大家好,又见面了,我是你们的朋友全栈君。
文章目录
一、安装Scrapy
- Anaconda安装
如果你的python是使用anaconda安装的,可以用这种方法。
conda install Scrapy
- Windows安装
如果你的python是从官网下载的,你需要先安装以下的库:- lxml
- pyOpenSSL
- Twisted
- PyWin32
安装完上述库之后,就可以安装Scrapy了,命令如下:
pip install Scrapy
我是通过anaconda安装的python,Windows方法参考自崔庆才老师著的《Python3网络爬虫开发实战》
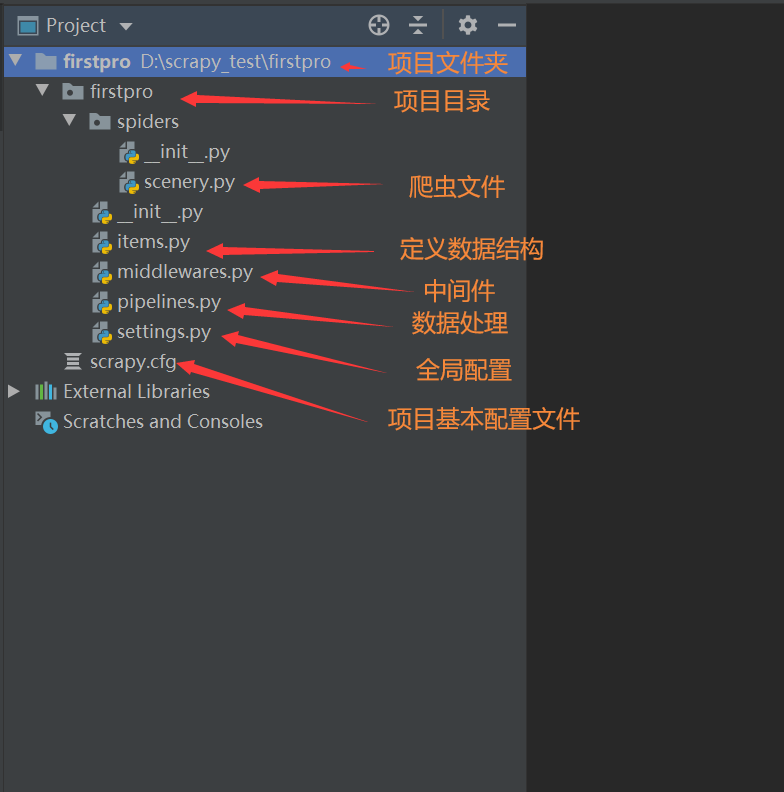
二、Scrapy项目生成
项目生成的位置是自己可以控制的,比如我是把项目放在了D盘的scrapy_test这个文件夹。
操作如下:
- win+R

- 点击确定,打开cmd
- 依次输入以下命令,便可以切换到自己想要的路径(需要根据自己的情况进行更改)
d: # 切换到D盘
cd scrapy_test # 切换到D盘的scrapy_test文件夹
- 输入命令
scrapy startproject 项目名,创建项目文件夹
示例如下:
scrapy startproject firstpro

- 切换到新创建的文件夹
cd firstpro
- 输入命令
scrapy genspider 爬虫名 爬取网址的域名,创建爬虫项目
示例如下:
scrapy genspider scenery pic.netbian.com

- 至此,一个scrapy项目创建完毕。
三、爬取壁纸图片链接
1、修改settings文件
打开settings.py
- 修改第20行的机器人协议
- 修改第28行的下载间隙(默认是注释掉的,取消注释是3秒,太长了,改成1秒)
- 修改第40行,增加一个请求头
- 修改第66行,打开一个管道
详细修改内容如下:
ROBOTSTXT_OBEY = False
DOWNLOAD_DELAY = 1
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent':'Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.94 Safari/537.36'
}
ITEM_PIPELINES = {
'firstpro.pipelines.FirstproPipeline': 300,
}
2、写item文件
打开items.py
我准备爬取的内容为每张图片的名称和链接,于是我就创建了name和link这两个变量。
Field()方法实际上就是创建了一个字典。
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class FirstproItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
name = scrapy.Field()
link = scrapy.Field()
pass
3、写爬虫文件
打开scenery.py(打开自己的爬虫文件,这里以我的为例)
import scrapy
from ..items import FirstproItem
class ScenerySpider(scrapy.Spider):
name = 'scenery'
allowed_domains = ['pic.netbian.com']
start_urls = ['https://pic.netbian.com/4kfengjing/'] # 起始url
page = 1
def parse(self, response):
items = FirstproItem()
lists = response.css('.clearfix li')
for list in lists:
items['name'] = list.css('a img::attr(alt)').extract_first() # 获取图片名
items['link'] = list.css('a img::attr(src)').extract_first() # 获取图片链接
yield items
if self.page < 10: # 爬取10页内容
self.page += 1
url = f'https://pic.netbian.com/4kfengjing/index_{str(self.page)}.html' # 构建url
yield scrapy.Request(url=url, callback=self.parse) # 使用callback进行回调
pass
-
构建url
第二页链接:https://pic.netbian.com/4kfengjing/index_2.html
第三页链接:https://pic.netbian.com/4kfengjing/index_3.html
根据第二第三页的链接,可以很容易的看出来,变量只能index_处的数字,且变化是逐次加1的规律。 -
css选择器
scrapy的选择器对接了css选择器,因此定位元素,我选择了css选择器。::attr()是获取属性;extract_first()是提取列表的第一个元素。
4、写pipelines文件
打开pipelines.py
在pipeline,我们可以处理提取的数据。为了方便,我选择直接打印。
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class FirstproPipeline:
def process_item(self, item, spider):
print(item)
return item
5、执行爬虫项目
在cmd(好久没用了,应该没关掉吧)中输入命令scrapy crawl 爬虫名。
以我的作为示例:
scrapy crawl scenery
这样是不是有点麻烦,而且生成的结果在cmd中,观感很差。
优化方案
在spiders文件夹中新建run.py文件(名称随意哈),输入代码(如下),执行run.py文件即可。
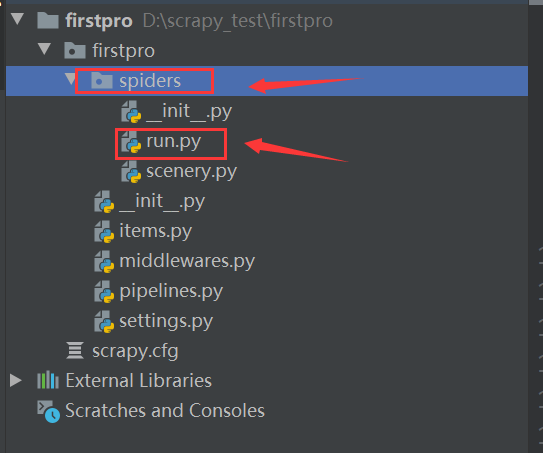
from scrapy import cmdline
cmdline.execute('scrapy crawl scenery'.split()) # 记得爬虫名改成自己的
输出结果:
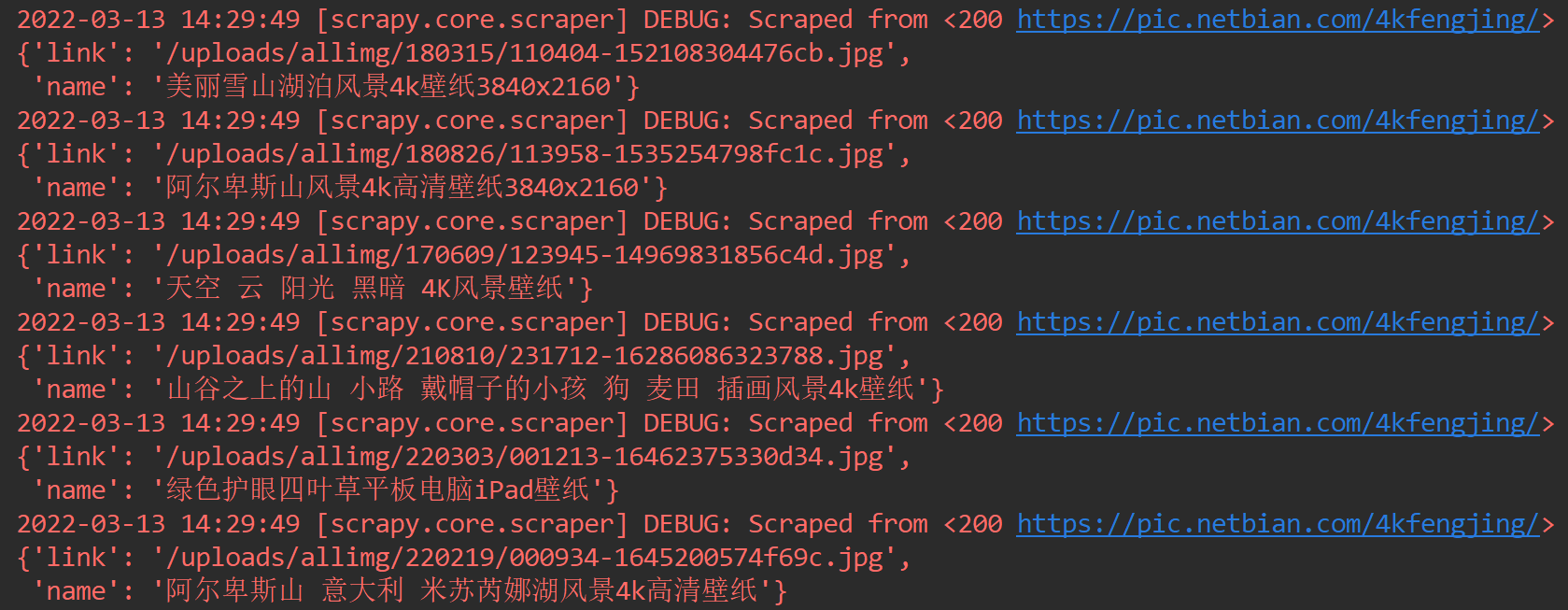
咱就是这观感,是不是比在cmd中好得不要太多。
四、未来可期
文章到这里就要结束了,但故事还没有结局
如果本文对你有帮助,记得点个赞?哟,也是对作者最大的鼓励?♂️。
如有不足之处可以在评论区?多多指正,我会在看到的第一时间进行修正
作者:爱打瞌睡的CV君
CSDN:https://blog.csdn.net/qq_44921056
本文仅用于交流学习,未经作者允许,禁止转载,更勿做其他用途,违者必究。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/153112.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
