大家好,又见面了,我是你们的朋友全栈君。
网页加载数据的另一种方式——通过 API(Application Programming Interface,应用程序编程接口)加载数据
网页通过 API 获取数据,实时更新内容, 它规定了网页与服务器之间可以交互什么数据、通过什么样的方式进行交互。
Network
Network 记录的是从打开浏览器的开发者工具到网页加载完毕之间的所有请求。如果你在网页加载完毕后打开,里面可能就是空的,我们开着开发者工具刷新一下网页即可


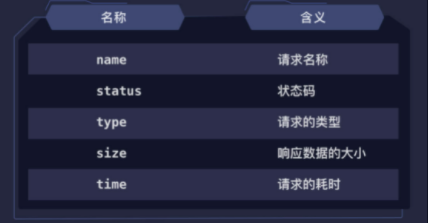
爬虫中常用的请求类型有 All、XHR、Img 和 Media,剩下的了解一下即可:

常用的请求信息,比如请求的名称、状态码、类型、数据大小和耗时等。这些都比较简单,我们只要能看懂,知道是什么意思就行。
在所有请求类型中,有一类非常重要的类型叫做 XHR。提前告诉你,完整的影评就在其中。那么 XHR 到底是什么呢?
-
XHR 全称 XMLHttpRequest,是浏览器内置的对象。浏览器想要在不刷新网页前提下加载、更新局部内容时,必须通过 XHR 向存放数据的服务器发送请求。
反过来说,XHR 类型请求里,就藏着我们需要的搜索结果。
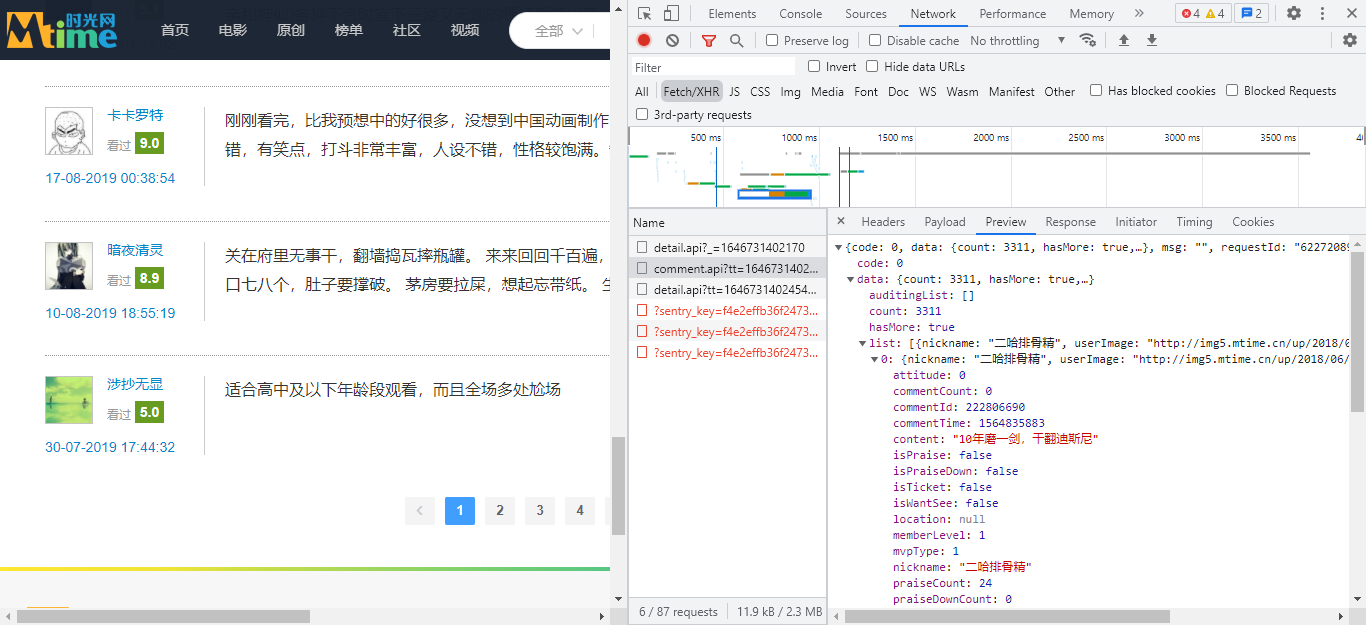
找到了获取评论数据的真正链接,以及相关的请求头参数,接下来我们就可以试着通过爬虫来爬取数据了
import requests headers = { 'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36', 'referer': 'http://movie.mtime.com/' } res = requests.get('http://front-gateway.mtime.com/library/movie/comment.api?tt=1641893701852&movieId=251525&pageIndex=2&pageSize=20&orderType=1', headers=headers) print(res.text)
由于查询字符串较长,requests.get() 方法提供了 params 参数,能让我们以字典的形式传递链接的查询字符串参数,使代码看上去更加的整洁明了

也就是说,链接中的 tt=1641893701852&movieId=251525&pageIndex=2&pageSize=20&orderType=1,可以拆分成一个字典:
params = { "tt": "1641893701852", "movieId": "251525", "pageIndex": "2", "pageSize": "20", "orderType": "1" } res = requests.get( 'http://front-gateway.mtime.com/library/movie/comment.api', params=params, headers=headers )


import requests headers = { 'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36', 'referer': 'http://movie.mtime.com/' } params = { "tt": "1646731402452", "movieId": "251525", "pageIndex": "1", "pageSize": "20", "orderType": "1" } res = requests.get( 'http://front-gateway.mtime.com/library/movie/comment.api', params=params, headers=headers ) print(res.text) print(type(res.text))
爬取评论所在内容
res.text 并不是多层级的字典,只是长得像字典的字符串罢了.
这种长得像字典的字符串,是一种名为 JSON 的数据格式。我们需要将其转换成真正的 字典/列表,才能从中提取出评论数据。所以,接下来我们学习 JSON 来将其转换成字典/列表。
什么是 JSON
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式。 易于人阅读和编写,同时也易于机器解析和生成。
JSON 建构于两种结构:键值对的集合 和 值的有序列表,分别对应 Python 里的字典和列表,这些都是常见的数据结构。大部分现代计算机语言都支持 JSON,所以 JSON 是在编程语言之间通用的数据格式。
JSON 本质上就是一个字符串,只是该字符串符合特定的格式要求。也就是说,我们将字典、列表等用字符串的形式写出来就是 JSON,就像下面这样:
1 # 字典 2 dict = {'price': 233} 3 4 # JSON 5 json = '{"price": 233}' 6 7 # 列表 8 list = ['x', 'y', 'z'] 9 10 # JSON 11 json = '["x", "y", "z"]'
Tips:Python 字符串使用单引号或双引号没有区别,但 JSON 中,字符串必须使用英文的双引号来包裹。
如何解析 JSON
print(type(res.json())) # 输出:<class 'dict'>
res.json() 方法的返回的是真正 dict(字典),这样我们就能从中提取数据了
获取前 5 页的评论为例,看一下如何实现:
import requests headers = { 'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36', 'referer': 'http://movie.mtime.com/' } for num in range(1, 6): params = { "tt": "1646731402452", "movieId": "251525", "pageIndex": "{}".format(num), "pageSize": "20", "orderType": "1" } res = requests.get( 'http://front-gateway.mtime.com/library/movie/comment.api', params=params, headers=headers ) rest = res.json() comment_list = rest['data']['list'] for i in comment_list: print('昵称: '+i['nickname']) print('评论内容: '+i['content'])
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/154594.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
