大家好,又见面了,我是你们的朋友全栈君。
引言
现实生活中,字符串匹配在很多的应用场景里都有着极其重要的作用,包括生物信息学、信息检索、拼写检查、语言翻译、数据压缩、网络入侵检测等等,至此诞生了很多的算法,那么我们今天就来探索这两种经典的算法。
一、概念分析
首先我们需要了解到什么是kmp算法和strstr函数
概念如下:KMP算法是一种改进的字符串匹配算法,由D.E.Knuth,J.H.Morris和V.R.Pratt提出的,因此人们称它为克努特—莫里斯—普拉特操作(简称KMP算法)。KMP算法的核心是利用匹配失败后的信息,尽量减少模式串与主串的匹配次数以达到快速匹配的目的。具体实现就是通过一个next()函数实现,函数本身包含了模式串的局部匹配信息。(来自百度百科)strstr(str1,str2) 函数用于判断字符串str2是否是str1的子串。如果是,则该函数返回 str1字符串从
str2第一次出现的位置开始到 str1结尾的字符串;否则,返回NULL。(来自百度百科)
分析
在这里我们很明显的看到,strstr作为最原始的算法,他的最差时间复杂度为O(len(s)*len(t)),效率是非常的低下的,而经过改良优化后的kmp算法则为O(m+n),两者进行一对比发现差距真的很大,而且kmp算法算然把字符串遍历了一遍,但如果不遍历一遍,怎么可能匹配的出来呢?
原理分析
对比发现,strstr函数对整个母串和字串都进行了多次的遍历,做了很多的重复工作,浪费了一些我们已经知道的信息,直接导致了时间的消耗,大大的降低了效率。例如,一个长度为9的t字符串abcdabcad,字串s为abca,当我们的指针走到t[4]的时候,发现匹配失败,此时s位置的指针已经走到了s[3]的位置,又得重新回到s[0],继续和t[4],进行匹配,重复此步骤,直到遍历完字符串t为止。这样子的话,重复匹配了s的字符n多次,所以效率极低。
strstr代码如下:
size_t Find(const char* str, size_t pos = 0) const
//(两个指针,字串和父串从第一个开始字符匹配,如果第一个字符匹配后,
//开始逐个字符串匹配到最后一个,中途若有不同,字串退回开始,父串不变,继续重复操作,直至找到为止)
{
if (pos > _size)
{
cout << "pos位置有误报<<endl";
}
size_t index_str = 0;
//若循环条件退出,要么找到了,要么找到结尾也没找到
while (_str[index_str] != '\0')
{
if (_str[index_str] == *str)//从开头开始匹配字符
{
size_t Find_index = index_str;
size_t str_index = 0;
while (1)
{
//如果遍历完了str没有停下来,就表示找到了
if (str[str_index] == '\0')
{
return index_str;
}
//如果不相等就结束循环
if (_str[Find_index] != str[str_index])
{
break;
}
Find_index++;
str_index++;
}
//跳出循环
}
//不匹配继续向前找
index_str++;
}
return -1;
}
KMP算法原理
基本操作
-
我们要明白一个定义是next数组,这里就用到了一个相当重要的预处理思想,在我们不能直接求解问题的时候,我们可以先生成一个预处理数组用来记录我们一些信息。
这个思想很关键,很重要。 就是一个字符串中最长的相同前后缀的长度加一, 例如字符串abcabcabc。
那么它的next[1]一直到next[9],计算的是’a’, ‘ab’, ‘abca’, ‘abcab’,
一直到’abcabcabc’相同的最长前缀和最长后缀,加一。前缀的意思是不能包含最后一个字符,后缀就是不能包含第一个字符。比如’a’,最长前后缀长度为0,原因上面刚说了,不包含。 “abca”最长前后缀长度为1,即第一个和最后一个。 “abcab”最长前后缀长度为2,即ab “abcabc”最长前后缀长度为3,即abc “abcabca”最长前后缀长度为4,即abca “abcabcabc”最长前后缀长度为6,即abcabc
图解
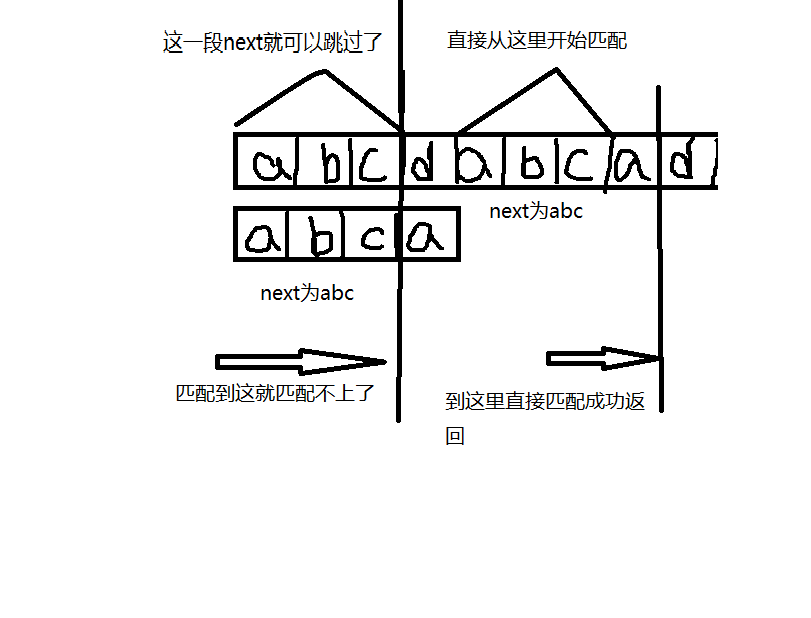

KMP原理
可能有人会想,为啥我们敢跳过那段长度为next的距离呢,再来一个图解。
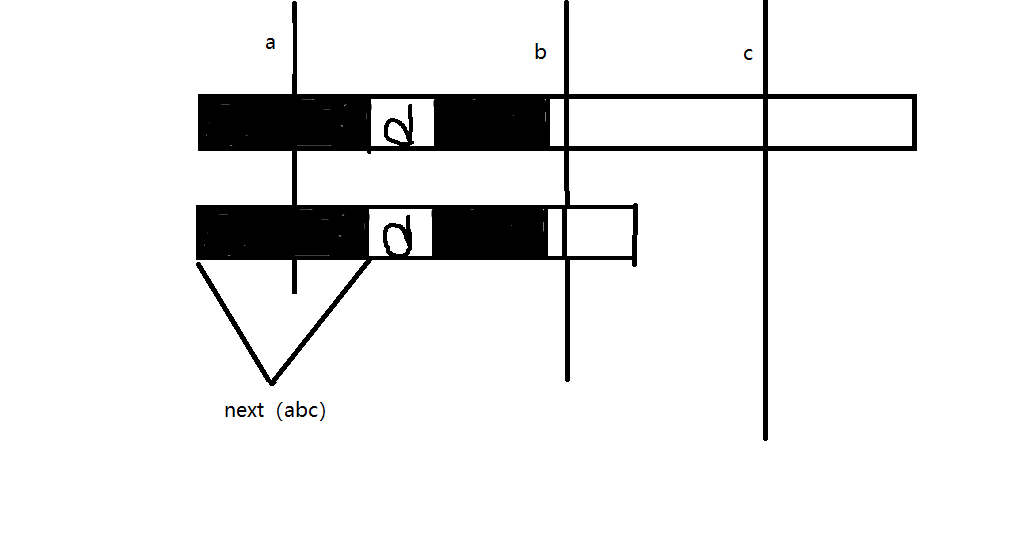
竖线叫abc吧。
- 主串叫t,子串交s 请看ab线中间包含的t中的子串,它在t中是一个以s[0]为开头,比黑块更长的前缀。
请看ab线中间包含的t中的子串,它在t中是一个以b线前一个元素为结尾,比黑块更长的后缀。
请回想黑块定义:这是目前位置之前的子串中,最长的相同前后缀。 请再想一想我们当初为什么能配到这里呢?
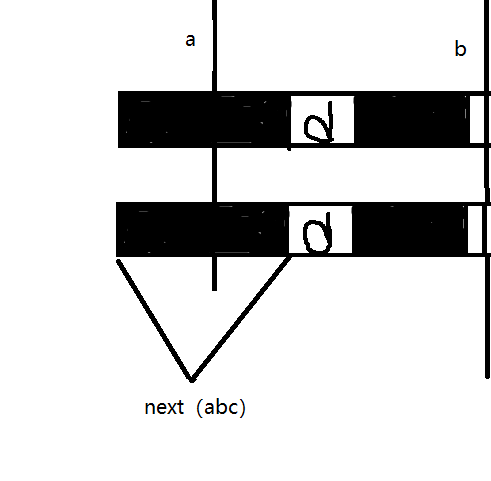
- 这个位置之前,我们全都一样,所以多长的后缀都是相等的。其实就是,主数组后缀等于子数组后缀,而子数组前缀不等于子数组后缀,所以子数组前缀肯定不等与主数组后缀,也就是说,当前位置肯定配不出来这是比最长相同前后缀更长的前后缀啊兄弟。。。所以肯定不相等,如果相等,最长相同前后缀至少也是它了啊。有可能我的语言表达的不是很清晰,但是看着图解或许能更清楚一些。
三、复杂度分析
- 时间复杂度是一个算法最为关键的性质,那么一起看一下这两者的时间复杂度对比,KMP在父串上的指针,两种情况,要么配了头一个就不对,就往后走了,这时用O(1)排除了一个位置。要么就是,配了n个位置以后配不对了,那不管next数组是多少,主串上的指针总会向后走n个位置的,所以每个位置还是O(1),这样看来,主串长度是len的话,时间复杂度就是O(len)啊。再看next数组求解的操作,一样的啊,最多就是子串的长度那么多。所以总体时间复杂度O(m+n),原来是O(m*n),这是一种非常聪明的方法,难怪可以称之为经典。
四、KMP算法代码
#define _CRT_SECURE_NO_WARNINGS 1
#include <iostream>
#include <cstring>
using namespace std;
typedef char* String;
//得到next数组
void Get_Next(String T, int *next)
{
int j, k;
j = 0;
k = -1;
next[0] = -1;
while (j < strlen(T))
{
if (k == -1 || T[j] == T[k])
{
j++;
k++;
next[j] = k;
}
else
{
k = next[k];
}
}
}
//KMP算法
int KMP(String S, String T, int *next)
{
int i = 0, j = 0;
Get_Next(T, next);
int slen = strlen(S);
int tlen = strlen(T);
while (i < slen && j < tlen)
{
if (j == -1 || S[i] == T[j])
{
i++;
j++;
}
else
{
j = next[j];
}
}
if (j == tlen)
{
return i - tlen;
}
else
{
return -1;
}
}
void main()
{
cout << "next就是输入的那一串字符每一个字符多对应的下标 " << endl;
int N;
cout << "请输入你想测试的次数:" << endl;
cin >> N;
while (N--)
{
cout << endl;
cout << "请输入一串字符:" << endl;
char S[255];
char T[255];
cin >> S >> T;
int next[255];
int i = 1;
//cout << strlen(S) << endl;
Get_Next(T, next);
cout << "模式每一个字符对应的next的值为:" << endl;
for (i = 0; i < strlen(T); i++)
{
printf("%d ", next[i]);
}
cout << endl;
cout << "匹配出现的位置:" << KMP(S, T, next) << endl;
}
cout << endl;
system("pause");
}
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/153013.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
