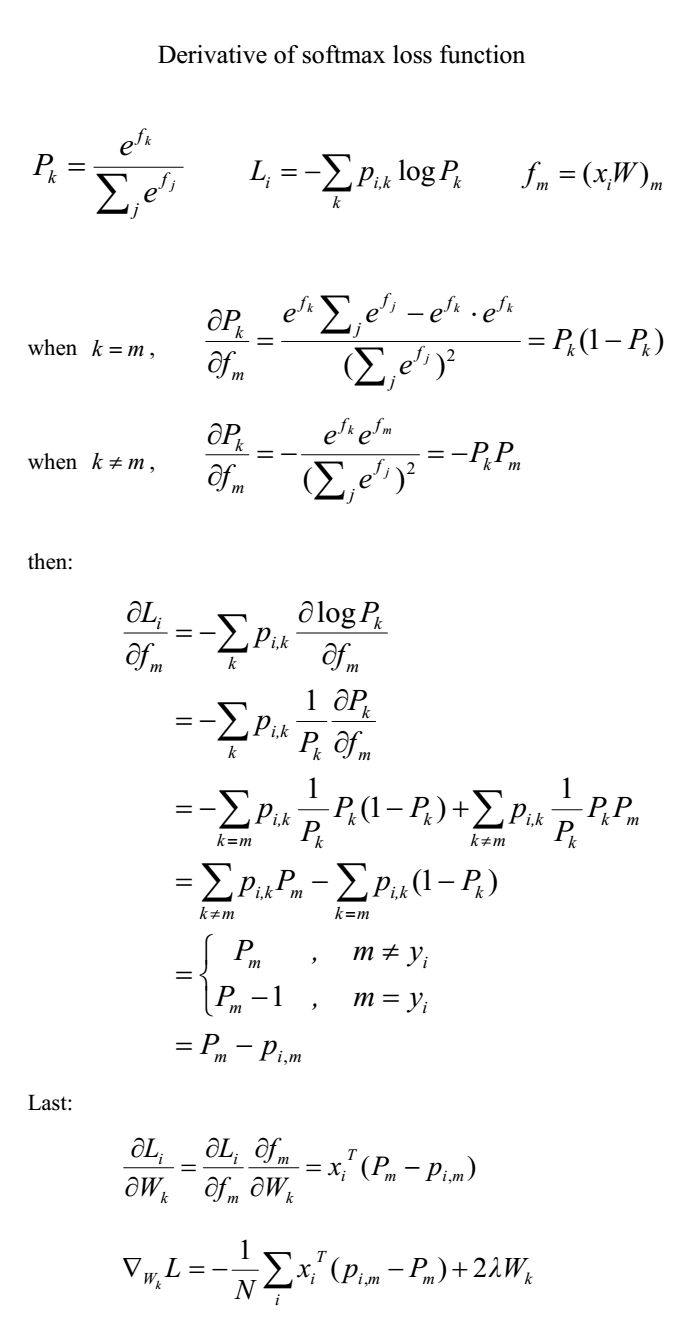设置以下变量: – 矩阵 W 代表权值,维度是 D∗C,其中 D 代表特征的维度,C 代表类别数目。 – 矩阵 X 代表样本集合,维度是 N∗D, 其中 N 代表样本个数。 – 分值计算公式为 f=X∗W,其维度为 N∗C, 每行代表一个样本的不同类别的分值。
对于第 i 个样本的损失函数计算如下:
Li=∑j≠yimax(0,WT:,jxi,:−WT:,yixi,:+Δ)
偏导数计算如下:
∂Li∂W:,yi=−(∑j≠yi1(wT:,jxi,:−wT:,yixi,:+Δ>0))xi,:
∂Li∂W:,j=1(wT:,jxi,:−wT:,yixi,:+Δ>0)xi,:
其中: – w:,j 代表W矩阵第 j 列,其维度为 D。 – xi,: 代表X矩阵的第 i 行,表示样本 i 的特征,其维度也为 D 。 二者相乘,得出的是样本 i 在第 j 个类别上的得分。 – 1 代表示性函数。
3. python实现
包括向量化版本和非向量化版本:
defsvm_loss_naive(W, X, y, reg):""" # SVM 损失函数 native版本 Inputs have dimension D, there are C classes, and we operate on minibatches of N examples. Inputs: - W: A numpy array of shape (D, C) containing weights. - X: A numpy array of shape (N, D) containing a minibatch of data. - y: A numpy array of shape (N,) containing training labels; y[i] = c means that X[i] has label c, where 0 <= c < C. - reg: (float) regularization strength Returns a tuple of: - loss as single float - gradient with respect to weights W; an array of same shape as W """
dW = np.zeros(W.shape) # initialize the gradient as zero# compute the loss and the gradient
num_classes = W.shape[1]
num_train = X.shape[0]
loss = 0.0# 对于每一个样本,累加lossfor i in xrange(num_train):
scores = X[i].dot(W) # (1, C)
correct_class_score = scores[y[i]]
for j in xrange(num_classes):
if j == y[i]:
continue# 根据 SVM 损失函数计算
margin = scores[j] - correct_class_score + 1# note delta = 1# 当 margin>0 时,才会有损失,此时也会有梯度的累加if margin > 0: # max(0, yi - yc + 1)
loss += margin
# 根据公式:∇Wyi Li = - xiT(∑j≠yi1(xiWj - xiWyi +1>0)) + 2λWyi
dW[:, y[i]] += -X[i, :] # y[i] 是正确的类# 根据公式: ∇Wj Li = xiT 1(xiWj - xiWyi +1>0) + 2λWj ,
dW[:, j] += X[i, :]
# 训练数据平均损失
loss /= num_train
dW /= num_train
# 正则损失
loss += 0.5 * reg * np.sum(W * W)
dW += reg * W
#return loss, dW
#defsvm_loss_vectorized(W, X, y, reg):""" SVM 损失函数 向量化版本 Structured SVM loss function, vectorized implementation.Inputs and outputs are the same as svm_loss_naive. """
loss = 0.0
dW = np.zeros(W.shape) # initialize the gradient as zero
scores = X.dot(W) # N by C 样本数*类别数
num_train = X.shape[0]
num_classes = W.shape[1]
scores_correct = scores[np.arange(num_train), y]
scores_correct = np.reshape(scores_correct, (num_train, 1)) # N*1 每个样本的正确类别
margins = scores - scores_correct + 1.0# N by C 计算scores矩阵中每一处的损失
margins[np.arange(num_train), y] = 0.0# 每个样本的正确类别损失置0
margins[margins <= 0] = 0.0# max(0, x)
loss += np.sum(margins) / num_train # 累加所有损失,取平均
loss += 0.5 * reg * np.sum(W * W) # 正则# compute the gradient
margins[margins > 0] = 1.0# max(0, x) 大于0的梯度计为1
row_sum = np.sum(margins, axis=1) # N*1 每个样本累加
margins[np.arange(num_train), y] = -row_sum # 类正确的位置 = -梯度累加
dW += np.dot(X.T, margins)/num_train + reg * W # D by Creturn loss, dW
defsoftmax_loss_naive(W, X, y, reg):""" Softmax loss function, naive implementation (with loops) Inputs have dimension D, there are C classes, and we operate on minibatches of N examples. Inputs: - W: A numpy array of shape (D, C) containing weights. - X: A numpy array of shape (N, D) containing a minibatch of data. - y: A numpy array of shape (N,) containing training labels; y[i] = c means that X[i] has label c, where 0 <= c < C. - reg: (float) regularization strength Returns a tuple of: - loss as single float - gradient with respect to weights W; an array of same shape as W """# Initialize the loss and gradient to zero.
loss = 0.0
dW = np.zeros_like(W)
dW_each = np.zeros_like(W)
#
num_train, dim = X.shape
num_class = W.shape[1]
f = X.dot(W) # 样本数*类别数 分值#
f_max = np.reshape(np.max(f, axis=1), (num_train, 1))
# 计算对数概率 prob.shape=N*10 每一行与一个样本相对应 每一行的概率和为1# 其中 f_max 是每行的最大值,exp(x)中x的值过大而出现数值不稳定问题
prob = np.exp(f - f_max) / np.sum(np.exp(f - f_max), axis=1, keepdims=True)
#
y_trueClass = np.zeros_like(prob)
y_trueClass[np.arange(num_train), y] = 1.0# 每行只有正确的类别处为1,其余为0#for i in range(num_train):
for j in range(num_class):
loss += -(y_trueClass[i, j] * np.log(prob[i, j]))
dW_each[:, j] = -(y_trueClass[i, j] - prob[i, j]) * X[i, :]
dW += dW_each
loss /= num_train
loss += 0.5 * reg * np.sum(W * W)
dW /= num_train
dW += reg * W
return loss, dW
defsoftmax_loss_vectorized(W, X, y, reg):""" Softmax loss function, vectorized version. Inputs and outputs are the same as softmax_loss_naive. """
loss = 0.0
dW = np.zeros_like(W) # D by C
num_train, dim = X.shape
f = X.dot(W) # N by C# Considering the Numeric Stability
f_max = np.reshape(np.max(f, axis=1), (num_train, 1)) # N by 1
prob = np.exp(f - f_max) / np.sum(np.exp(f - f_max), axis=1, keepdims=True)
y_trueClass = np.zeros_like(prob)
y_trueClass[range(num_train), y] = 1.0# N by C# 计算损失 y_trueClass是N*C维度 np.log(prob)也是N*C的维度
loss += -np.sum(y_trueClass * np.log(prob)) / num_train + 0.5 * reg * np.sum(W * W)
# 计算损失 X.T = (D*N) y_truclass-prob = (N*C)
dW += -np.dot(X.T, y_trueClass - prob) / num_train + reg * W
return loss, dW
information leakage._information interviewhttps://www.owasp.org/index.php/Information_LeakageExamplesExample1Thefollowingcodeprintsthepathenvironmentvariabletothestandarderrorstream: char*path=getenv(“PATH”); …