大家好,又见面了,我是你们的朋友全栈君。以前写文章的时候,有些过于草率,本来以为作为科普,把这个名词告诉大家就可以了,结果应该是这个东西国内的科普性文章太少,很多同学都拿来做入门读物了,而且还多次阅读,读着读着,就发现,虾神你文章里面好多坑啊……该说的没有说清楚,关键还有很多说错的地方……
每次遇见这种情况,我都想这样:

不过装死是不能解决问题的……

正所谓“教然后知不足”,这段时间以来很多同学跟我讨论了关于空间统计的一些内容,让我很受启发和教育,所以我决定把一起的一些漏洞和坑给补上。
今天再来谈谈莫兰指数这个空间统计的入门概念。
还有同学问过,说虾神你能不能说说在ArcGIS里面怎么用这个工具啊。。。遇见这个问题的时候,虾神首先表示:

不过既然同学们有要求,那就写写呗。
人类天然有归纳的习惯,比如看见一堆东西之后,会用很简单的一个字(词、句)来统合表达对整体的一个印象,比如:
我们会说:“帅”!或者“酷”!或者“威武”!

又另外:
对于三哥的阅兵。。。米帝大统领也给出了一个字评语:赞……

所以,对于一票数据,我们首先也会给出一个综合性的评论。比如“这数据真尼玛的乱”。。。当然,这种评论更多是“定性”的,对于科学观测法来说,我们要给出一个量化的评定标准,所以就有了各种指数。
那么这个所谓的莫兰指数,就是用来衡量空间自相关的程度的一个综合性评价——特指全局莫兰指数。
关于空间自相关,我以前也写过一篇文章,大家有兴趣就去翻历史文章吧,这里仅作简单的回顾。其实空间自相关要是把空间两个字去掉,就是经典统计学里面的相关性分析,加上空间之后,就变成了空间与属性共同作用的相关性分析了。
自相关的这个“自”,表示你进行相关性观察统计量,是来源于不同对象的同一个属性,比如两学生(不同对象),同时对他们的数学成绩(统一属性)进行统计,如果他们同桌(空间邻接),而且A考得好B就考得好,A考不好B也考不好(高端相关),那么基本上就可以判定他们他们的空间自相关性很强——有考试串通作弊的行为。如下图所示:
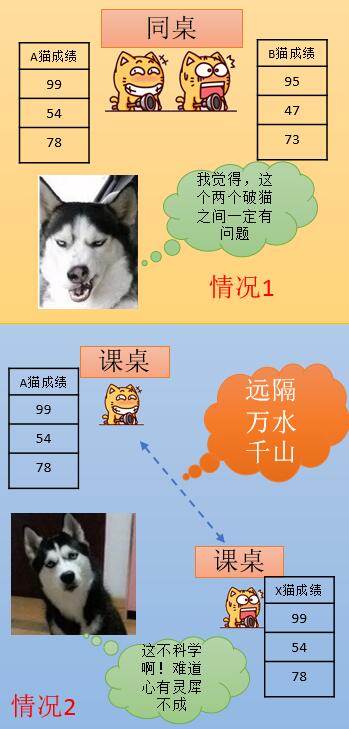
所以我们可以看见,如果排除空间关系,A猫和B猫,以及情况2得A猫和X猫,都是相关的,特别是情况2,A猫和X猫简直是完全相关。
但是加上空间关系之后,情况2计算出来的A猫和X猫,可能就是完全不相关了,最最关键得是定义他们的空间关系,这个远隔万水千山,也顶不住现代化通信工具啊……这里排除这种情况,仅仅用常规意义上的空间邻接关系来定义。
所以说,经典相关性分析是两条数据(属性维度)之间的相互依赖关系,那么空间自相关就是在空间范围内的相互依赖程度。
全局的莫兰指数就是用来衡量空间自相关程度的。在ArcGIS的工具集里面,这个工具干脆就直接叫做“空间自相关”(Spatial Autocorrelation (Global Moran’s I) )。
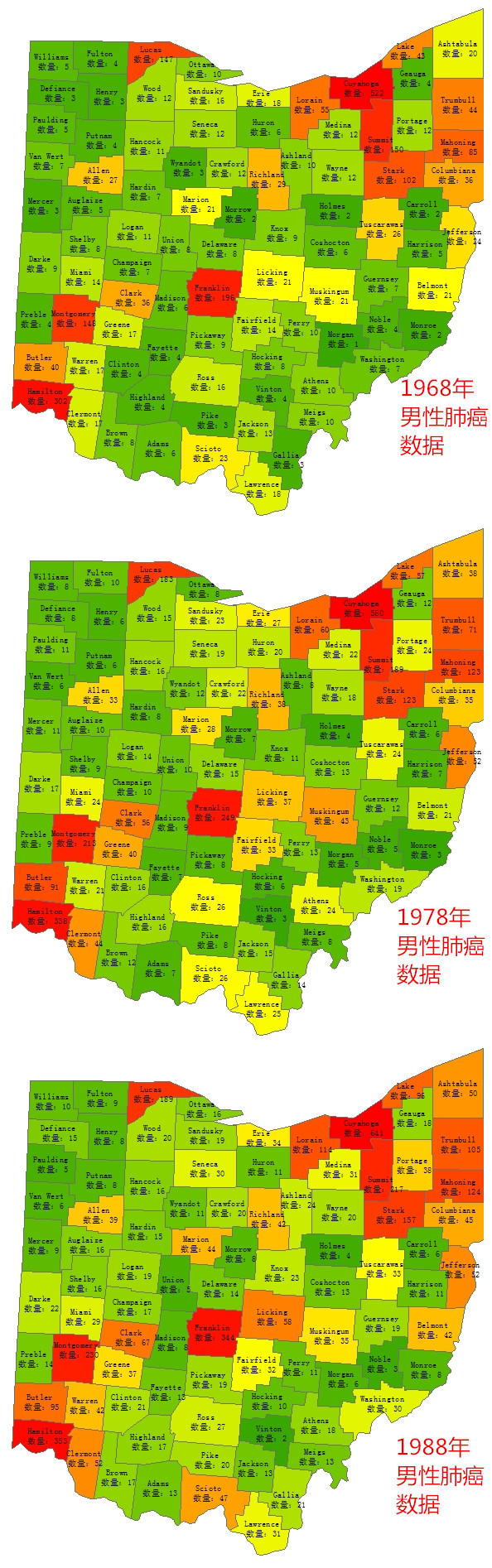
使用这个工具,首先来看一份数据,美国俄怀明州有关肺癌的一份统计数据,分别选取是68年、78年、88年三个年度的男性肺癌的记录进行可视化,(以下数据可以提供下载,见文章最后):
从整体的情况来看,数据量是在不断上升的,当然,人口在增长,病患的数据也相应增长,是合乎情理的事情。
那么接下,我们可以来计算一下空间自相关,空间自相关解释什么东西呢?解释的是,这些病患的数据,是否与空间分布又关系?也就是说,一个县本身的肺癌病患数量,是否与他周边的县的肺癌病患数量有关?这种判定,需要同时从空间上和属性上来判定。
全局莫兰指数是一个在-1——1之间的数,如下所示:
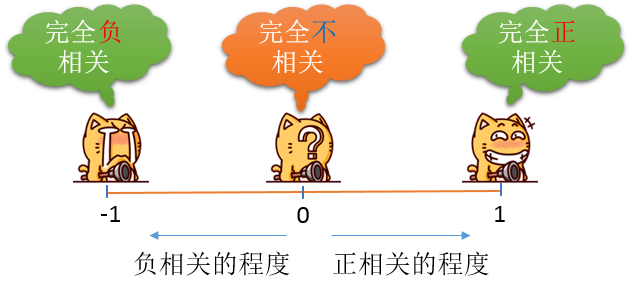
当然,解读的时候,还需要有P值和Z得分来判定,P值和Z得分的相关内容,也请看以前写过的博客。
在ArcGIS中,工具在如下位置:Spatial Statistics Tools —— Analyzing Patterns —— Spatial Autocorrelation(Moran’s I)
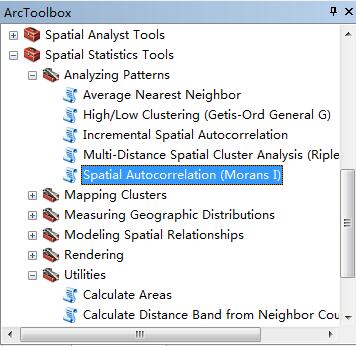
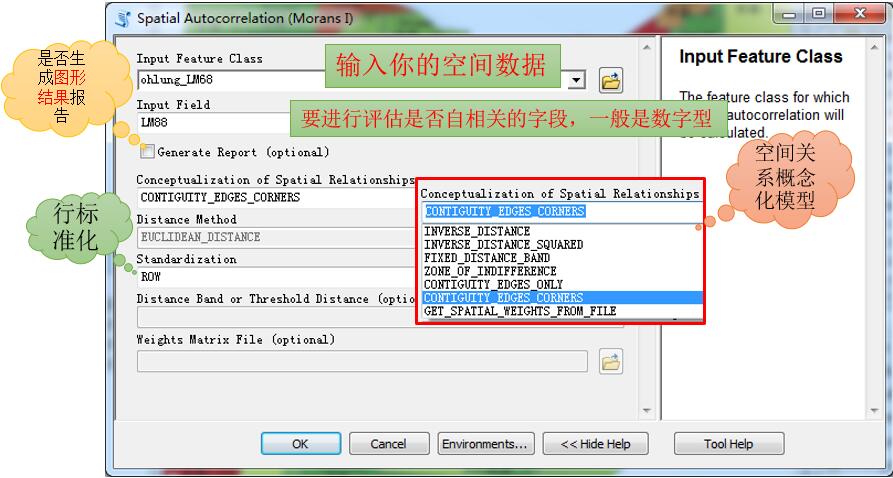
打开之后,相关参数说明如下:
这里空间关系概念化我选择了CONTIGUITY_EDGES_CORNERS,也就是所谓的Queen’s Case,共边共点都被视为邻接要素。这个参数的选择非常重要,一定要注意选择。
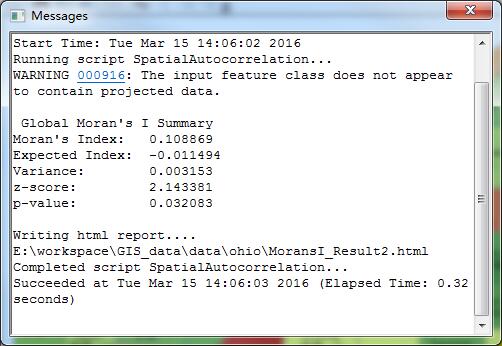
然后计算如下,如果不勾选生成图形结果报告,直接会弹出以下计算结果:
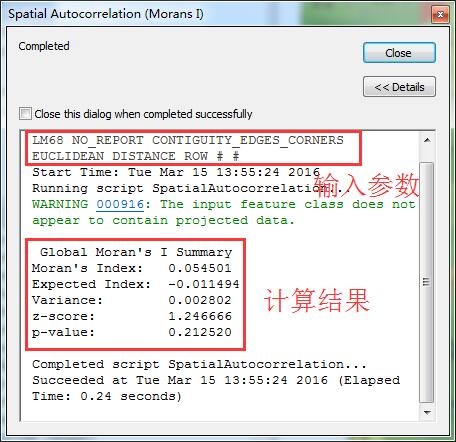
很容易看出:P值大于0.05的95%置信度,而且Z得分也没有过1.65这个临界值,也就说这个数据偏向于随机了……剩下的结果基本上不用读,解读的方法,请大家看以前写P值和Z得分。
当然,如果你勾选了生成图形结果报告,还会生成一个html的页面,如下:
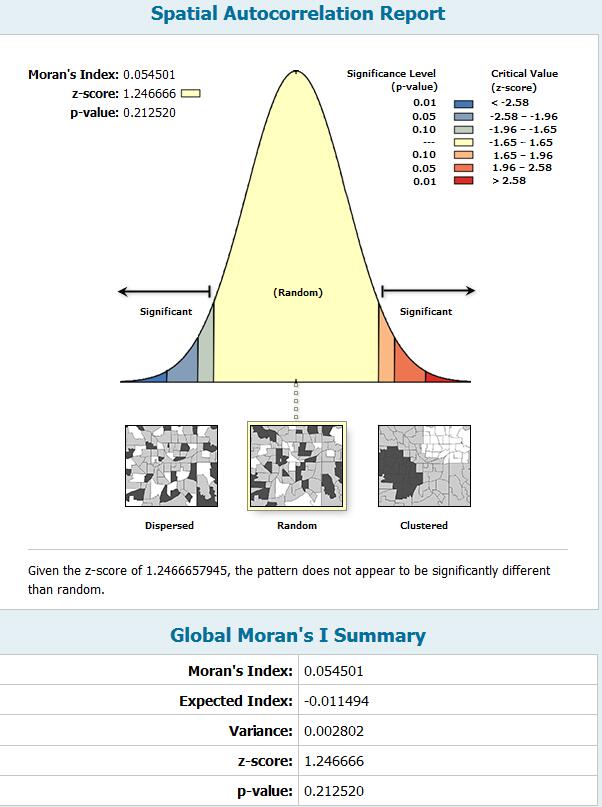
这个报告就直接告诉,你的Z得分没有过临界值,所以数据显著的表现出了随机模式……
我们依次把78年、88年的数据都计算完成,计算结果如下:
1978年:
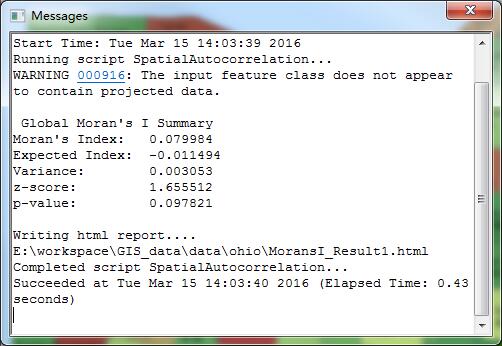
1988年:
生成的图形报告如下:
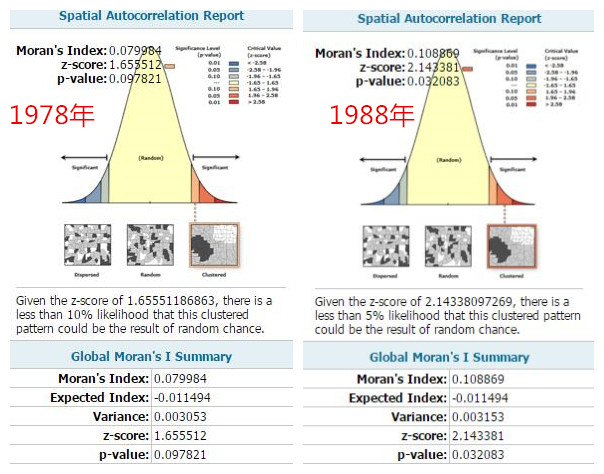
1978的数据刚刚跨过了1.65的临界值,所以系统告诉我们,这份数据仅有小于10%的可能是随机创建的;而1988年,Z得分是2.14,这份数据仅有小于5%是随机的可能,如果按照费希尔爵士对于拒绝零假设设定的阈值来看,只有1988年的数据拒绝了零假设,有显著的聚类和空间正相关的可能性。这可能性大于95%。
通过以上分析,最后我们就可以编写分析报告了,数据分析人员很喜欢找一些自以为是的理由,这是一个很不好的习惯,虾神的个人建议是,如果写分析报告,最好就直接进行现象描述:
数据说明:美国俄怀明州男子肺癌数据全局空间自相关计算结果。
1968年,数据分布出现显著的随机分布特性,无法拒绝零假设,无分析价值。
1978年,数据分布仅有小于10%的可能是随机分布的,出现数据聚集的可能性大于随机分布的可能性,但是不能显著的拒绝零假设。
1988年,数据分布仅有小于5%的可能是随机分布的,出现数据聚集的可能性大于随机分布的可能,且能够显著的拒绝零假设。此结果表示1988年,俄怀明州男子肺癌数据的空间分布,出现一定的聚集特征,且具有空间正相关模式。
最后给出数据下载地址:
http://pan.baidu.com/s/1i4qPnt7
里面各字段的数据在文件包中有个txt文档进行描述,另外数据本身没有进行投影,而且也没有显著空间参考,是无法和标准地图叠加在一起的,仅供大家学习测试使用。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/153061.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
