大家好,又见面了,我是你们的朋友全栈君。
作者:Barranzi_


注:本文所有代码、案例测试环境:1.Linux – 系统版本:Ubuntu20.04 LTS 2.windows – 系统版本:WIN10 64位家庭版
-
所需第三方库安装
-
pillow
pip install pillow -i https://pypi.douban.com/simple -
mysqlclient
pip install mysqlclient -i https://pypi.douban.com/simple
-
-
新建scrapy项目
-
创建项目:
scrapy startproject demo01_jobbole -
新建爬虫:
cd demo01_jobbole scrapy genspider jobbole http://news.cnblogs.com/
-
-
项目初始配置及准备工作
-
项目文件同级目录下新建main.py,用于run整个爬虫项目
-
main.py内编写如下代码:
main.py # -*- coding:utf-8 _*- """ @version: author:weichao_an @time: 2021/01/29 @file: main.py @environment:virtualenv @email:awc19930818@outlook.com @github:https://github.com/La0bALanG @requirement: """ import sys import os from scrapy.cmdline import execute #将当前文件添加到系统路径 sys.path.append(os.path.dirname(os.path.abspath(__file__))) #脚本方式一键运行scrapy项目 execute(['scrapy','crawl','jobbole']) -
settings.py内进行初始配置:将是否遵循robots协议更改为false,以防止爬虫获取数据不完整:
settings.py # Obey robots.txt rules ROBOTSTXT_OBEY = False -
项目文件内新建images文件夹,用于保存获取的图片;
-
settings.py中配置图片下载路径:
settings.py IMAGES_URLS_FIELD = 'front_image_url' projects_dir = os.path.dirname(os.path.abspath(__file__)) IMAGES_STORE = os.path.join(projects_dir,'images') -
新建数据库:article_spider(可以先预想好数据库名称,待后续items中定义完毕数据结构之后,再进行具体的建库操作,这一步,是为了先方便在settings.py中配置数据库的基本信息,方便最后的入库)
settings.py MYSQL_HOST = '127.0.0.1' MYSQL_DBNAME = 'article_spider' MYSQL_USER = 'root' MYSQL_PASSWORD = '******'#写你自己本机数据库的密码就行了
-
-
页面结构分析及所需数据结构简单分析
这次我们要爬的是博客园的新闻内容详情页,url地址:http://news.cnblogs.com/
我们先访问一下,打开对应的新闻首页:
看到首页的内容后,我们先简单看下页面的结构:
- 新闻首页看上去是以“列表”的形式先呈现每一篇新闻的概要描述;
- 其中的新闻标题可以点击,点击后直接跳转至新闻详情页面;
以及看下后续几页的内容及其分页规律:

- 新闻页面通过分页技术展示概要详情;
- 每一页之间的url应该是存在规律的(预先猜想,毕竟还没有实质调试页面及URL规律)
随便选一个新闻我们点进去看一下:

这次我们想要的数据,就存在于每一个具体新闻页面内部。
那么我们到底需要什么数据呢?我们需要每一个新闻内容的如下数据:
- 新闻的标题
- 新闻的发布时间
- 该条新闻对应的详情页的请求路径(因为只有获得了请求路径我们才可能请求到每一个新闻的详情页面)
- 详情页图片的下载连接
- 详情页图片的保存路径
- 该篇新闻的评论数
- 该篇新闻的阅读数
- 该篇新闻的推荐数
- 该篇新闻的标签
- 该篇新闻的内容主体
先简单分析到这,毕竟这只是个简单的爬虫项目,我们确实没什么必要提前把数据模型设计做的非常到位,我们可以先明确主体数据结构,待后续分析页面及代码实现的过程中,如果还需要再新增何种数据,灵活再添加即可。
现在,我们先定义好items:
items.py # Define here the models for your scraped items # # See documentation in: # https://docs.scrapy.org/en/latest/topics/items.html import scrapy class Demo01JobboleItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() pass #不使用提供的模板,我们自己定义一个item,只需要像模板一样让自己的item类也继承scrapy.Item即可 class JobBoleArticleItem(scrapy.Item): ''' 定义数据结构,对应到数据库中也就是所需字段 ''' #新闻标题 title = scrapy.Field() #新闻发布时间:因为要入库,预想到,很大可能是时间日期格式数据 create_date = scrapy.Field() #每一个新闻详情页的请求URL url = scrapy.Field() #待定:后续讲解该字段的含义 url_object_id = scrapy.Field() #详情页包含的图片下载URL front_image_url = scrapy.Field() #图片保存路径 front_image_path = scrapy.Field() #点赞/推荐数量 praise_nums = scrapy.Field() #评论数量 comment_nums = scrapy.Field() #新闻阅读数量 fav_nums = scrapy.Field() #新闻所属标签:预想到标签可能不止一个 tags = scrapy.Field() #新闻页面的主体内容 content = scrapy.Field()欧克,明确需求之后,接下来我们就开始详细的分析页面结构及URL规律。
-
详细分析页面结构及URL规律
第一步,我们先分析每个新闻列表页的URL规律。
F12打开控制台,随意切换几页,观察URL规律如下:
第一页:https://news.cnblogs.com/[n/page/1/] 第二页:https://news.cnblogs.com/n/page/2/ 第三页:https://news.cnblogs.com/n/page/3/ 第四页:https://news.cnblogs.com/n/page/4/ ... 第n页:https://news.cnblogs.com/n/page/n/看上去规律挺简单的,使用自增1的数字表示第几页,所以看上去我们可以通过循环来模拟页数的变化,但是,这样做其实有一个局限:
如果我们想进行全站爬取呢?
什么意思,也就是:
不管新闻列表页最大页数能达到多少,有几页数据,我就爬几页
(通过上一步简单分析我们已经看出,博客园只把新闻列表页展示前100页的内容,但其实我们都知道,博客园运营了好几年,所发布的新闻也绝不止100页的内容吧?)
那么如果是为了满足全站爬取的需求,那么我们的循环模拟页数,到底要循环至多大的数字呢?我们也不可能写一个死循环吧?所以,这种方式其实并不可取。
那么,到底该如何能够实现不断的获取下一页的URL呢?
我们留意一下页数:
我们发现,其实每一页想要跳转到下一页,我不仅可以选择手动去选择查看第几页,一个更好的方式是我们可以直接点击这个next,就自动跳转到下一页了。
那也就是说,下一页的URL,一定是包含在next这个富文本内的。
所以,我们可以先捋一下思路:
-
我们先想办法获取第一页的数据;
-
然后我们只要能解析到这个next内部的下一页的URL,不就ok了么?
-
每一页我们都解析出下一页的URL,然后让解析函数递归执行,下一页的新闻列表内容,不也就解析出来了么?
-
那如何才能获取到下一页新闻列表的URL呢?我们只需要从当前新闻列表页解析出来就可以了啊?
至此,爬虫的第一步思路就出来了:
- 先请求第一页新闻列表页;
- 获取该列表页中每一条新闻的详情页面的URL(毕竟这才是我们获取所需数据的前提)交给scrapy进行下载并调用相应的解析方法
- 获取下一页的URL交给scrapy进行下载,下载完毕下一页后调用当前解析函数继续执行(递归调用,也就是再一次执行解析第二页新闻列表页)
至此,有关每一页新闻列表的URL解析我们就分析完了。
继续,接下来分析新闻列表页的数据。
F12打开控制台,我们使用抓手工具抓到任意一个新闻概要区域,如下图:

从上图及相关的标示中我们能够看出:
- 每一个新闻概要内容,其实都对应一个class为news_block的div;
- 而这么多个新闻概要内容其实都在一个大的,id为news_list的div内部;
但是此时,我们需要注意:控制台elements选项中展示出来的页面结构,是经过服务器响应及浏览器渲染结束之后的页面,这里存在的数据,并不代表在我们的具体请求的响应体中也存在,所以,为了证明我们在这看到的数据是否真实存在,我们需要查看一下当前页面的源代码,或切换至页面请求的response区域验证一下。
我们现在右键 ,点击查看网页源代码,我们随便检索一下这个news_block,看看所需数据是否真实存在:
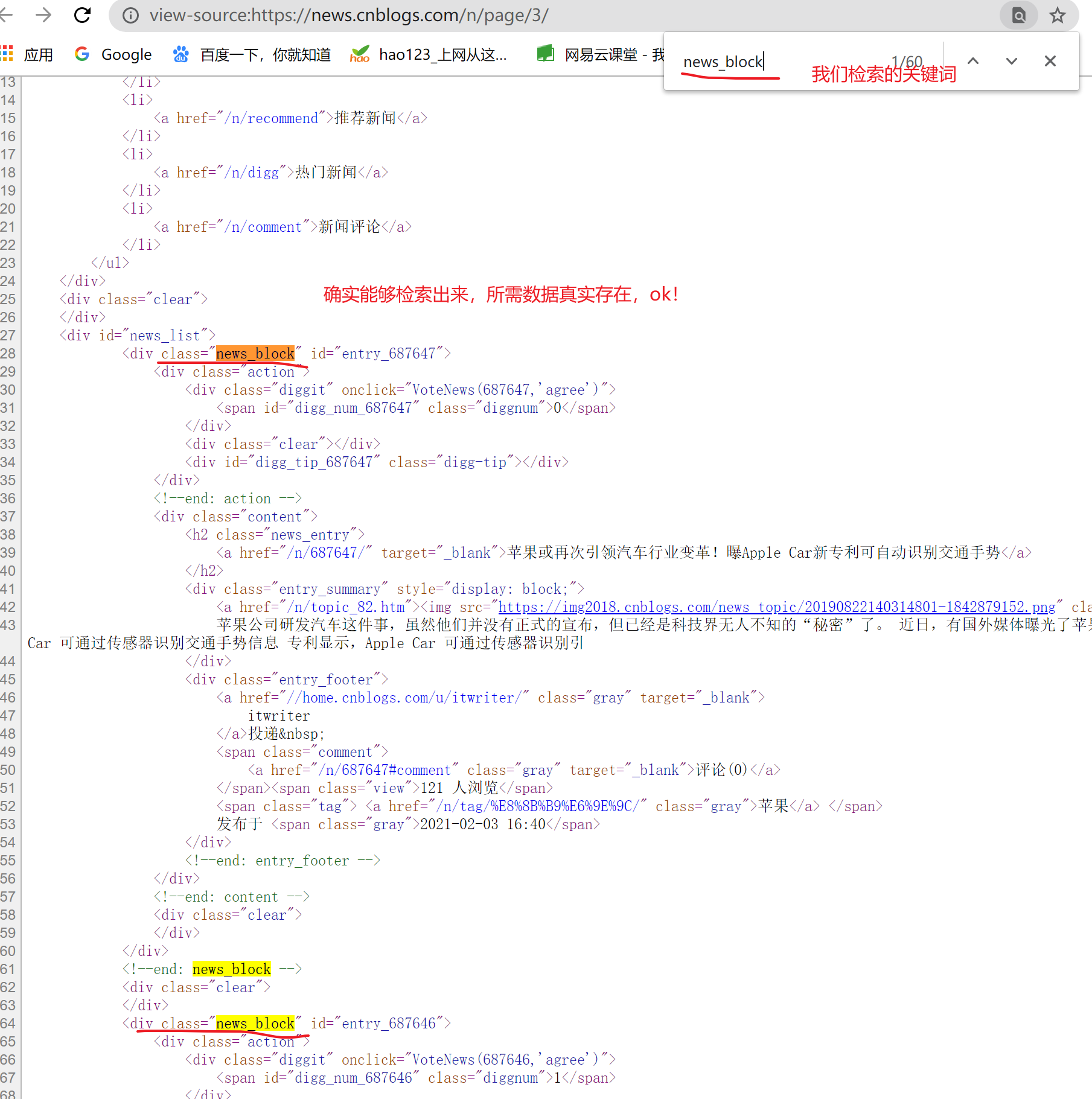
欧克,经过验证,确实真实存在于源码中(也就是真实存在于页面的response);
根据上述的分析,我们发现,其实每个news_block是news_list的子节点,所以我们可以先获取news_list节点,而后通过遍历该节点,就可以拿到每一个新闻概要的内容了。
先分析到这,我们现在开始写代码。
-
-
伴随页面的详细分析开始编码
进入爬虫文件jobbole.py,我们所有的数据解析全部都在爬虫文件内实现。
打开文件,我们发现scrapy已经为我们初始化好了基本的代码结构:
class JobboleSpider(scrapy.Spider): name = 'jobbole' allowed_domains = ['news.cnblogs.com'] #初始URL已经自动生成,parse方法即从初始URL开始访问 start_urls = ['http://news.cnblogs.com/'] def parse(self, response): pass接下来,我们开始在parse内部编写爬虫逻辑。
首先,我们先明确需求:
def parse(self, response): ''' 功能实现: 1.获取新闻列表页中的新闻url交给scrapy进行下载后调用相应的解析方法 2.获取下一页的url交给scrapy进行下载,下载完成后交给parse继续跟进 '''这里scrapy给我们默认注入好的response,即为自动请求页面URL之后页面的响应数据,接下来我们就根据页面的response开始解析数据。
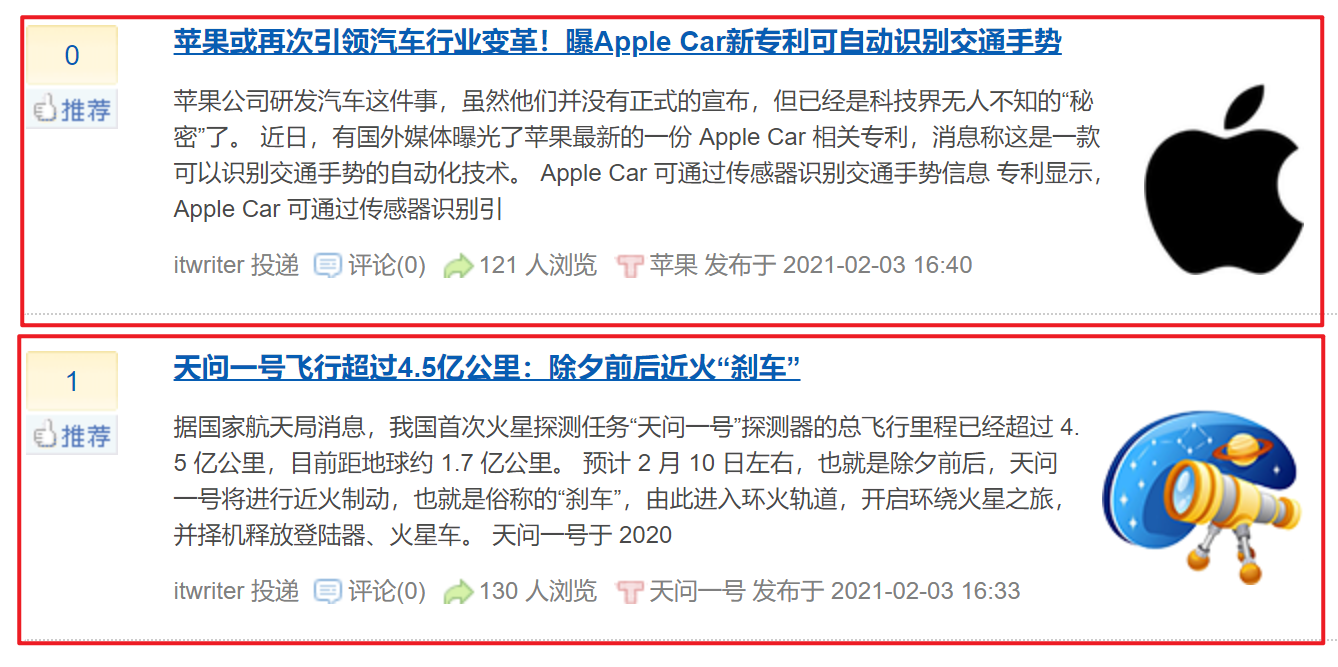
首先,我们先获取到news_list节点:
post_nodes = response.css('#news_list .news_block')此时post_nodes拿到的就是news_list下的若干个news_block,也就是当前新闻列表页下的每一个新闻的概要内容,如下图:
拿到这每一个新闻的概要内容之后,我们先通过控制台看看,我们需要从中解析出哪些我们需要的数据:
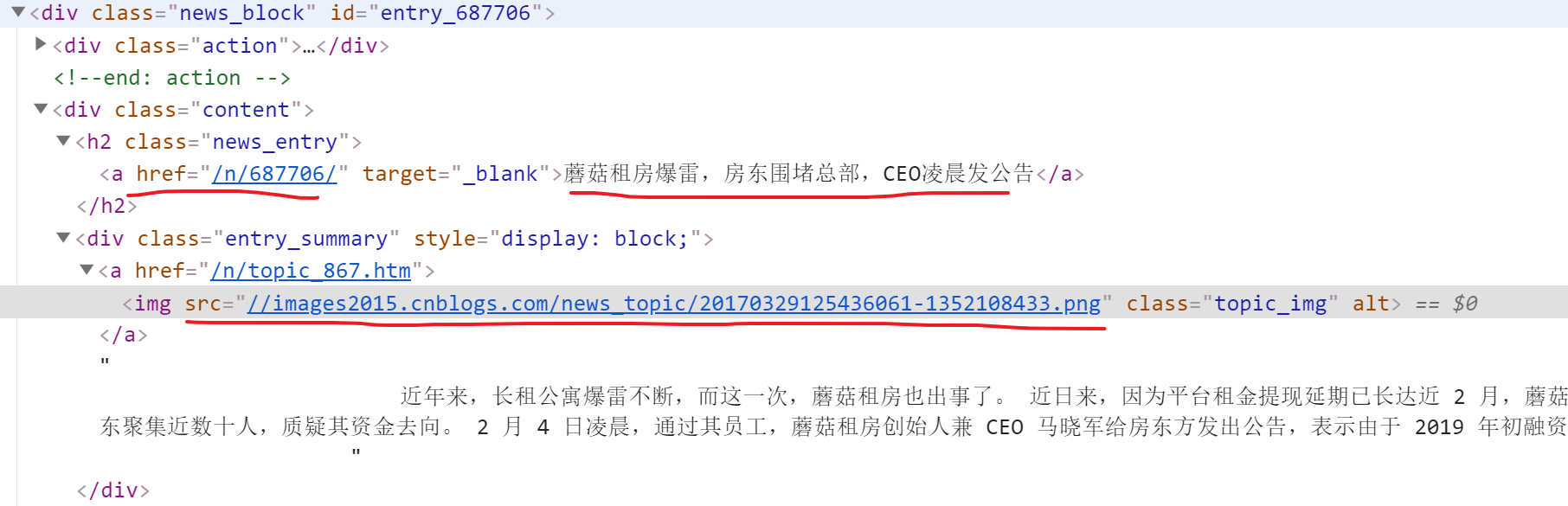
我们需要两个数据:
- 该新闻的详情页的URL,在h2内部的a标签的href中;
- 该新闻的图片URL,在class为entry_summary的div内部的img标签的src属性中;
接下来,我们遍历节点,针对每一个新闻概要内容,解析该两部分数据:
for post_node in post_nodes: #图片的URL image_url = post_node.css('.entry_summary a img::attr(src)').extract_first('') if image_url.startswith('//'): image_url = 'https:' + image_url #新闻详情页的URL post_url = post_node.css('h2 a::attr(href)').extract_first('')但是在解析的过程中我们发现了如下隐藏的问题:
有的时候,我们解析出来的图片URL是这样的:

而有的图片,解析出来的URL却是这样的:

也就是:
- 解析得到的图片URL,有的完整,有的不完整,缺失“https:”
为了规避该细节造成的后期run程序时的异常报错,我们做一个细节性处理,看上述代码逻辑,即:
- 如果获取的URL开头是“//”,则手动为其拼接上“https:”
继续。解析出来得到的新闻详情页的URL,其实也有问题:
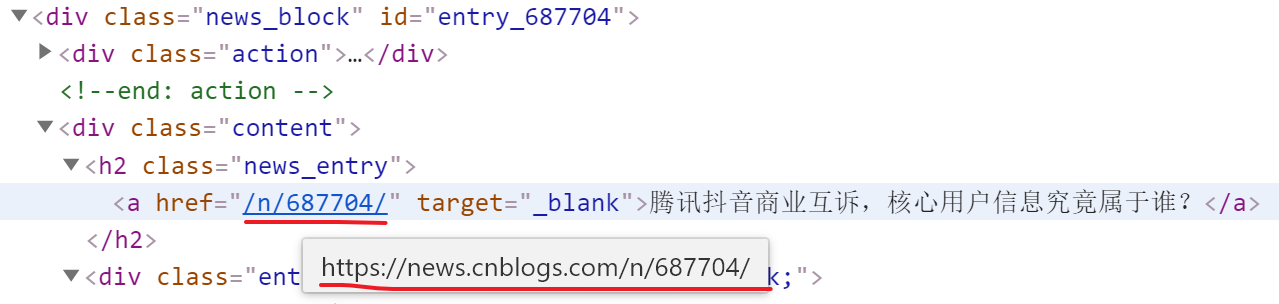
- 我们得到的href的内容,只是详情页URL的路径部分,但前面的协议和主机地址内容却没有;
所以,这个post_url我们还是得手动拼接上协议和主机地址,详情页的URL才算完整。
如何拼接呢?直接使用format拼接?
不行。
为什么?吸取刚才图片URL的教训,虽然这里大部分我们看到的详情页的URL是不完整的,直接拼接肯定没问题,但你真保不齐哪个URL是完整的,对吗?那如果已经完整了,再去拼接主机地址,那得到的URL肯定就是错误的了。所以,为了灵活拼接,我们借助urllib库下的parse方法:
url=parse.urljoin(response.url,post_url)ok,详情页的URL拼接完整之后,我们将URL交给scrapy进行下载,并为其设置回调函数进行页面解析:
yield Request(url=parse.urljoin(response.url,post_url),meta={ 'front_image_url':image_url},callback=self.parse_detail)至于yield语句内的meta参数:这里参数传递的是图片的URL,这个图片即存在于列表内的新闻概述中,其实也存在于新闻详情页中,所以在这里其实我们不着急先去下载图片,我们可以把它放在详情页解析中去下载,所以暂时先把它传递到详情页解析的回调函数parse_detail中即可。
至此,parse方法的第一个功能完成了:
- 获取新闻列表页中的新闻url交给scrapy进行下载后调用相应的解析方法
现在来完成第二个方法。
我们还是找到next:

可以发现,next所处的a标签有很多,且都在class为pager的div内部;
现在这个next确实找到了,可是我们看看它有什么问题。我们现在进入第100页:

我们会发现,第100页,就没这个next了,那既然是这样的情况,我可以通过:
- 抓取class为pager的div下的最后一个a标签
这种方式来获取这个next吗?显然就不行了,因为第100页是个例外,最后一个a不是next。
那怎么获取呢?
只好通过精准匹配咯,即:
- 先获取class为pager的div下的最后一个a标签的文本;
- 如果这个文本内容为“Next >”,则获取这个a标签的href属性值
这样,我们就能确保精准拿到下一页新闻列表页的URL了:
next_url = response.css('div.pager a:last-child::text').extract_first('') if next_url == 'Next >': next_url = response.css('div.pager a:last-child::attr(href)').extract_first('')还是一样的问题,这里拿到的next的URL仍然是不完整的,也需要先拼接成完整的URL:
url=parse.urljoin(response.url,post_url)此时,拼接完毕下一页的URL之后,交给scrapy进行下载,下载完毕后交给parse继续解析下一页新闻列表:
yield Request(url=parse.urljoin(response.url,post_url),meta={ 'front_image_url':image_url},callback=self.parse_detail)至此,新闻列表页的解析,就全部完成了,我先把parse方法的所有代码先展示一下,方便大家直接使用:
def parse(self, response): ''' 功能实现: 1.获取新闻列表页中的新闻url交给scrapy进行下载后调用相应的解析方法 2.获取下一页的url交给scrapy进行下载,下载完成后交给parse继续跟进 ''' # urls = response.css('div#news_list h2 a::attr(href)').extract() post_nodes = response.css('#news_list .news_block') for post_node in post_nodes: image_url = post_node.css('.entry_summary a img::attr(src)').extract_first('') if image_url.startswith('//'): image_url = 'https:' + image_url post_url = post_node.css('h2 a::attr(href)').extract_first('') yield Request(url=parse.urljoin(response.url,post_url),meta={ 'front_image_url':image_url},callback=self.parse_detail) #提取下一页交给scrapy进行下载 next_url = response.css('div.pager a:last-child::text').extract_first('') # next_url = response.xpath('a[contains(text(),"Next >")]/@href').extract_first('') # yield Request(url=parse.urljoin(response.url, next_url), callback=self.parse) if next_url == 'Next >': next_url = response.css('div.pager a:last-child::attr(href)').extract_first('') yield Request(url=parse.urljoin(response.url, next_url),callback=self.parse) -
详情页数据解析及写入items
还是先回看下parse方法。
在parse方法中,我们两次yield出数据:
- 第二次的yield不用管了,因为第二次是将解析得到的下一页新闻列表的URL提交给scrapy下载并再次执行列表页解析;
- 第一次,我们将详情页URL提交给了scrapy进行下载,并调用parse_detail方法进行解析;
这个方法还没有,所以我们先定义好:
def parse_detail(self,response):#定义时一定要默认注入好response pass接下来,我们就开始在parse_detail方法中,开始解析我们所需要的数据。
我们先看下详情页的页面结构:
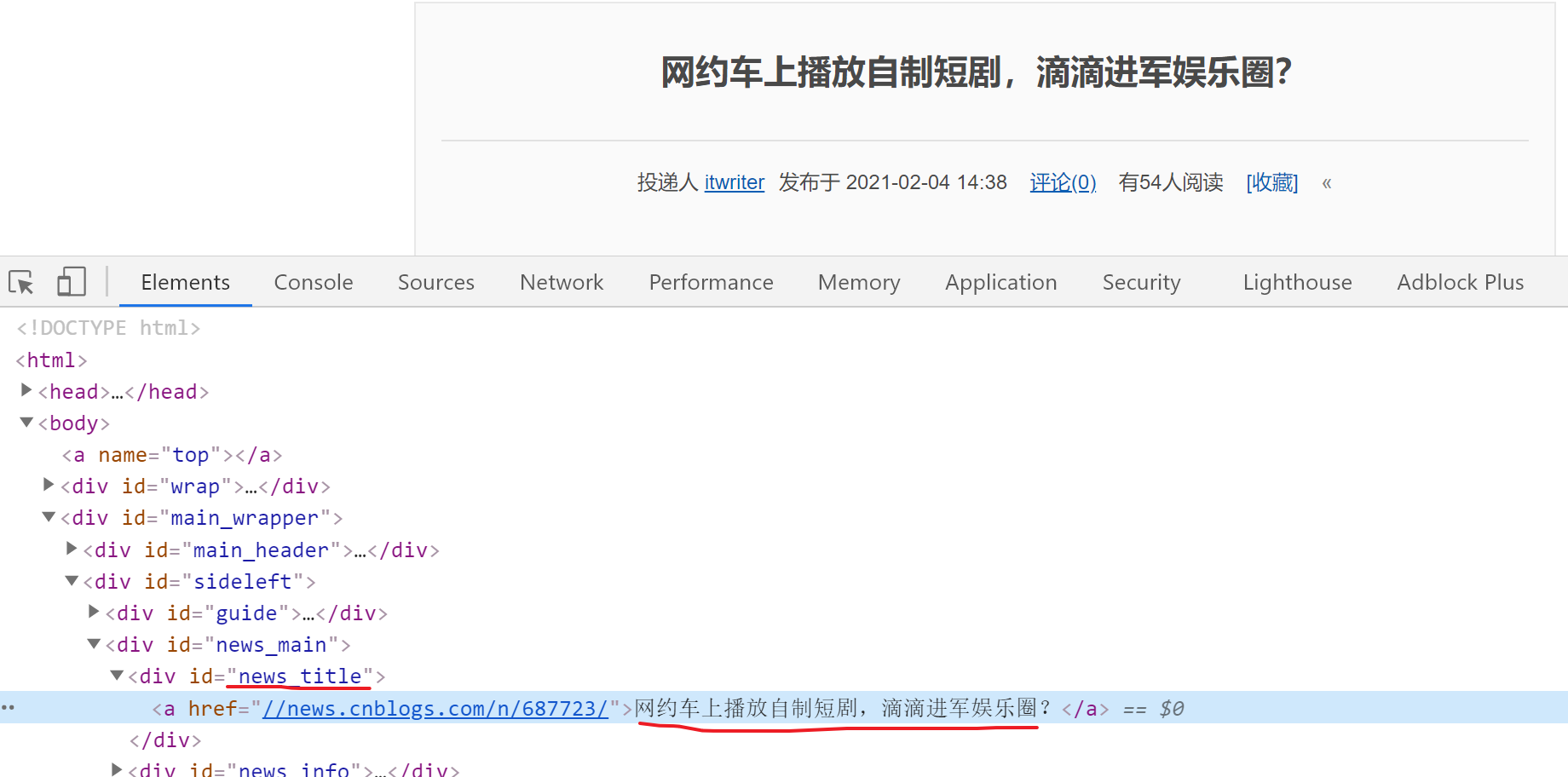
经过测试,详情页的源码也是直接响应出来的,所以数据也是真实存在。
在正式开始解析之前,先给大家讲一个测试代码的小技巧:
毕竟我们是在爬一个网站的数据,对吧,那每一次写完代码我们总归要测试一下看看是否正确,那如果每写一点代码,为了测试,我都去请求一下这个网站,那请求次数多了,难免触发网站的反爬措施,这样的话很有可能最后我们完全实现功能真的要开始爬数据的时候,网站可能已经不能爬了。所以为了避免这个问题,我们可以使用scrapy给我们提供的scrapy shell,来方便的测试代码。
如何使用呢?简单。打开命令行,输入:
scrapy shell 具体的详情页URL如下:
(SpiderEnvs_space) C:\Users\anwc>scrapy shell https://news.cnblogs.com/n/687723/ 2021-02-04 16:09:25 [scrapy.utils.log] INFO: Scrapy 2.4.1 started (bot: scrapybot) 2021-02-04 16:09:25 [scrapy.utils.log] INFO: Versions: lxml 4.6.2.0, libxml2 2.9.5, cssselect 1.1.0, parsel 1.6.0, w3lib 1.22.0, Twisted 20.3.0, Python 3.9.1 (tags/v3.9.1:1e5d33e, Dec 7 2020, 17:08:21) [MSC v.1927 64 bit (AMD64)], pyOpenSSL 20.0.1 (OpenSSL 1.1.1i 8 Dec 2020), cryptography 3.3.1, Platform Windows-10-10.0.18362-SP0 2021-02-04 16:09:25 [scrapy.utils.log] DEBUG: Using reactor: twisted.internet.selectreactor.SelectReactor 2021-02-04 16:09:25 [scrapy.crawler] INFO: Overridden settings: { 'DUPEFILTER_CLASS': 'scrapy.dupefilters.BaseDupeFilter', 'LOGSTATS_INTERVAL': 0} 2021-02-04 16:09:25 [scrapy.extensions.telnet] INFO: Telnet Password: 0681311bf88802b3 2021-02-04 16:09:25 [scrapy.middleware] INFO: Enabled extensions: ['scrapy.extensions.corestats.CoreStats', 'scrapy.extensions.telnet.TelnetConsole'] 2021-02-04 16:09:26 [scrapy.middleware] INFO: Enabled downloader middlewares: ['scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware', 'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware', 'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware', 'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware', 'scrapy.downloadermiddlewares.retry.RetryMiddleware', 'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware', 'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware', 'scrapy.downloadermiddlewares.redirect.RedirectMiddleware', 'scrapy.downloadermiddlewares.cookies.CookiesMiddleware', 'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware', 'scrapy.downloadermiddlewares.stats.DownloaderStats'] 2021-02-04 16:09:26 [scrapy.middleware] INFO: Enabled spider middlewares: ['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware', 'scrapy.spidermiddlewares.offsite.OffsiteMiddleware', 'scrapy.spidermiddlewares.referer.RefererMiddleware', 'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware', 'scrapy.spidermiddlewares.depth.DepthMiddleware'] 2021-02-04 16:09:26 [scrapy.middleware] INFO: Enabled item pipelines: [] 2021-02-04 16:09:26 [scrapy.extensions.telnet] INFO: Telnet console listening on 127.0.0.1:6023 2021-02-04 16:09:26 [scrapy.core.engine] INFO: Spider opened 2021-02-04 16:09:26 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://news.cnblogs.com/n/687723/> (referer: None) [s] Available Scrapy objects: [s] scrapy scrapy module (contains scrapy.Request, scrapy.Selector, etc) [s] crawler <scrapy.crawler.Crawler object at 0x000002210240F310> [s] item { } [s] request <GET https://news.cnblogs.com/n/687723/> [s] response <200 https://news.cnblogs.com/n/687723/> [s] settings <scrapy.settings.Settings object at 0x000002210240C9D0> [s] spider <DefaultSpider 'default' at 0x2210274edf0> [s] Useful shortcuts: [s] fetch(url[, redirect=True]) Fetch URL and update local objects (by default, redirects are followed) [s] fetch(req) Fetch a scrapy.Request and update local objects [s] shelp() Shell help (print this help) [s] view(response) View response in a browser >>>可以看到,一次请求后,scrapy shell返回了相应的对象,包含item啊,request啊什么的,我们只需要关注这个response就行,这里这个response,其实就是我们注入parse_detail的response,我们就可以直接使用相应的解析语句进行测试了,比如:
我们先解析标题:
>>> response.css('#news_title a::text').extract_first('') '网约车上播放自制短剧,滴滴进军娱乐圈?' >>>ok标题获取成功,那么这个语句我就可以直接复制粘贴到代码里了:
title = response.css('#news_title a::text').extract_first('')继续,我们解析下新闻的发布时间:
create_date = response.css('#news_info .time::text').extract_first('')我们先看下解析出来的时间格式:
>>> response.css('#news_info .time::text').extract_first('') '发布于 2021-02-04 14:38' >>>也就是我们拿到的时间格式是一个字符串加后面的日期格式。但这个时间我们只想要后面的时间格式的数字,而不想要前面的字符串,那么我们需要对其进行再一次的正则匹配,取出想要的日期格式就行了:
create_date = response.css('#news_info .time::text').extract_first('') match_res = re.match('.*?(\d+.*)',create_date) if match_res: create_date = match_res.group(1)继续,该解析页面的详情内容了。但此时又来了一个问题:
- 新闻的详情内容,即包含文字,又包含图片,甚至可能包含音视频,但其实大部分内容都是文本;
那如果我以获取文本的方式来解析详情内容,那详情中包含的图片,音视频等外部资源,可能就遗漏了,因为这些资源在解析文本时是没办法解析出来的。那怎么办呢?我们可以先暂时把整个详情内容的html全解析出来,至于其中的图片,音视频等外部资源,啥时候需要,我们再从数据库中读取出详情内容,进行二次解析就行了么,这一步,我们没必要把这些外部资源都解析出来呀,对吧。
这样一分析,解析详情内容就简单了,直接获取全部的html不就行了么:
content = response.css('#news_content').extract()[0]继续,接下来获取标签:
>>> response.css('.news_tags a::text').extract() ['滴滴'] >>>ok数据是能拿到,但是,我们看,返回的结果是一个list,而等会这些数据我们都是要入库的,但MySQL好像不支持list类型的数据吧?所以没办法,还是得给它转成字符串。
但还有个小问题,这里我们测试的这个新闻,它只有一个标签,但保不齐别的新闻会有很多标签啊,那多个标签该如何一次入库呢?那就转字符串的时候拼接一下嘛:
tags = ','.join(response.css('.news_tags a::text').extract())继续,我们提取新闻详情页中也包含的新闻概述内容中存在的那个图片,即通过parse第一次yield时提交的meta参数中的图片URL。
可是此时仍然有几个小问题:
- 图片我们是交给scrapy进行下载的,而scrapy需要的是一个URL队列,所以我得把取到的图片URL放入list结构内部;
- 并不是每一个新闻,其概述内容中都有图片的吧?所以当没有图片时,这个异常情况仍然需要处理一下;
经过上述分析,提取图片并做异常处理:
#如果存在图片,即能取到meta参数传递过来的图片URL if response.meta.get('front_image_url',[]): front_image_url = [response.meta.get('front_image_url','')] #否则,如果该条新闻概述内没有图片,则给个空队列就行了 else: front_image_url = []继续,接下来解析评论数:

>>> response.css('span.comment a::text').extract() [] >>>emmmm?怎么为空?明明控制台能看到这个评论数啊?
ahhhhh…可能动态加载了吧?
先看下源码:

源码确实没有…
那么经过测试,阅读数以及推荐数,在源码中也没有。
所以,这三个数据,应该是异步加载了。
没关系,我们现在查看下XHR数据包。经过筛选,检索,我们定位了这样的一个数据包:
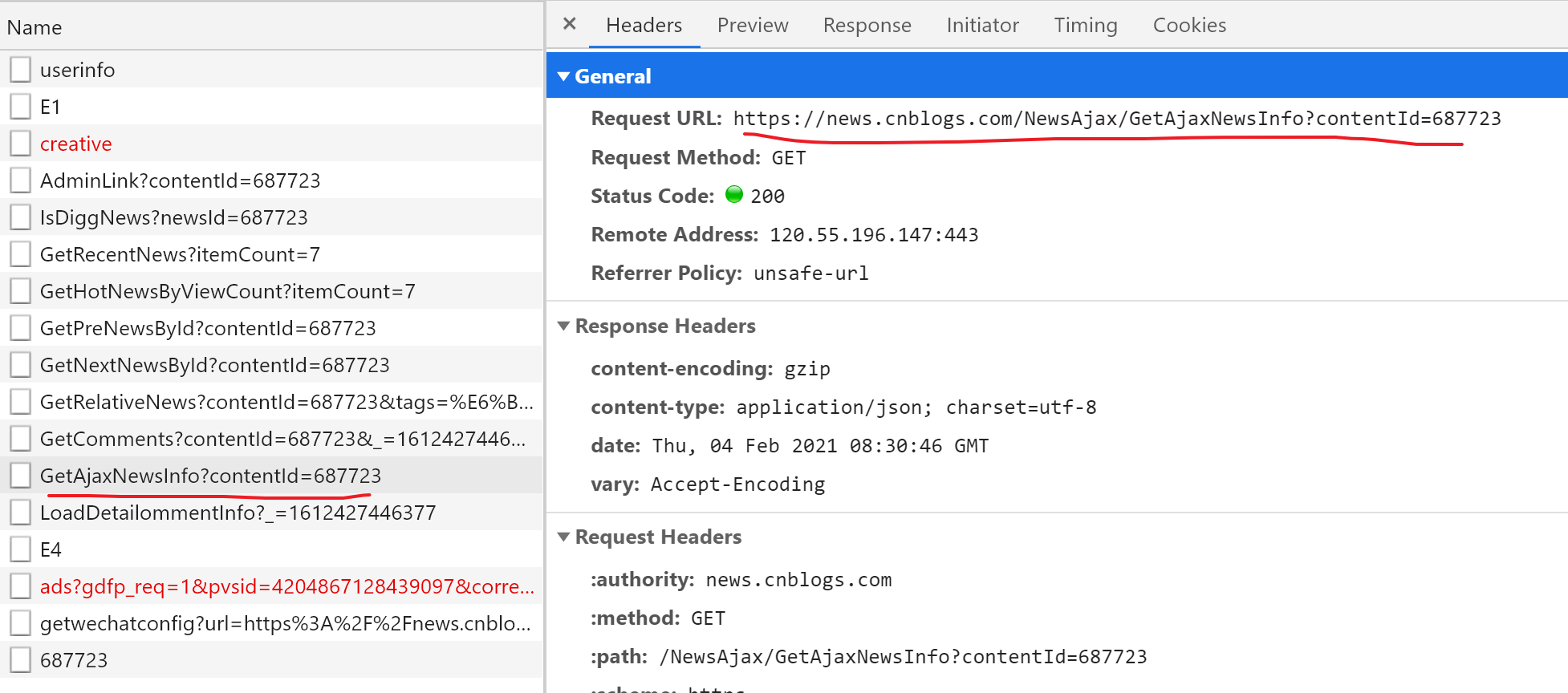
其响应数据:
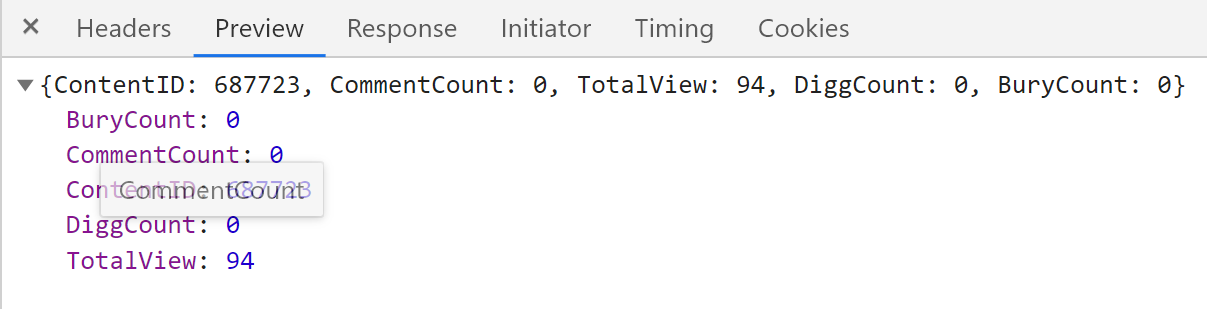
确实包含所需的三个数据。
找到了就好,现在就是想办法获取这三个数据。
但,问题来了。
这三个数据,得去请求一个XHR接口才能获取,也就是说,这三个数据得单独下载,而我们前面解析出来的数据,在这一步之前,到底是yield还是不yield呢?
最好还是把所有数据全部都解析到之后再yield到item吧。
可是已经解析出了好多数据了,此时不yield,等到下载完毕三个异步加载的数据之后再yield,那就需要把已经解析得到的数据传递给异步数据下载方法,等待最后三个数据下载完毕后再统一yield至item,那这些已经解析完毕的数据怎么传递至异步数据下载方法啊?
所以此时,我们先把已有的这部分数据先写入item吧,然后把item传递到异步数据下载方法,等最后三个数据也获取完了,并且也写入至item了,再最后统一全部yield至item吧,只能这样了。
ok,思路明确之后,现在我们先将已解析的部分数据写入item。
先把刚才我们定义好的item类导入并实例化:
from demo01_jobbole.items import JobBoleArticleItem再在parse_detail中实例化item类:
article_item = JobBoleArticleItem()然后,将我们刚才已经解析出的数据先入item:
article_item['title'] = title article_item['create_date'] = create_date article_item['content'] = content article_item['tags'] = tags article_item['url'] = response.url if response.meta.get('front_image_url',[]): article_item['front_image_url'] = [response.meta.get('front_image_url','')] else: article_item['front_image_url'] = []现在,我们先准备好异步数据下载方法:
def parse_nums(self,response): pass此时,我们就可以开始下载异步数据了。
接下来我们分析下这个XHR接口的请求URL:
https://news.cnblogs.com/NewsAjax/GetAjaxNewsInfo?contentId=687723前半部分:https://news.cnblogs.com/,其实包含在response.url中;
后半部分直至:NewsAjax/GetAjaxNewsInfo?contentId=,这部分我们通过字符串写入;
可关键是这个contentId,它是根据详情页随时变化的,这个ID在哪呢?也存在于response.url中。
所以,我们可以先使用正则,从详情页的URL中解析出这个content_id,再拼接至‘NewsAjax/GetAjaxNewsInfo?contentId=’中,最后再灵活拼接上前面的协议和主机地址即可:
match_re = re.match('.*?(\d+)',response.url) post_id = match_re.group(1) url=parse.urljoin(response.url, '/NewsAjax/GetAjaxNewsInfo?contentId={}'.format(post_id))XHR数据包的URL已经拼接完毕,下载异步数据我们需要将URL提供给scrapy进行下载并绑定回调函数进行数据解析,同时前面说到了,已经写入部分数据的item也要传递到parse_nums方法:
yield Request(url=parse.urljoin(response.url, '/NewsAjax/GetAjaxNewsInfo?contentId={}'.format(post_id)), meta={ 'article_item':article_item},callback=self.parse_nums)ok,至此,parse_detail的职责完成:
- 解析详情页的部分数据;
- 写入item;
- 将异步数据的URL提交给scrapy下载并将已有的item传递至回调函数;
现在放上parse_detail的全部代码:
def parse_detail(self,response): ''' 详情页面解析方法 ''' match_re = re.match('.*?(\d+)',response.url) #这里为什么是这个逻辑呢?因为为了代码的逻辑严谨性,其实如果解析出的详情页URL没有contentid的话,整个页面的解析其实也会出错,既然是这样的情况,不如将contentid的解析放在逻辑判断内,如果能解析出详情页的contentid,则代表代码没有异常。 if match_re: article_item = JobBoleArticleItem() title = response.css('#news_title a::text').extract_first('') create_date = response.css('#news_info .time::text').extract_first('') match_res = re.match('.*?(\d+.*)',create_date) if match_res: create_date = match_res.group(1) content = response.css('#news_content').extract()[0] # tag_list = response.css('.news_tags a::text').extract() tags = ','.join(response.css('.news_tags a::text').extract()) post_id = match_re.group(1) # html = requests.get(url=parse.urljoin(response.url, '/NewsAjax/GetAjaxNewsInfo?contentId={}'.format(post_id))) # j_data = json.loads(html.text) article_item['title'] = title article_item['create_date'] = create_date article_item['content'] = content article_item['tags'] = tags article_item['url'] = response.url if response.meta.get('front_image_url',[]): article_item['front_image_url'] = [response.meta.get('front_image_url','')] else: article_item['front_image_url'] = [] yield Request(url=parse.urljoin(response.url, '/NewsAjax/GetAjaxNewsInfo?contentId={}'.format(post_id)), meta={ 'article_item':article_item},callback=self.parse_nums)现在我们进入异步数据下载方法,实现异步数据的解析逻辑。
通过刚才的分析我们知道,评论数,阅读数,推荐数这三个数据是通过异步加载的,且该接口响应的数据为json格式,那么我们就可以通过解析json数据的方式,方便的拿到这三个数据,并且将其写入item:
def parse_nums(self,response): j_data = json.loads(response.text) #将传递过来的item取出,方便后续写入三个数据 article_item = response.meta.get('article_item','') praise_nums = j_data['DiggCount'] fav_nums = j_data['TotalView'] comment_nums = j_data['CommentCount'] article_item['praise_nums'] = praise_nums article_item['fav_nums'] = fav_nums article_item['comment_nums'] = comment_nums至此,前期分析的item应有的数据,我们都解析完毕并且写入至item了。
但其实,我们还缺少一个数据。
回看我们之前的代码,针对我们获取的每一个详情页的URL,其实不难发现,这些URL的长度都是不定的。往往我们在进行数据爬取时,对于请求的URL,为了实现方便管理,我们需要将其变为定长的格式,这里我们就需要使用到md5加密了。
那具体怎么实现呢?思路其实很简单:
- 定义一个md5加密算法,将传入的URL加密为定长格式;
- 针对加密后定长的URL,将其写入item,作为需要解析的最后一项数据;
接下来我们实现这个功能。
在spider目录的同级目录下,新建一个目录:untils,在其中创建一个模块:common.py;在该模块内部实现加密算法:
# -*- coding:utf-8 _*- """ @version: author:weichao_an @time: 2021/02/03 @file: common.py @environment:virtualenv @email:awc19930818@outlook.com @github:https://github.com/La0bALanG @requirement: """ import hashlib def get_md5(url): if isinstance(url,str): url = url.encode('utf-8') m = hashlib.md5() m.update(url) return m.hexdigest() if __name__ == '__main__': print(get_md5('https://www.baidu.com'))回到我们的spider文件,先导入该算法:
from demo01_jobbole.utils import common再将详情页URL传入,加密后写入item:
article_item['url_object_id'] = common.get_md5(article_item['url'])至此,item所需数据全部解析完成,将其yield回items,后续即将开始数据的持久化操作。
现放上parse_nums的所有代码:
def parse_nums(self,response): j_data = json.loads(response.text) article_item = response.meta.get('article_item','') praise_nums = j_data['DiggCount'] fav_nums = j_data['TotalView'] comment_nums = j_data['CommentCount'] article_item['praise_nums'] = praise_nums article_item['fav_nums'] = fav_nums article_item['comment_nums'] = comment_nums article_item['url_object_id'] = common.get_md5(article_item['url']) yield article_item -
数据入管道,进行入库等持久化操作
-
对于图片的持久化-保存为本地文件
pipelines.py class ArticleImagePipeline(ImagesPipeline): def item_completed(self, results, item, info): if 'front_image_url' in item: image_file_path = '' for ok,value in results: image_file_path = value['path'] item['front_image_path'] = image_file_path return item -
解析得到的数据写入json文件-保存为本地json文件
pipelines.py class JsonWithEncodingPipline(object): ''' 自定义json文件的导出 ''' def __init__(self): self.file = codecs.open('article.json','a',encoding='utf-8') def process_item(self,item,spider): lines = json.dumps(dict(item),ensure_ascii=False) + '\n' self.file.write(lines) return item def spider_closed(self,spider): self.file.close() -
数据库建库-准备将数据写入MySQL
create table jobbole_article ( title varchar(255) not null, url varchar(500) not null, url_object_id varchar(50) not null primary key, front_image_path varchar(200) null, front_image_url varchar(500) null, paise_nums int default 0 not null, comment_nums int null, fav_nums int null, tags varchar(255) null, content longtext null, create_date datetime null ); -
同步方式将数据写入MySQL
pipelines.py class MysqlPipeline(object): def __init__(self): self.conn = MySQLdb.connect('127.0.0.1','root','185268','article_spider',charset='utf8',use_unicode=True) self.cursor = self.conn.cursor() def process_item(self,item,spider): insert_sql = """ insert into jobbole_article (title,url,url_object_id,front_image_path,front_image_url,paise_nums,comment_nums,fav_nums,tags,content,create_date) values (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s) ON DUPLICATE KEY UPDATE comment_nums=VALUES(comment_nums) """ parmas = list() parmas.append(item.get('title','')) parmas.append(item.get('url','')) parmas.append(item.get('url_object_id','')) parmas.append(item.get('front_image_path','')) front_image = ','.join(item.get('front_image_url',[])) parmas.append(front_image) parmas.append(item.get('paise_nums',0)) parmas.append(item.get('comment_nums',0)) parmas.append(item.get('fav_nums',0)) parmas.append(item.get('tags','')) parmas.append(item.get('content','')) parmas.append(item.get('create_date','1970-07-01')) self.cursor.execute(insert_sql,tuple(parmas)) self.conn.commit() return item -
异步方式将数据写入MySQL
pipelines.py class MysqlTwistedPipeline(object): def __init__(self,dbpool): self.dbpool = dbpool @classmethod def from_settings(cls,settings): dbparms = dict( host = settings['MYSQL_HOST'], db = settings['MYSQL_DBNAME'], user = settings['MYSQL_USER'], passwd = settings['MYSQL_PASSWORD'], charset = 'utf8', cursorclass = DictCursor, use_unicode = True ) dbpool = adbapi.ConnectionPool('MySQLdb',**dbparms) return cls(dbpool) def process_item(self,item,spider): query = self.dbpool.runInteraction(self.do_insert,item) query.addErrback(self.handle_error,item,spider) return item def handle_error(self,failure,item,spider): print(failure) def do_insert(self,cursor,item): insert_sql = """ insert into jobbole_article (title,url,url_object_id,front_image_path,front_image_url,paise_nums,comment_nums,fav_nums,tags,content,create_date) values (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s) ON DUPLICATE KEY UPDATE comment_nums=VALUES(comment_nums) """ parmas = list() parmas.append(item.get('title', '')) parmas.append(item.get('url', '')) parmas.append(item.get('url_object_id', '')) parmas.append(item.get('front_image_path', '')) front_image = ','.join(item.get('front_image_url', [])) parmas.append(front_image) parmas.append(item.get('paise_nums', 0)) parmas.append(item.get('comment_nums', 0)) parmas.append(item.get('fav_nums', 0)) parmas.append(item.get('tags', '')) parmas.append(item.get('content', '')) parmas.append(item.get('create_date', '1970-07-01')) cursor.execute(insert_sql,tuple(parmas)) -
管道配置至settings
settings.py ITEM_PIPELINES = { 'demo01_jobbole.pipelines.ArticleImagePipeline':1, 'demo01_jobbole.pipelines.JsonWithEncodingPipline':2, 'demo01_jobbole.pipelines.MysqlTwistedPipeline': 3, 'demo01_jobbole.pipelines.Demo01JobbolePipeline': 300 }
至此,本爬虫案例所有编码全部完成。
-
-
测试结果
-
json文件(数据量较大,只展示一条数据)
{ "title": "微信红包封面背后的生意经", "create_date": "2021-02-03 14:00", "content": "<div id=\"news_content\">\n <div id=\"news_body\">\n \n<p> 12 月 9 号,微信开放了视频号的自制红包封面权限,从此定制红包封面不再是大型企业或机构的专利。从微信的角度看,开放视频号的红包封面制作权限可以吸引更多用户使用视频号,从而壮大自己的视频号生态。尤其农历新年即将到来,谁又不想在过年「红包大战」时在亲朋好友面前秀出「极具个性」的红包封面呢?</p>\r\n<p style=\"text-align: center;\"><img title=\"\" src=\"//img2020.cnblogs.com/news/66372/202102/66372-20210203141942833-1016059283.png\" alt=\"\"></p>\r\n<p> 不过事情的发展似乎超出了微信的预料,尽管在微信红包封面的微信指数在十二月底与农历新年前屡创新高,在 2 月 1 日更是超过了 1.3 亿万,日环比高达 216.54%,但视频号的微信指数除了 12 月 28 日突发破亿以外,其余时间都异常平静,停留在 800 万上下。</p>\r\n<p> 那问题来了,按照微信的逻辑,红包封面应该是和视频号相互关联的两个热点,即使考虑到机构红包等因素,红包封面的微信指数也不应该领先视频号这么多。这些「多出来的」的红包封面,究竟从何而来?</p>\r\n<p> 很简单,用户花钱买来的。</p>\r\n<p> <strong>微信红包,里面外面都是生意</strong></p>\r\n<p> 其实早在 12 月 9 号微信红包封面开放视频号制作之前,网上就有出售,或在特定条件下「免费发放」红包封面的情况。按照最初的设定,「红包封面」应该是各企业买给自己员工的福利,或是向公众派发的广告赠品。毕竟这些红包封面上都有着大大的品牌标志,用户每次发红包都等于给品牌做广告。</p>\r\n<p> 微信的红包封面已经成为大众茶余饭后的谈资之一,抢夺数量稀少的红包,甚至比抢购热门数码产品、奢侈品更加困难。日前,微信派官方表示,将会在春节周期内发放超过 5000 万的红包封面,但根据此前红包封面被一扫而空的情况来看,这 5000 万个红包封面似乎也是杯水车薪。</p>\r\n<p style=\"text-align: center;\"><img title=\"\" src=\"//img2020.cnblogs.com/news/66372/202102/66372-20210203141943072-960441720.png\" alt=\"\"></p>\r\n<p> <strong>但正所谓「物以稀为贵」,限量派发的品牌红包很快就成为大家互相「炫耀」的资本,之后更是成为了少数人的「商品」。比如 LV、Gucci、Supreme 等品牌的红包封面,在闲鱼与「红包贩子」手中就一直是畅销商品——一个免费领取的红包序列码,甚至可以在闲鱼上转手以 30 元出售,可谓是「无本万利」。</strong></p>\r\n<p> 而 12 月 9 号的开放的个人红包封面,则是将各「商机」彻底点燃——随着红包封面制作成本的直线下降(10 元/个降低至 1 元/个),一条关于红包封面的成熟「产业链」也浮出了水面。</p>\r\n<p> <strong>简单来说,一条红包封面的「产业链」从源头的「图源」到末端的「消费者」,大致可以分为「图源」「制作」「分销」「二级分销」「消费者」这五个角色。</strong>其中「图源」顾名思义就是提供红包封面原始素材的画师或摄影师,但就像大家想的那样,由于国内没人注重的版权规定,市面上流通的绝大多数红包封面都「省略」的图片采购这个步骤,基本上都是制作者在互联网上随便找来的图。</p>\r\n<p> <strong>有了图源,接下来就是「制作」,这也是整条产业链中存在不可避免固定成本的环节——根据微信红包封面页面的指引,每提交一个红包封面,微信将收取一元的费用。尽管这个「硬性成本」不可避免,但在高达 500% 的利润率面前,这点费用还真算不上什么。</strong></p>\r\n<p> 审核通过意味着红包封面进入到「分销」环节。「分销商」会从制作者手中大量采购序列号,或者干脆自己一手包办制作与分销两个环节,以将利润空间掌握在自己手里。<strong>不同于各位在微信朋友圈或微博上见到的「二级分销」,这里的「一级」分销商无论是规模还是利润空间都大得多,部分</strong><strong>分</strong><strong>销商的利润甚至足以支撑他们为此专门建立一个「线上商城」。</strong></p>\r\n<p style=\"text-align: center;\"><img title=\"\" src=\"//img2020.cnblogs.com/news/66372/202102/66372-20210203141943077-1530096933.jpg\" alt=\"\"></p>\r\n<p> 以某红包封面商城为例,尽管这只是一个基于快速建站模板的小网站,交互界面也非常简陋,但在简陋的背后分销商已经打通了一条完整的支付路径:<strong>不支持微信支付以避开微信监管,使用其他类目(水果店)的支付宝收款端口掩人耳目,通过 QQ 发放序列号再次绕开微信监管。这套成熟的分销体系将分销商与终端消费者隔离开来,让经销商在赚取高额利润的同时「卸下」自己的风险。</strong></p>\r\n<p style=\"text-align: center;\"><img title=\"\" src=\"//img2020.cnblogs.com/news/66372/202102/66372-20210203141943077-1588516174.jpg\" alt=\"\"></p>\r\n<p> <strong>赚的就是信息差</strong></p>\r\n<p> 刚刚说过,我们在微信朋友圈或微博、闲鱼等平台见到的一般都只是「二级分销商」,或者说「二道贩子」。<strong>他们不参与红包制作与采购,只对终端消费者「负责」,但这并不意味着他们技术含量低——在我看来,这些「二级分销商」可以说极具互联网思维:他们的利润,完全建立在「信息差」这一概念上。</strong></p>\r\n<p> 回到刚才说的商城,这其实也是二级分销「拿货」的地方。尽管网站的右下角有登录的功能,但整个购买流程其实完全不做任何要求;除此之外,网站也没有最低购买数量的限制,也就是不存在批发与零售的区别。</p>\r\n<p style=\"text-align: center;\"><img title=\"\" src=\"//img2020.cnblogs.com/news/66372/202102/66372-20210203141942826-1022245698.jpg\" alt=\"\"></p>\r\n<p> <strong>换句话说,二级分销商既不需要「交钱进群」,也不需要「垫资进货」,他们只要把商城里的图片下载下来,再加价卖给终端消费者就够了。</strong>当然,他们也要承担一定的「风险」:因同行举报或版权原因,已经生成的红包封面后可能会「失效」,此时终端买家第一个找上的肯定就是二级分销。</p>\r\n<p> <strong>但刚刚说过,二级分销是一个完全基于信息差的,赚多赚少只看胆子的「无本万利」行业,在足够高的利润率面,即使给买家「全额退款」又能有什么损失呢?</strong></p>\r\n<p> 当然了,除了这条成熟的产业链外,「私域流量」概念的兴起也催生出另一条「致富道路」:部分公众号会以「免费红包封面」为噱头要求买家加微信并完成某些「推广任务」。对于账号运营者来说,这其实就是在用红包封面「买人头」。</p>\r\n<p> <strong>千篇一律的「个性化」</strong></p>\r\n<p> <strong>看到这里,可能有人会觉得奇怪?不就是一个微信红包的封面吗?连红包都不是,究竟有什么吸引人的地方?在我看来,红包封面的流行,本质上是封闭环境内群众个性化需求的体现。</strong></p>\r\n<p> 最初在接触这个选题时,由于刻板的固有印象,我以为红包封面的用户画像应该是中年群体——<strong>他们有发红包的刚性需求,同时对互联网也相对陌生,不能自制红包封面,而且「花钱买红包」这个逻辑在过去十年里也是他们日常生活的一部分,不需要重新建立消费习惯。</strong></p>\r\n<p> 但没想到的是,在与一位「兼职封面卖家」的交流中得知,<strong>红包封面的消费主力更多的是年轻群体,生肖与猫相关的红包封面也占据销量榜首。</strong>发红包对年轻群体来说并不是什么「硬性任务」,猫相比过年红包,也更像是个人喜好的展现。<strong>也就是说,这些「高价」买来的封面,其实就像 QQ 的气泡、微博的卡片、视频网站的头像框一样,是一个基于「个性化」需求创造出的市场空缺。</strong></p>\r\n<p style=\"text-align: center;\"><img title=\"\" src=\"//img2020.cnblogs.com/news/66372/202102/66372-20210203141943076-1009299782.jpg\" alt=\"\"></p>\r\n<p> 但问题是,从别人手中买来的「个性」,还算得上「个性」吗?你能买,别人也能买,这种流水线批量「生产」的虚拟商品,真的是追求个性的年轻人彰显个人品味的正确方法吗?延伸开来,那些在广东、浙江甚至是东南亚血汗工厂批量生产的「成衣」潮牌,又算得上是个性的表现吗?</p>\r\n<p> 这个问题我无法回答,但我能肯定的是,红包封面的「产业链」不仅不会随着新年假期的结束而消失,还将继续「壮大」下去,让更多人的账户余额实现「10W+」,而在红包封面的「盛世」中,视频号将是唯一的「输家」。</p> </div><!--end: news_body -->\n <div id=\"news_otherinfo\">\n <div id=\"up_down\">\n <div class=\"diggit\" οnclick=\"VoteNews(687629,'agree')\">\n <span class=\"diggnum\" id=\"digg_num_687629\"></span>\n </div>\n <div class=\"buryit\" οnclick=\"VoteNews(687629,'anti')\">\n <span class=\"burynum\" id=\"bury_num_687629\"></span>\n </div>\n <div class=\"clear\"></div>\n <div id=\"digg_tip_687629\" class=\"digg_tip_detail\"> </div>\n </div>\n <div id=\"come_from\">\n 来自:\n 雷科技网 </div><!--end: come_from -->\n <div class=\"clear\"></div>\n <div id=\"article_A4area\">\n <span id=\"shareA4\" class=\"fl\">\n <a href=\"https://brands.cnblogs.com/aws/register\" target=\"_blank\"><b>注册AWS账号,立享12个月免费套餐</b></a>\n </span>\n <span id=\"sharebox\">\n <a οnclick=\"PutInWz();return false;\" href=\"javascript:void(0);\">\n <img border=\"0\" title=\"收藏至网摘\" src=\"/Images/icon_wz.png\" alt=\"收藏\">\n </a>\n <a rel=\"nofollow\" οnclick=\"ShareToTsina();return false;\" href=\"javascript:void(0)\">\n <img border=\"0\" title=\"转发至新浪微博\" src=\"/Images/icon_sina.gif\" alt=\"新浪微博\">\n </a>\n <a rel=\"nofollow\" οnclick=\"ShareToTweixin(687629);return false;\" href=\"javascript:void(0)\">\n <img border=\"0\" title=\"分享至微信\" src=\"/Images/icon_weixin.gif\" alt=\"分享至微信\">\n </a>\n </span>\n <div class=\"clear\">\n </div>\n </div><!--end: share block-->\n <div class=\"clear\"></div>\n <div id=\"e4\" style=\"height:60px; width:468px;\">\n <div id=\"div-gpt-ad-1533633736227-3\" class=\"e4-dfp\" style=\"height:60px; width:468px;\"></div>\n </div>\n <div id=\"news_more_info\">\n <div class=\"news_tags\">标签: <a href=\"/n/tag/%E5%BE%AE%E4%BF%A1/\" class=\"catalink\">微信</a></div>\n <input type=\"hidden\" name=\"tagsId\" id=\"tagsId\" value=\"微信\">\n </div>\n </div><!--end: news_otherinfo -->\n </div>", "tags": "微信", "url": "https://news.cnblogs.com/n/687629/", "front_image_url": ["https://img2018.cnblogs.com/news_topic/20191011113837921-1266267629.png"], "praise_nums": 0, "fav_nums": 287, "comment_nums": 0, "url_object_id": "9b1094ca99579b94af75266bc8fa3907", "front_image_path": "full/0b51367f1c0e48bea4ab14f6512739300db9cf3f.jpg"} -
MySQL写入:
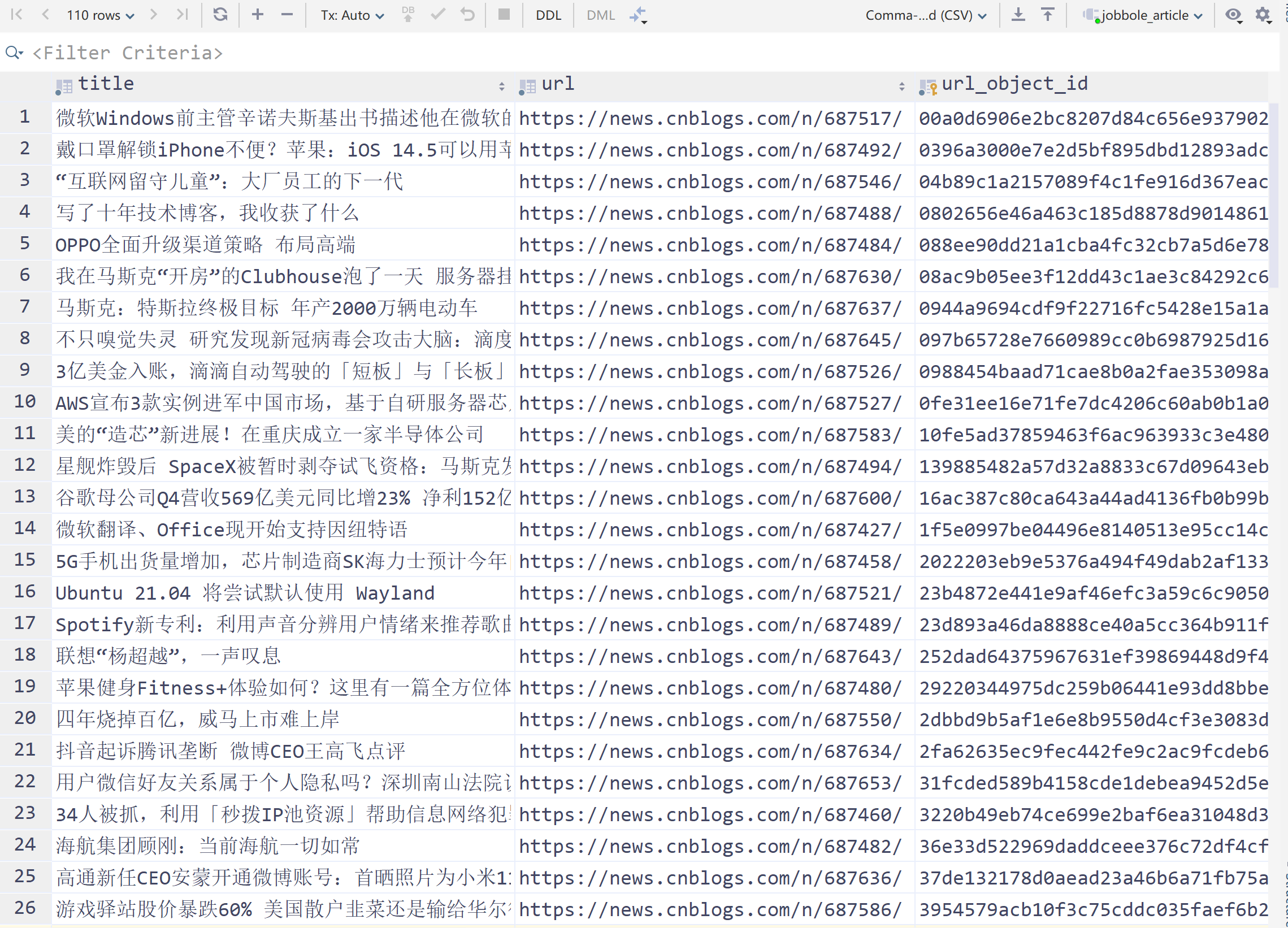
-
图片下载:

-
-
本案例所有源码
-
settings.py
import os import sys # Scrapy settings for demo01_jobbole project # # For simplicity, this file contains only settings considered important or # commonly used. You can find more settings consulting the documentation: # # https://docs.scrapy.org/en/latest/topics/settings.html # https://docs.scrapy.org/en/latest/topics/downloader-middleware.html # https://docs.scrapy.org/en/latest/topics/spider-middleware.html BOT_NAME = 'demo01_jobbole' SPIDER_MODULES = ['demo01_jobbole.spiders'] NEWSPIDER_MODULE = 'demo01_jobbole.spiders' # Crawl responsibly by identifying yourself (and your website) on the user-agent #USER_AGENT = 'demo01_jobbole (+http://www.yourdomain.com)' # Obey robots.txt rules ROBOTSTXT_OBEY = False # Configure maximum concurrent requests performed by Scrapy (default: 16) #CONCURRENT_REQUESTS = 32 # Configure a delay for requests for the same website (default: 0) # See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay # See also autothrottle settings and docs #DOWNLOAD_DELAY = 3 # The download delay setting will honor only one of: #CONCURRENT_REQUESTS_PER_DOMAIN = 16 #CONCURRENT_REQUESTS_PER_IP = 16 # Disable cookies (enabled by default) #COOKIES_ENABLED = False # Disable Telnet Console (enabled by default) #TELNETCONSOLE_ENABLED = False # Override the default request headers: #DEFAULT_REQUEST_HEADERS = { # 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', # 'Accept-Language': 'en', #} # Enable or disable spider middlewares # See https://docs.scrapy.org/en/latest/topics/spider-middleware.html #SPIDER_MIDDLEWARES = { # 'demo01_jobbole.middlewares.Demo01JobboleSpiderMiddleware': 543, #} # Enable or disable downloader middlewares # See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html #DOWNLOADER_MIDDLEWARES = { # 'demo01_jobbole.middlewares.Demo01JobboleDownloaderMiddleware': 543, #} # Enable or disable extensions # See https://docs.scrapy.org/en/latest/topics/extensions.html #EXTENSIONS = { # 'scrapy.extensions.telnet.TelnetConsole': None, #} # Configure item pipelines # See https://docs.scrapy.org/en/latest/topics/item-pipeline.html ITEM_PIPELINES = { 'demo01_jobbole.pipelines.ArticleImagePipeline':1, 'demo01_jobbole.pipelines.JsonWithEncodingPipline':2, 'demo01_jobbole.pipelines.MysqlTwistedPipeline': 3, 'demo01_jobbole.pipelines.Demo01JobbolePipeline': 300 } # Enable and configure the AutoThrottle extension (disabled by default) # See https://docs.scrapy.org/en/latest/topics/autothrottle.html #AUTOTHROTTLE_ENABLED = True # The initial download delay #AUTOTHROTTLE_START_DELAY = 5 # The maximum download delay to be set in case of high latencies #AUTOTHROTTLE_MAX_DELAY = 60 # The average number of requests Scrapy should be sending in parallel to # each remote server #AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0 # Enable showing throttling stats for every response received: #AUTOTHROTTLE_DEBUG = False # Enable and configure HTTP caching (disabled by default) # See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings #HTTPCACHE_ENABLED = True #HTTPCACHE_EXPIRATION_SECS = 0 #HTTPCACHE_DIR = 'httpcache' #HTTPCACHE_IGNORE_HTTP_CODES = [] #HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage' # # print(os.path.dirname(os.path.abspath(__file__))) IMAGES_URLS_FIELD = 'front_image_url' projects_dir = os.path.dirname(os.path.abspath(__file__)) IMAGES_STORE = os.path.join(projects_dir,'images') MYSQL_HOST = '127.0.0.1' MYSQL_DBNAME = 'article_spider' MYSQL_USER = 'root' MYSQL_PASSWORD = '185268' -
jobbole.py
import re import json from urllib import parse import scrapy import requests from scrapy import Request from demo01_jobbole.items import JobBoleArticleItem from demo01_jobbole.utils import common class JobboleSpider(scrapy.Spider): name = 'jobbole' allowed_domains = ['news.cnblogs.com'] start_urls = ['http://news.cnblogs.com/'] def parse(self, response): ''' 功能实现: 1.获取新闻列表页中的新闻url交给scrapy进行下载后调用相应的解析方法 2.获取下一页的url交给scrapy进行下载,下载完成后交给parse继续跟进 ''' # urls = response.css('div#news_list h2 a::attr(href)').extract() post_nodes = response.css('#news_list .news_block') for post_node in post_nodes: image_url = post_node.css('.entry_summary a img::attr(src)').extract_first('') if image_url.startswith('//'): image_url = 'https:' + image_url post_url = post_node.css('h2 a::attr(href)').extract_first('') yield Request(url=parse.urljoin(response.url,post_url),meta={ 'front_image_url':image_url},callback=self.parse_detail) #提取下一页交给scrapy进行下载 next_url = response.css('div.pager a:last-child::text').extract_first('') # next_url = response.xpath('a[contains(text(),"Next >")]/@href').extract_first('') # yield Request(url=parse.urljoin(response.url, next_url), callback=self.parse) if next_url == 'Next >': next_url = response.css('div.pager a:last-child::attr(href)').extract_first('') yield Request(url=parse.urljoin(response.url, next_url),callback=self.parse) def parse_detail(self,response): ''' 详情页面解析方法 ''' match_re = re.match('.*?(\d+)',response.url) if match_re: article_item = JobBoleArticleItem() title = response.css('#news_title a::text').extract_first('') create_date = response.css('#news_info .time::text').extract_first('') match_res = re.match('.*?(\d+.*)',create_date) if match_res: create_date = match_res.group(1) content = response.css('#news_content').extract()[0] # tag_list = response.css('.news_tags a::text').extract() tags = ','.join(response.css('.news_tags a::text').extract()) post_id = match_re.group(1) # html = requests.get(url=parse.urljoin(response.url, '/NewsAjax/GetAjaxNewsInfo?contentId={}'.format(post_id))) # j_data = json.loads(html.text) article_item['title'] = title article_item['create_date'] = create_date article_item['content'] = content article_item['tags'] = tags article_item['url'] = response.url if response.meta.get('front_image_url',[]): article_item['front_image_url'] = [response.meta.get('front_image_url','')] else: article_item['front_image_url'] = [] yield Request(url=parse.urljoin(response.url, '/NewsAjax/GetAjaxNewsInfo?contentId={}'.format(post_id)), meta={ 'article_item':article_item},callback=self.parse_nums) # praise_nums = j_data['DiggCount'] # fav_nums = j_data['TotalView'] # comment_nums = json['CommentCount'] def parse_nums(self,response): j_data = json.loads(response.text) article_item = response.meta.get('article_item','') praise_nums = j_data['DiggCount'] fav_nums = j_data['TotalView'] comment_nums = j_data['CommentCount'] article_item['praise_nums'] = praise_nums article_item['fav_nums'] = fav_nums article_item['comment_nums'] = comment_nums article_item['url_object_id'] = common.get_md5(article_item['url']) yield article_item -
items.py
# Define here the models for your scraped items # # See documentation in: # https://docs.scrapy.org/en/latest/topics/items.html import scrapy class Demo01JobboleItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() pass #不使用提供的模板,我们自己定义一个item,只需要像模板一样让自己的item类也继承scrapy.Item即可 class JobBoleArticleItem(scrapy.Item): ''' 定义数据结构,对应到数据库中也就是所需字段 ''' #新闻标题 title = scrapy.Field() #新闻发布时间:因为要入库,预想到,很大可能是时间日期格式数据 create_date = scrapy.Field() #每一个新闻详情页的请求URL url = scrapy.Field() #待定:后续讲解该字段的含义 url_object_id = scrapy.Field() #详情页包含的图片下载URL front_image_url = scrapy.Field() #图片保存路径 front_image_path = scrapy.Field() #点赞/推荐数量 praise_nums = scrapy.Field() #评论数量 comment_nums = scrapy.Field() #新闻阅读数量 fav_nums = scrapy.Field() #新闻所属标签:预想到标签可能不止一个 tags = scrapy.Field() #新闻页面的主体内容 content = scrapy.Field() -
pipelines.py
# Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html import codecs import json import MySQLdb from twisted.enterprise import adbapi from MySQLdb.cursors import DictCursor from scrapy.pipelines.images import ImagesPipeline # useful for handling different item types with a single interface from itemadapter import ItemAdapter class Demo01JobbolePipeline(object): def process_item(self, item, spider): return item class MysqlPipeline(object): def __init__(self): self.conn = MySQLdb.connect('127.0.0.1','root','185268','article_spider',charset='utf8',use_unicode=True) self.cursor = self.conn.cursor() def process_item(self,item,spider): insert_sql = """ insert into jobbole_article (title,url,url_object_id,front_image_path,front_image_url,paise_nums,comment_nums,fav_nums,tags,content,create_date) values (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s) ON DUPLICATE KEY UPDATE comment_nums=VALUES(comment_nums) """ parmas = list() parmas.append(item.get('title','')) parmas.append(item.get('url','')) parmas.append(item.get('url_object_id','')) parmas.append(item.get('front_image_path','')) front_image = ','.join(item.get('front_image_url',[])) parmas.append(front_image) parmas.append(item.get('paise_nums',0)) parmas.append(item.get('comment_nums',0)) parmas.append(item.get('fav_nums',0)) parmas.append(item.get('tags','')) parmas.append(item.get('content','')) parmas.append(item.get('create_date','1970-07-01')) self.cursor.execute(insert_sql,tuple(parmas)) self.conn.commit() return item class MysqlTwistedPipeline(object): def __init__(self,dbpool): self.dbpool = dbpool @classmethod def from_settings(cls,settings): dbparms = dict( host = settings['MYSQL_HOST'], db = settings['MYSQL_DBNAME'], user = settings['MYSQL_USER'], passwd = settings['MYSQL_PASSWORD'], charset = 'utf8', cursorclass = DictCursor, use_unicode = True ) dbpool = adbapi.ConnectionPool('MySQLdb',**dbparms) return cls(dbpool) def process_item(self,item,spider): query = self.dbpool.runInteraction(self.do_insert,item) query.addErrback(self.handle_error,item,spider) return item def handle_error(self,failure,item,spider): print(failure) def do_insert(self,cursor,item): insert_sql = """ insert into jobbole_article (title,url,url_object_id,front_image_path,front_image_url,paise_nums,comment_nums,fav_nums,tags,content,create_date) values (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s) ON DUPLICATE KEY UPDATE comment_nums=VALUES(comment_nums) """ parmas = list() parmas.append(item.get('title', '')) parmas.append(item.get('url', '')) parmas.append(item.get('url_object_id', '')) parmas.append(item.get('front_image_path', '')) front_image = ','.join(item.get('front_image_url', [])) parmas.append(front_image) parmas.append(item.get('paise_nums', 0)) parmas.append(item.get('comment_nums', 0)) parmas.append(item.get('fav_nums', 0)) parmas.append(item.get('tags', '')) parmas.append(item.get('content', '')) parmas.append(item.get('create_date', '1970-07-01')) cursor.execute(insert_sql,tuple(parmas)) class JsonWithEncodingPipline(object): ''' 自定义json文件的导出 ''' def __init__(self): self.file = codecs.open('article.json','a',encoding='utf-8') def process_item(self,item,spider): lines = json.dumps(dict(item),ensure_ascii=False) + '\n' self.file.write(lines) return item def spider_closed(self,spider): self.file.close() class ArticleImagePipeline(ImagesPipeline): def item_completed(self, results, item, info): if 'front_image_url' in item: image_file_path = '' for ok,value in results: image_file_path = value['path'] item['front_image_path'] = image_file_path return item -
common.py
# -*- coding:utf-8 _*- """ @version: author:weichao_an @time: 2021/02/03 @file: common.py @environment:virtualenv @email:awc19930818@outlook.com @github:https://github.com/La0bALanG @requirement: """ import hashlib def get_md5(url): if isinstance(url,str): url = url.encode('utf-8') m = hashlib.md5() m.update(url) return m.hexdigest() if __name__ == '__main__': print(get_md5('https://www.baidu.com')) -
main.py
# -*- coding:utf-8 _*- """ @version: author:weichao_an @time: 2021/01/29 @file: main.py @environment:virtualenv @email:awc19930818@outlook.com @github:https://github.com/La0bALanG @requirement: """ import sys import os from scrapy.cmdline import execute sys.path.append(os.path.dirname(os.path.abspath(__file__))) execute(['scrapy','crawl','jobbole'])
-
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/153129.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
