大家好,又见面了,我是你们的朋友全栈君。
- 定义
- 背景
- 难点
- 最新论文
- 最新算法
- 数据集
1 定义
行为识别:行为识别(Action Recognition) 任务是从视频剪辑(2D帧序列)中识别不同的动作,其中动作可以在视频的整个持续时间内执行或不执行。行为识别似乎是图像分类任务到多个帧的扩展,然后聚合来自每帧的预测。尽管图像分类取得了很大的成功,但是视频分类和表示学习依然进展缓慢。
2 背景
2.1 方法
2.1.1 传统方法
提取视频区域的局部高维视觉特征,然后组合成固定大小的视频级描述,最后利用分类器(SVM,RF等) 进行最终预测


2.1.2 深度学习方法
单流法:视频的连续帧作为单一网络的输入,进行预测
双流法:设计两个单独的网络,一个用于空间流,一个用于时间流
基于骨架:基于骨架数据的人体行为识别
2.2 传统方法原理
2.2.1 特征提取
特征提取一般根据人体行为的构成方式,分为整体表示方式和局部表示方式:
- 整体表示方式:是将视频帧看作一个整体,通过人体定位->背景提取追踪->ROI编码一系列过程,自上而下的提取全局特征。优点在于编码信息比较丰富,缺点在于过于依赖准确的定位、精确的背景提取追踪,且对摄像机视点、噪声、遮挡极其敏感。
- 局部表示方式:是将视频段落作为一个整体,通过时空兴趣点检测->邻域特征点计算->特征整合与表达一系列过程,自下而上的提取特征。优点在于对摄像机视点、噪声、局部遮挡不敏感,不依赖背景提取、追踪算法,缺点在于依赖兴趣点提取的数量和预处理方法,摄像机运动产生的误差也会对兴趣点采集造成影响。
整体表示方式包括ROI提取表示、网络切分(Grid-based)表示与时空体积(Space-time volume)
- ROI提取表示用到的方法有背景剪除法、差分法和光流法,轮廓边缘特征包括运动能量图像(Motion Energy Image, MEI)、运动历史图像(Motion History Image, MHI)、形状上下文(Shape Context, SC)等。优点在于算法相对简单,缺点在于背景剪除可能带来很多噪声,导致人体行为特征很难精确描述,即准确率很大受限于人体行为轮廓提取及帧序列中轮廓的跟踪。
- 网络切分表示是指将待识别的人体区域ROI分割成若干时间空间网格,每个网格代表视频帧的一部分特征,网格的组合代表ROI的整体特征。优点在于减少ROI中存在的噪声,降低了视角变化带来的细微差异,平滑了自身遮挡产生区分度较差的特征空间。
- 时空体积表示是指将给定序列的帧进行堆叠,但是也需要精确的定位、对齐以及背景剪除。
局部表示方式包括时空兴趣点检测、局部网格表示两种方法。
- 时空兴趣点检测是在时空域内提取出兴趣点,该兴趣点是空域时域均变化显著的邻域点,如3D Harris。有时候多个时空兴趣点的组合也称为局部描述符,描述符已经不再仅仅关注于某些点,而是更上层的关注并描述视频中人体特征的局部。常用的时空兴趣点有:STIP[1];Cuboid[2];MEI+MHI[3];HoG+HoF[4]。
- 局部网格表示类似于整体网格表示,只不过是将局部的patch放入了网格单元中。
- On space-time interest points
- Behavior Recognition via Sparse Spatio-Temporal Features
- The recognition of human movement using temporal templates
- Learning realistic human actions from movies
2.2.2 特征融合
在特征融合方面,人体的轮廓、边缘、运动特征等方面不具备通用性,只有将其组合起来,才能构建出更好鲁棒性和有效性的特征。在特征提取之后,为了使特征具有较高的区分能力,去掉冗余信息,提高目标识别的计算效率,需要对所提取的特征进行融合,这一过程也称为特征编码,主流的特征编码方式有Bag of Feature[1]和Fisher Vector[2]两种。有些文献中,特征提取后的结果(如纹理、轮廓、角点、边缘、光流)称为低级特征,特征融合后的结果称为中级特征(或中级语义),特征分类后的结果称为高级特征(或高级语义)。
- Bag of Feature算法过程如下:
首先提取图像视频特征,其次对特征进行聚类得到一部字典(Visual Vocabulary,或Code Book);再次根据字典将图片或视频表示成直方图向量(Visual Word,或Code Vector);最后作为特征分类器的输入对分类器进行训练。最为关键的是第二步,即通过区分度高的特征来寻找聚类中心 - Fisher Vector通过模型化信号的产生过程,通过EM算法训练SIFT描述子得到每个视觉单词的权重、均值和协方差矩阵。
2.2.3 特征分类
特征分类包含直接分类法、时域状态空间融合模型两种方法。
- 直接分类法需要对提取出来或编码后的行为特征进行降维处理(如PCA)来减少计算复杂度、去除噪声,再用KNN、SVM等传统分类器进行分类,不同特征之间距离的计算可以通过欧式距离、马氏距离等进行度量。
- 时域状态空间模型主要是利用动态时间规划(Dynamic Time Warping, DTW)或动态时空规划(Dynamic Space-Time Warping, DSTW),对不同尺度的时间维度进行对齐,或利用生成模型(如HMM)判别模型(如CRF、MEMM)进行分类判断。
2.2.4 传统方法-DT法
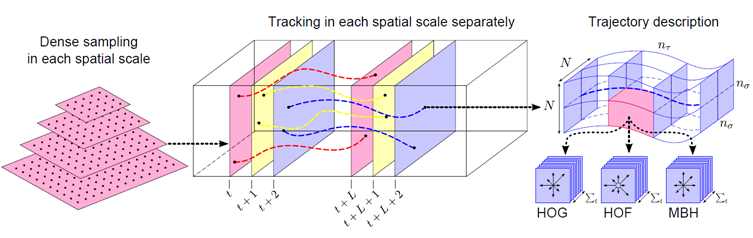
DT(Dense Trajectories) 是利用光流场来获得视频序列中的轨迹,在沿着轨迹提取轨迹形状特征和HOF,HOG, MHB特征,然后利用BoF (Bag of Features)方法对特征进行编码,最后基于编码结果训练SVM分类器。下图为DT算法的基本框架,左图为密集采样特征点,中间的为特征点轨迹跟踪,右图为基于轨迹的特征提取的HOG,HOF,MBH方法。
2.2.5 传统方法-iDT方法
iDT算法的基本框架和DT算法相同,但基于DT算法进行了以下几点的改进:对光流图像的优化,估计相机运动;特征正则化方式的改进;特征编码方式的改进。
- 相机运动估计:通过估计相机运动来消除背景上的光流以及轨迹;假设相邻的两帧图像之间的关系可以用一个投影变换矩阵来描述,即后一帧图像是前一帧图像通过投影变换得到的;为了准确估计投影变换,采用了SURF特征以及光流特征来获得匹配点对;还使用human detector检测人的位置框,并去除该框中的匹配点对。
- 特征归一化方式:对HOF,HOG和MBH特征采用了L1正则化后,再对特征的每个维度开平方。
- 特征编码方式:不再使用BoF方法,而是采用效果更好的Fisher Vector编码。
iDT法作为行为检测中效果最好的传统算法,有着很好的效果和鲁棒性,在UCF50数据集上达到了91.2%的准确率,并在HMDB51上的准确率达到了57.2%。
2.3 one stream
2.3.1 one stram原理
在本工作中,作者Karpathy等提出了使用2D预训练卷积融合连续帧的时间信息的多种方法。
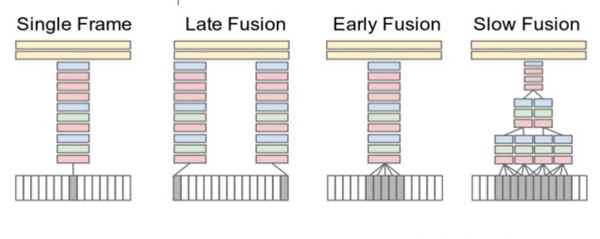
在下图中可以看到,视频的连续帧在所有的方法中都被表示为输入。Single Frame使用单一架构,融合最后阶段所有帧的信息。Late fusion使用共享参数的两个网络,间隔15帧,并融合预测结果。Early fusion 通过第一层卷积整合超过10帧的信息。Slow fusion 包含多个阶段的融合,平衡Early fusion和Late fusion。对于最终预测,从整个视频中采样多个剪辑,并对他们的预测分数进行平均,以达到最终预测。
缺点:学习的时空特征没有捕捉到运动特征;由于数据集缺少多样化,学习具体的特征很困难。
2.3.2 one steam方法
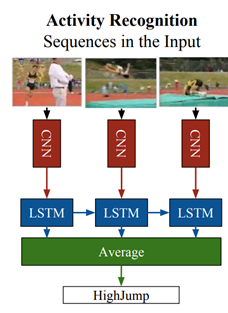
(1)LRCN: 在本文中,作者设计了在卷积块(编码器)之后使用LSTM(解码器)的框架,但整体架构是端到端的训练。作者还将RGB和光流作为输入选择进行比较,发现基于两种输入的预测加权平均最佳。
在训练期间,从视频中采样16帧剪辑。该架构以端到端的方式进行训练,输入为RGB或16帧剪辑的光流。每个剪辑的最终预测是每个时间步长的预测平均值。视频级的最终预测是每个剪辑的预测平均值。此方法有以下几个优点: 在先前工作的基础上,使用RNN而不是基于流的设计;使用编码器-解码器架构进行行为识别;提出了用于行为识别的端到端的可训练架构。
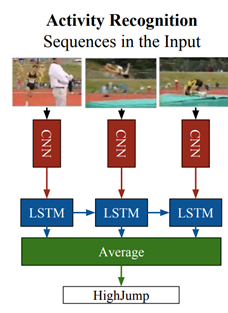
上图用于行为识别,下图适用于所有任务。
(2)C3D:在这项工作中,作者首次在视频上使用3D卷积。作者的想法是在Sports 1M上训练这些网络,然后将这些网络作为其他数据集的特征提取器。作者发现,一个简单的线性分类器如SVM,对提取的特征做分类,结果比先前的算法效果更好。
- 算法:在训练期间,为每个视频提取五个随机的2秒剪辑,剪辑的标签为视频的标签。在测试时,随机采样10个剪辑,并对他们之间的预测进行平均以达到最终预测的目的。
主要贡献:将3D卷积网络作为特征提取器;广泛的搜索最佳3D卷积核和架构;使用反卷积来解释模型决策。

(a) 在图像上应用2D卷积会产生图像;(b)在 video volume上(多个帧作为多个通道)应用2D卷积也会产生图像;(c)在video volume 上应用3D卷积则会产生另一个volume, 保留信号的时间信息。
(3)Conv3D&Attention:在本文中,作者使用3D CNN LSTM作为视频描述任务的基础架构并使用预先训练的3D CNN来提升效果。
- 算法:本文网络结构和LSRCN中描述的编码器-解码器架构几乎相同,但有以下两点不同:不是将特征从3D CNN传递到LSTM,而是将剪辑的3D CNN 特征映射与用于同一组帧的堆叠2D特征映射连接;不是所有帧的temporal vectors求平均,而是用加权平均来整合 features。 Attention weights 是由每个时间步的LSTM输出决定的。
- 主要贡献:设计新的3D CNN-RNN 编码器-解码器架构来捕获局部时空信息;在CNN-RNN架构内使用注意力机制来捕获全局上下文。
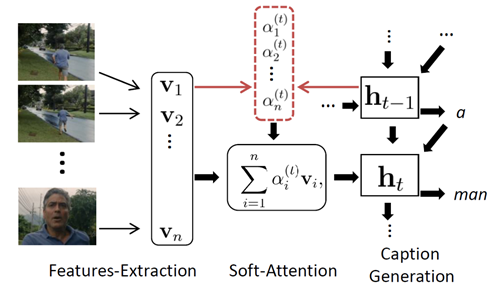
LSTM解码器中提出的注意力机制
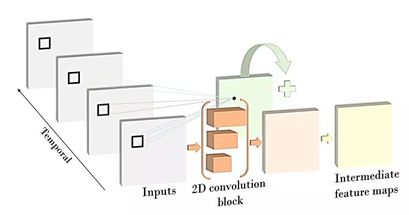
(4)MiCT:在本文中,作者认为时空融合的高度训练复杂性和3D卷积的巨大内存成本阻碍了当前3D CNN,通过输出对于高级任务至关重要的更深层特征图,逐层堆叠3D卷积。因此,提出了一种MiCT,它将2D CNN与3D卷积模块相结合,以生成更深入,更丰富的信息特征图,同时降低每轮时空融合的训练复杂性。
- 首先提出3D/2D串联混合模块 ,可以有效地增加3D CNN的深度,加强2D空域的学习能力,从而生成更深更强的3D特征,并使得3D CNN可以充分利用在图像数据上预先训练的2D CNN模型。
其次提出了一个3D/2D跨域残差并联模块 ,在3D卷积的输入和输出之间引入另一个2D CNN的残差连接,以进一步降低时空融合的复杂性,并有效地促进整个网络的优化。
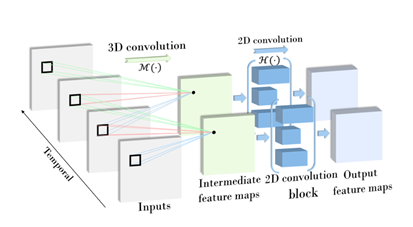
上图是3D/2D串联混合模块,下图是3D/2D跨域残差并联模块
(5)OFF此算法是由商汤科技所提出的一种用于视频行为识别的新颖运动表示,称为光流引导特征(OFF),它使网络能够通过快速而稳健的方法提取时间信息。通过直接计算深度特征映射的逐像素时空梯度,OFF可以嵌入任何现有的基于CNN的视频行为识别框架中,仅需要少量额外成本。它使CNN能够同时提取时空信息,尤其是帧与帧之间的时间信息。
主要贡献:
OFF是一个快速鲁棒性的motion representation。当只有RGB作为输入时,OFF能快速启用超过200帧/秒,并且来自光流并由光流引导。且性能和当时最优的基于光流算法相当。
OFF可以端到端的训练,也就是说在一个网络里可以学习到时域和空域的特征表达,而不需要像two stream 一样分支训练了。
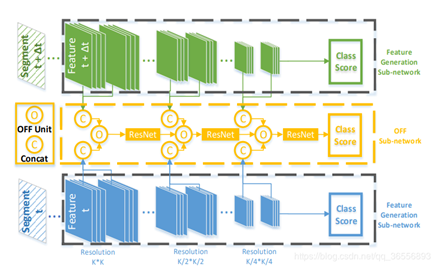
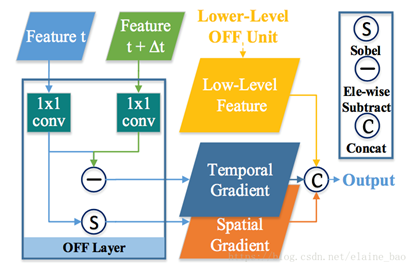
左图为核心的两个网络架构概述,输入是蓝色和绿色的两个段,分别输入特征生成子网以获得基本特征。每个特征生成子网络的主干是BN-Inception 。这里K表示选择用于经历OFF子网以获得OFF特征的方形特征映射的最大边长。OFF子网由几个OFF单元组成。并且几个残差块连接在不同分辨率级别的OFF单元之间。当从整体上看时,这些残差块构成ResNet-20。
右图为OFF单元的详细结构。 1×1卷积层连接到输入基本特征以进行降维。 之后,利用Sobel算子和element-wise subtraction 分别计算空间和时间梯度。 梯度的组合构成OFF,并且sobel算子,subtracting operator 和它们之前的1×1卷积层构成OFF层。

2.4 two stream
2.4.1 方法一
在这项工作中,作者使用两种新的方法构建了two stream 架构,证明了在没有参数增加的情况下,性能有了较大的提升。作者探讨了两个主要观点:
- 空间流和时间流的融合(如何以及何时融合),空间网络可以捕获视频中的空间依赖性,而时间网络可以捕获周期性运动在视频里的空间位置。因此将特定区域有关的空间特征图映射到对应区域的时间特征图是非常重要的。为了实现这一目标,网络需要在early level 融合以此对应相同像素位置的响应。
在时间帧上联合时间网络输出,以便对长期依赖型建模。
主要贡献:
通过更好的远程损失进行长距离时间建模。
新颖的多层融合架构。
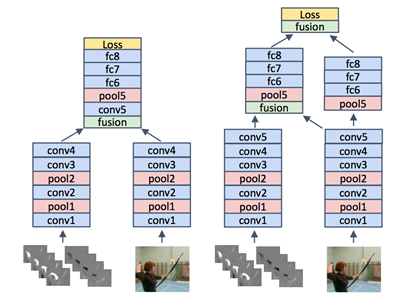
two stream 基本架构,本算法做了以下的改进:
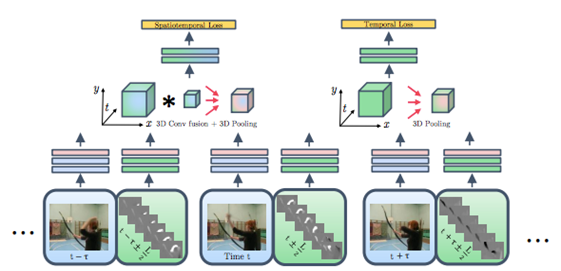
1.如上图(2)所示,来自两个流的conv_5通过conv+pooling层进行融合。最后一层再次进行融合的输出用于时空损失评估。
2.如下图(2)所示,对于时间融合,跨时间堆叠的时间网络输出通过conv+pooling融合,最后用于计算时间损失。
2.4.2 two stream方法二—TSN
在这项工作中,作者改进了two stream架构达到当时最好的效果,与原始的two stream相比有两个主要的差异:
在视频中稀疏地对剪辑进行采样而不是对整个视频进行随机采样,以此更好地捕获长距离时序依赖。
为了对视频作出最终预测,作者探索了多种策略。最好的策略是:
1.通过对snippets平均来分别结合时间流和空间流的得分
2.在所有类别上使用加权平均值和应用Softmax来结合最终空域和时域分数的得分
这项工作的另外一个部分是解决过拟合的问题(由于数据集规模较小),并且证明了现有技术的有效性,如batch normalization, dropout以及pre-training。 作者还评估了两种新的输入模态: 光流与RGB的结果差异。
- 主要贡献:
针对长距离时序建模的解决方案。
提出了batch normalization, dropout和pre-training的使用。
算法:
在训练和预测期间,视频被分成相等持续时间的K个片段,然后在K个片段中随机采样出snippets。其余的步骤仍然类似于two stream架构。
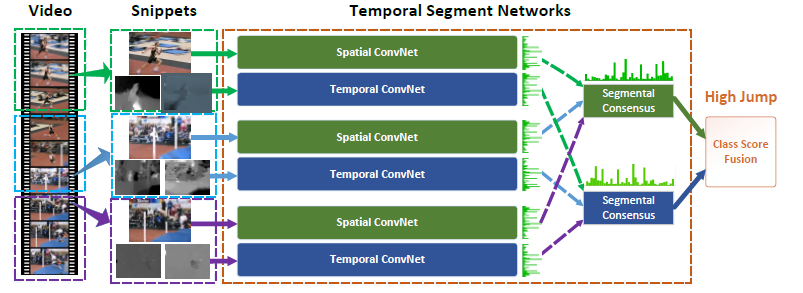
时域段网络:一个输入视频被切分成K个片段,然后从每个片段中随机选出snippets. 不同snippets的分数通过segmental consensus function 融合产生segmental consensus,最后输出预测。
2.4.3 two stream方法二—ActionVALD
在这项工作中,与使用maxpool和avgpool的常规聚合不同,作者选择使用了可学习特征聚合(VLAD)。Two stream中的每个流的输出会根据k-space“行为词汇”进行编码。
- 主要贡献:提出可学习的视频级特征聚合方法,通过视频级聚合特征来训练端到端的模型以此来捕获长距离时序依赖性。
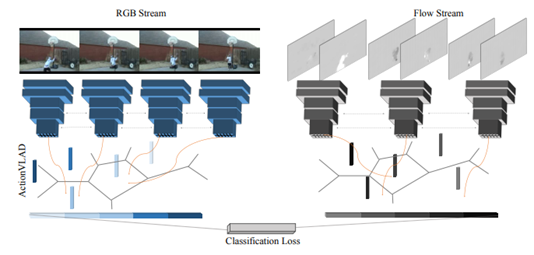
本文使用的网络架构。作者用VGG-16 从视频中提取采样外观和运动帧的特征。然后使用ActionVLAD池化层在空域和时域上池化以此训练出端到端的分类loss。作者还尝试使用ActionVLAD来融合两个流。
2.4.4 two stream方法四-HiddenTwoStream
在two stream 架构中,使用光流特征必须先计算每个采样帧之间的光流,然而却不利于存储和速度。本文提倡使用无监督的架构来为所有的帧生成光流。
光流可认为是一个图像重建问题。给定一对相邻的帧L1和L2作为输入,文中的CNN生成流场V。然后使用预测的流场V和L2, LI可以通过inverse warping重建为L1’,并使得L1与L1’之间的差异最小化。
- 主要贡献:创建了用于使用单独的网络生成即时光流输入的新型架构,作者还证明了使用基于TSN融合而不是传统架构的two stream的方法性能的提升。
算法:作者探索了多种策略和体系架构,以生成具有最大fps和最小参数的光流,而不会对精度造成太大影响。最终的架构与two stream相似,但做了以下的改进:
时间流具有堆叠在一般时间流架构顶部的光流生成网络(MotionNet),时间流的输入不是预处理的光流而是后续帧。 对于无监督的MotionNet训练,设计了一个额外的多级loss。
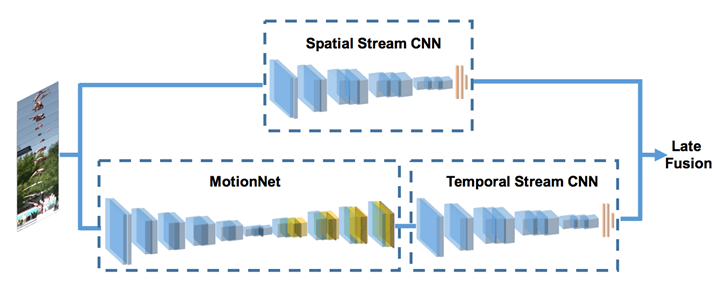
Hidden two stream架构;MontionNet将连续的视频帧作为输入和估计运动。然后,时间流CNN学习将运动信息投影到行为标签。Late Fusion通过对预测分数的加权平均来融合时空流,两个流都是端到端可训练的。
2.4.5 two stream 方法五-I3D
此算法基于C3D,但不是使用单个3D网络,而是在two stream中使用不同3D网络。此外为了利用预训练的2D模型,作者在3D网络第三维中重复2D预训练的权重。空间流的输入包含按时间维度堆叠的帧,而不是base two stream架构中的单个帧。
- 主要贡献:
将3D模型结合到two stream架构中。
创建用于测试和改进的动作数据集多样性的Kinetics 数据库。
算法:
和base two stream架构相同,只不过利用3D网络训练每个流。
2.4.6 two stream方法六-T3D
除此之外,作者还提出了一种新的技术,用于预训练2D 卷积网络和T 3D 之间的可监督迁移学习。2D 预训练卷积网络和T3D都是来自于视频的帧和剪辑,其中帧和剪辑可以来自于相同或者不同的视频。
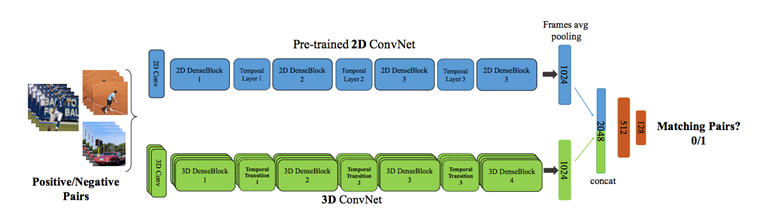
从预训练的2D ConvNet 到 3D ConvNet的迁移框架。2D ConvNet在RGB帧上操作,并且3D网络在相同时间戳的视频剪辑上操作。通过3D ConvNet 在图像视频任务中学习mid-level 特征表示,2D ConvNet 可监督迁移到3D ConvNet。 2D ConvNet的模型参数将保留,任务仅仅是有效的学习3D ConvNet 的模型参数。
2.5 基于骨架原理
骨架信息可以用来做行为识别,区别于C3D和two-stream,主要是输入信息模式不一样,因此方法也有差异,最主要的差异,应该是C3D和two-stream可以用其他方法利用imagenet上的预训练模型,而骨架信息作为输入往往利用不上预训练模型。
骨架输入信息相比于之前其他输入方法,最明显是缺乏人体的外观信息。但是骨架序列有三个显着的特征:1)每个节点与其相邻节点之间存在很强的相关性,因此骨架框架包含丰富的身体结构信息。 2)时间连续性不仅存在于相同的关节(例如,手,腕和肘)中,而且存在于身体结构中。 3)空间域和时域之间存在共生关系。
正是由于骨架信息的显著特征,也使得基于骨架信息的行为检测有了很大的发展和较为可观的效果。另外因为骨架信息的特殊性,一些基于骨架信息的新方法也相继被提出,比如基于图卷积的行为识别算法等。
2.5.1 基于骨架方法一
行为识别有着多种模态,比如外观,深度,光流和身体骨骼。在这些模态中,动态人类骨骼与其他模态相辅相成,能够传达许多重要信息。骨骼不能以2D或3D网络的方式展现,而是以图像的方式展现。最近,将卷积神经网络(CNN)泛化到任意结构图形的图卷积神经网络并成功应用于图像分类。
本方法是由港中文-商汤科技联合实验室所提出的一种时空图卷积网络(ST-GCN)。这种算法基于人体关节位置的时间序列表示以此对动态骨骼建模,并将图卷积扩展为时空卷积网络而捕捉时空的变化关系。如右图所示,该模型是在骨骼图序列上制定的,其中每个节点对应于人体的一个关节。图中存在两种类型的边,即符合关节的自然连接的空间边(spatial edge)和在连续的时间步骤中连接相同关节的时间边(temporal edge)。在此基础上构建多层的时空图卷积,它允许信息沿着空间和时间两个维度进行整合。
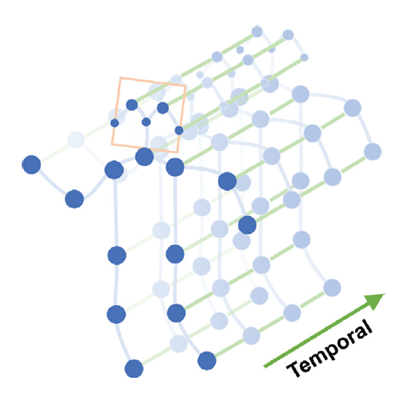
骨骼序列的时空图,蓝点表示关节,关节之间的连接基于人体的自然连接来定义的,关节坐标用作ST-GCN的输入。
2.5.2 基于骨架方法二
ST-GCN 的层次性消除了手动划分部分或遍历规则的需要。这不仅能获得更强的表达能力和更高的性能,而且还使其易于在不同的环境中推广。在通用 GCN 的基础上,我们还基于图像模型的灵感设计了图卷积核的新策略。 这项工作的主要贡献在于三个方面:1)提出 ST-GCN,一个基于图的动态骨骼建模方法,这是首个用以完成本任务的基于图形的神经网络应用。2)提出了在 ST-GCN 中设计卷积核的几个原则,旨在满足骨骼建模的具体要求。3)在基于骨骼行为识别的两个大规模数据集上,作者的模型与先前使用的手动分配部分或遍历规则的方法相比,需要相当少的手动设计,实现了更优越的性能。本方法的网络结构如下图所示:
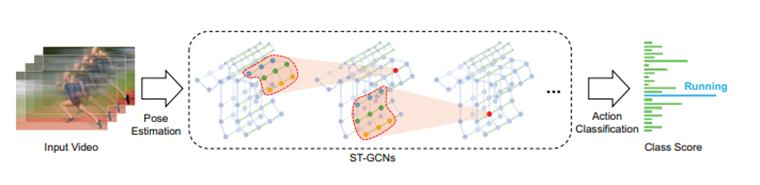
对视频进行姿态估计,并在骨架序列上构建时空图。应用ST-GCN的multiple layers并逐渐在图上产生higher-level特征图。然后通过标准的Softmax分类器分类到相应的行为类别
2.5.3 基于骨架方法三
本文提出了一种用于基于骨架的视频中的行为识别的深度渐进强化学习(DPRL)方法,其旨在提取最具信息性的帧并丢弃序列中的模糊帧以识别行为。由于每个视频代表帧的选择众多,通过深度强化学习将帧选择建模为渐进过程,在此期间通过考虑两个重要因素逐步调整所选帧:1)质量选择的帧;2)所选帧与整个视频之间的关系。此外,考虑到人体的拓扑结构基于图形的结构中,顶点和边缘分别代表铰接关节和刚性骨骼,采用基于图的卷积神经网络来捕捉关节之间的依赖关系以进行行为识别。
左图为此算法提出的模型流程。此算法中有两个子网:帧蒸馏网络frame distillation network(FDNet)和基于图的卷积网络graph-based convolutional network(GCNN)。 FDNet旨在通过深度渐进强化学习方法从输入序列中提取固定数量的关键帧。 然后,根据人体关节之间的依赖关系将FDNet的输出组织成图形结构,并将它们输入GCNN以识别行为标签。
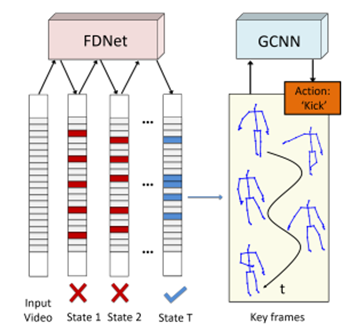
根据FDNet选择关键帧,然后利用GCNN对选择的关键帧进行行为识别。
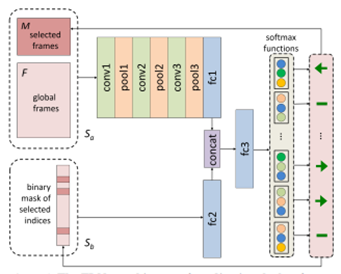
对于骨架视频中行为识别的任务,并非每个帧都具有相同的时间重要性。这是应用基于强化学习的注意力的关键见解。 关键帧的选择被制定为马尔可夫决策过程Markov decision process(MDP),基于此本文使用强化学习来在每次迭代中细化帧。 左图提供了该过程的示意图,该图基于FDNet实现,如右图所示。代理(agent)与提供奖励(rewards)和更新其状态(state)的环境交互,通过最大化总折扣奖励来调整所选帧,最终导致给定数量m的最可区分的帧。
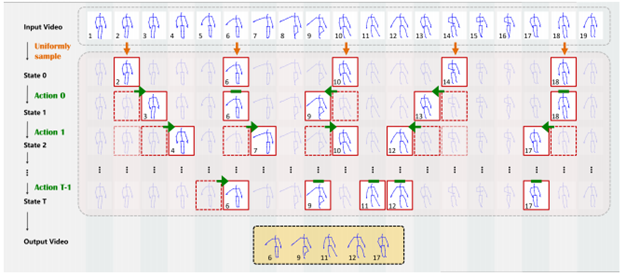
上图是逐步选择基于骨架的视频中的关键帧的过程,下图是调整基于骨架的视频中关键帧的FDnet架构。
2.5.4 基于骨架方法四
在本文中,作者提出了一种新的LSTM网络,即全局情景感知注意力LSTM(global context aware attention LSTM),以用于基于骨架的行为识别,其中通过使用全局情景记忆单元(global context memory cell)选择性地聚焦在每帧中更具信息的节点上。为了进一步提高注意力性能,作者也引入一个周期性的注意力机制(recurrent attention mechanism),这样,所提出网络的注意力性能就可以进一步提高。此外,还介绍了利用粗粒度注意力(coarse-grained attention)和细粒度注意力(fine-grained attention)方法的一种双流架构。
- 主要贡献:
提出了一种GCA-LSTM模型,该模型保留了原始LSTM的序列建模能力,同时通过引入全局情景记忆单元来提升其选择性注意力。
提出了一种周期性注意力机制,可以逐步提高网络的注意力性能。
提出了一种逐步训练方案,以更有效地训练网络。
进一步扩展了GCA-LSTM模型的设计,并提出了更强大的双流GCA-LSTM网络。
提出的端到端网络在评估的基准数据集上产生最好的结果
本文提出的用于基于骨架的行为识别的GCA-LSTM网络包括全局情景记忆单元和两个LSTM层,如下图所示。First LSTM层用于编码骨架序列并初始化全局情景记忆单元。然后,将全局情景记忆的数据馈送到Second LSTM层,以帮助网络选择性地关注每个帧中的信息性关节,并进一步生成行为序列的注意力表示。接着,注意力表示被反馈到全局情景记忆单元以便对其进行细化。此外,作者为GCA-LSTM网络提出了一种周期性注意力机制。由于在注意力机制过程之后产生了精细的全局情景记忆,所以可以将全局情景记忆再次馈送到Second LSTM层以更可靠地执行注意力。作者进行多次关注迭代以逐步优化全局情景记忆。最后,全局情景送到Softmax分类器预测行为类别。
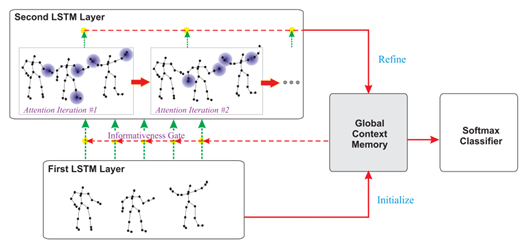
作者还扩展了GCA-LSTM网络的设计,并进一步提出了一种双流GCA-LSTM,它结合了细粒度(关节级)注意力和粗粒度(身体部分级)注意力,以达到更准确的行为识别结果。
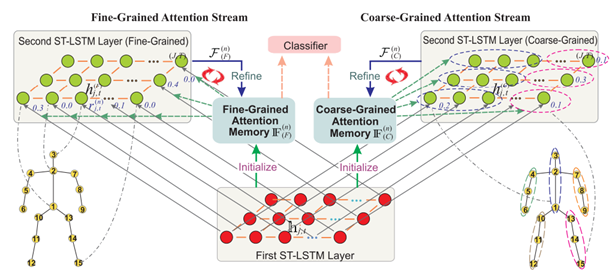
双流GCA-LSTM网络,包括细粒度(关节级)注意力和粗粒度(身体部分级别)注意力。为了进行粗粒度注意力,骨骼中的关节被分成五个身体部位,来自同一身体部位的所有关节共享相同的信息得分。在用于粗粒度注意力的第二ST-LSTM层中,仅在每个帧处示出两个身体部位,并且为了清楚起见而省略了其他身体部位。
2.5.5 基于骨架方法五
在本文中,作者提出了一种新的注意力增强图卷积LSTM网络Attention Enhanced Graph Convolutional LSTM Network(AGC-LSTM),用于从骨架数据识别人类行为。所提出的AGC-LSTM不仅可以捕获空间配置和时间动态的判别特征,还可以探索空间域和时域之间的共现关系。作者还提出了一种时间层次结构,以增加顶级AGC-LSTM层的时间感受野,这提高了学习高级语义表示的能力,并显着降低了计算成本。此外,为了选择判别空间信息,作者采用注意力机制来增强每个AGC-LSTM层中关键关节的信息。
- 主要贡献:
提出了一种新颖的通用AGC-LSTM网络,用于基于骨架的行为识别,这是图卷积LSTM首次尝试此类任务。
所提出的AGC-LSTM能够有效地捕获有辨别力的时空特征。更具体地说,采用注意力机制来增强关键节点的特征,这有助于改善时空表达。
提出了一种时间层次结构,以提高学习高级时空语义特征的能力,并显着降低计算成本。
所提出的模型在NTU RGB + D数据集和Northwestern-UCLA数据集上实现了最先进的结果。 作者进行了大量实验来证明模型的有效性。
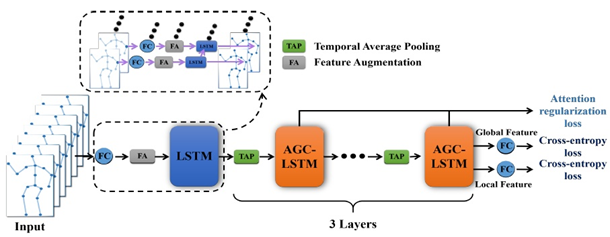
算法:所提出的AGC-LSTM网络架构如下图所示。首先,将每个关节的坐标转换为具有线性层的空间特征。然后,连接两个连续帧之间的空间特征和特征差异,以组成一个增强特征。为了消除两个特征之间的比例差异,采用共享LSTM来处理每个关节序列。应用三个AGC-LSTM层来模拟时空特征。由于AGC-LSTM中的图卷积算子,它不仅可以有效地捕获空间配置和时间动态的判别特征,而且可以探索空间域和时域之间的共现关系。即采用注意力机制来增强每个时间步的关键节点的特征,这可以促进AGC-LSTM学习更多的判别特征。受CNN空间池的启发,作者提出了一种时间层次结构,其时间平均池化以增加顶级AGC-LSTM层的时间感受野。最后,使用所有关节的全局特征和来自最后一个AGC-LSTM层的聚焦关节的局部特征来预测人类行为的类别。
3 应用场景
- 校园:可识别暴力,打斗,侵害,逃课等行为;高空抛物,趴阳台等;禁区闯入,如楼顶,围墙外等;校园内部失窃,失火,触电,溺水,中毒等;体育,化学课中的意外情况等。
- 养老院:监控老人们的状态如活动状态,睡眠状态等,当出现各种异常情况时立即预警。
- 工地:在安全生产区域内识别检测在岗人员是否佩戴安全帽,是否进行违规操作以及危险动作,如有发现,则输出报警信息,通知后台人员。
- 景区:识别异常聚集,奔跑动作,逃票行为等。
- 监狱:识别打架斗殴等行为。
- 工厂:检测各种类别事件:打电话,安全帽,安全带检测,打架,离岗事件等。
- 驾驶:利用麦克风和摄像头去识别驾驶员的情绪和肢体动作等,防止交通事故的发生。
4 难点
-
巨大的计算成本:对于101类别的2D网络参数为5M,而对于相同的3D网络需要33M。在UCF101 上训练3D ConNet需要3到4天,在Sports-1M上训练大约需要两个月,这使得广泛的框架搜索变得困难,并且容易发生过拟合。
-
捕捉长期上下文:动作识别涉及跨帧捕获时空上下文。 另外,捕获的空间信息必须补偿相机移动。 即使具有强大的空间物体检测也不够,因为运动信息也携带更精细的细节。 关于运动信息存在局部和全局背景,需要捕获这些背景以进行稳健的预测。
光流在行为识别中是不可或缺的特征信息,但是提取多少帧的光流依然是不确定的,对于不同的行为,提取帧数是不同的,因此很难确定统一的帧数。 -
设计分类架构:设计可以捕获时空信息的架构涉及多个选项,这些选项非常重要且评估成本高昂。 例如,一些可能的策略可能是:一个用于捕获时空信息的网络VS一个用于每个空间和时间的两个独立信息的网络;融合多个剪辑的预测;端到端训练 VS特征提取和单独分类;自基于深度学习的行为检测算法提出以来,不同的学者在one stream, two stream, skeleton-based 等多种类别方法,也使用了CNN, RNN,GCN,RL等多种学习方法,设计了大量的分类结构,但依然存在着许多的问题,亟待解决。
-
没有标准的基准
其他: 类内和类间差异,环境差异,时间变化等
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/152024.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
