大家好,又见面了,我是你们的朋友全栈君。
曾经研究过jkd1.5新特性,其中ConcurrentHashMap就是其中之一,其特点:效率比Hashtable高,并发性比hashmap好。结合了两者的特点。
集合是编程中最常用的数据结构。而谈到并发,几乎总是离不开集合这类高级数据结构的支持。比如两个线程需要同时访问一个中间临界区(Queue),比如常会用缓存作为外部文件的副本(HashMap)。这篇文章主要分析jdk1.5的3种并发集合类型(concurrent,copyonright,queue)中的ConcurrentHashMap,让我们从原理上细致的了解它们,能够让我们在深度项目开发中获益非浅。
在tiger之前,我们使用得最多的数据结构之一就是HashMap和Hashtable。大家都知道,HashMap中未进行同步考虑,而Hashtable则使用了synchronized,带来的直接影响就是可选择,我们可以在单线程时使用HashMap提高效率,而多线程时用Hashtable来保证安全。
当我们享受着jdk带来的便利时同样承受它带来的不幸恶果。通过分析Hashtable就知道,synchronized是针对整张Hash表的,即每次锁住整张表让线程独占,安全的背后是巨大的浪费,慧眼独具的DougLee立马拿出了解决方案—-ConcurrentHashMap。
ConcurrentHashMap和Hashtable主要区别就是围绕着锁的粒度以及如何锁。如图
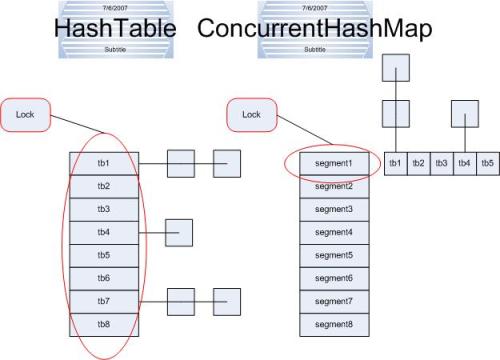

左边便是Hashtable的实现方式—锁整个hash表;而右边则是ConcurrentHashMap的实现方式—锁桶(或段)。 ConcurrentHashMap将hash表分为16个桶(默认值),诸如get,put,remove等常用操作只锁当前需要用到的桶。试想,原来 只能一个线程进入,现在却能同时16个写线程进入(写线程才需要锁定,而读线程几乎不受限制,之后会提到),并发性的提升是显而易见的。
更令人惊讶的是ConcurrentHashMap的读取并发,因为在读取的大多数时候都没有用到锁定,所以读取操作几乎是完全的并发操作,而写操作锁定的粒度又非常细,比起之前又更加快速(这一点在桶更多时表现得更明显些)。只有在求size等操作时才需要锁定整个表。而在迭代时,ConcurrentHashMap使用了不同于传统集合的快速失败迭代器(见之前的文章《JAVA API备忘—集合》)的另一种迭代方式,我们称为弱一致迭代器。在这种迭代方式中,当iterator被创建后集合再发生改变就不再是抛出 ConcurrentModificationException,取而代之的是在改变时new新的数据从而不影响原有的数 据,iterator完成后再将头指针替换为新的数据,这样iterator线程可以使用原来老的数据,而写线程也可以并发的完成改变,更重要的,这保证 了多个线程并发执行的连续性和扩展性,是性能提升的关键。
接下来,让我们看看ConcurrentHashMap中的几个重要方法,心里知道了实现机制后,使用起来就更加有底气。
ConcurrentHashMap中主要实体类就是三个:ConcurrentHashMap(整个Hash表),Segment(桶),HashEntry(节点),对应上面的图可以看出之间的关系。
get 方法(请注意,这里分析的方法都是针对桶的,因为ConcurrentHashMap的最大改进就是将粒度细化到了桶上),首先判断了当前桶的数据个数是 否为0,为0自然不可能get到什么,只有返回null,这样做避免了不必要的搜索,也用最小的代价避免出错。然后得到头节点(方法将在下面涉及)之后就 是根据hash和key逐个判断是否是指定的值,如果是并且值非空就说明找到了,直接返回;程序非常简单,但有一个令人困惑的地方,这句return readValueUnderLock(e)到底是用来干什么的呢?研究它的代码,在锁定之后返回一个值。但这里已经有一句V v = e.value得到了节点的值,这句return readValueUnderLock(e)是否多此一举?事实上,这里完全是为了并发考虑的,这里当v为空时,可能是一个线程正在改变节点,而之前的 get操作都未进行锁定,根据bernstein条件,读后写或写后读都会引起数据的不一致,所以这里要对这个e重新上锁再读一遍,以保证得到的是正确值,这里不得不佩服Doug Lee思维的严密性。整个get操作只有很少的情况会锁定,相对于之前的Hashtable,并发是不可避免的啊!
V get(Object key, int hash) {
if (count != 0) { // read-volatile
HashEntry<K,V> e = getFirst(hash);
while (e != null) {
if (e.hash == hash && key.equals(e.key)) {
V v = e.value;
if (v != null)
return v;
return readValueUnderLock(e); // recheck
}
e = e.next;
}
}
return null;
}
V readValueUnderLock(HashEntry<K,V> e) {
lock();
try {
return e.value;
} finally {
unlock();
}
}
-
put 操作一上来就锁定了整个segment,这当然是为了并发的安全,修改数据是不能并发进行的,必须得有个判断是否超限的语句以确保容量不足时能够 rehash,而比较难懂的是这句int index = hash & (tab.length – 1),原来segment里面才是真正的hashtable,即每个segment是一个传统意义上的hashtable,如上图,从两者的结构就可以看出区别,这里就是找出需要的entry在table的哪一个位置,之后得到的entry就是这个链的第一个节点,如果e!=null,说明找到了,这是就要替换节点的值(onlyIfAbsent == false),否则,我们需要new一个entry,它的后继是first,而让tab[index]指向它,什么意思呢?实际上就是将这个新entry 插入到链头,剩下的就非常容易理解了。
-
V put(K key, int hash, V value, boolean onlyIfAbsent) {
lock();
try {
int c = count;
if (c++ > threshold) // ensure capacity
rehash();
HashEntry<K,V>[] tab = table;
int index = hash & (tab.length - 1);
HashEntry<K,V> first = tab[index];
HashEntry<K,V> e = first;
while (e != null && (e.hash != hash || !key.equals(e.key)))
e = e.next;
V oldValue;
if (e != null) {
oldValue = e.value;
if (!onlyIfAbsent)
e.value = value;
}
else {
oldValue = null;
++modCount;
tab[index] = new HashEntry<K,V>(key, hash, first, value);
count = c; // write-volatile
}
return oldValue;
} finally {
unlock();
}
}
remove 操作非常类似put,但要注意一点区别,中间那个for循环是做什么用的呢?(*号标记)从代码来看,就是将定位之 后的所有entry克隆并拼回前面去, 但有必要吗?每次删除一个元素就要将那之前的元素克隆一遍?这点其实是由entry的不 变性来决定的,仔细观察entry定义,发现除了value,其他 所有属性都是用final来修饰的,这意味着在第一次设置了next域 之 后便不能再改变它,取而代之的是将它之前的节点全都克隆一次。至于entry为什么要设置为不变性,这跟不变性的访问 不需要同步从而节省时间有关,关于不变性的更多内容,请参阅之前的文章《线程高级—线程的一些编程技巧》
V remove(Object key, int hash, Object value) {
lock();
try {
int c = count - 1;
HashEntry<K,V>[] tab = table;
int index = hash & (tab.length - 1);
HashEntry<K,V> first = tab[index];
HashEntry<K,V> e = first;
while (e != null && (e.hash != hash || !key.equals(e.key)))
e = e.next;
V oldValue = null;
if (e != null) {
V v = e.value;
if (value == null || value.equals(v)) {
oldValue = v;
// All entries following removed node can stay
// in list, but all preceding ones need to be
// cloned.
++modCount;
HashEntry<K,V> newFirst = e.next;
for (HashEntry<K,V> p = first; p != e; p = p.next)
newFirst = new HashEntry<K,V>(p.key, p.hash,
newFirst, p.value);
tab[index] = newFirst;
count = c; // write-volatile
}
}
return oldValue;
} finally {
unlock();
}
}
static final class HashEntry<K,V> {
final K key;
final int hash;
volatile V value;
final HashEntry<K,V> next;
HashEntry(K key, int hash, HashEntry<K,V> next, V value) {
this.key = key;
this.hash = hash;
this.next = next;
this.value = value;
}
@SuppressWarnings("unchecked")
static final <K,V> HashEntry<K,V>[] newArray(int i) {
return new HashEntry[i];
}
}
转载自这里:http://www.cnblogs.com/samuelin/articles/2208194.html(好像已经不存在了,故转载保存)
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/152728.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
