大家好,又见面了,我是你们的朋友全栈君。
一:神经网络中的损失函数
cnn进行前向传播阶段,依次调用每个Layer的Forward函数,得到逐层的输出,最后一层与目标函数比较得到损失函数,计算误差更新值,通过反向传播逐层到达第一层,所有权值在反向传播结束时一起更新。
loss layer 是CNN的终点,接受两个Blob作为输入,其中一个是CNN的预测值,另一个是真实标签。损失层则将这两个输入进行一系列运算,得到当前网络的损失函数(Loss Function),一般记做L(θ)其中θ是当前网络权值构成的向量空间。机器学习的目的是在权值空间中找到让损失函数L(θ) 最小的权值θ(opt),可以采用一系列最优化方法(如SGD方法)逼近权值θ(opt)。
损失函数是在前向传播计算中得到的,同时也是反向传播的起点。
二:Softmax函数
假设有K个类别,Softmax计算过程为:
 其中,j=0,1,2,3,4,5,…,K-1
其中,j=0,1,2,3,4,5,…,K-1

下面图更直观:
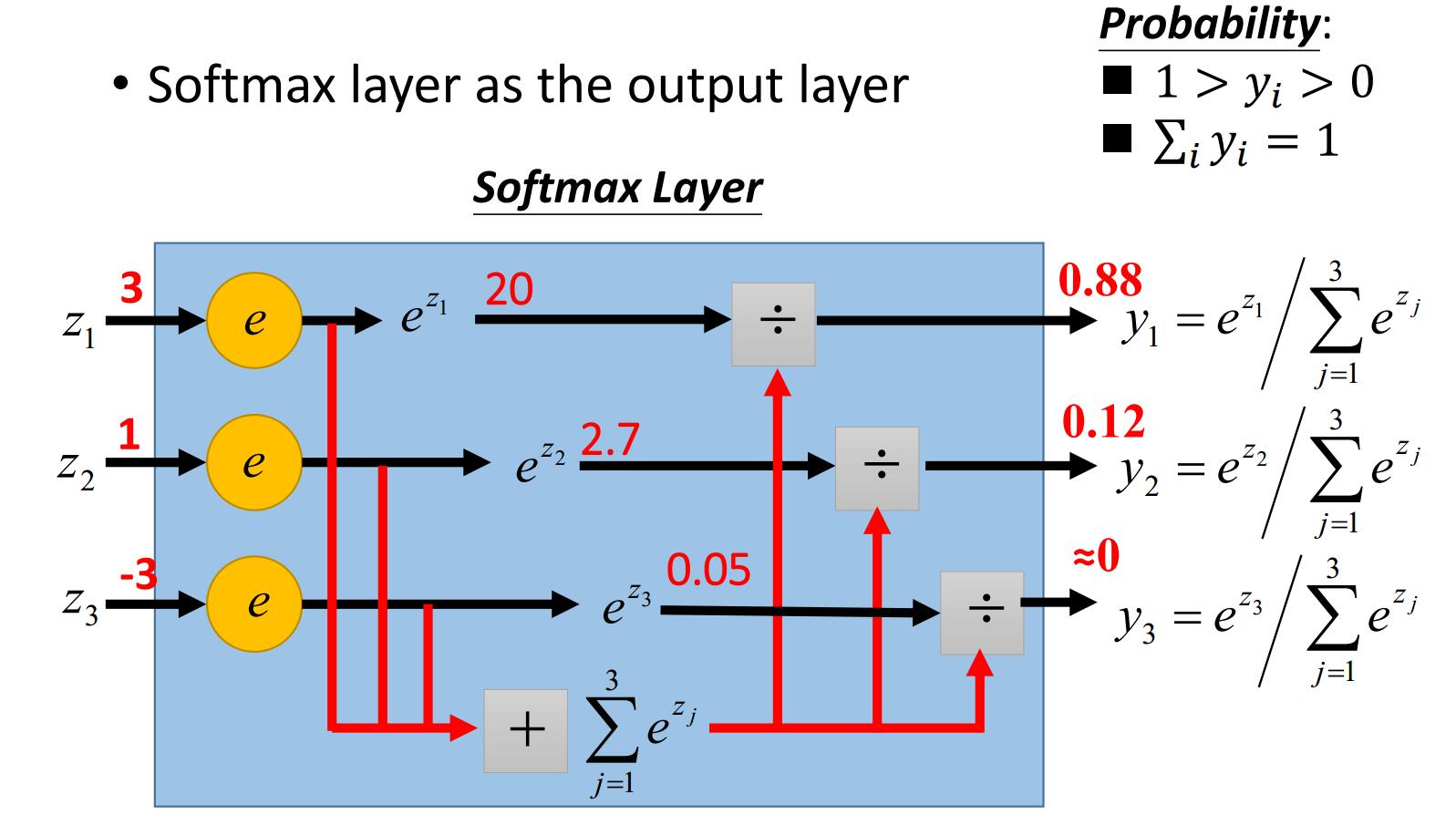
softMax的结果相当于输入图像被分到每个标签的概率分布,该函数是单调增函数,即输入值越大,输出也就越大,输入图像属于该标签的概率就越大。
神评论:SVM只选自己喜欢的男神,Softmax把所有备胎全部拉出来评分,最后还归一化一下
对softmax的结果计算交叉熵分类损失函数为:
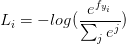
取log里面的值就是这组数据正确分类的Softmax值,它占的比重越大,这个样本的Loss也就越小,这种定义符合我们的要求.
三:wiki百科对softmax函数的定义:
In mathematics, the softmax function, or normalized exponential function,[1]:198 is a generalization of the logistic function that “squashes” a K-dimensional vector of arbitrary real values to a K-dimensional vector of real values in the range [0, 1] that add up to 1. The function is given by


-
for j = 1, …, K.

The softmax function is used in various multiclass classification methods, such as multinomial logistic regression,[1]:206–209 multiclass linear discriminant analysis, naive Bayes classifiers, and artificial neural networks.[2] Specifically, in multinomial logistic regression and linear discriminant analysis, the input to the function is the result of K distinct linear functions, and the predicted probability for the j‘th class given a sample vector x and a weighting vector w[further explanation needed] is:

This can be seen as the composition of K linear functions and the softmax function (where denotes the inner product of and ). The operation is equivalent to applying a linear operator defined by to vectors , thus transforming the original, probably highly-dimensional, input to vectors in a K-dimensional space .





注:
softmax函数的本质就是将一个K
维的任意实数向量压缩(映射)成另一个K维的实数向量,其中向量中的每个元素取值都介于(0,1)之间。
x,w 点积就是上图中Z1,Z2,Z3的计算。将高维的输入x转化一个K维的实数,即K类的各自的概率。
四:后记:
理想的分类器应当是除了真实标签的概率为1,其余标签概率均为0,这样计算得到其损失函数为-ln(1)=0.
损失函数越大,说明该分类器在真实标签上的分类概率越小,性能也就越差。
当损失函数接近正无穷时表明训练发散,需要调小学习速率。
在ImageNet-1000分类问题中,初始状态为均匀分布,每个类别的分类概率均为0.001,此时损失函数-ln(0.001)=ln(1000)=6.90775..,
当loss总在6.9左右时,说明没有训练收敛的迹象,尝试调大学习速率,或者修改权值初始化方式。
参考:
知乎
http://blog.csdn.net/u014422406/article/details/52805924
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/153113.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
