大家好,又见面了,我是你们的朋友全栈君。
语音合成:把语音波形文件重现,以一种灵活的方式,只用极少数的基础数据,比如元音辅音的语音参数,那么首先需要研究元音辅音的语音学性质。
先从元音开始,根据相关资料,不同的元音是由相同的原始声带音通过不同的共振腔(由声腔形状的变化决定)产生不同的共振效果,导致其频谱发生很大变化而得以区分。一般来说每个频谱都有三个振幅比较强的频率区,在频谱上呈现为波峰状,称为“共振峰”(formant),从低频到高频顺序排列为第一共振峰、第二共振峰和第三共振峰,简称为F1、F2、F3,还可以有F4、F5,不过与语音关系不大,因此忽略。
原始声带音的基本特点是,谐波的频率越高,振幅就越小,频谱的振幅曲线从高到低,形成明显的斜坡,原始声带音的频率称为基频F0(疑问:原始声带音的频谱图中有多个频率,哪一个是基频?难道都是?)
元音的共振峰频率和基频之间没有相互依存的关系。基频由声带颤动的频率决定,共振峰频率则取决于共振腔的形状,两种频率的变化是彼此独立的。
要注意对频谱图和波形图的对照使用:二维频谱所表现的只是频率和振幅的二维关系,并没有包括时间因素,分析一个音段,不论切分得多么小,都必然占有一段时间,只有能够反映频率、振幅、时间三维关系的频谱,才能够把一个音段的声学特征全部表现出来。比如现代语音学研究常用的语图仪就是这样一种动态频谱仪,语图仪输出的语图中,横坐标是时间,单位毫秒,纵坐标是频率,单位HZ,振幅的强弱通过图形痕迹的浓度来表示,颜色越深,说明振幅越强,颜色越浅,说明振幅越小,振幅的单位是分贝dB。
波形图用来描述时域信号,横轴为时间(可以直观地看到波形周期),纵轴为振幅;频谱图用来描述频域信号,横轴为频率,纵轴为dB化的幅值,时域信号和频域信号可以通过FFT、IFFT算法来转换(快速傅里叶变换和快速傅里叶变换的逆变换),有很多在时域无法完成的信号处理算法可以在频域上轻松处理。缺点是使用FFT会出现频谱泄露。
频谱图:


频谱图来自 http://www.innovateasia.com/cn/win_2008/CN321.htm
语图(下面的图,上面那个是波形图):

语图来自 中国社会科学院语言研究所语音研究室(http://ling.cass.cn/yuyin/spectrum/spectrum.htm)
http://www.it9000.cn/tech/CTI/wav.html
WAV文件格式介绍
文件是Windows标准的文件格式,WAV文件作为多媒体中使用的声波文件格式之一,它是以RIFF格式为标准的。RIFF是英文Resource Interchange FileFormat的缩写,每个WAV文件的头四个字节便是“RIFF”。WAV文件由文件头和数据体两大部分组成。其中文件头又分为RIFF/WAV文件标识段和声音数据格式说明段两部分。WAV文件各部分内容及格式见附表。常见的声音文件主要有两种,分别对应于单声道(11.025KHz采样率、8Bit的采样值)和双声道(44.1KHz采样率、16Bit的采样值)。采样率是指:声音信号在“模→数”转换过程中单位时间内采样的次数。采样值是指每一次采样周期内声音模拟信号的积分值。对于单声道声音文件,采样数据为八位的短整数(short int 00H-FFH); 而对于双声道立体声声音文件,每次采样数据为一个16位的整数(int),高八位和低八位分别代表左右两个声道。WAV文件数据块包含以脉冲编码调制(PCM)格式表示的样本。WAV文件是由样本组织而成的。在单声道WAV文件中,声道0代表左声道,声道1代表右声道。在多声道WAV文件中,样本是交替出现的。
WAV文件格式说明表
| 文件头 | 偏移地址 | 字节数 | 数据类型 | 内 容 |
| 00 | H | 4 | char | “RIFF”标志 |
| 04 | H | 4 | long | int 文件长度 |
| 08 | H | 4 | char | “WAV”标志 |
| 0C | H | 4 | char | “fmt”标志 |
| 10 | H | 4 | 过渡字节(不定) | |
| 14 | H | 2 | int | 格式类别(10H为PCM形式的声音数据) |
| 16 | H | 2 | int | 单声道为1,双声道为2通道数 |
| 18 | H | 2 | int | 采样率(每秒样本数),表示每个通道的播放速度 |
| 1C | H | 4 | long | 波形音频数据传送速率,其值为通道数×每秒数据位数×每样 本的数据位数/8。播放软件利用此值可以估计缓冲区的大小 |
| 22 | H | 2 | 每样本的数据位数,表示每个声道中各个样本的数据位数。如果有多 个声道,对每个声道而言,样本大小都一样。 24H 4 char 数据标记符"data" 28H 4 long int 语音数据的长度 |
PCM数据的存放方式:
样本1 样本2
8位单声道 0声道 0声道
8位立体声 0声道(左) 1声道(右) 0声道(左) 1声道(右)
16位单声道 0声道低字节 0声道高字节 0声道低字节 0声道高字节
16位立体声 0声道(左)低字节 0声道(左)高字节 1声道(右)低字节 1声道(右)高字节
PCM数据的存放方式:
WAV文件的每个样本值包含在一个整数i中,i的长度为容纳指定样本长度所需 的最小字节数。首先存储低有效字节,表示样本幅度的位放在i的高有效位上, 剩下的位置为0,这样8位和16位的PCM波形样本的数据格式如下所示。
| 样本大小 | 数据格式 | 最大值 | 最小值 |
| 8位PCM | unsigned int | 225 | 0 |
| 16位PCM | int | 327 | 67 |
http://210.28.216.200/cai/dmtjishu/course2/course2-1.htm#nowhere
一. 模拟音频和数字音频
1.模拟音频
 物体振动产生声音,为了记录和保存声音信号,先后诞生了机械录音(以留声机、机械唱片为代表)、光学录音(以电影胶片为代表)、磁性录音(以磁带录音为代表)等模拟录音方式,二十世纪七、八十年代开始进入了数字录音的时代。
物体振动产生声音,为了记录和保存声音信号,先后诞生了机械录音(以留声机、机械唱片为代表)、光学录音(以电影胶片为代表)、磁性录音(以磁带录音为代表)等模拟录音方式,二十世纪七、八十年代开始进入了数字录音的时代。
声音是机械振动在弹性介质中传播的机械波。声音的强弱体现在声波压力的大小上,音调的高低体现在声音的频率上。声音用电表示时,声音信号在时间和幅度上都是连续的模拟信号。声音信号的两个基本参数是频率和幅度。频率是指信号每秒钟变化的次数,用Hz表示。幅度是指信号的强弱。
2.数字音频
数字音频主要包括两类:波形音频和MIDI音频。
模拟声音在时间和幅度上是连续的,声音的数字化是通过采样、量化和编码,把模拟量表示的音频信号转换成由许多二进制数1和0组成的数字音频信号。数字音频是一个数据序列,在时间和幅度上是断续的。
计算机内的基本数制是二进制,为此我们要把声音数据写成计算机的数据格式。将连续的模拟音频信号转换成有限个数字表示的离散序列(即实现音频数字化),在这一处理技术中,涉及到音频的采样、量化和编码。
二.数字音频的采样和量化
 声音进入计算机的第一步就是数字化,数字化实际上就是采样和量化。连续时间的离散化通过采样来实现,如果每隔相等的一小段时间采样一次,称为均匀采样(uniform sampling);连续幅度的离散化通过量化(quantization)来实现,把信号的强度划分成一小段一小段,如果幅度的划分是等间隔的,就称为线性量化,否则就称为非线性量化。
声音进入计算机的第一步就是数字化,数字化实际上就是采样和量化。连续时间的离散化通过采样来实现,如果每隔相等的一小段时间采样一次,称为均匀采样(uniform sampling);连续幅度的离散化通过量化(quantization)来实现,把信号的强度划分成一小段一小段,如果幅度的划分是等间隔的,就称为线性量化,否则就称为非线性量化。
在数字音频技术中,把表示声音强弱的模拟电压用数字表示,如0.5V电压用数字20表示,2V电压是80表示。模拟电压的幅度,即使在某电平范围内,仍然可以有无穷多个,如1.2V,1.21V,1.215V…。而用数字来表示音频幅度时,只能把无穷多个电压幅度用有限个数字表示。即把某一幅度范围内的电压用一个数字表示,这称之为量化。
计算机内的基本数制是二进制,为此我们也要把声音数据写成计算机的数据格式,这称之为编码,模拟电压幅度、量化、编码的关系举例如下表。
|
声音数字化需要回答两个问题:①每秒钟需要采集多少个声音样本,也就是采样频率(fs)是多少,②每个声音样本的位数(bit per sample,bps)应该是多少,也就是量化精度。
1.
采样频率

| 采样频率是指将模拟声音波形数字化时,每秒钟所抽取声波幅度样本的次数,采样频率的计算单位是kHz。通常,采样频率越高声音失真越小,但用于存储音频的数据量也越大。
音频实际上是连续信号,或称连续时间函数x(t)。用计算机处理这些信号时,必须先对连续信号采样,即按一定的时间间隔(T)取值, 得到x(nT)(n为整数)。T称采样周期,1/T称为采样频率。称x(nT)为离散信号。离散信号 x(nT) 是从连续信号 x(t) 上取出的一部分值。 采样定理:设连续信号x(t)的频谱为x(f),以采样间隔T采样得到离散信号x(nT),如果满足: 当|f|≥fc时,fc是截止频率 T≤ 1/2fc 或fc≤ 1/2T 则可以由离散信号x(nT)完全确定连续信号x(t)。 当采样频率等于1/(2T)时,即fN =1/2T,称fN为奈奎斯特频率。 采样频率的高低是根据奈奎斯特理论(Nyquist theory)和声音信号本身的最高频率决定的。奈奎斯特理论指出,采样频率不应低于声音信号最高频率的两倍,这样就能把以数字表达的声音还原成原来的声音,这叫做无损数字化(lossless digitization)。 通常人耳能听到频率范围大约在20Hz~20kHz之间的声音,根据奈奎斯特理论,为了保证声音不失真,采样频率应在40kHz左右。常用的音频采样频率有:8kHz、11.025kHz、22.05kHz、16kHz、37.8kHz、44.1kHz、48kHz等。 |
2.
量化精度(也称量化位数、量化级、样本尺寸、采样精度等)
| 量化是将经过采样得到的离散数据转换成二进制数的过程,量化精度是每个采样点能够表示的数据范围,在计算机中音频的量化位数一般为4、8、16、32位(bit)等。例如:量化精度为8bit时,每个采样点可以表示256个不同的量化值,而量化精度为16bit时,每个采样点可以表示65536个不同的量化值。量化精度的大小影响到声音的质量,显然,位数越多,量化后的波形越接近原始波形,声音的质量越高,而需要的存储空间也越多;位数越少,声音的质量越低,需要的存储空间越少。
采样精度的另一种表示方法是信号噪声比,简称为信噪比(signal-to-noise ratio,SNR),并用下式计算: SNR= 10 log [(Vsignal)2 / (Vnoise)2]=20 log (Vsignal / Vnoise) 例1:假设Vnoise=1,采样精度为1位表示Vsignal=21,它的信噪比SNR=6分贝。 量化采样的过程如下:先将整个幅度划分成为有限个小幅度(量化阶距)的集合,把落入某个阶距内的样值归为一类,并赋予相同的量化值。 如果量化值是均匀分布的,我们称之为均匀量化,也称为线性量化。
如果大输入信号采用大的量化间隔,小输入信号采用小的量化间隔,这样就可以在满足精度要求的情况下使用较小的位数来表示。数据还原时采用相同的原则。量化值是非均匀分布的,我们称之为非均匀量化,也称非线性量化。
|


3.
声道数
| 记录声音时,如果每次生成一个声波数据,称为单声道;每次生成两个声波数据,称为双声道。使用双声道记录声音,能够在一定程度上再现声音的方位,反映人耳的听觉特性。 |
4.
声音质量与数据率
| 根据声音的频带,通常把声音的质量分成5个等级,由低到高分别是电话(telephone)、调幅(amplitude modulation,AM)广播、调频(frequency modulation,FM)广播、激光唱盘(CD-Audio)和数字录音带(digital audio tape,DAT)的声音。在这5个等级中,使用的采样频率、样本精度、通道数和数据率列于下表。
表: 声音质量和数据率
|





5.
数字音频的存储
|
一般来说,采样频率、量化位数越高,声音质量也就越高,保存这段声音所用的空间也就越大。立体声(双声道)是单声道文件的两倍。 如:录制1分钟采样频率为44.1KHz,量化精度为16位,立体声的声音(CD音质),文件大小为: |
三. 数字音频的文件格式
声音数据有多种存储格式,这里我们主要介绍WAV 文件、MIDI文件。
1.
WAV 文件
| WAV 文件主要用在PC上,是微软公司的音频文件格式,又称为波形文件格式,它来源于对声音模拟波形的采样,用不同的采样频率对声音的模拟波形进行采样可以得到一系列离散的采样点,以不同的量化位数把这些采样点的值转换成二进制数,然后存盘,就产生了声音的WAV文件。
声音是由采样数据组成的,所以它需要的存储容量很大。用前面我们介绍的公式可以简单的推算出WAV文件的文件大小。 |
2.
MIDI文件
|
MIDI是Musical Instrument Digital Interface的首写字母组合词,可译成“电子乐器数字接口”。用于在音乐合成器(music synthesizers)、乐器(musical instruments)和计算机之间交换音乐信息的一种标准协议。MIDI是乐器和计算机使用的标准语言,是一套指令(即命令的约定),它指示乐器即MIDI设备要做什么,怎么做,如演奏音符、加大音量、生成音响效果等。MIDI不是声音信号,在MIDI电缆上传送的不是声音,而是发给MIDI设备或其它装置让它产生声音或执行某个动作的指令。当信息通过一个音乐或声音合成器进行播放时,该合成器对系列的MIDI信息进行解释,然后产生出相应的一段音乐或声音。 记录MIDI信息的标准格式文件称为MIDI文件,其中包含音符、定时和多达16个通道的乐器定义以及键号、通道号、持续时间、音量和击键力度等各个音符的有关信息。由于MIDI文件是一系列指令而不是波形数据的集合,所以其要求的存储空间较小。 |
|
WAV文件记录的是声音的波形,要求较大的数据空间;MIDI文件记录的是一系列的指令,文件紧凑占用空间小,预先装载比WAV容易,设计播放所需音频的灵活性较大。WAV文件可编辑性好于MIDI,音质饱满。 WAV文件适合于: MIDI文件适合于: |
表: 常见的数字声音文件扩展名
|
文件的扩展名
|
说明 |
|
au |
Sun和NeXT公司的声音文件存储格式(8位μ律编码或者16位线性编码) |
|
Aif |
Apple计算机上的声音文件存储格式(Audio Interchange File Format) |
|
ape |
Monkey’s Audio |
|
mid |
Windows的MIDI文件存储格式 |
|
mp3 |
MPEG Layer III |
|
rm |
RealNetworks公司的流放式声音文件格式(RealMedia) |
|
ra |
RealNetworks公司的流放式声音文件格式(RealAudio) |
|
voc |
声霸卡存储的声音文件存储格式(Creative Voice) |
|
wav |
Windows采用的波形声音文件存储格式 |
|
wrk |
Cakewalk Pro软件采用的MIDI文件存储格式 |
四.音频信号的特点
音频信号处理的特点如下:
(1) 音频信号是时间依赖的连续媒体。因此音频处理的时序性要求很高,如果在时间上有 25ms 的延迟,人就会感到断续。
(2) 理想的合成声音应是立体声。由于人接收声音有两个通道(左耳、右耳),因此计算机模拟自然声音也应有两个声道,即立体声。
(3) 由于语音信号不仅仅是声音的载体,同时情感等信息也包含其中,因此对语音信号的处理,要抽取语意等其它信息,如可能会涉及到语言学、社会学、声学等。
从人与计算机交互的角度来看音频信号相应的处理如下:
(1) 人与计算机通信(计算机接收音频信号)。音频获取,语音识别与理解。
(2) 计算机与人通信(计算机输出音频)。 音频合成( 音乐合成,语音合成)、声音定位(立体声模拟、音频/视频同步)。
(3) 人—计算机—人通信:人通过网络,与处于异地的人进行语音通信,需要的音频处理包括:语音采集、音频编码/解码、音频传输等。这里音频编/解码技术是信道利用率的关键。
http://www.chinaaet.com/article/index.aspx?id=14965
语音信号产生模型的建立及应用
摘 要:从人类语音产生的机理出发,介绍了语音信号的特征和语音信号的语谱图,引出了语音信号的产生模型。同时讨论了在语音信号产生的模型应用中,线性预测编码方法及语音产生模型在语音合成和语音识别中的应用原理,体现了语音产生模型在语音处理技术方面的重要地位。
关键词:模型;频率;线性预测编码
语音由一连串的音所组成,这些音及其相互间的过渡就是代表信息的符号。这些符号的排列由语音的规则所控制。对这些规则及其在人类通信中的含义的研究属于语言学的范畴。但对语音信号加以处理以改善或提取信息时,有必要对语音产生的机理进行讨论。
图1为发音器官示意图。声道起始于声带的开口(即声门处)而终止于嘴唇,它包含了咽喉(连接食道和口)和口(或称为口腔)。声道的截面积取决于舌、唇、颌以及小舌的位置,它可以从0 (完全闭合)变化到约20 cm2,鼻道则从小舌开始到鼻孔为止。当小舌下垂时,鼻道与声道发生声耦合而产生语音中的鼻音。另外,图中还包含了由肺、支气管、气管组成的次声门系统,这个次声门系统是产生语音能量的源泉。当空气从肺里呼出时,呼出的气流由于声道某一地方的收缩而受到扰动,语音就是这一系统在此时辐射出来的声波。

语音的声音按其激励形式的不同可分为三类:浊音、摩擦音和爆破音。浊音:当气流通过声门时,如果声带的张力刚好使声带发生张弛振荡式的振动,就能产生准周期的空气脉冲,这一空气脉冲激励声道得到浊音,如音标中的“U”、“d”、“w”、“i”、“e”等为浊音。摩擦音或称为清音:如果声道在某处(一般在接近嘴的那端)发生收缩,同时迫使空气以高速冲过这一收缩部分而产生湍流,从而得到摩擦音,此时建立的宽带噪声源激励了声道,如音标中的“∫”就是摩擦音;爆破音:如果使声道前部完全闭合,在闭合后建立起气压,然后突然释放,这样就得到了爆破音,如音标中的“t∫”就是爆破激励产生的。
1 语音信号的特征和语谱图
图1中声道和鼻道都表示为非均匀截面的声管,当声音产生以后就顺着声管传播,它的频谱形状会被声管的选择性所改变。这类似于人们在管风琴或管乐器中所看到的谐振现象。在此将声道管的谐振频率称为共振峰频率。共振峰频率和声道的形状与大小有关,每种形状都有一套共振峰频率作为其特征。改变声道的形状就产生不同的声音,因此,当声道形状改变时,语音信号的谱特性也随之改变。
语谱图是通过语谱仪画出的、以显示语音信号的通用图。它的垂直方向表示频率,水平方向表示时间。图2表示了一段英语语句的语音信号。

获得这些图的原理大致如下:
首先把语音信号拆成短的时段,一般为2 ms~40 ms,然后在合适的窗口长度上使用FFT找每一短时段的频谱。图中每一点表示在给定时间和给定频率范围内频谱的能量。段的长度是根据频率分辨率和时间分辨率要求折中选择的。目前数字信号处理技术水平已能够实时处理语音频谱随时间的变化,这就意味着, FFT和显示处理能够在下一段数据捕获前完成。例如,采样频率为8 kHz(由采样定理知,信号带宽的上限为4 kHz),一段长度内有256个采样点,FFT和显示处理时间必须小于32 ms。
从英文字“rain”中字母a的实例表明:语音信号有周期的时域波形,如图2(a)所示;它的频谱类似于一串有间隔的谐波,如图2(b)所示。同样,字“storm”中的字母s的实例表明:摩擦音时域信号为噪声,如图2(c)所示,它的频谱如图2(d)所示。这个频谱证明对声音的2个主要源都存在共振峰频率的影响。
在图3中,图的下半部分是相应的语谱图,语音能量由颜色的深浅来表示,颜色越深,语音能量越强。

由图3可知,语音样例“他去无锡市,我到黑龙江”的每一个汉字的发音对应一组频谱,有其基音和谐波。基音和谐波的宽度不等说明有共振峰频率的影响。从短时稳定的频谱存在说明语音信号存在短期相关性,即尽管模拟声道的数字滤波器参数是随时间改变的,但是在很短的时间(如几毫秒)内,由于存在确定的周期性频谱,因而可以认为,在该段时间内,数字滤波器参数不随时间而变化。可以使用线性预测方法,即一个语音采样值能够由前面若干个采样值的组合逼近,故称为线性预测。因此,每一个汉字语音对应一组线性预测系数,也就是对应一组确定的声道数字滤波器系数。
2 语音信号的产生模型
根据上面的分析,可以用近期所有语音合成和识别技术采用的人类语音模型来模拟语音信号的产生,如图4所示。

用随机噪声发生器产生噪声源模拟摩擦音(汉语称清音),利用音调或称基音周期控制脉冲串产生器模拟元音(汉语称浊音)。用增益函数表示声音振幅。模拟声道的数字滤波器是一个线性时变滤波器。
3 线性预测编码(LPC)
线性预测编码LPC( Line Predictive Coding )方法在语音信号产生模型应用中是至关重要的,下面给出它的物理概念和方法。采样后的语音是离散信号,可以利用Z变换进行分析计算。设声道滤波器为一个全极点滤波器,其传递函数为V(z),则输出信号为:
S(z)=E(z)×V(z)=G×E(z)/A(z) (1)
式中,E(z)为声道滤波器的激励e(n)的Z变换;A(z)为声道滤波器的逆滤波器,是全零点滤波器;G为增益函数,表示声音振幅的一个参数;S(z)为合成的语音。在已知激励和滤波器参数后,可得到合成语音,故(1)式称为合成模型。由(1)式可得:
E(z)=S(z)×A(z) (2)
(2)式为(1)式的逆运算,故称为语音分析模型。
若逆滤波器为A(z),输入语音信号为S(z),则输出即为激励信号E(z)。然而,A(z)是未知的,需要使用线性预测的方法求得。
因为A(z)是全零点滤波器,其结构如图5所示。通过证明可得:

即A(z)是由M节滤波器组成,式中i是滤波器的阶数,ai是逆滤波器的系数,有待确定。把(3)式代入(2)式,并将Z变换的式子转换为离散值来写,则有:

(4)式说明对样本序列值S(n),n时刻序列值由它前面M个样本线性预测得到。即:

同时表示,激励信号e(n)是语音信号S(n)与预测信号 之差,称为预测误差。(5)式可写为Z变换形式:
之差,称为预测误差。(5)式可写为Z变换形式:

式中,F(z)为预测滤波器值,若输入A(z),输出即为预测值,见图5。

可见,这里存在2个滤波器,1个是预测滤波器F(z),可用来求预测值;另一个为逆滤波器,它等于1-F(z),可用来从激励信号求出重建的语音信号。使用这2个滤波器关键是求系数ai。利用公式(4),预测误差e(n)越小,预测值越接近信号值S(n)。可采用e(n)的最小均方误差准则来确定ai的系数。若S(n)已知,在短时间范围内(如20 ms),在8 kHz采样频率下就有160个S(n)样本点,利用它来训练预测滤波器A(z),系数ai就可以确定。系数ai是时变的,但在短的时限内是不变的。因此,在线性预测算法中,系数ai的计算每帧都要进行1次,当前帧系数ai计算值作为下一次计算时用。
4 语音产生模型的应用
语音产生模型说明一个短时的语音信号可以用3个参数来定义:(1)从周期性波和随机噪声中选择1个作为激发态;(2)如果使用周期性波,必须选择1个频率作为基音;(3)模拟声道响应所使用的数字滤波器系数。
4.1 语音产生模型在语音合成技术中的应用
早期产品中应用到的连续语音合成技术,是借助于大约以每秒40次速度修改上述的短时语音信号的3个参数来实现的。如适合儿童学习的“说和拼音机”。由于它仅仅采用26个英文字母作为音库,因而这种语音合成的声音质量不高,声音非常机械。
此后,用汉字语音作为库,用波形拼接方法进行语音合成,效果有所改进,但是库的存储量太大。解决的方案是,使用语音分析方法,即利用语音产生模型概念,把一个语音信号分解成下列特性参数:线性预测系数(取10个)、基音周期范围、基音周期数目(基音持续时间)和清音存在时间等。根据ITU-T G.729语音编码方法,一帧语音信号特征参数仅需80 bit,即80个16 bit样本压缩为80 bit,缩小16倍。到合成需要该音时,再利用语音产生模型由所存的特征参数实时转换为语音。
4.2 语音产生模型在语音识别技术中的应用
与机器进行语音交流,让机器明白你说什么,这是人们长期以来梦寐以求的事情。语音识别技术就是让机器通过识别和理解过程把语音信号转变为相应的文本或命令的技术。其原理是:由于每一个短时语音信号包含一串语音特性参数,不同的汉字音有不同的特征参数,所以利用特征参数的差别来识别不同的汉字音。
近20年来,语音识别技术取得显著进步,开始从实验室走向市场。预计未来10年内,语音识别技术将进入工业、家电、通信、汽车电子、医疗、家庭服务、消费电子产品等各个领域。
参考文献
[1] 拉宾纳 L R,谢弗 R W. 语音信号数字处理[M]. 北京:科学出版社,1983.
[2] 戴逸民,梁晓雯,裴小平. 基于DSP的现代电子系统设计[M]. 北京:电子工业出版社,2002.
[3] 奥本海姆. 信号与系统[M]. 刘树棠,译 . 西安:西安交通大学出版社,1998.
[4] 何苏勤,王忠勇.TMS320C2000系列DSP原理及应用技术[M].北京:电子工业出版社,2003.
http://www.innovateasia.com/cn/win_2008/CN321.htm
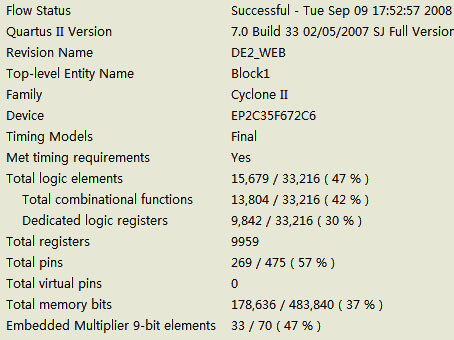
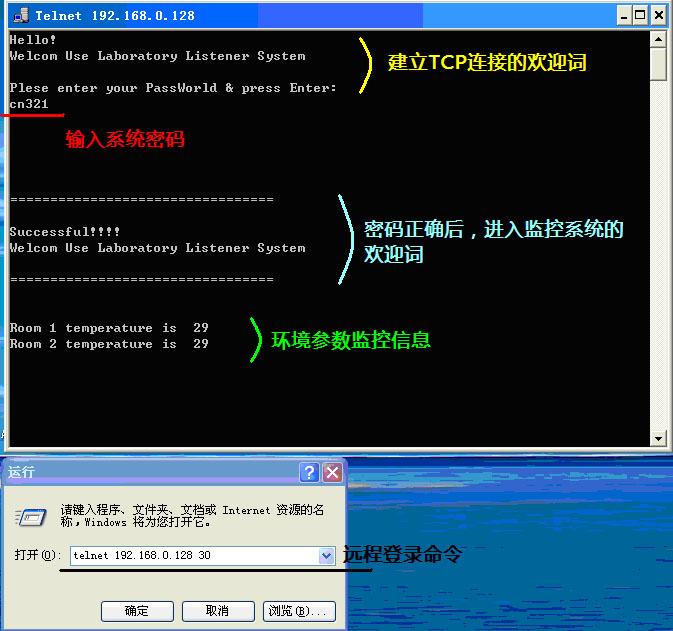
Profile – CN321 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
CN321基于语音识别及RFID的多重安防门禁监控系统 广西师范大学 | Advisor
Members
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Project Paper1. 设计概述 (Preliminary Paper)
2. 功能描述 (Final Project Paper)
3. 性能参数 (Final Project Paper)
4. 设计结构 (Preliminary Paper)
5. 设计方法 (Final Project Paper)
6. 设计特点 (Preliminary Paper)
7. 总结 (Final Project Paper)
|







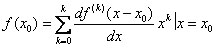
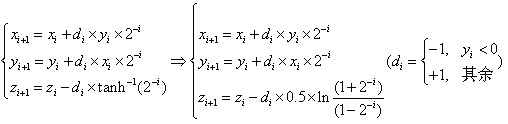
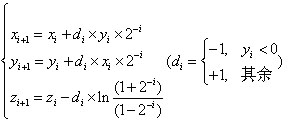




发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/153137.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
