大家好,又见面了,我是你们的朋友全栈君。
https://www.cnblogs.com/zhanht/p/5450559.html
本文主要介绍MySQL 中关于索引的一些问题,例如:索引的作用;怎么创建索引;设计索引的原则;怎么优化索引等等。
一:索引概述
索引一般是通过排序,然后查找时可以二分查找,这一特点来达到加速查找的目的的。
所有的MySQL列类型都能创建索引,良好设计的所以能够很好地提高查询的性能,但如果索引过多,由于每次更新操作都会对索引进行更新,反而会影响到数据库的整体性能。因而,遵循一定的原则,设计合适的索引是非常重要的。
(1):创建索引的语法
CREATE [UNIQUE|FULLTEXT|SPQTIAL] INDEX index_name [USING index_type] ON table_name(col_name)
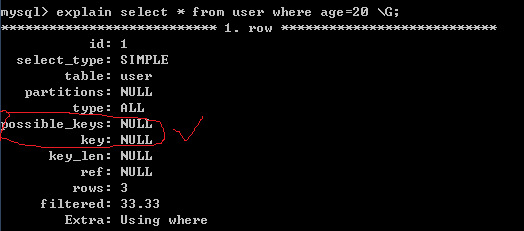
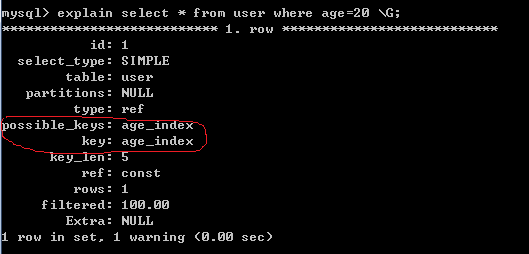
例子:建了一张user表,有属性 name, age, address, 下面图可以看出没建立索引和建立索引时查询的区别。


二:设计索引的几个原则
(1): where子句中的列比select中的列更适合做索引。
(2): 选择那些基数大的列,这要的索引效果更好,这要索引才能很好地区分不同值。
(3): 使用短索引,例如一个char(200)的列,如果前20个字符就能很好的区分不同的值时,就没必要对整个列进行索引,这样可以大大的减少索引的存储空间。
(4): 不要过度索引,只建立所需的索引。过多的索引会浪费磁盘空间,降低写的性能,也会给查询优化带来更多的工作,让MySQL选择不到最好的索引。
(5): InnoDB尽量自己指定主键:InnoDB 引擎存储的表会按照一定的顺序保存,例如主键,唯一索引,如果都没有则会自动生成一个内部列,按照这些进行访问是最快的,所以InnoDB尽量自己指定主键。当有多个列可以作为主键时,选择最常作为访问条件的列作为主键。
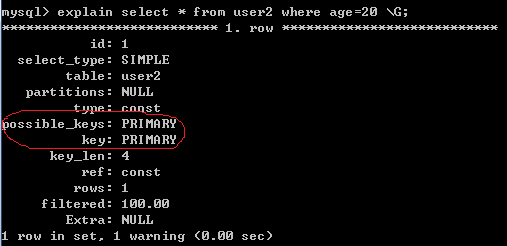
例子:InnoDB没创建索引,但建立了主键,会用主键进行查询。

三:BTREE索引和HASH索引
MyISAM 和 InnoDB 默认创建的是BTREE索引,MEMORY引擎默认创建的是Hash索引,BTREE 用于全值匹配,匹配列前缀,范围匹配时非常有效。HASH索引存储的是hash值,并且是所有索引列的Hash值,只能用于精确匹配。
BTREE 的几个限制:
(1). 必须按照索引的最左列开始查找
(2). 不能跳过索引中的列
(3). 某个列使用了范围查询,其右边的列都无法使用索引。
索引列的位置顺序,非常重要,写SQL时需要尤其注意。
HASH索引的几个限制:
(1). hash索引只存储哈希值和行指针,不存储字段值,结构紧凑。
(2). 数据不是按照索引值顺序存储的,所以无法用于排序。
(3). 不支持部分索引列的匹配查找,因为hash值是用所有的索引列计算的。
(4). 只支持精确查找
四:索引的优化
在遵循索引的设计原则后,设计索引和编写SQL时还需要注意索引使用时的几个特点:
(1). 前缀特性 : 当创建了多列索引时,只要用到了前面的列,索引就会起作用。例如创建了两列索引(a,b) ,当where条件语句中仅出现了a,索引也会被使用,但仅仅出现了b,索引将不会被使用。
(2). 使用like查询时,%不能出现在第一个字符,应该是 “ 常量 + %”,这样索引才可能会起作用。
(3). 对大文本进行搜索时,使用全文索引而不是使用 like ‘%…%, 更好的方法是在BTREE的基础上建立伪Hash索引,仅仅需要对这列计算hash值再存储,可以节省空间。缺陷是需要维护hash值,可以用触发器维护。
(4). 用or分割开的条件,如果or前面的列有索引,后面的列没有索引,那么涉及到索引都不会被用到。
(5). 如果列类型是字符串,记得where条件中把字符串常量值用引号引起来。
查看索引的使用情况,用 show status like ‘Handle_read%’ 查看Handle_read_key(值大说明索引得到了很好的使用,反之亦然) 和 Handle_read_rnd_next(值很大说明进行了大量的全盘扫描,索引没得到很好地使用) 的值。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/154904.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...