CAP (Consistency、Availability、Partition Tolerance)
当初CAP只是布鲁尔的一个猜想,并没有详细定义这三个词的定义,去查询 CAP 定义的时候会感到比较困惑,因为不同的资料对 CAP 的详细定义有一些细微的差别。如:
Consistency: where all nodes see the same data at the same time.
Availability: which guarantees that every request receives a response about whether it succeeded or failed.
Partition tolerance: where the system continues to operate even if any one part of the system is lost or fails.
Consistency: Every read receives the most recent write or an error.
Availability: Every request receives a (non-error) response – without guarantee that it contains the most recent write.
Partition tolerance: The system continues to operate despite an arbitrary number of messages being dropped (or delayed) by the network between nodes.
Consistency: all nodes have access to the same data simultaneously.
Availability: a promise that every request receives a response, at minimum whether the request succeeded or failed.
Partition tolerance: the system will continue to work even if some arbitrary node goes offline or can’t communicate.
②中定义了什么才是 CAP 理论探讨的分布式系统,强调了两点:interconnected 和 share data,为何要强调这两点呢?因为分布式系统并不一定会互联和共享数据。最简单的例如
Memcache 的集群,相互之间就没有连接和共享数据,因此 Memcache 集群这类分布式系统就不符合 CAP 理论探讨的对象; 负载均衡的集群节点也不互联。
而 MySQL 集群就是互联和进行数据复制的,因此是 CAP 理论探讨的对象。
②中强调了 write/read pair,这点其实是和上一个差异点一脉相承的。也就是说, CAP 关注的是对数据的读写操作,而不是分布式系统的所有功能。例如, ZooKeeper 的选举机制就不是 CAP 探讨的对象。
②中的定义和解释更加严谨,但内容相比第一版来说更加难记一些,所以现在大部分技术人员谈论 CAP 理论时,更多还是按照第一版的定义和解释来说的,因为第一版虽然不严谨,
但非常简单和容易记住。②除了基本概念,三个基本的设计约束也进行了重新阐述,如下:
三个基本约束
1. 一致性(Consistency)
① All nodes see the same data at the same time;所有节点在同一时刻都能看到相同的数据。
② A read is guaranteed to return the most recent write for a given client;对某个指定的客户端来说,读操作保证能够返回最新的写操作结果。
①的关键词是 see,其实并不确切,因为节点 node 是拥有数据,而不是看到数据,即使要描述也是用 have;强调同一时刻拥有相同数据(same time + same data)
②的关键词是 read。从客户端 client 的读写角度来描述一致性,定义更加精确。
这就意味着实际上对于节点来说,可能同一时刻拥有不同数据(same time + different data),这和我们通常理解的一致性是有差异的,为何做这样的改动呢?其实在第一版的详细解释中已经提到了,具体内容如下:
A system has consistency if a transaction starts with the system in a consistent state, and ends with the system in a consistent state. In this model, a system can (and does) shift into an inconsistent state during a transaction, but the entire transaction gets rolled back if there is an error during any stage in the process.
参考上述的解释,对于系统执行事务来说,在事务执行过程中,系统其实处于一个不一致的状态,不同的节点的数据并不完全一致,因此第一版的解释“All nodes see the same data at the same time”是不严谨的。 而第二版强调 client 读操作能够获取最新的写结果就没有问题,因为事务在执行过程中,client 是无法读取到未提交的数据的,只有等到事务提交后,client 才能读取到事务写入的数据,而如果事务失败则会进行回滚, client 也不会读取到事务中间写入的数据。
2. 可用性(Availability)
① Every request gets a response on success/failure. 每个请求都能得到成功或者失败的响应。
② A non-failing node will return a reasonable response within a reasonable amount of time (no error or timeout). 非故障的节点在合理的时间内返回合理的响应(不是错误和超时的响应)。
二者的差异点在于:
① 是 every request,它是不严谨的,因为只有非故障节点才能满足可用性要求,如果节点本身就故障了,发给节点的请求不一定能得到一个响应。response 分为 success 和 failure,定义太泛了,几乎任何情况,无论是否符合 CAP 理论,我们都可以说请求成功和失败,因为超时也算失败、错误也算失败、异常也算失败、结果不正确也算失败;即使是成功的响应,也不一定是正确的。例如,本来应该返回 100,但实际上返回了 90,这就是成功的响应,但并没有得到正确的结果。
②强调了 A non-failing node。②用了两个 reasonable:reasonable response 和 reasonable time,而且特别强调了 no error or timeout。
① System continues to work despite message loss or partial failure. 出现消息丢失或者分区错误时系统能够继续运行。
② The system will continue to function when network partitions occur. 当出现网络分区后,系统能够继续“履行职责”。
它们的主要差异点表现在:
①用的是 work,work 强调“运行”,只要系统不宕机,都可以说系统在 work,返回错误也是 work,拒绝服务也是 work;分区用的是 message loss or partial failure,直接说原因,即 message loss 造成了分区,但 message loss 的定义有点狭隘,因为通常我们说的 message loss(丢包),只是网络故障中的一种。
虽然 CAP 理论定义是三个要素中只能取两个,但放到分布式环境下来思考,我们会发现必须选择 P(分区容忍)要素,因为网络本身无法做到 100% 可靠,有可能出故障,所以分区是一个必然的现象。如果我们选择了 CA 而放弃了 P,那么当发生分区现象时,为了保证 C,系统需要禁止写入,当有写入请求时,系统返回 error(例如,当前系统不允许写入),这又和 A 冲突了,因为 A 要求返回 no error 和 no timeout。因此, 分布式系统理论上不可能选择 CA 架构,只能选择 CP 或者 AP 架构。
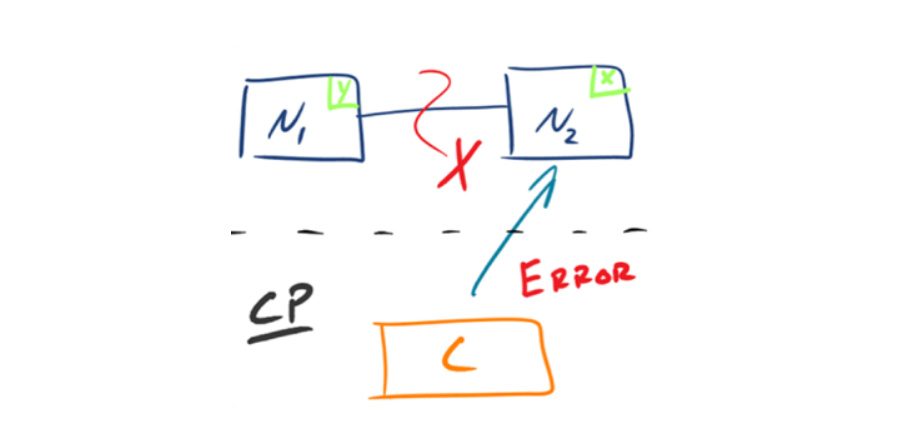
1.CP – Consistency/Partition Tolerance
如下图所示,为了保证一致性,当发生分区现象后,N1 节点上的数据已经更新到 y,但由于 N1 和 N2 之间的复制通道中断,数据 y 无法同步到 N2,N2 节点上的数据还是 x。这时客户端 C 访问 N2 时,N2 需
要返回 Error,提示客户端 C“系统现在发生了错误”,这种处理方式违背了可用性(Availability)的要求,因此 CAP 三者只能满足 CP。
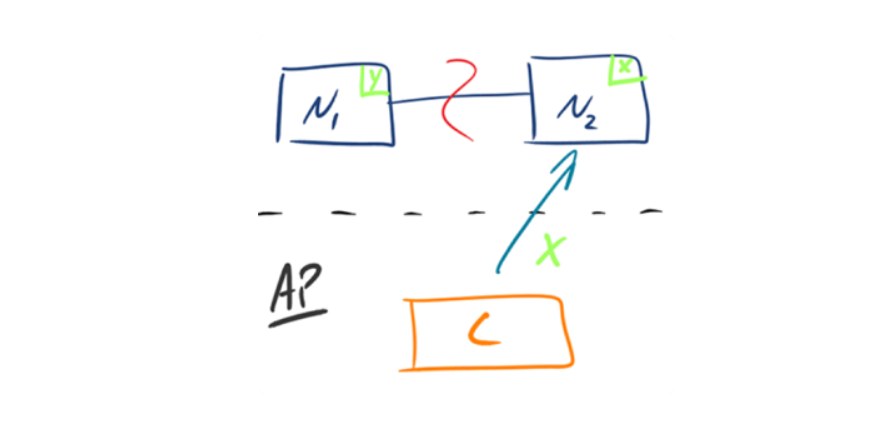
2.AP – Availability/Partition Tolerance
如下图所示,为了保证可用性,当发生分区现象后,N1 节点上的数据已经更新到 y,但由于 N1 和 N2 之间的复制通道中断,数据 y 无法同步到 N2,N2 节点上的数据还是 x。这时客户端 C 访问 N2 时,N2 将当前自己拥有的数据 x 返回给客户端 C 了,而实际上当前最新的数据已经是 y 了,这就不满足一致性(Consistency)的要求了,因此 CAP 三者只能满足 AP。注意:这里 N2 节点返回 x,虽然不是一个“正确”的结果,但是一个“合理”的结果,因为 x 是旧的数据,并不是一个错乱的值,只是不是最新的数据而已。
CAP 理论落地实践时,我们需要将系统内的数据按照不同的应用场景和要求进行分类,每类数据选择不同的策略(CP 还是 AP),而不是直接限定整个系统所有数据都是同一策略。
CAP 是忽略网络延迟的
这是一个非常隐含的假设,布鲁尔在定义一致性时,并没有将延迟考虑进去。也就是说,当事务提交时,数据能够瞬间复制到所有节点。但实际情况下,从节点 A 复制数据到节点 B,总是需要花费一定时间的。如果是相同机房,耗费时间可能是几毫秒;如果是跨地域的机房,例如北京机房同步到广州机房,耗费的时间就可能是几十毫秒。这就意味着,CAP 理论中的 C 在实践中是不可能完美实现的,在数据复制的过程中,节点 A 和节点 B 的数据并不一致。
CAP 理论告诉我们分布式系统只能选择 CP 或者 AP,但其实这里的前提是系统发生了“分区”现象。如果系统没有发生分区现象,也就是说 P 不存在的时候(节点间的网络连接一切正常),我们没有必要放弃 C 或者 A,应该 C 和 A 都可以保证,这就要求架构设计的时候既要考虑分区发生时选择 CP 还是 AP,也要考虑分区没有发生时如何保证 CA。
CAP 理论告诉我们三者只能取两个,需要“牺牲”(sacrificed)另外一个,这里的“牺牲”是有一定误导作用的,因为“牺牲”让很多人理解成什么都不做。实际上,CAP 理论的“牺牲”只是说在分区过程中我们无法保证 C 或者 A,但并不意味着什么都不做。因为在系统整个运行周期中,大部分时间都是正常的,发生分区现象的时间并不长。例如,99.99% 可用性(俗称 4 个 9)的系统,一年运行下来,不可用的时间只有 50 分钟;99.999%(俗称 5 个 9)可用性的系统,一年运行下来,不可用的时间只有 5 分钟。分区期间放弃 C 或者 A,并不意味着永远放弃 C 和 A,我们可以在分区期间进行一些操作,从而让分区故障解决后,系统能够重新达到 CA 的状态。
最典型的就是在分区期间记录一些日志,当分区故障解决后,系统根据日志进行数据恢复,使得重新达到 CA 状态。同样以用户管理系统为例,对于用户账号数据,假设我们选择了 CP,则分区发生后,节点 1 可以继续注册新用户,节点 2 无法注册新用户(这里就是不符合 A 的原因,因为节点 2 收到注册请求后会返回 error),此时节点 1 可以将新注册但未同步到节点 2 的用户记录到日志中。当分区恢复后,节点 1 读取日志中的记录,同步给节点 2,当同步完成后,节点 1 和节点 2 就达到了同时满足 CA 的状态。
可以看到,ACID 中的 A(Atomicity)和 CAP 中的 A(Availability)意义完全不同,而 ACID 中的 C 和 CAP 中的 C 名称虽然都是一致性,但含义也完全不一样。ACID 中的 C 是指数据库的数据完整性,而 CAP 中的 C 是指分布式节点中的数据一致性。再结合 ACID 的应用场景是数据库事务,CAP 关注的是分布式系统数据读写这个差异点来看,其实 CAP 和 ACID 的对比就类似关公战秦琼,虽然关公和秦琼都是武将,但其实没有太多可比性。
四. BASE
BASE 是指基本可用(Basically Available)、软状态( Soft State)、最终一致性( Eventual Consistency),核心思想是即使无法做到强一致性(CAP 的一致性就是强一致性),但应用可以采用适合的方式达到最终一致性。
“横向扩展”是为了解决单点瓶颈问题,进而保证高并发量下的「可用性」;“高可用性”是为了解决单点故障(SPOF)问题,进而保证部分节点故障时的「可用性」。由此可以看出,分布式系统的核心诉求就是「可用性」。这个「可用性」正是 CAP 中的 A:用户访问系统时,可以在合理的时间内得到合理的响应。
为了保证「可用性」,一个分布式系统通常由多个节点组成。这些节点各自维护一份数据,但是不管用户访问到哪个节点,原则上都应该读取到相同的数据。为了达到这个效果,一个节点收到写入请求更新自己的数据后,必须将数据同步到其他节点,以保证各个节点的数据「一致性」。这个「一致性」正是 CAP 中的 C:用户访问系统时,可以读取到最近写入的数据。
发生“网络分区”时,系统中多个节点的数据一定是不一致的,但是可以选择对用户表现出「一致性」,代价是牺牲「可用性」:将未能同步得到新数据的部分节点置为“不可用状态”,访问到这些节点的用户显然感知到系统是不可用的。发生“网络分区”时,系统也可以选择「可用性」,此时系统中各个节点都是可用的,只是返回给用户的数据是不一致的。这里的选择,就是 CAP 中的 P。
分布式系统理论上一定会存在 P,所以理论上只能做到 CP 或 AP。如果套用 CAP 中离散的 C/A/P 的概念,理论上没有 P 的只可能是单点(子)系统,所以理论上可以做到 CA。但是单点(子)系统并不是分布式系统,所以其实并不在 CAP 理论的描述范围内。