大家好,又见面了,我是你们的朋友全栈君。
一、跌倒检测数据集
随着计算机学科与人工智能的发展和应用,视频分析技术迅速兴起并得到了广泛关注。视频分析中的一个核心就是人体行为识别,行为识别的准确性和快速性将直接影响视频分析系统后续工作的结果。因此,如何提高视频中人体行为识别的准确性和快速性,已成为视频分析系统研究中的重点问题。
目前,典型的视频人体行为识别方法主要有:时空兴趣点、密集轨迹等。其中:
时空兴趣点,是通过检测视频中的角点、提取角点的特征进行人体行为识别,但是一部分角点是由背景噪声产生,不但会影响最后的结果,还会降低识别的运行速度。
密集轨迹,是先对视频每一帧进行多个尺度上的密集采样,然后对采样的点进行跟踪得到轨迹,再提取轨迹的特征进行行为识别。但是该方法的计算复杂度高,并且产生的特征维度高,会占用大量的内存,很难做到实时识别。
二、
一种基于姿态估计的人体行为识别方法,主要解决现有技术在视频人体行为中处理速度过慢的问题。
实现步骤:
1.利用Open‑pose方法对视频中人体进行姿态估计,提取视频中每帧人体关节点位置坐标;
2.根据每帧人体关节点位置坐标,计算相邻两帧人体关节点距离变化量矩阵;
3.将视频进行分段,利用每段视频距离变化量矩阵生成视频特征;
4.将数据集中视频分为训练集和测试集两部分,用训练集的视频特征训练分类器,利用训练好的分类器对测试集中的视频进行分类。
提高了视频中人体行为识别的速度,可用于智能视频监控、人机交互、视频检索
具体方法
(1)提取视频中每帧人体关节点位置坐标:
(1a)利用Open-pose方法对视频中每帧人体进行姿态估计,得到人体脖子、胸部、头部、右肩、左肩、右臀部、左臀部、右手肘、左手肘、右膝盖、左膝盖、右手腕、左手腕、右脚踝和左脚踝这15个关节点的位置坐标,其中第k个关节点的坐标表示为Lk=(xk,yk),k从1到15;
(1b)对每个关节点的位置坐标进行归一化;
(1c)用归一化之后的15个关节点位置坐标构成坐标矩阵P,P=[(x1,y1),(x2,y2),…,(xk,yk),…,(x15,y15)],其中(xk,yk)表示第k个关节点归一化之后的坐标;
(2)计算相邻两帧人体关节点距离变化量矩阵:
(2a)根据相邻两帧的坐标矩阵Pn和Pn-1,计算相邻两帧关节点位置坐标变化量矩阵
(2b)根据关节点位置坐标变化量矩阵计算关节点距离变化量矩阵D;
(3)生成视频特征:
(3a)按照视频的时间长度将视频平均分成4段,将每一段视频中相邻两帧产生的距离变化量矩阵D相加,得到各段累计距离变化量矩阵Di,i从1到4;
(3b)对Di进行L2归一化,得到归一化之后的Di’;
(3c)将累计距离变化量矩阵Di’串联起来作为整个视频的特征:
F=[D1′,D2′,D3′,D4′];
(4)训练分类器对视频进行分类:
(4a)把sub-JHMDB数据集的视频分成训练集和测试集两部分,将训练集视频的特征输入到支持向量机中进行训练,得到训练好的支持向量机;
(4b)把测试集视频的特征输入到训练好的支持向量机中得到分类结果。
2.根据权利要求1所述的方法,其中步骤(1b)中对每个关节点的位置坐标进行归一化,按如下公式进行:
其中x,y表示归一化前的坐标,x’,y’表示归一化后的坐标,W表示视频的每一帧宽度,H表示视频的每一帧高度。
3.根据权利要求1所述的方法,其中步骤(2a)中计算相邻两帧关节点位置坐标变化量矩阵按如下公式计算:
其中Pn和Pn-1分别表示前一帧和后一帧的关节点位置矩阵,dxk和dyk表示第k个关节点相邻两帧坐标变化量。
4.根据权利要求1所述的方法,其中步骤(2b)中计算关节点距离变化量矩阵D,按如下公式计算:
其中dxk和dyk表示中第k个元素。
5.根据权利要求1所述的方法,其中步骤(3b)中对Di进行L2归一化得到Di’,按如下公式计算:
其中Di=[d1,d2,…,dk,…,d15]是第i段视频累计距离变化量矩阵,dk表示Di中第k个元素,是Di的L2范数,表示Di中第k个元素的平方。
论文来自《基于姿态估计的人体行为识别方法与流程》
others
提取特征,通过计算前景图像的几何特征,如宽高比、轮廓长度与所围面积比、离心率等,利用这些参数构成特征向量反映人体姿态。姿态分类过程使用了支持向量机方法,依据算法要求,采集各种人体姿态图像样本,提取样本特征数据集,以此数据集训练分类器。将学习训练得到的分类器应用于检测过程,从而达成姿态识别的目的。
GCN在行为识别领域的应用
行为识别的主要任务是分类识别,对给定的一段动作信息(例如视频,图片,2D骨骼序列,3D骨骼序列),通过特征抽取分类来预测其类别。目前(18年过后)基于视频和RGB图片的主流方法是two-stream双流网络,而基于骨骼数据的主流方法就是图卷积网络了。
人体的骨骼图本身就是一个拓扑图,因此将GCN运用到动作识别上是一个非常合理的想法。但不同于传统的图结构数据,人体运动数据是一连串的时间序列,在每个时间点上具有空间特征,而在帧于帧之间则具有时间特征,如何通过图卷积网络来综合性的发掘运动的时空特征,是目前的行为识别领域的研究热点。笔者选取了自18年以来将GCN和行为识别相结合的代表性工作,用于讨论并分析这些工作的核心思想,以及在此基础上可以尝试的idea。
[1]SpatialTemporal Graph Convolutional Networks for Skeleton-Based Action Recognition(AAAI,2018)(cv,88.3%,表示在NTU RGB+D数据集上cross-view验证结果,下同)
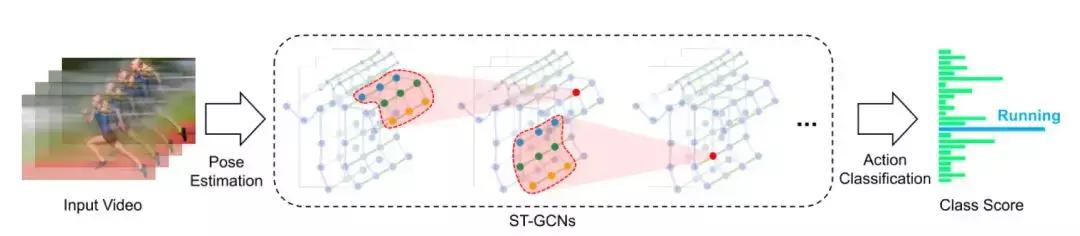

主要贡献:
1.将图卷积网络扩展到时空域,称为时空图卷积网络(ST-GCN)。对于每个关节而言,不仅考虑它在空间上的相邻关节,还要考虑它在时间上的相邻关节,也就是说将邻域的概念扩展到了时间上。
2.新的权重分配策略,文章中提到了三种不同的权重分配策略:
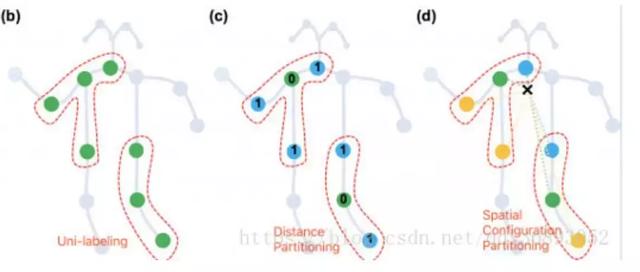
图(b)唯一划分,将节点和其1邻域节点划分到相同的子集中,使他们具有相同的label,自然也就具有相同的权重。这样的话每个kernel中的权重实际上就是一个1*N的向量,N是节点的特征维数。
图(c)按距离划分,将节点自身划分为一个子集,1领域划分到一个子集。每个kernel的权重是一个2*N的向量。
图(d)按节点与重心距离划分,距离重心更近(相对于中心节点)的1邻域节点为一个子集,距离重心更远的1邻域节点为一个子集,中心节点自身为1个子集。每个kernel的权重是一个3*N的向量。
经过测试发现第三种策略效果最好,这是因为第三种策略实际上也包含了对末肢关节赋予更多关注的思想,通常距离重心越近,运动幅度越小,同时能更好的区分向心运动和离心运动。
核心思想:
1.将图卷积扩展到了时域上,从而更好的发掘动作的运动特征,而不仅仅是空间特征。
2.设计了新的权重分配策略,能更加差异化地学习不同节点的特征。
3.合理的运用先验知识,对运动幅度大的关节给予更多的关注,潜在的体现在权重分配策略中。
[2]DeepProgressive Reinforcement Learning for Skeleton-based Action Recognition(CVPR,2018)(cv,89.8%)
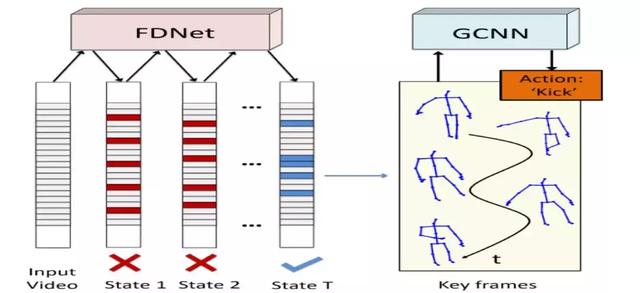
主要贡献:
1.首先通过深度渐进式强化学习(DPRL),用类似蒸馏的方法逐步得从输入的动作帧序列中挑选最具识别力的帧,并忽略掉那些模棱两可的帧,这是一种类似于lstem中的attention的机制,只不过注意力只放在了时域上。对应的网络是frame distillation network(FDNet)。
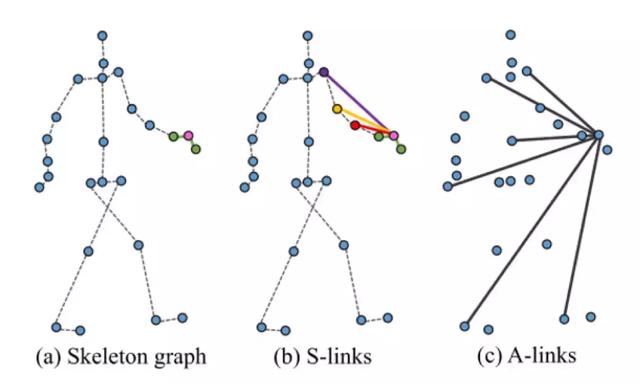
2.将FDNet的输出作为GCN的输入,用于动作识别。不同于传统的骨骼图,本文还定义了一些特殊的骨骼连接,如下图:
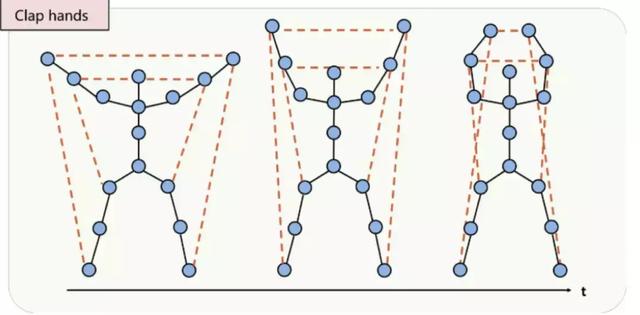
不仅包含了骨架的肢节连接(实线),为了发掘那些没有直接连接的关节之间的关系,还定义了一些重要关节之间的间接连接(虚线)。例如系鞋带,手部关节和脚部关节会有亲密合作,但他们并没有在骨骼图中直接相连,距离较远,需要经过多层的图卷积两个关节的特征才会相互传播给对方,因此可以通过额外建立间接连接来发掘其中的关系。这个思想体现在邻接矩阵上,就是将邻接矩阵中一部分原本值为0的元素改为其他大于0的值。此外,观察上图你会发现,定义了虚线连接的那些关节大都是距离重心较远的关节,这是因为在大部分动作中,距重心越远的关节运动幅度越大,其蕴含的信息越多。
核心思想:
1.attention机制,在时域上选择具有代表性,识别能力更强的帧。
2.对邻接矩阵进行改进,不再是单一的0-1布尔矩阵,对没有直接连接的节点之间也赋予一定的权重。
3.合理运用先验知识,对末肢关节赋予更多的关注,体现在邻接矩阵上。
[3]Part-based Graph ConvolutionalNetwork for Action Recognition(BMVC,2018)(cv,93.2)
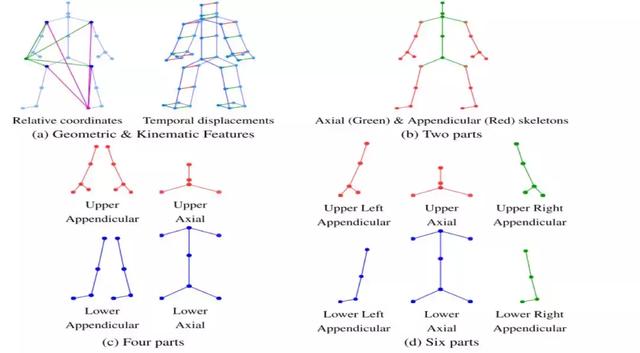
主要贡献:
1.用几何特征(Geometric Features)和运动特征(Kinematic Features)来代替原始的空间三维坐标,作为每个节点的原始特征。如上图中的图(a)。
2.将人体骨架图按一定的原则划分为多个不同的子图。对每个子图分别进行图卷积操作,然后再通过一个融合函数将结果融合。具体思想是:首先对于一个节点,计算该节点与所属子图内的邻接节点的卷积值,我们称之为基本卷积值。而对于所属子图外的邻接节点(属于相邻的另一个子图),首先计算该邻接节点的基本卷积值,然后将二者的基本卷积值以一定的权重融合。这么做可以在很大程度上提高每个子图边缘节点的感受野(直接覆盖到相邻子图),同时对于每个子图的非边缘节点(于其他子图不相连),则需要多次传播才能获取到其他子图节点的特征。
本文测试了三种不同的划分策略,分别是:
图(b):按距离重心的距离,分为中轴关节和末肢关节两个部分。
图(c):在图(b)的基础上进一步细化,按照关节的上下位置分为4个部分。
图(d):在(c)的基础上加入了左右关节的概念,按左右再细分为6个部分。
实验证明,图(c)的划分方法结果最好,这是因为如果子图数量过多,会导致特征值得传播更困难,而数量过少,则无法差异化地对待不同类型的关节。
3.时空域卷积。不同于文章[1],本文采用的时空卷积策略是:先对每一帧,按照子图特征融合的方法进行卷积,得到空域卷积结果,然后在将空域卷积结果作为时域上的特征值,再进行时域上的卷积。这么做实际上是扩大了计算量和复杂度,但能发掘的时空信息也更全面,不再局限于局部关节范围。
核心思想:
1.定义了更加复杂的卷积策略,不再是简单的邻域特征融合,而是扩大了邻域的概念,从而提高了节点的感受野。
2.采用了分图策略,有助于挖掘局部范围内的关节联系。通常这种策略我们称为part-based或part-aware。
3.定义了范围更广的时空卷积操作,代价是计算量更大了。
4.传统方法使用关节原始的坐标信息作为GCN的输入,而这里采用更具代表性的两种不同类型特征作为输入,可以进一步提高识别能力。
[4]Actional-Structural Graph Convolutional Networksfor Skeleton-based Action Recognition(arXiv,2019)(cv,94.2)
顶会的文章真的是一年比一年复杂,虽然说效果越做越好,但是特征工程和网络结构都非常复杂,有时候纯粹是靠堆复杂度来提升结果,作者并不能合理解释自己的网络结构,而且这种工作也很难follow
主要贡献:
提出了AS-GCN,主要涉及了两种网络结构:Action-link和Structural-link。通过Action-link来发掘潜在的关节之间的联系,通过structual-link来发掘骨骼图的高阶关系。
1.Action-Link提取关节连接信息
如图(c),Action-Link实际上就是每个关节和其他所有关节的连接,通过一个编码-解码器来学习这些连接的权重,进而发掘关节之间的潜在联系,如下图:
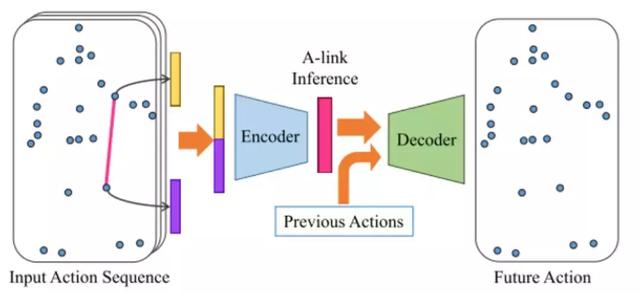
具体细节(理解难度较大,如果不深入研究可以忽略):
上图中左侧黄色和紫色分别代表某一帧的原始的joints features和links features,将两种类型的特征反复迭代更新(encoder),可以实现特征在关节和边中的流动传播,最终得到一个概率权重矩阵。将这个矩阵和该帧之前的所有时刻的帧信息结合起来,通过一个decoder来预测下一时刻的关节位置。这样就能通过反向传播的方式来不断的迭代更新网络参数,实现对网络的训练。在网络得到初步的训练后,将decoder去掉,只使用前半部分抽取A-link特征,用于动作分类任务的进一步训练。
2.Structural-link扩大节点感受野
传统的图卷积网络中,每个节点只将自己的信息传播给邻居节点,这会导致节点感受野较小,不利于获取长距离的连接信息。通过对邻接矩阵取一定次数的幂,可以扩大感受野,如图(b)。
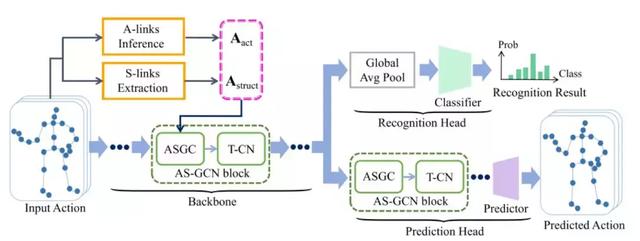
3.多任务处理
将A-Link和S-link加权结合起来作为GCN的输入。将GCN和Temporal-GCN结合,得到AS-GCN,作为基本网络(Backbone)。接不同的后端网络,可以分别实现分类功能和预测功能,如下图:
核心思想:
1.从原始的坐标信息中提取出A-links特征信息作为输入特征,具有更高的可识别度,类似于工作[3]。
2.通过对邻接矩阵取多次幂来扩大节点的感受域。
3.多个block叠加,通过提高复杂度来提高识别能力。
[5] An AttentionEnhanced Graph Convolutional LSTM Network for Skeleton-Based ActionRecognition(CVPR,2019)(cv,95%,目前最好)
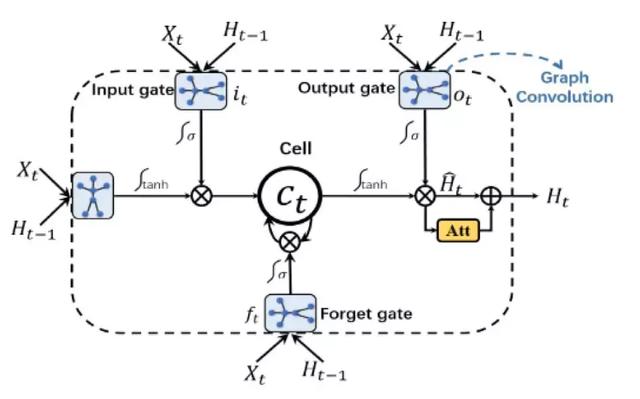
主要贡献:
不同于前面介绍的工作,本文没有采用GCN,而是将骨骼图作为LSTM的输入,通过注意力增强型图卷积LSTM网络(AGC-LSTM)来抽取图中具有的空间和时间特征,并且设计了专门的损失函数和特殊的学习方法。
核心思想:
探究不同的图处理方式,LSTM具有很强的时序特征获取能力,将其于图结构结合起来,可以实现对时空特征的获取。
[6] SemanticGraph Convolutional Networks for 3D Human Pose Regression(arXiv,2019)
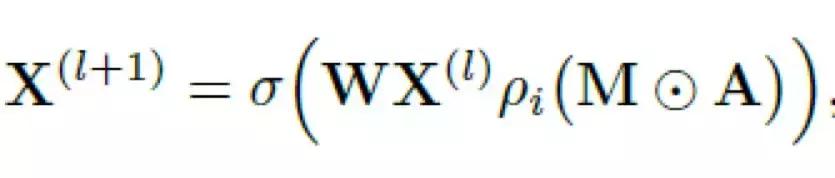
本文的工作不是行为识别,而是姿态估计。但笔者认为其中用到的一些方法非常有道理,可以迁移到行为识别任务中。
主要贡献:
在我们之前介绍的图卷积工作中,GCN网络需要学习的通常都只有基本的权重矩阵(上面公式中的W),而对于邻接矩阵都是通过一些先验知识提前设置好的,不会随着网络进行迭代变化。然而事实上,邻接矩阵的本质也是权重,只不过通常这个权重是我们根据一些先验的知识或者规律提前设置好的,因此,本文作者提出,如果能通过网络来学习邻接矩阵的权重,也就是公式中的M,是否能更好的做到对特征的抽取呢?
按照这个思路,网络就需要学习两个不同的权重,其中基本权重W在不同的图卷积层有不同的值,那么邻接矩阵的权重M也应该是在不同的层有不同的值。可能有小伙伴会问,为什么不把M和W结合到一起呢?读一读原文,你就能找到答案了,这里只提供一种思路。
核心思想:
额外添加一个针对邻接矩阵的权重,让网络自己去学习自己的邻接矩阵。
总结
总的来说,在基于图卷积的行为识别工作和类似的工作中,研究重点在以下几个方面:
1.如何设计GCN的输入,用一些更加具有识别能力的特征来代替空间坐标,作为网络输入。
2.如何根据问题来定义卷积操作,这是非常硬核的问题。
3.如何设计邻接矩阵。
4.如何确定权重分配策略。
Idea可是无价之宝,不过还是分享出来,有兴趣的同学可以和我一起探讨。
从前面的文章中我们可以发现,邻接矩阵和权重矩阵在GCN中非常重要,其中权重矩阵通常情况下是不随图的结构变化的,也就是说不仅在不同的节点之间共享,还会在不同的图结构中共享,这样GCN就能在不同结构的图上训练和测试。但是行为识别工作是比较特殊的,因为人的骨架通常不会发生变化,而且同一个数据集提供的骨架也是固定不变的,这样的话,我们就不用考虑GCN的在不同结构上的通用性,转而将权重直接指派到每个关节,也就是说,现在每个节点都有一个只属于自己的权重,而不再依赖于label策略和其他节点共享。这么做能让网络能更加差异化地对待每一个关节,从而对那些具有更强识别能力的关节赋予更多的关注。此外,自动学习邻接矩阵也是一个不错的思路,只不过在代码实现上面难度会比较大。
基于空域的图卷积网络目前在NTU RGB+D数据集[7]上已经达到了前所未有的高度,要想再有所提升恐怕会很困难,不过南洋理工大学rose lab已经发布了新的NTU 120+数据集[8],而且越来越多的工作聚焦于基于2D骨骼的姿态识别,与之相对应的Kinetic数据集也更有挑战性,所以这个领域还是非常有研究价值和前景的。此外,谱图卷积在近年也得到了很大的关注,但就目前来看笔者只发现了一篇与姿态识别有关的文章是使用了谱图卷积的,笔者认为主要是谱图卷积相对于空域图卷积而言复杂程度太高,导致很多人望而却步,但越是复杂的东西其性能相对也越好,因此在下一篇文章中,笔者将为大家详细剖析谱图卷积的原理,以及相关的行为识别工作!
从目前顶会文章的发展趋势来看,工作都是越来越复杂的,如果考虑冲击顶会,就要重点研究第1个和第2个思路,如果是次级一些的会议,就可以从第3和第4个思路入手。此外,尽量follow一些已经在顶会上发表了的,被同行检查过的文章,以及有源代码的文章,这样可以有效降低工作难度。
附:
Awesome-Skeleton-based-Action-Recognition
参考文章:
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/152047.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
