大家好,又见面了,我是你们的朋友全栈君。
文章目录
目录
1.什么是textCNN
1.1 textCNN 提出的背景
我们知道,CNN在图像领域应用的比较好了,那么CNN能不能用于文本分析呢?答案是肯定的。在2014年,Yoon Kim在其论文“Convolutional Neural Networks for Sentence Classification”就提出了使用CNN对文本进行分类。这应该是最早将CNN用于文本分类中的文章了。所以,我们称将用于文本分析的CNN网络叫做textCNN。
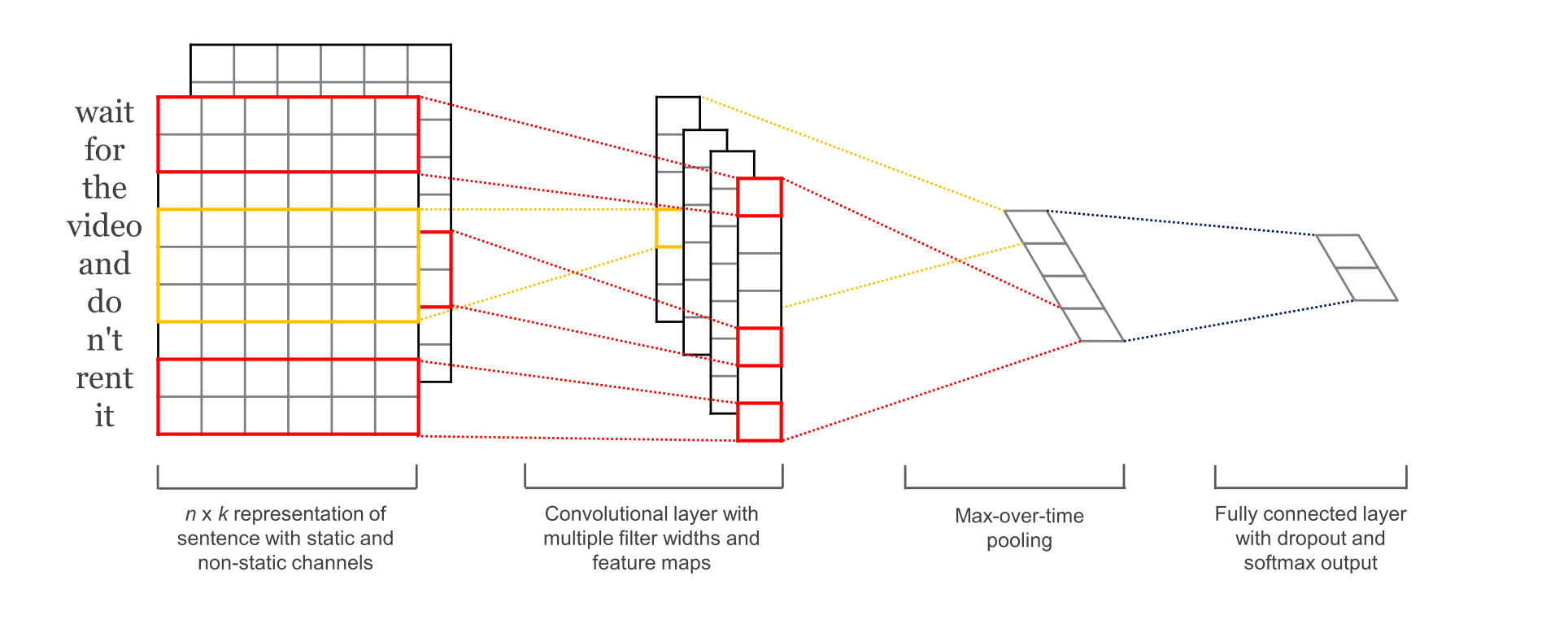

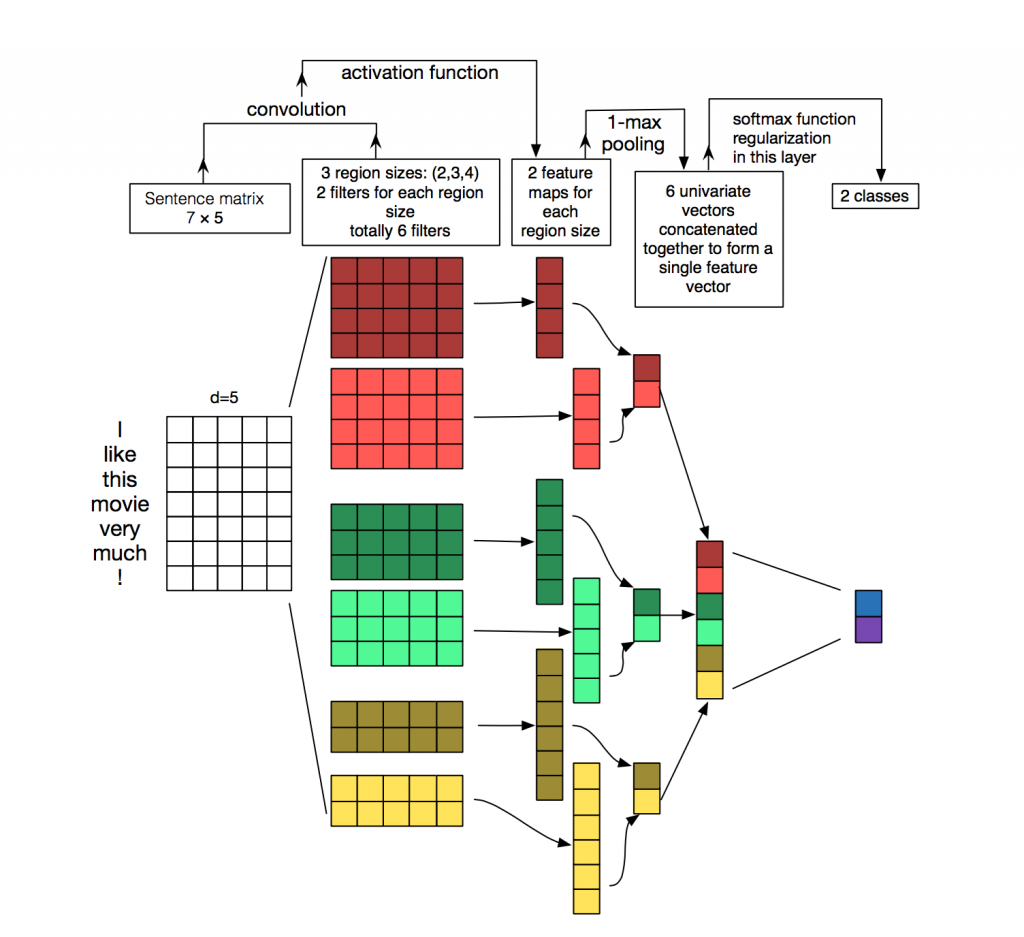
textCNN的变种

1.2 textCNN 合理性分析
- 深度学习模型在计算机视觉与语音识别方面取得了卓越的成就. 在 NLP 也是可以的.
- 卷积具有局部特征提取的功能, 所以可用 CNN 来提取句子中类似 n-gram 的关键信息.
2.textCNN相比于传统图像领域的CNN有什么特点?
1.相同点:
- textCNN和传统的CNN的结构非常类似,都是包含输入层,卷积层,池化层和最后的输出层(softmax)等;可用于CNN防止过拟合的措施,如:dropout , BN , early_stop , L1/L2正则化等也都是通用的;
- 全连接层:全连接层跟其他模型一样,假设有两层全连接层,第一层可以上’relu’作为激活函数,第二层则使用softmax激活函数得到属于每个类的概率。如果处理的数据集为二分类问题,如情感分析的正负面时,第二层也可以使用sigmoid作为激活函数,然后损失函数使用对数损失函数’binary_crossentropy’。
2.创新点:
卷积层:
- 在处理图像数据时,CNN使用的卷积核的宽度和高度的一样的,但是在text-CNN中,卷积核的宽度是与词向量的维度一致!!!这是因为我们输入的每一行向量代表一个词,在抽取特征的过程中,词做为文本的最小粒度,如果我们使用卷积核的宽度小于词向量的维度就已经不是以词作为最小粒度了。
- 而高度和CNN一样,可以自行设置(通常取值2,3,4,5),高度就类似于n-gram了。由于我们的输入是一个句子,句子中相邻的词之间关联性很高,因此,当我们用卷积核进行卷积时,不仅考虑了词义而且考虑了词序及其上下文。(类似于skip-gram和CBOW模型的思想)。
池化层:
- 因为在卷积层过程中我们使用了不同高度的卷积核,使得我们通过卷积层后得到的向量维度会不一致,所以在池化层中,我们使用1-Max-pooling对每个特征向量池化成一个值,即抽取每个特征向量的最大值表示该特征,而且认为这个最大值表示的是最重要的特征。当我们对所有特征向量进行1-Max-Pooling之后,还需要将每个值给拼接起来。得到池化层最终的特征向量。在池化层到全连接层之前可以加上dropout防止过拟合。
3.textCNN例子讲解
3.1 参数和超参数

3.2 textCNN的数据
- 打标签分类,对每句话进行分类
- jieba分词,可以选取的操作,自己添加词库和停用词。
使用jieba分词 - 得到想要的分词后,进行word2id操作,获取文本特征
- shuf 制作好训练、测试、验证数据集
3.3 textCNN的网络结构定义

3.4 代码
import tensorflow as tf
import numpy as np
class TextCNN(object):
""" A CNN for text classification. Uses an embedding layer, followed by a convolutional, max-pooling and softmax layer. sequence_length = """
def __init__(
self, sequence_length, num_classes, vocab_size,
embedding_size, filter_sizes, num_filters, l2_reg_lambda=0.0):
# 定义模型数据输出结构 定长的sequence_length
self.input_x = tf.placeholder(tf.int32, [None, sequence_length], name="input_x")
self.input_y = tf.placeholder(tf.float32, [None, num_classes], name="input_y")
self.dropout_keep_prob = tf.placeholder(tf.float32, name="dropout_keep_prob")
# Keeping track of l2 regularization loss (optional)
l2_loss = tf.constant(0.0)
# Embedding layer
with tf.device('/cpu:0'), tf.name_scope("embedding"):
self.W = tf.Variable(
# 每一个词都是embedding_size长度的特征向量 (18758,128)
tf.random_uniform([vocab_size, embedding_size], -1.0, 1.0),
name="W")
#根据词的下标,获取它们的word2vec。
#embedded_chars的shape[sequence_length, embedding_size]
# (none,56,128) sequence_length = 56
self.embedded_chars = tf.nn.embedding_lookup(self.W, self.input_x)
#扩充维度 相当于一个1维的通道数
# [None,56,128,1]
self.embedded_chars_expanded = tf.expand_dims(self.embedded_chars, -1)
# Create a convolution + maxpool layer for each filter size
pooled_outputs = []
for i, filter_size in enumerate(filter_sizes):
with tf.name_scope("conv-maxpool-%s" % filter_size):
# Convolution Layer
# filter_size 分别为3 4 5
filter_shape = [filter_size, embedding_size, 1, num_filters]
W = tf.Variable(tf.truncated_normal(filter_shape, stddev=0.1), name="W")
b = tf.Variable(tf.constant(0.1, shape=[num_filters]), name="b")
conv = tf.nn.conv2d( # [None,56-3+1,1,128] [None,56-4+1,1,128] [None,56-5+1,1,128]
self.embedded_chars_expanded,
W,
strides=[1, 1, 1, 1],
padding="VALID",
name="conv")
# Apply nonlinearity
h = tf.nn.relu(tf.nn.bias_add(conv, b), name="relu")
# Maxpooling over the outputs
pooled = tf.nn.max_pool( #[None,1,1,128]
h,
ksize=[1, sequence_length - filter_size + 1, 1, 1], #[1,54,1,1] [1,53,1,1] [1,52,1,1]
strides=[1, 1, 1, 1],
padding='VALID',
name="pool")
print(pooled)
pooled_outputs.append(pooled)
# Combine all the pooled features
num_filters_total = num_filters * len(filter_sizes)
self.h_pool = tf.concat(pooled_outputs, 3)
self.h_pool_flat = tf.reshape(self.h_pool, [-1, num_filters_total])
# 全连接dropout
with tf.name_scope("dropout"):
self.h_drop = tf.nn.dropout(self.h_pool_flat, self.dropout_keep_prob)
# Final (unnormalized) scores and predictions
with tf.name_scope("output"):
W = tf.get_variable(
"W",
shape=[num_filters_total, num_classes],
initializer=tf.contrib.layers.xavier_initializer())
b = tf.Variable(tf.constant(0.1, shape=[num_classes]), name="b")
l2_loss += tf.nn.l2_loss(W)
l2_loss += tf.nn.l2_loss(b)
self.scores = tf.nn.xw_plus_b(self.h_drop, W, b, name="scores")
self.predictions = tf.argmax(self.scores, 1, name="predictions")
# Calculate mean cross-entropy loss
with tf.name_scope("loss"):
losses = tf.nn.softmax_cross_entropy_with_logits(logits=self.scores, labels=self.input_y)
self.loss = tf.reduce_mean(losses) + l2_reg_lambda * l2_loss
# Accuracy
with tf.name_scope("accuracy"):
correct_predictions = tf.equal(self.predictions, tf.argmax(self.input_y, 1))
self.accuracy = tf.reduce_mean(tf.cast(correct_predictions, "float"), name="accuracy")
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/154013.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
