大家好,又见面了,我是你们的朋友全栈君。
一、资料推荐
爱丁堡大学课程(全英文,有能力的推荐学习一遍):https://speech.zone/courses/speech-synthesis/
TensorflowTTS(比较系统的开源项目):https://github.com/TensorSpeech/TensorFlowTTS
二、基础概念介绍
1、时域:波形的振幅、频率;
2、频域:
- 傅里叶变换:每个复杂的波形都可以由不同频率的正弦波组成;
- 语谱(spectrum):描述了信号包含的频率成分和它们的幅度;
- 语谱图(spectrogram):语谱随时间的变化,也称为频谱图;
推荐使用Adobe Audiotion工具来查看音频信息:
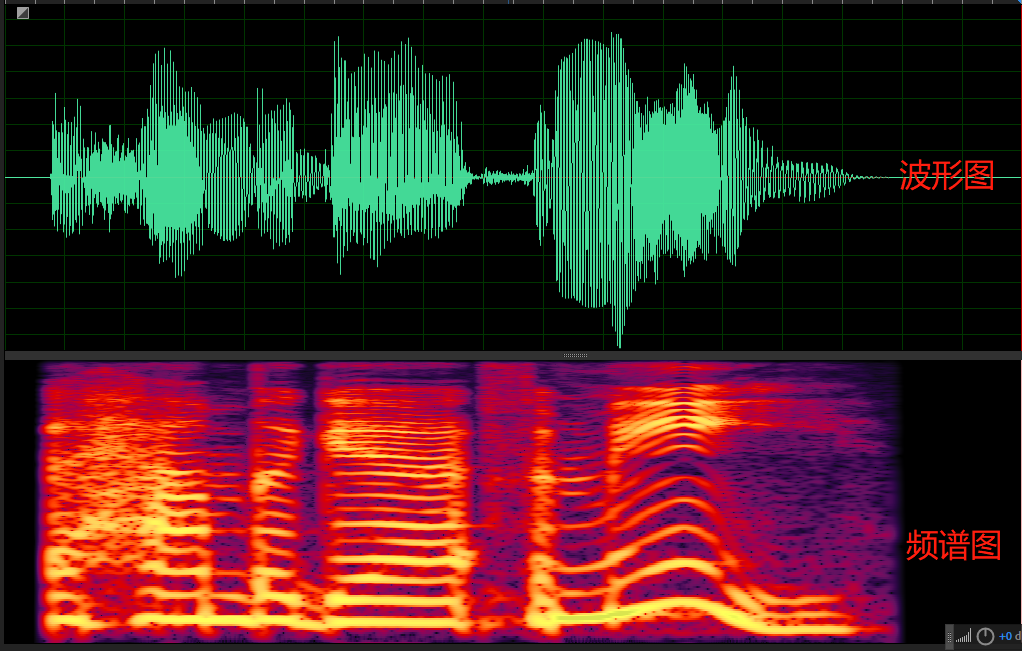

三、语音基本信息
思考一下,一段语音中包含了什么信息呢?
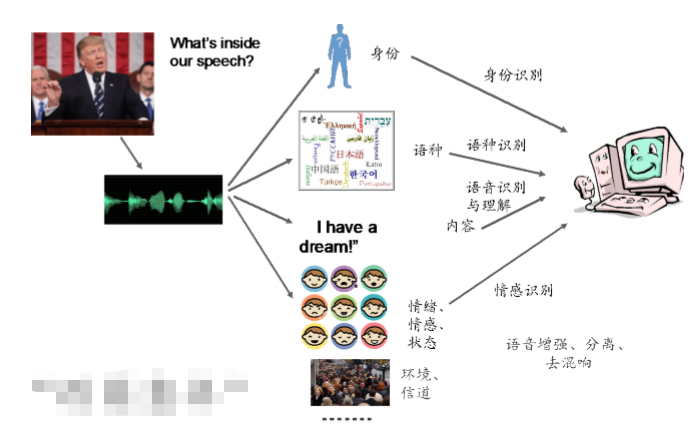
语音信息:发音人身份、语种、文本、情感、环境;
语音任务:身份识别、语种识别、语音识别、情感识别、语音增强分离等;
四、语音生成
一段语音的生成其实是音素的构成,下面介绍关于音素的一些概念:
1、音素:一种语言中语音的”最小”单元,在声学上也称为Phone;
2、IPA:国际音标,统一一套体系标注标准;
3、音节:元音和辅音结合构成一个音节;
4、协同发音:音素在声学上的实现和上下文强相关,往往我们需要采用上下文模型;
5、音素抄本:一段语音对应的音素列表(带或不带时间边界),时间边界可由人工标注或自动对齐获得,用于声学与时长模型,这里也是一种标注信息;
五、语音合成简述
1、热门研究方向
- 语音转换:说话人转换、语音到歌唱转换、情感转换、口音转换等;
- 歌唱合成:文本到歌唱的转换;
- AI虚拟人:可视化语音合成的技术,现在热门的元宇宙就依赖语音合成技术;
2、应用方向
- 语音交互:机器人领域、智能车;
- 内容生成:有声读物,微信听书等;
- 辅助功能:对障碍人士起到辅助功能,能够让他们发声;
3、难点
文字—>波形:
-
一到多且不等长的映射;
-
局部+全局依赖性;
评价指标:
- 只能根据听感来判断,有比较明显的主观性;
实际应用:
- 小样本(数据量少)
- 语音质量低,有噪声;
- 实时性和效果的平衡;
- 需要具有可控性且有表现力;
- 具备多语种、跨语言的能力(中英混合);
4、现代语音合成技术
端到端级的语音合成架构:
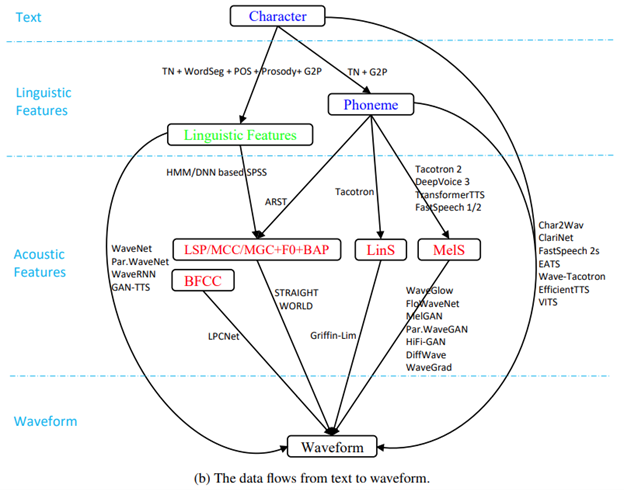
上述描述了当前主流的一些端到端级的语音合成方法组合,
当前的TTS主要架构:NLP + Speech Generation(文本分析到波形生成)
六、文本分析
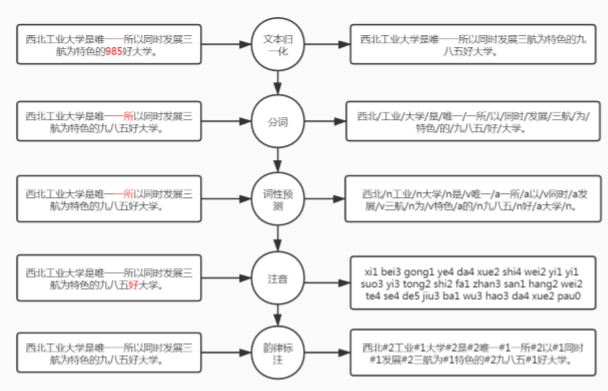
主要有以下几个方面处理:
- 断句:基于规则或基于模型来断句;
- 文本归一化(TN):消除非标准词在读音上的歧义,例如数字、缩写、符号等(基于规则或模型)
- 分词和词性标注:有时候分词错误会造成歧义;
- 注音:Grapheme to phoneme(G2P)也就是文本转音素,解决多音字、儿化音、变调问题;
- 韵律分析:Prosody(反映在能量、基频、时长上),句调、重读、韵律边界预测(停顿);
具体例子如下:
七、语音合成方法
1、波形拼接合成(单元选择合成)
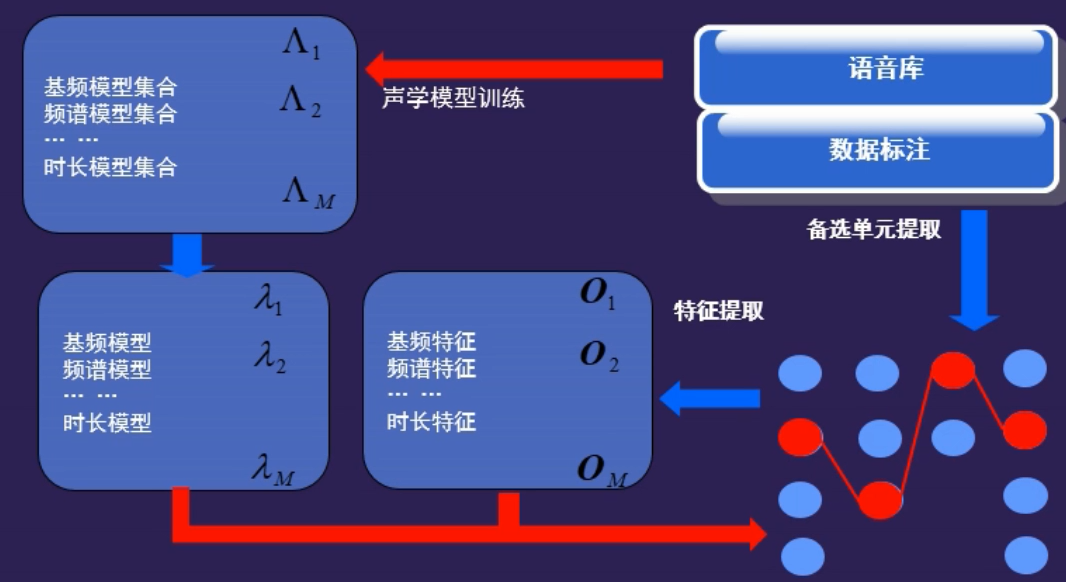
优点:高质量、高自然度;
缺点:需要大音库,一致性差,可控性差,通常只能在线使用;
原理:从音库中选择”最佳”路径上的单元进行拼接,使得目标代价和连接代价最低;
2、基于轨迹指导的拼接合成
方法:基于参数语音合成的轨迹指导单元合成;
优点:相对平滑和稳定的参数轨迹,又能保证比较自然的音质;
3、统计参数语音合成(SPSS)
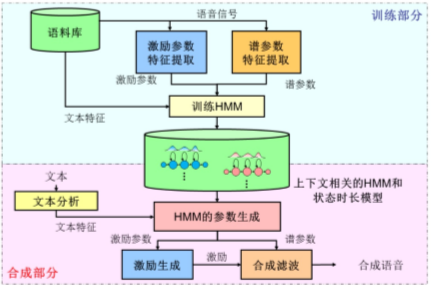
第一步是帧级的建模:
- 时长模型:音素序列 ——> 帧级文本特征;
- 声学模型:帧级文本特征 ——> 帧级语音输出;
第二步是训练数据:
- 利用语音识别强制对齐,得到音素帧级对应关系;
最常见的模型是基于HMM的SPSS:
优点:系统存储空间小,灵活度高(可参数调节),语音平滑流畅,适合离线、嵌入式设备;
缺点:合成语音音质受限,合成的韵律平淡;
实现步骤:
提参——训练数据帧级对齐——单音素HMM——三音素HMM——决策树聚类——优化
4、基于神经网络的语音合成
HMM存在问题:
利用上下文信息不足,决策树聚类对模型来说不够精细;
DNN优点:
神经网络能够拟合任何的函数映射,替代决策树模型,增加语音合成的表现力;
方案:将HMM替换为DNN,自然都得到一定的提升;
5、声码器
功能:提取语音参数,合成还原语音波形;
常见传统声码器:HTS、World等;
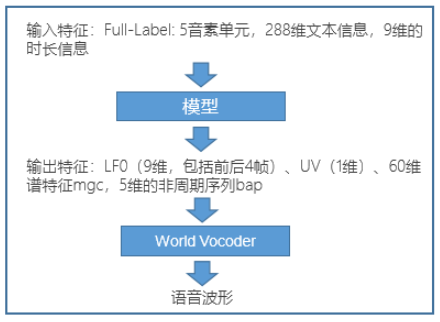
像一些基于神经网络的声码器将在后续进行介绍,相对来说传统声码器会造成一定损失,神经网络的声码器效果会好一些,但大小和耗时会更大;
6、端到端神经网络
定义:并不是完全端到端,是一套序列到序列(seq2seq)模型;
编码器——解码器架构:解决了对齐问题,但信息过度压缩;(M—>1—>N)
编码器——注意力机制——解码器架构:保留了全部编码信息,注意力机制是一种查表工具(M—>M—>N)
主流模型:Tacotron、Tacotron2、Transformer TTS
7、神经声码器
定义:利用神经网络强大的非线性拟合能力从语音特征转换为语音波形(采样点)
目前有两种主流方案:
① DSP+NN:传统信号处理和神经网络结合;
② GAN:生成效率很高,并且质量也不错;
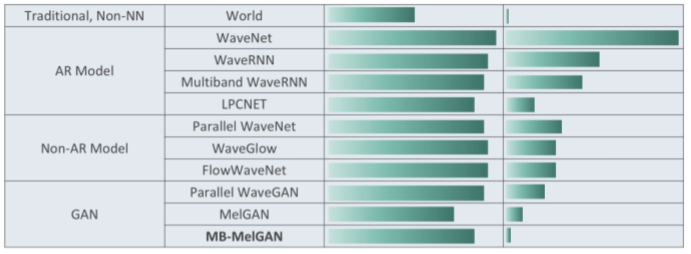
左边一列表示合成质量,右边一列表示合成成本,从图中来看,采用GAN的声码器效果和性能上比较好;
八、语音合成前沿探索
有以下几个热门研究方向:
1、小样本训练;
2、增加对情感等信息的可控性;
3、完全端到端;
4、抗噪;
5、语音转换;
6、唱歌合成;
九、语音合成评估
1、文本分析(前端)模块
主要关注以下一些客观指标
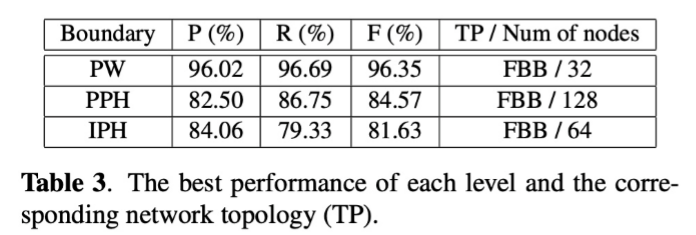
2、声学模型模型及声码器(后端)模块
主观指标:
- 从测试集考察语音的”还原度”;
- 从集外数据考察泛化能力,以及对场景的覆盖能力;
- MOS打分;
客观指标:
- 时间等长:用原始语音的单元时长,计算差异;
- 时间不等长:时间对齐,对局部差异求和;
十、语音合成语料库
对常见语料库总结如下图:
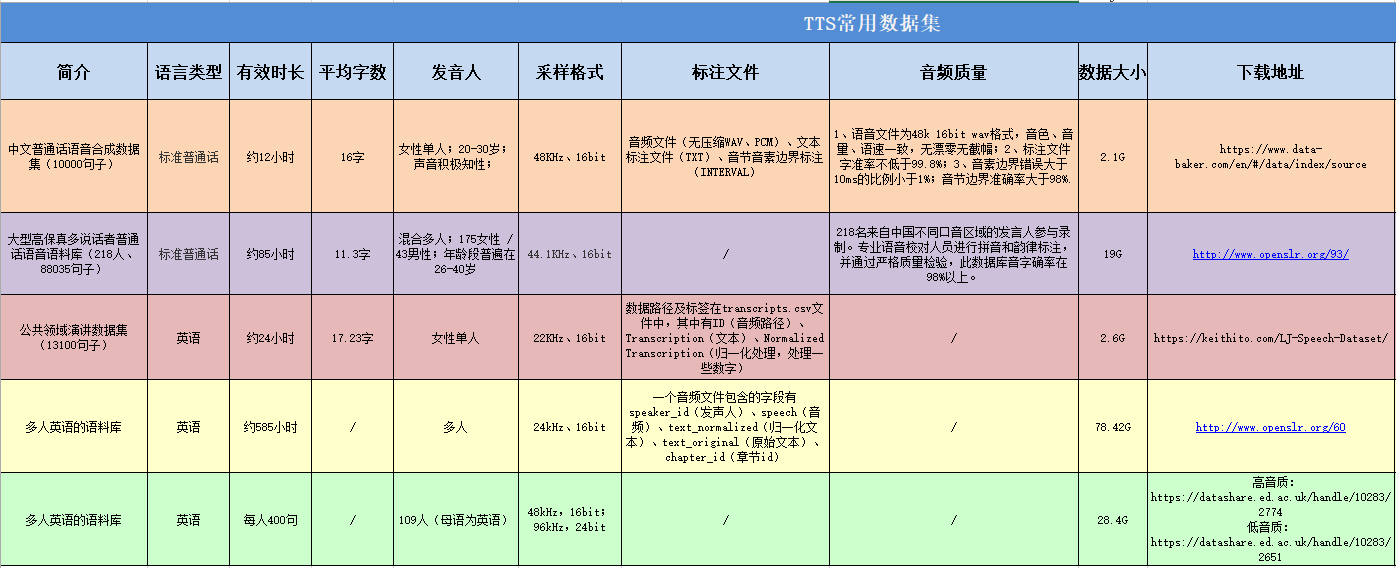
图中网址不太清楚,如有需要的可直接私信我;
总结
本篇是对语音合成的一个综述,实际上对于刚接触TTS领域的来说,对很多概念并不能完全理解;并且搜索引擎中对于语音合成的总结并不多,也由于TTS是比较小众的一个技术;通过本篇希望读者对于常见的概念,以及TTS的具体任务和发展有一定掌握;
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/153128.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
