大家好,又见面了,我是你们的朋友全栈君。
采用selenium界面抓取信息,需要渲染界面,并且也是单线程操作,效率极低,一晚上只爬去了一个工行的数据。
突然想到了分布式爬虫
- 安装 Scrapy
pip版本过于老旧不能使用,需要升级pip版本,输入python -m pip install --upgrade pip,升级成功
安装scrapy命令:pip install Scrapy
因为scrapy框架基于Twisted,所以先要下载其whl包安装
地址:http://www.lfd.uci.edu/~gohlke/pythonlibs/
搜索 twisted 根据自己的版本下载
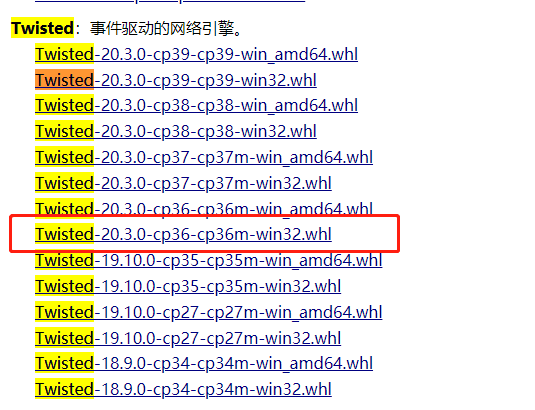

进行安装 xxxxxxxx是包的名字 进入whl包所在的路径,执行下面命令
pip install xxxxxxx.whl- scrapy的使用
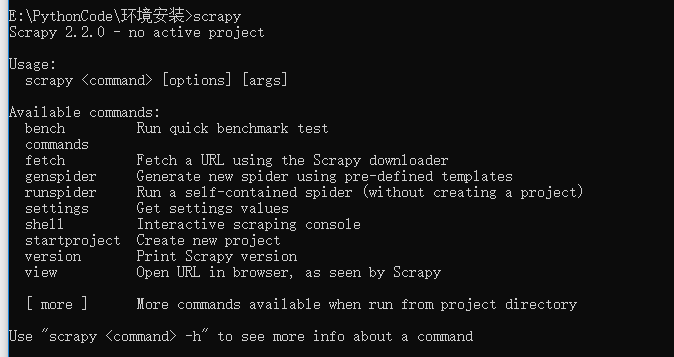
首先,在我们进行第一步——Scrapy的安装时,无论通过什么方式安装,都要进行验证,在验证时输入Scrapy命令后,会得到系统给出的类似于文档的提示,其中包括了Scrapy的可执行命令
(1)首先创建已给爬虫文件夹,cmd中打开这个文件夹的目录
(2)在终端输入指令:scrapy startproject Bank 进行项目创建。scrapy startproject是创建项目的命令,后面跟的是项目名称。该指令执行后的结果如下图所示
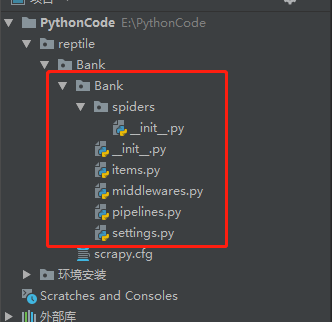
reptile文件夹中,被创建几个文件夹和py文件,这就表示一个项目初步创建成功。
(3) cd spiders , 进入spiders文件夹内
(4)在终端中输入scrapy genspider bankSpider icvio.cn,这个命令是指定要爬取的网站的域名,命令格式为:scrapy genspider taobaoSpider + 目标网站的域名。执行效果如图所示:

至此,一个初步得scrapy项目就已经创建成功,下面我们了解一下这个框架的每个部分的功能:
Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,
Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器),
Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方.
Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。
Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
四. 开始前的准备工作。
在第二部分,我们初步创建了一步Scrapy项目,在自动创建的文件夹中,有着如图所示的几个文件:
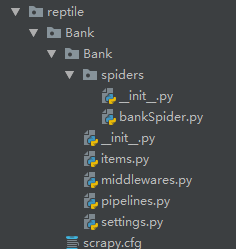
它们的作用分别是:
items.py:定义爬虫程序的数据模型
middlewares.py:定义数据模型中的中间件
pipelines.py:管道文件,负责对爬虫返回数据的处理
settings.py:爬虫程序设置,主要是一些优先级设置,优先级越高,值越小
scrapy.cfg:内容为scrapy的基础配置
值得注意的是,在学习阶段,我们要明白几点设置文件setting中的几处配置代码,它们影响着我们的爬虫的效率:
(一)修改ROBOTSTXT_OBEY
ROBOTSTXT_OBEY = True
这行代码意思是:是否遵守爬虫协议,学习阶段我们要改为False
因为默认为 True,就是要遵守 robots.txt 的规则, robots.txt 是遵循 Robot协议 的一个文件,它保存在网站的服务器中,它的作用是,告诉搜索引擎爬虫,本网站哪些目录下的网页不希望你进行爬取收录。在 Scrapy 启动后,会在第一时间访问网站的 robots.txt 文件,然后决定该网站的爬取范围。查看 robots.txt 可以直接网址后接 robots.txt 即可。
SPIDER_MIDDLEWARES = {
‘Bank.middlewares.WxzSpiderMiddleware’: 800,
}
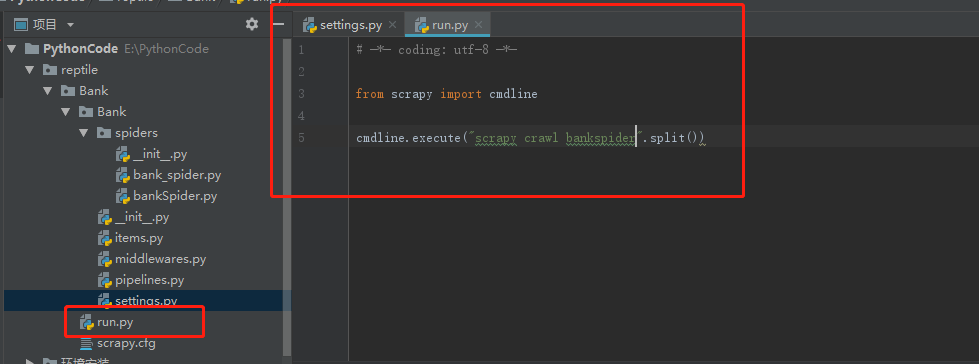
(二)、在 scrapy.cfg 同级目录下创建 pycharm 调试脚本 run.py,内容如下:
# -*- coding: utf-8 -*-
from scrapy import cmdline
cmdline.execute(“scrapy crawl bankspider”.split())
(三)settings.py 里添加 USER_AGENT。
USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36"

(四)不需要模拟登陆,settings.py 里的 COOKIES_ENABLED ( Cookies中间件) 设置禁用状态。
COOKIES_ENABLED = False
第五步: 定义 Item,编写 items.py 文件。
class BankItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 银行名称
yhmc = scrapy.Field()
# 联行号
lhh = scrapy.Field()
# 电话
dh = scrapy.Field()
# 地址
dz = scrapy.Field()
# 省份
sf = scrapy.Field()
第六步: 查看HTML源码,使用XPath helper爬虫插件一起查看需要爬取的字段的 xpath 路径。
编写bankSpider.py文件
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/153155.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
