大家好,又见面了,我是你们的朋友全栈君。
基于树莓派的语音识别和语音合成
摘要
语音识别技术即Automatic Speech Recognition(简称ASR),是指将人说话的语音信号转换为可被计算机程序所识别的信息,从而识别说话人的语音指令及文字内容的技术。目前语音识别被广泛的应用于客服质检,导航,智能家居等领域。树莓派自问世以来,受众多计算机发烧友和创客的追捧,曾经一“派”难求。别看其外表“娇小”,内“心”却很强大,视频、音频等功能通通皆有,可谓是“麻雀虽小,五脏俱全”。本文采用百度云语音识别API接口,在树莓派上实现低于60s音频的语音识别,也可以用于合成文本长度小于1024字节的音频。
此外,若能够结合snowboy离线语音唤醒引擎可实现离线语音唤醒,实现语音交互。
材料:
树莓派3B+ ×1
USB声卡 ×1
麦克风 ×1
PC ×1
音视频线材若干


实现过程:
一、 百度云语音识别 python-SDK的安装
-
为了能够调用百度云语音识别API接口,需要申请属于自己的百度AI开发者账号,安装SDK(Software Development Kit,软件开发工具包)。
-
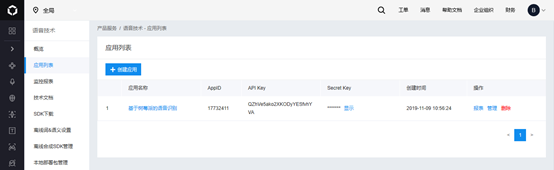
进入百度云平台,进入百度语音控制台后,创建自己的应用,获取属于你的ID号和密钥。
-
Python-SDK的下载与安装
将下载的SDK包拷贝到树莓派pi目录下,终端界面解压安装,安装过程如下:
解压包:unzip aip-python-sdk-2.0.0.zip
安装SDK包: sudo pip install baidu-aip

二.修改编辑官方python测试程序
- 语音识别程序:
#_*_ coding:UTF-8 _*_
# @author: zdl
# 百度云语音识别Demo,实现对本地语音文件的识别。
# 需安装好python-SDK,录音文件不不超过60s,文件类型为wav格式。
# 音频参数需设置为 单通道 采样频率为16K PCM格式 可以先采用官方音频进行测试
# 导入AipSpeech AipSpeech是语音识别的Python SDK客户端
from aip import AipSpeech
import os
''' 你的APPID AK SK 参数在申请的百度云语音服务的控制台查看'''
APP_ID = '17xxxx11'
API_KEY = 'QZhVe5xxxxxvhYVA'
SECRET_KEY = 'bGlGGxbWLxxxxxxxxA8tshAGA'
# 新建一个AipSpeech
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
# 读取文件
def get_file_content(test): #filePath 待读取文件名
with open(test, 'rb') as fp:
return fp.read()
def stt(test): # 语音识别
# 识别本地文件
result = client.asr(get_file_content(test),
'wav',
16000,
{
'dev_pid': 1536,} # dev_pid参数表示识别的语言类型 1536表示普通话
)
print (result)
# 解析返回值,打印语音识别的结果
if result['err_msg']=='success.':
word = result['result'][0].encode('utf-8') # utf-8编码
if word!='':
if word[len(word)-3:len(word)]==',':
print (word[0:len(word)-3])
with open('demo.txt','wb+') as f:
f.write(word[0:len(word)-3])
f.close()
else:
print (word.decode('utf-8').encode('gbk'))
with open('demo.txt','wb+') as f:
f.write(word)
f.close()
else:
print ("音频文件不存在或格式错误")
else:
print ("错误")
# main函数 识别本地录音文件yahboom.wav
if __name__ == '__main__':
stt('test.wav')
- 语音合成程序:
#_*_ coding:UTF-8 _*_
# @author: zdl
# 百度云语音合成Demo,实现对本地文本的语音合成。
# 需安装好python-SDK,待合成文本不超过1024个字节
# 合成成功返回audio.mp3 否则返回错误代码
# 导入AipSpeech AipSpeech是语音识别的Python SDK客户端
from aip import AipSpeech
import os
''' 你的APPID AK SK 参数在申请的百度云语音服务的控制台查看'''
APP_ID = '17xxxx1'
API_KEY = 'QZhVxxxxxxxxxxxhYVA'
SECRET_KEY = 'bGlGGxxxxxxxxxxxxPGP8A8tshAGA'
# 新建一个AipSpeech
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
# 将本地文件进行语音合成
def tts(demo):
f = open(demo,'r')
command = f.read()
if len(command) != 0:
word = command
f.close()
result = client.synthesis(word,'zh',1, {
'vol': 5,'per':0,
})
# 合成正确返回audio.mp3,错误则返回dict
if not isinstance(result, dict):
with open('audio.mp3', 'wb') as f:
f.write(result)
f.close()
print ('tts successful')
# main
if __name__ == '__main__':
tts('demo.txt')
测试和分析:
测试过程中,我对此功能进行三次测试,测试用例分别为:
- 短句“北京理工大学”
- 短句“智能语音交互技术”
- 绕口令
“刘奶奶找牛奶奶买牛奶,牛奶奶给刘奶奶拿牛奶,刘奶奶说牛奶奶的牛奶不如柳奶奶的牛奶,牛奶奶说柳奶奶的牛奶会流奶,柳奶奶听见了大骂牛奶奶你的才会流奶,柳奶奶和牛奶奶泼牛奶吓坏了刘奶奶,大骂再也不买柳奶奶和牛奶奶的牛奶”
此三条测试用例,分别从长句和短句,简单含义和复杂含义,是否有易混音三个方面对比进行测试,对百度语音技术的准确性提出了较高的要求。
测试前,需要提前用录音软件录制好三段音频,然后用Adobe Audition软件对音频格式化处理,因为百度智能云语音识别技术支持原始 PCM 的录音参数必须符合 16k 采样率、16bit 位深、单声道,支持的格式有:pcm(不压缩)、wav(不压缩,pcm编码)、amr(压缩格式)。
结果及结论:
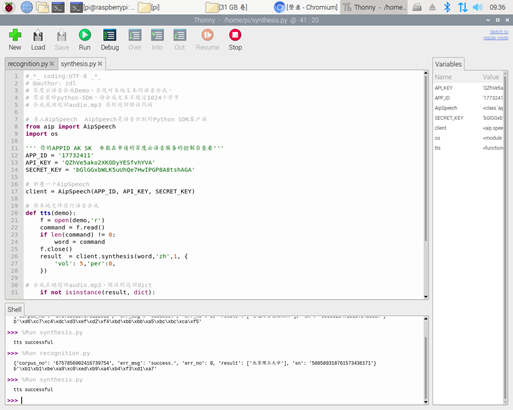
测试一:短句“北京理工大学”
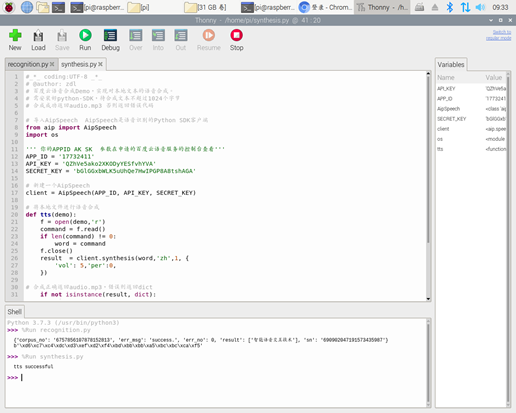
测试二:短句“智能语音交互技术”
测试三:绕口令
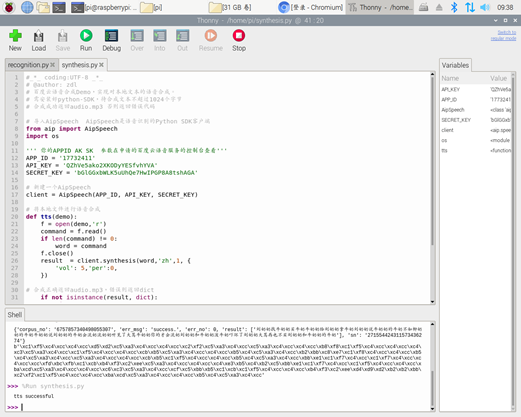
三个测试均成功运行。
语音识别方面,此程序成功运行后,会在python-IDE中产生返回值结果,并会在路径/home/pi内产生一个demo.txt文件,文件内容即为输入音频文件的文字识别结果。百度在语音识别方面做出的努力可见一斑,通过调整程序中的参数,可以识别除普通话以外其他语言的音频文件(如英语),而且准确度较高,尤其是短句识别甚高,在易混淆字音重复出现的绕口令中,仅将其中一个“柳”字错误识别为“牛”。
语音合成方面,程序以上述的demo.txt为输入,将文字上传到百度云数据库,转换成功后反馈“successful”到IDE界面,并在目录/home/pi文件夹下生成audio.wav音频文件,此文件即为由文字合成的语音。测试发现,次音频信号在生活中较为熟悉的停顿处有较为明显的顿挫感,但是在长难句中,无法做到顿挫处的智能识别。
遇到的问题:
在整个编程过程中,可以说是举步维艰,由于自身能力有限,初学python和Linux,导致在系统操作和规范方面有很多的盲区,导致犯了很多诸如Linux系统授权、python缩进、命令行书写等十分低级的错误,一度陷入程序不断报错却不知错在何处的尴尬境地。同时,由于百度语音识别技术对于上传的音频有着较为苛刻的要求,必须符合 16k 采样率、16bit 位深、单声道等,对于这些内容的不熟悉也走了很多弯路。
最令我惊艳的是,百度智能云计算AI开放平台为程序员搭建了一个十分全面,而且性能强悍的平台,从语音到图像,再到智能数据,涉猎了我们所熟知的绝大多数AI领域,其中对不同实现方式进行了细致的备注和说明,为我实现此项目扫清了障碍。

深入开发的设想:
在完成上述功能的实现之后,我尝试让树莓派实现类似与智能音箱的人机交互功能(全网已有大神实现),实现过程中无疑要用到snowboy引擎,它一款高度可定制的唤醒词检测引擎,可以用于实时嵌入式系统,并且始终监听(即使离线)。当前,它可以运行在 Raspberry Pi、(Ubuntu)Linux 和 Mac OS X 系统上。在一些棘手的解决方案中,它可以运行完整的自动语音识别(ASR,Automatic Speech Recognition)来执行热词检测。但是,我在尝试实现过程中遇到了几个无法解决的问题:
- 由于树莓派内置声卡没有麦克风,需要利用外接声卡执行热词唤醒,但是在Linux系统中更改声卡驱动成了我越不去的坎儿,尝试了网络上更改驱动的多种方式后,无一能更够成功更改,我仍需继续在Linux方向深入学习。
- 在树莓派上下载好portaudio后,编译过程中频繁报错,涉及到gcc相关内容,我在这方面仍需继续努力。
致谢:
感谢百度智能云提供的云计算支持
参考文献:
- https://ai.baidu.com/docs#/ASR-Online-Python-SDK/f55e8c00
- https://www.cnblogs.com/rnckty/p/8067115.html
- https://blog.csdn.net/sinat_35162460/article/details/86544772
- https://snowboy.kitt.ai/
- https://blog.csdn.net/sinat_35162460/article/details/86547013
作者:Boyle Zhao
2019年11月于北京理工大学
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/153143.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
