底是怎么回事!命令:$ git checkout dev,切换过来之后,你发现工作区新建的readme2.txt文件有神奇的出现了!!!这时候你肯定会想这是为什么呢?咱们一开始提到过的平行分支的概念!git就是这么玩儿的!分支之间是互不干扰的!!!在dev分支上你爱怎么玩儿就怎么玩儿,对我主分支是没有丝毫影响。这就相当于是上线的业务分支和新开发的程序分支一样,业务线分支上的程序在正常运转,而你在开发这个分支上恶搞,能影响到业务线吗?
合并
当我们在dev上完成了我们的开发任务,我们就想着怎么把上线的业务更新到最新版本呢?这时候就需要把dev分支上的版本合并到master分支上。那Git怎么合并呢?这时候你是否还记得,上面咱们说的主分支master分支,这时候我们就需要回到主分支上,然后使用命令对dev分支进行合并!这样就相当于是完成了合并操作,把dev的版本更新到master版本上!
|
1
2
3
4
5
6
7
|
$ git checkout master //切换到master分支
$ git branch //查看当前所在分支
$ git merge dev //git merge 分支名 命令用于合并指定分支到当前分支。
查看分支合并情况:
$ git log --graph
$ git log --graph --pretty=oneline --abbrev-commit //详细
|
通常,合并分支时,如果可能,Git会用Fast forward模式,但这种模式下,删除分支后,会丢掉分支信息。如果要强制禁用Fast forward模式,Git就会在merge时生成一个新的commit,这样,从分支历史上就可以看出分支信息。我们实战一下–no-ff 方式的git merge:
创建分支及切换更新版本操作此处省略;
当切换到master分支下,准备合并dev分支的时候,请注意–no-ff参数,表示禁用Fast forward:命令如下:$ git merge –no-ff -m “merge with no-ff” dev 因为本次合并要创建一个新的commit,所以加上-m参数,把commit描述写进去。
合并后,我们用git log看看分支历史:此处要敲代码了(哥)!我们会发现不使用Fast forward模式,merge合并后给出的合并方式(因为多了一步 commit)。
合并分支的风风雨雨 —–> 冲突问题:
时刻记住一句话,合并分支往往不是一帆风顺的。无冲突那肯定是万事大吉,什么事都不用做!高兴的喝茶就好!如果合并问题的过程中出现冲突,那我们就需要手动解决冲突后再提交!我们可以通过 git status 查看发生冲突的文件。然后进入文件,我们会发现,git用<<<<<<<,=======,>>>>>>>标记出不同分支的内容,我们根据 git 给出的标记,将两段内容中重复的部分手动去掉,然后把两段内容整合!最后去除标记符号,保存!然后手动提交到仓库(分支)。
举例如下:
第一种,无冲突发生的情况:如果你在master分支上创建一个新的分支(dev),然后在该仓库下添加了某个文件(如test.txt)并更新到分支,当合并时由于master分支的库中没有这个文件(test.txt),那么合并时就不会出现冲突问题!
第二种,有冲突发生的情况:如果你在master分支上创建一个新的分支(dev),正在为某个文件(如:plugins.py)添加新功能,这时有人跟你说这个文件(plugins.py)中有bug,你又在master分支基础上重新建立了一个bug分支,用于修改这个bug当改好测试正常之后,合并到主分支master上,然后你切换到dev分支下plugins.py文件继续完善你的功能,当你测试正常合并的时候,git报错说你plugins.py文件的出现冲突了!为什么呢?
就因为你在plugins.py文件改了一次bug,更新了主线master分支版本,你开发分支dev操作的时候也是修改的这个文件,当合并时,git发现同一个文件下,开发分支dev与主分支master之间的版本差一代,他对不上了,所以就引发出现冲突这个问题!
出现这个问题不用慌张,这不是你的代码除了问题,而是你的版本出现差异了!只需要找到对应的文件,按照文件内部git给出的表记把内容整合在一起,然后再手动提交一次,就万事大吉!
删除
合并完分支后,甚至可以删除dev分支。当然删除操作要慎重删掉临时创建而不常用的分支(当然,我们需要的话还是可以在创建的!),这样我们就剩下了主分支master.
|
1
2
3
|
git branch -d dev //只删除完成合并之后的dev分支
git branch -D dev //强制删除dev分支,
场景:dev分支上开发新更新的某个版本,还未合并到主分支,而项目发展出现变动你开发的东西不再需要,通过-d的方法删除这个分支git会报错的,此时就需要强制删除!
|
二、关于Bug我们不得不说的那点事儿
bug一直伴随在程序员的身边,如胶似漆比媳妇儿都黏人。哪怕是你考虑的再周全,你也不可能是上帝把所有要出现的问题全部解决!更何况你还不是上帝呢!所以说,在业务上线之后,你正在为这个业务编写新功能时,出现bug了怎么办呢?宝宝不慌,Git给了我们两种解决方案!
方案一:(stash,工作正在进行,新内容还没提交)
当你正在进行的工作还没法提交【不是效率问题,而是时间预估】,而bug必须在2小时内解决,总不能把现在写好的东西先保存到别的地儿然后再恢复到原来的版本吧,这样一个小时都过去了,你还怎么如期完成修复bug的问题?幸好,Git还提供了一个stash功能,可以把当前工作现场临时“储藏”起来,等以后恢复现场后再继续工作:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
临时隐藏工作区:(常见的场景是,当我们需要临时处理其它事情【如:解决BUG】时而不得不暂时中断目前的主要开发任务)
//dev分支下
$ git stash //隐藏目前工作区
$ git status //查看工作区,就是干净的(除非有没有被Git管理的文件)因此可以放心地创建分支来修复bug。
//切换到master分支,创建分支
$ git checkout master //切换到需要建立临时分支的分支,比如:master
$ git checkout -b issue-101 //建立并切换到临时分支,issue-101 用于修复bug
//修复完bug,提交
$ git add file //添加到暂存区
$ git commit -m "fix bug 101" //提交到临时分支仓库
//切换到master分支,合并
$ git checkout master //回到master分支
$ git merge --no-ff -m "merged bug fix 101" issue-101 //合并临时分支,这里禁用fast foward模式,保留提交记录以便日后可查或恢复
//删除分支
$ git branch -d issue-101 //删除临时分支
//到此bug修复完成,切换到dev分支!
查看被隐藏的工作区信息:
$ git stash list
恢复工作区:
$ git stash pop //相当于以下两条命令
$ git stash apply //恢复工作区
$ git stash drop //清除隐藏区
|
在dev分支下,我们执行 git status 命令看到工作区是干净的,原先我们隐藏的文件去哪里了?我们可以使用 git stash list 查看!发现工作现场还在,Git把stash内容存在某个地方了,但是需要恢复一下,有两个办法:
一是用git stash apply恢复,但是恢复后,stash内容并不删除,你需要用git stash drop来删除;
另一种方式是用git stash pop,恢复的同时把stash内容也删了:
恢复之后,再使用 git stash list 查看就应该看不到任何文件了!此处要注意一点:可以多次把工作区临时隐藏存放,恢复的时候,就需要使用命令:git stash list 查看,然后利用命令:git stash apply stash名 指定恢复文件!
方案二:(推荐,当然是你当前dev分支已经提交保存了)
利用分支,在业务线的基础上创建一个bug分支,解决完bug问题之后合并分支,没冲突就过,有冲突就解决冲突再提交!问题解决!
三、分支策略
在实际开发中,我们应该按照几个基本原则进行分支管理:
首先,master分支应该是非常稳定的,也就是仅用来发布新版本,平时不能在上面干活;
那在哪干活呢?干活都在dev分支上,也就是说,dev分支是不稳定的,到某个时候,比如1.0版本发布时,再把dev分支合并到master上,在master分支发布1.0版本;你和你的小伙伴们每个人都在dev分支上干活,每个人都有自己的分支,时不时地往dev分支上合并就可以了。
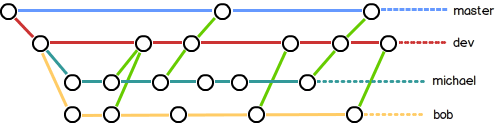
所以,团队合作的分支看起来就像这样(盗用廖神的图片):
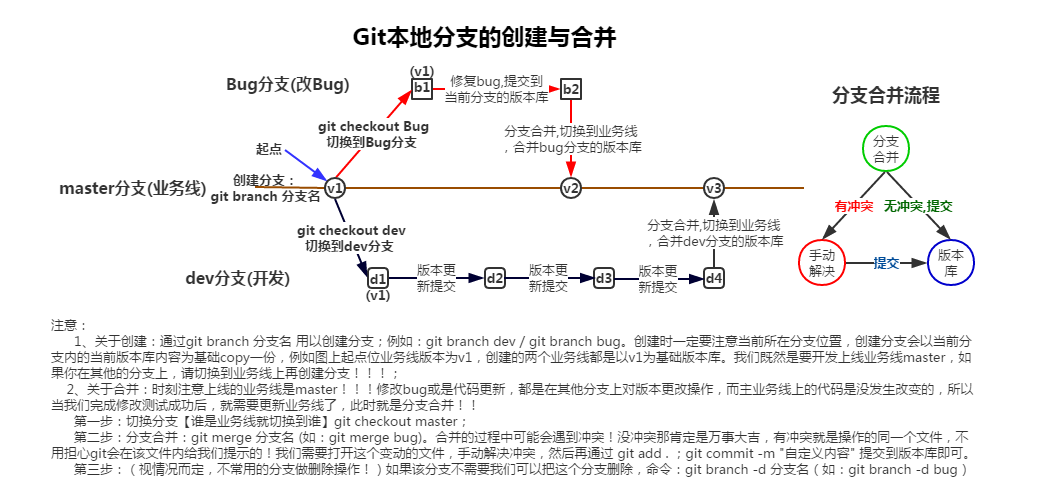
四、本地分支的创建与合并
【远程库(GitHub)协同开发,fork和忽略特殊文件】
远程库
远程库,通俗的讲就是不再本地的git仓库!他的工作方式和我们本地的一样,但是要使用他就需要先建立连接!
远程库有两种,一个是自己搭建的git服务器;另一种就是使用GitHub,这个网站就是提供Git仓库托管服务的,所以,只要注册一个GitHub账号,就可以免费获得Git远程仓库。友情提示:在GitHub上免费托管的Git仓库,任何人都可以看到喔(但只有你自己才能改)。所以,不要把敏感信息放进去。
远程仓库的好处:
1、我们可以随时随地的与仓库建立连接,以实时存放我们开发的内容;
2、与他人实现协同开发,而不是再需要来回的发送修改过的代码由他人整合在一起,git自动的帮我们完成了更新,这是最重要的也是无可比拟的!
3、只要你不把提交到本地仓库中的代码提交到远程库,那么别人一辈子也休想看到你的代码!
一、创建远程仓库(GitHub)
1、GitHub网站地址:https://github.com/,这个网站就是提供Git仓库托管服务的,所以,只要注册一个GitHub账号,就可以免费获得Git远程仓库。
2、由于本地Git仓库和GitHub仓库之间的传输是通过SSH加密的,所以,需要如下设置:
第1步:创建SSH Key。在用户主目录下(例如:C:\Users\Administrator\),看看有没有.ssh目录,如果有,再看看这个目录下有没有id_rsa和id_rsa.pub这两个文件,如果已经有了,可直接跳到下一步。如果没有,打开Shell(Windows下打开Git Bash),创建SSH Key:
|
1
|
ssh-keygen.exe //创建SSH key 【公钥和私钥,连接省却了用户名密码的输入】git窗口下,直接执行ssh-keygen.exe,默认往下执行,然后把公钥复制到github上
|
如果一切顺利的话,可以在用户主目录里找到.ssh目录,里面有id_rsa和id_rsa.pub两个文件,这两个就是SSH Key的秘钥对,id_rsa是私钥,不能泄露出去,id_rsa.pub是公钥,可以放心地告诉任何人。
第2步:登陆GitHub,打开“Account settings”,“SSH Keys”页面,然后,点“Add SSH Key”,填上任意Title,在Key文本框里粘贴id_rsa.pub文件的内容,最后点击“Add Key”按钮完成。
说明:为什么GitHub需要SSH Key呢?因为GitHub需要识别出你推送的提交确实是你推送的,而不是别人冒充的,而Git支持SSH协议,所以,GitHub只要知道了你的公钥,就可以确认只有你自己才能推送。当然,GitHub允许你添加多个Key。
假定你有若干电脑,你一会儿在公司提交,一会儿在家里提交,只要把每台电脑的Key都添加到GitHub,就可以在每台电脑上往GitHub推送了。
二、添加远程库:
1、登录GitHub网站,并按网站要求创建一个新的仓库;
2、根据GitHub网站提示,可以从这个仓库克隆出新的仓库,也可以把一个已有的本地仓库与之关联,然后,把本地仓库的内容推送到GitHub仓库。
3、本地仓库与GitHub上相应的仓库建立关联,代码如下:(git@github.com:zh605929205/LearnGit.git为我新建的仓库路径)
|
1
|
$ git remote add origin git@github.com:zh605929205/LearnGit.git
|
添加后,远程库的名字就是origin,这是Git默认的叫法,也可以改成别的,但是origin这个名字一看就知道是远程库。
4、把本地库的内容推送到远程库上,用git push命令,实际是把当前分支master推送到远程。
|
1
|
$ git push -u origin master
|
由于远程库是空的,我们第一次推送master分支时,加上了-u参数,Git不但会把本地的master分支内容推送的远程新的master分支,还会把本地的master分支和远程的master分支关联起来,在以后的推送或者拉取时就可以简化命令(不用带-u参数)。当然也可以不写!就需要你手动输入yes
当你第一次使用Git的clone或者push命令连接GitHub时,会得到一个警告,这是因为Git使用SSH连接,而SSH连接在第一次验证GitHub服务器的Key时,需要你确认GitHub的Key的指纹信息是否真的来自GitHub的服务器,输入yes回车即可。
5、通过GitHub上的仓库来克隆出新的本地仓库(可以在任意一个文件夹下,建议最好在一个固定的盘下方便于管理),要克隆一个仓库,首先必须知道仓库的地址,然后使用 git clone命令克隆从远程库克隆到本地(说白了就是下载版本库)。代码如下:
|
1
|
$ git clone git@github.com:zh605929205/LearnGit.git //应用场景:切换办公地点:家和公司,第一次都能从远程库上克隆然后进行开发!
|
注意点:执行clone命令,实质上内部已经完成了初始化git库和本地与远程库连接的过程(内部config文件,已写好命名,同时远程库名字默认为origin)!
也许还注意到,GitHub给出的地址不止一个,还可以用 https://github.com/zh605929205/LearnGit.git 这样的地址。实际上,Git支持多种协议,默认的git://使用ssh,但也可以使用https等其他协议。使用https除了速度慢以外,还有个最大的麻烦是每次推送都必须输入口令,但是在某些只开放http端口的公司内部就无法使用ssh协议而只能用https。Git支持多种协议,包括https,但通过ssh支持的原生git协议速度最快。
三、本地与远程库协同开发
1、查看远程库:
|
1
2
|
$ git remote
$ git remote -v //加上-v参数可以查看详细信息 ----> 显示了可以抓取和推送的origin的地址。如果没有推送权限,就看不到push的地址。
|
2、当本地更新完毕,提交到本地的版本库,要推送分支到远程库分支。推送分支,就是把该分支上的所有本地提交推送到远程库。推送时,要指定本地分支,这样,Git就会把该分支推送到远程库对应的远程分支上:
|
1
2
|
语法:$ git push origin 分支名
$ git push origin master // $ git push origin dev
|
但是,并不是一定要把本地分支往远程推送,那么,哪些分支需要推送,哪些不需要呢?
master分支是主分支,因此要时刻与远程同步;
dev分支是开发分支,团队所有成员都需要在上面工作,所以也需要与远程同步;
bug分支只用于在本地修复bug,就没必要推到远程了,除非老板要看看你每周到底修复了几个bug;
总之,就是在Git中,分支完全可以在本地自己藏着玩,是否推送,视你的心情而定!
3、若是有多个分支,创建远程origin的dev分支到本地,需要创建本地分支并关联远程分支:
|
1
2
|
语法:$ git checkout -b 分支名 origin/分支名 //origin/dev为远程分支路径
$ git checkout -b dev origin/dev<br>$ git branch --set-upstream 分支名 origin/分支名 //若本地已有分支,可通过该命令来关联远程分支
|
4、从远程库中拉下分支新版本,用以更新本地库:
|
1
|
$ git pull origin 分支名
|
5、远程库推送解决冲突:
多人协同开发,向远程推送提交时产生冲突【实质就是提交快慢的问题】,则需先用git pull把最新的提交从origin/dev抓下来,然后,在本地合并,解决冲突,再推送,如下:
|
1
2
3
|
$ git pull //从远程获取分支
$ git commit -m "marge files" //本地更新合并
$ git push origin dev //推送提交到远程分支
|
注意:如果你在公司开发某段代码而忘记推送到远程库,别人又开发了别的功能并推送到远程库(此时远程库的版本已经与你本地库版本不一致),遇到这种情况,一定要记住先把远程库中对应的分支拉下来,然后再本地提交到版本库后,再重新推送到远程库!而且每次遇到解决冲突或是版本不一致的情况,一定要先看看是谁上一次做的操作,推送前一定要与其沟通!以免推送出错!
因此,多人协作的工作模式通常是这样:
首先,可以试图用git push origin branch-name推送自己的修改;
如果推送失败,则因为远程分支比你的本地更新,需要先用git pull试图合并;
如果合并有冲突,则解决冲突,并在本地提交;
没有冲突或者解决掉冲突后,再用 git push origin branch-name 推送就能成功!
如果git pull 提示“no tracking information”,则说明本地分支和远程分支的链接关系没有创建,用命令git branch –set-upstream branch-name origin/branch-name 关联远程分支。
6、远程库的操作都是先克隆或是把程序拉到本地,然后在本地对代码进行修改,然后更新到本地版本库,再推送到远程库!这里边儿肯定是会涉及到分支的问题,在上一文中已经详细的说明了分支的操作!具体按照流程来即可!
Git本地库与远程库连接的补充说明
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
关于本地仓库与远程库建立第一次建立连接的问题!
1、本地库提交到远程库!(本地库有数据而远程库没有数据)
第一步,先在远程库创建一个仓库(默认是master分支),用于上传你本地仓库内的所有文件!
第二步,在你本地仓库执行以下命令,以和远程库建立连接(先获取你远程库的ssh or https的远程库路径)
git remote add origin 【远程库的ssh or https协议路径】//此处远程库名可以自定义任意取名!
第三步,把本地库的代码提交到远程库!
此处场景:你在本地有两个分支,业务线master分支和开发dev分支
1)先提交master分支
git branch //查看是否在master不是切换到master分支
git checkout master
git push origin master //推送
2)再提交dev分支
git checkout dev
git branch //查看当前分支
git push origin dev //推送
第四步,推送成功之后,在远程库查看两条分支是否都在,都在的话证明提交成功!
2、远程库所有分支下载到本地(远程库有数据而本地库没有)
第一步,登录你的远程库,找到要下载的库名,点击进去找到 Clone or download 绿色的按钮,点击获取当前远程库的ssh or https协议的地址,获取这个地址;
第二步,在你的本地及你的电脑上找一地儿,创建一个自认为名字很帅的文件夹,点进去右击点 git bash here 等待一个git的窗口模式出现;
第三步:克隆你的远程库到本地,在窗口执行以下命令:
git clone【ssh or https 的地址】 //注:克隆下来的第一个分支,铁定是master分支!
等待完成,本地工作区会出现和远程库相同的master的所有文件
git branch //查看本地分支,会发现只有 master分支
git branch -a //可以查看远程库有几个分支,及当前指针所在分支!
第三步,下载其他分支例如开发分支,执行以下命令:
git checkout -b dev origin/dev //创建并切换到dev分支同时与远程分支关联,获取远程分支内的所有数据
第四步,等待完成,查看dev分支内工作区与远程库dev分支内容是否一致!
当本地库与远程库建立连接,分支都已同步之后,剩下的推送版本或是下载版本就都是很简单了!
1、在本地修改文件,提交到本地版本库,再从本地版本库上传到远程库就是用命令
git push origin dev //(注意你推送的分支)
2、从远程库分支获取文件更新你的本地版本
git pull origin dev //(注意你拉取的分支)
|
协同开发
1个远程库,多个人员使用,同时对某个业务线进行开发!
既然要实现协同开发,那么一个人铁定是不行的。就需要创建组织,然后再对这个组件进行管理添加成员,点进去这个库,在people栏下点击邀请开发人员!发送邀请的同时可以对这个开发人员进行权限分配,以限制其都能有什么权限!
注意:非组织成员是不允许对这个仓库进行操作的!
协同开发的时候,共同使用一个项目,当需要对这个远程库提交的时候,一定是先进行拉取操作,然后再提交!否则就会因为版本库内代码不一致的问题导致报错或是紊乱!
两人未沟通的情况下同时提交代码到远程库,肯定是得取决于谁提交的快谁会提交到远程库!提交慢的人会被拒绝,就是因为慢的原因!所以如果遇到这种被拒绝的情况,不用惊慌,你先把远程库的代码拉取下来,然后你再提交一次就OK了!【注意:解决冲突的时候,一定要先与上一个提交的人先沟通!】
奉上一张相关错误截图,借用的老师的图片,当遇到这个问题时,一定是版本冲突的问题!把远程库的代码拉下来,重新提交就OK!

四、参与开源项目 fork
1、首先你自己必需要有GitHub账号并已登录成功。
2、找到指定的开源项目GitHub地址,例如:
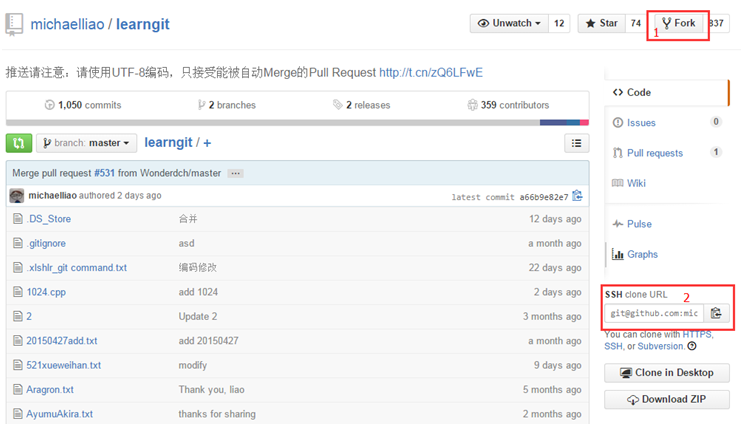
3、点击图上的Fork按钮,会在自己账号下克隆一个相同的仓库,例如:
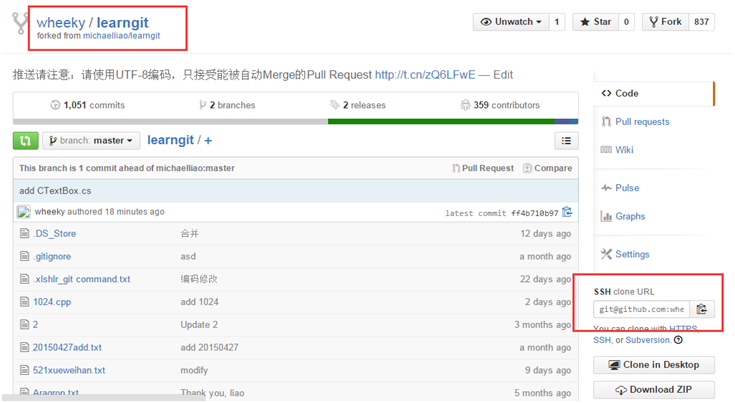
4、使用git clone命令克隆到本地仓库,如:
|
1
|
$ git clone git@github.com:wheeky/learngit.git
|
5、在本地进行相应的操作,比如新增了一个文件(CTextBox.cs):
|
1
2
|
$ git add CTextBox.cs
$ git commit -m 'add CTextBox.cs'
|
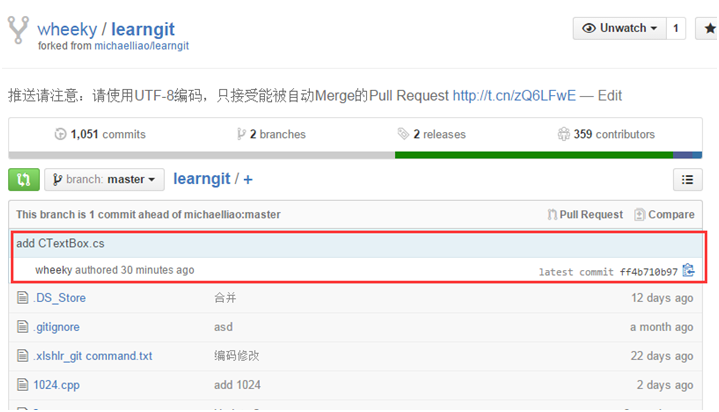
6、使用git push命令推送更新到远程仓库:
|
1
|
$ git push origin master
|
此时远程仓库就可以看到相应的更新(红色框内显示最后提交的信息),如图:
7、创建pull request请求,向开源项目的作者发送更新请求,如下列图示:
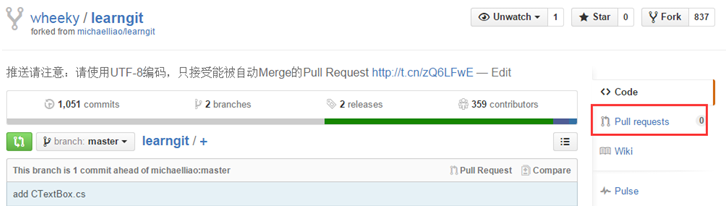
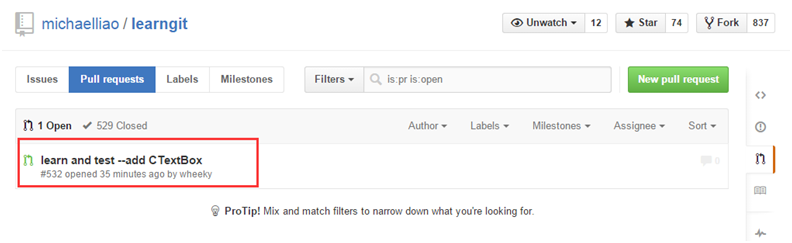
点击“New pull request”按钮,并在随后的页面里填写相应的标题、备注说明等信息提交即可,剩下的就是等原作者的处理。若提交成功可在作者的开源项目的Pull requests中可以看到自己请求记录,如下:
五、忽略特殊文件
在Git工作区的根目录下创建一个特殊的.gitignore文件,然后把要忽略的文件名填进去(按照规则填写),Git就会自动忽略这些类型的文件。不需要从头写.gitignore文件,GitHub已经为我们准备了所有语言的各种配置文件,只需要找到python的文件,组合一下就可以使用了。所有配置文件可以直接在线浏览https://github.com/github/gitignore
注意:.gitignore文件本身要放到版本库里,并且可以对.gitignore做版本管理!
【标签和搭建Git服务】
一、标签是什么
发布一个版本时,我们通常先在版本库中打一个标签,这样,就唯一确定了打标签时刻的版本。将来无论什么时候,取某个标签的版本,就是把那个打标签的时刻的历史版本取出来。所以,标签也是版本库的一个快照。
Git的标签虽然是版本库的快照,但其实它就是指向某个commit的指针(跟分支很像对不对?但是分支可以移动,标签不能移动),所以,创建和删除标签都是瞬间完成的。
二、创建标签
Git 使用的标签有两种类型:轻量级的(lightweight)和含附注的(annotated)。轻量级标签就像是个不会变化的分支,实际上它就是个指向特定提交对象的引用。而含附注标签,实际上是存储在仓库中的一个独立对象,它有自身的校验和信息,包含着标签的名字,电子邮件地址和日期,以及标签说明,标签本身也允许使用 GNU Privacy Guard (GPG) 来签署或验证。一般我们都建议使用含附注型的标签,以便保留相关信息;当然,如果只是临时性加注标签,或者不需要旁注额外信息,用轻量级标签也没问题。
1.创建轻量级的标签
|
1
2
3
|
$ git tag v1.0 //v1.0即为标签名,也可理解为定义的版本名,默认标签是打在最新提交的commit上的
$ git tag v0.9 commitId //指定为某个提交ID创建标签
|
2.创建含附注的标签
|
1
|
$ git tag -a v1.4 -m 'my version 1.4'
|
3.创建签署标签
|
1
|
$ git tag -s v1.0 -m 'my signed version 1.0'
|
注意:签名采用PGP签名,因此,必须首先安装GPG,如果没有找到gpg,或者没有gpg密钥对,就会报错
三、查看标签
1.查看所有标签
|
1
|
$ git tag
|
显示的标签按字母顺序排列,所以标签的先后并不表示重要程度的轻重。
2.用特定的搜索模式列出符合条件的标签(如下列出标签名前面为v1.的所有标签)
|
1
|
$ git tag -l 'v1.*'
|
3.使用 git show 命令查看标签的信息
|
1
|
$ git show v1.0
|
四、操作标签
|
1
2
3
4
5
6
7
|
$ git push origin <tagname> //可以推送一个本地标签
$ git push origin --tags //可以推送全部未推送过的本地标签
$ git tag -d <tagname> //可以删除一个本地标签
$ git push origin :refs/tags/<tagname> //可以删除一个远程标签
|
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/156009.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
