大家好,又见面了,我是你们的朋友全栈君。
之前的博客有介绍过R和Geoda计算莫兰指数的方法,考虑到有时候我们需要自定义空间权重矩阵来计算莫兰指数,那以上两种方法显得有点复杂。所以,今天来分享Stata计算莫兰指数的方法~
一、数据准备
1.1 数据导入
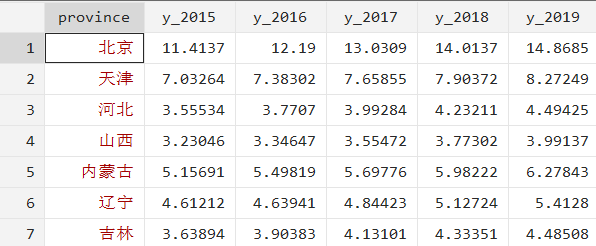
本次案例使用的数据为15-19年全国的人均GDP,数据图如下:

Stata中导入数据的方式十分便捷,通常可以分以下两种:
- 打开数据编辑器,直接将excel数据复制粘贴即可
- 当有dta文件时,可在命令行输入
use dta文件地址(例如,dta文件在D盘,则使用use "D:/data.dta"即可导入)
1.2 程序包下载
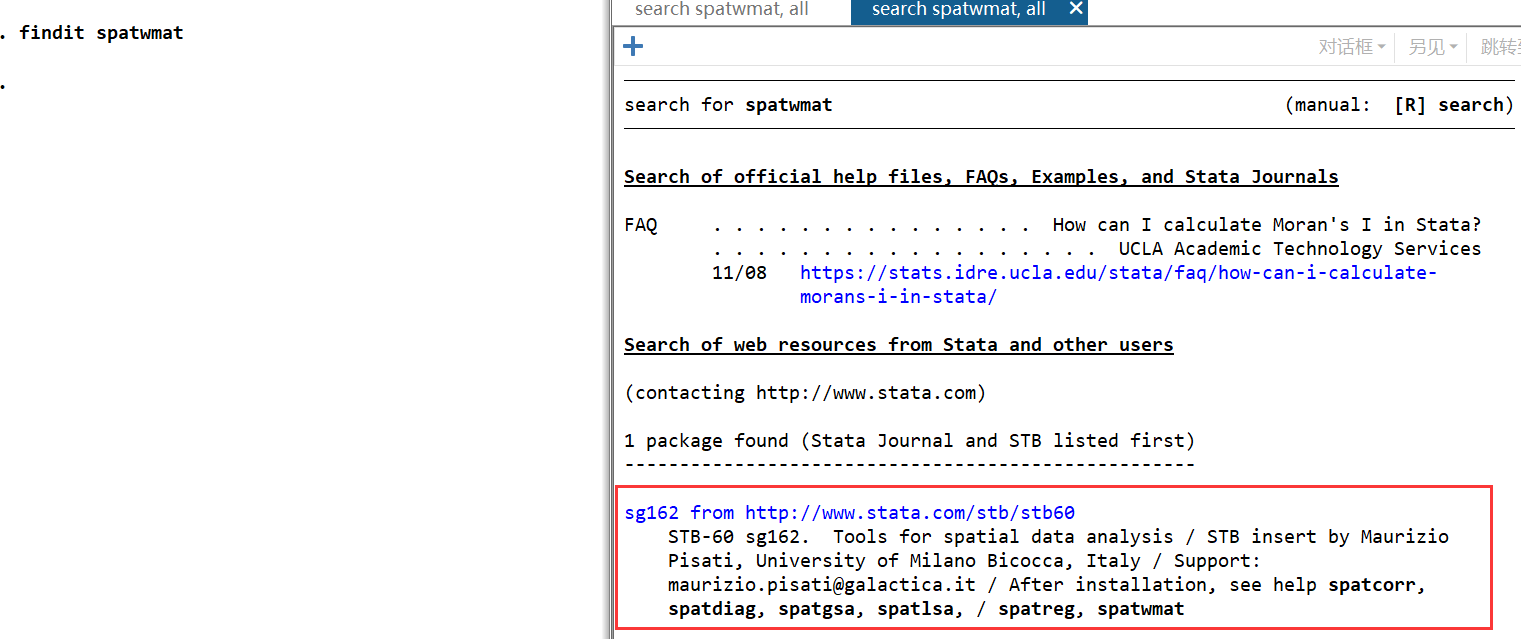
莫兰指数计算的相关程序包需要预先下载,在命令行输入findit spatwmat后,点击sg162程序包即可
二、导入权重矩阵
主要命令如下,注意using后没有引号,standardize表示行标准化
spatwmat using d:/weight.dta,name(W) standardize

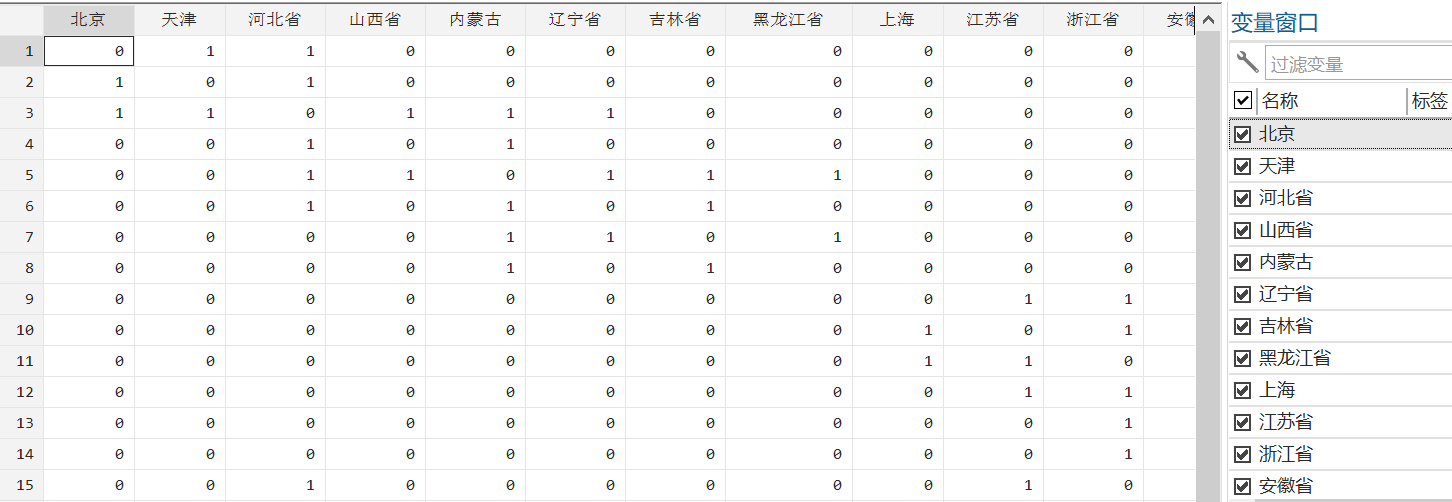
权重数据文件需自行构造,示例图为邻接矩阵样例
注意点:
- 不同于excel中权重矩阵的格式,Stata中第一列是没有省份列的,否则后续程序会报错!
- 权重矩阵文件里的省份顺序需要和数据文件的省份顺序保持一致例如,各省份人均GDP数据文件是按照北京、天津、…、新疆顺序来的,对应的权重矩阵也应是该种排序。
- Geoda和R主要通过shp文件构建权重矩阵,而Stata可以自行构建dta文件。因此,也更加适合导入自定义权重矩阵。
三、莫兰指数计算
3.1 全局莫兰指数计算
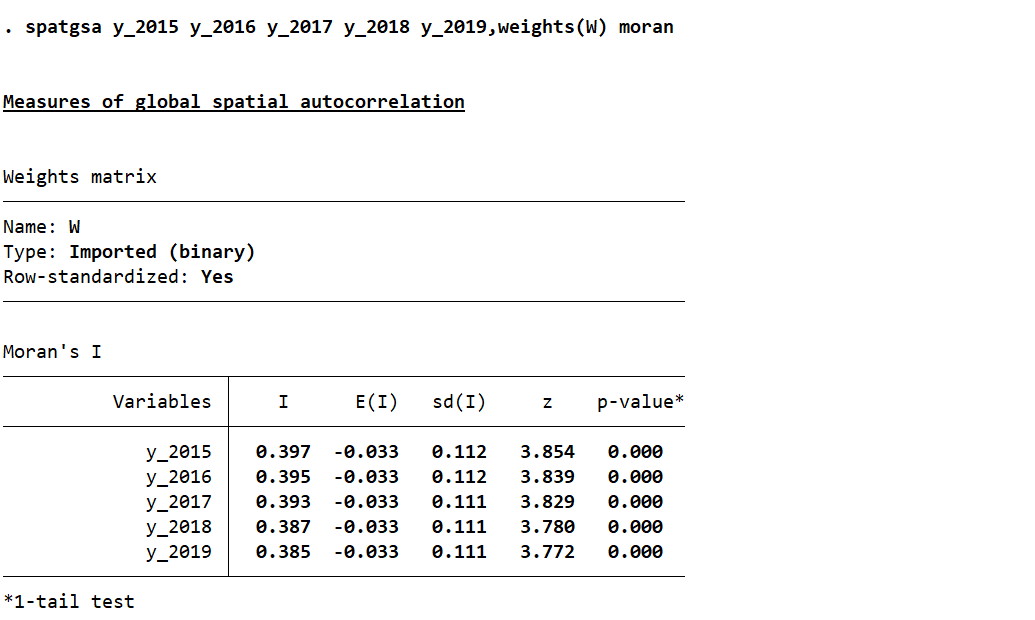
以邻接矩阵W,计算15-19莫兰指数
spatgsa y_2015 y_2016 y_2017 y_2018 y_2019,weights(W) moran
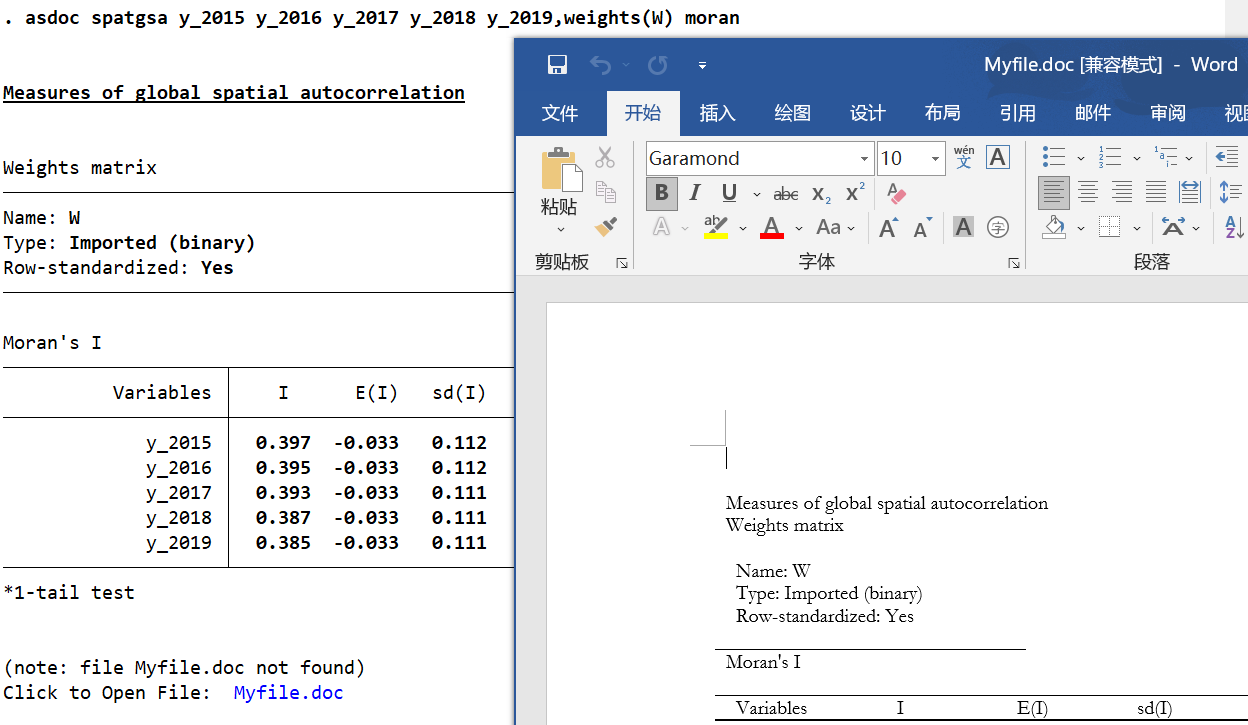
如果想一键将结果生成表格,可使用asdoc+命令,即可将结果输入word中,如下图所示(asdoc需通过ssc install asdoc安装)
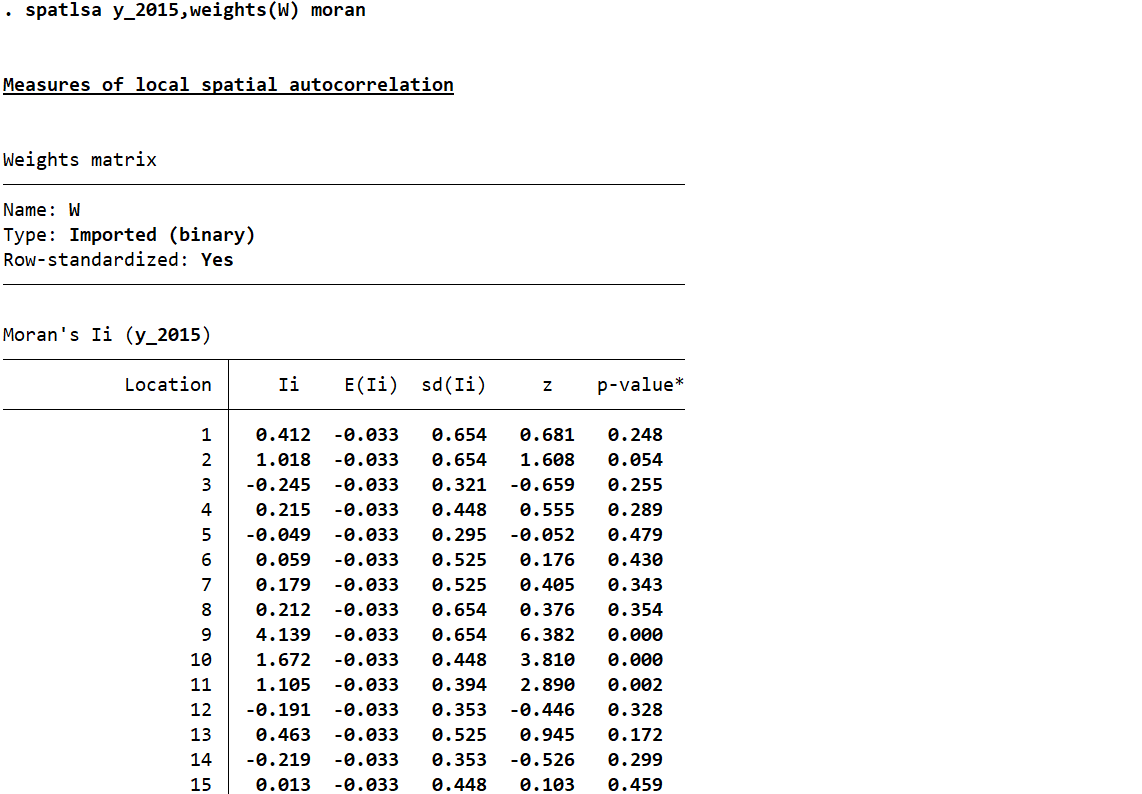
3.2 局部莫兰指数计算
#熟悉stata编程的朋友,这里可以用循环代替
spatlsa y_2015,weights(W) moran
spatlsa y_2016,weights(W) moran
spatlsa y_2017,weights(W) moran
spatlsa y_2018,weights(W) moran
spatlsa y_2019,weights(W) moran
四、莫兰指数图
spatlsa y_2015 ,weight(W) moran id(province) graph (moran) symbol(id)
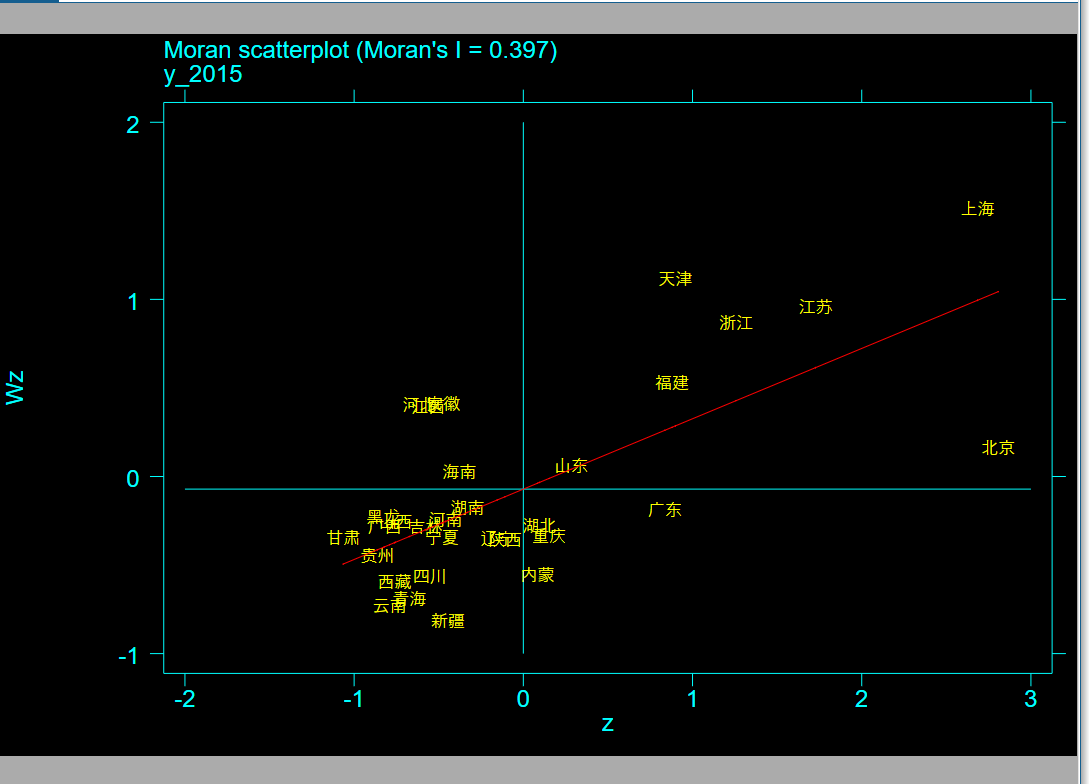
该图在stata中背景显示是黑底,复制到word中是透明的
全部代码
findint spatwmat #安装程序包
spatwmat using d:/weight.dta,name(W) standardize #导入权重矩阵
spatgsa y_2015 y_2016 y_2017 y_2018 y_2019,weights(W) moran #计算Global moran'I
spatlsa y_2015,weights(W) moran #计算local moran'I
spatlsa y_2015 ,weight(W) moran id(province) graph (moran) symbol(id) #带汉字的moran'I
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/153076.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
