大家好,又见面了,我是你们的朋友全栈君。
随着深度学习技术的发展,以及计算能力的进步(GPU等),现在基于视频的研究领域越来越受到重视。视频与图片最大的不同在于视频还包含了时序上的信息,此外需要的计算量通常也大很多。
这篇主要介绍Action Recognition(行为识别)这个方向。这个方向的主要目标是判断一段视频中人的行为的类别,所以也可以叫做Human Action Recognition。虽然这个问题是针对视频中人的动作,但基于这个问题发展出来的算法,大都不特定针对人,也可以用于其他类型视频的分类。
背景介绍
什么是动作识别?
动作识别的主要目标是判断一段视频中人的行为的类别,所以也可以叫做 Human Action Recognition。
动作识别的难点在哪里?
(1)类内和类间差异, 同样一个动作,不同人的表现可能有极大的差异。
(2)环境差异, 遮挡、多视角、光照、低分辨率、动态背景.
(3)时间变化, 人在执行动作时的速度变化很大,很难确定动作的起始点,从而在对视频提取特征表示动作时影响最大。
(4)缺乏标注良好的大的数据集
有那些解决方法?
最好的传统的方法? iDT
当前的深度学习的方法?
- RGB + 光流
- 3D卷积
- lstm + 单帧
- skeleton(数据集缺乏)
视频中的人体行为识别主要包括两个方向:Action Recognition 以及 Temporal Action Localization:
- Action Recognition的目的是给定一个视频片段进行分类,类别通常是人的各类动作。特点是简化了问题,一般使用的数据库都先将动作分割好了,一个视频片断中包含一段明确的动作,时间较短(几秒钟)且有唯一确定的label。所以也可以看作是输入为视频,输出为动作标签的多分类问题。常用数据库包括UCF101,HMDB51等。相当于对视频进行分类。
- Temporal Action Localization 则不仅要知道一个动作在视频中是否发生,还需要知道动作发生在视频的哪段时间(包括开始和结束时间)。特点是需要处理较长的,未分割的视频。且视频通常有较多干扰,目标动作一般只占视频的一小部分。常用数据库包括HUMOS2014/2015, ActivityNet等。相当于对视频进行指定行为的检测。
- action recognition与temporal action detection之间的关系,同 image classfication与 object detection之间的关系非常像。基于image classification问题,发展出了许多强大的网络模型(比如ResNet,VGGNet等),这些模型在object detection的方法中起到了很大的作用。同样,action recognition的相关模型(如two stream,C3D, iDT等)也被广泛的用在temporal action detection的方法中。
数据集
The HMDB-51 dataset(2011)
Brown university 大学发布的 HMDB51, 视频多数来源于电影,还有一部分来自公共数据库以及YouTube等网络视频库.数据库包含有6849段样本,分为51类,每类至少包含有101段样本。
UCF-101(2012)
来源为YouTube视频,共计101类动作,13320段视频。共有5个大类的动作:
1)人-物交互;2)肢体运动;3)人-人交互;4)弹奏乐器;5)运动.
[Sport-1M(2014)] (https://cs.stanford.edu/people/karpathy/deepvideo/)
Sports1M 包含487类各项运动, 约110万个视频. 此外,Sports1M 的视频长度平均超过 5 分钟,而标签预测的动作可能仅在整个视频的很小一部分时间中发生。 Sports1M 的标注通过分析和 youtube视频相关的文本元数据自动地生成,因此是不准确的。
Kinetics-600是一个大规模,高质量的YouTube视频网址数据集,其中包括各种人的行动。
该数据集由大约50万个视频剪辑组成,涵盖600个人类行为类,每个行为类至少有600个视频剪辑。每个剪辑持续约10秒钟,并标记一个类。所有剪辑都经过了多轮人工注释,每个剪辑都来自单独的YouTube视频。这些行为涵盖了广泛的类别,包括人与物体的互动,如演奏乐器,以及人与人之间的互动,如握手和拥抱。
算法
光流
光流是视觉领域的一个独立分支
光流通常被表述为估计世界真实三维运动的二维投影的问题。
In spite of the fast computation time (0.06s for a pair of frames),

 

(a)(b) 视频中的连续的两帧, (c) 蓝绿色框中的光流信息, (d) 位移向量的水平信息, (e) 位移向量的垂直信息;
iDT
iDT(13年)(improved dense trajectories(轨迹))
iDT 方法(是深度学习进入该领域前效果最好,稳定性最好,可靠性最高的方法,不过算法速度很慢(在于计算光流速度很慢)。
基本思路为利用光流场来获得视频序列中的一些轨迹,再沿着轨迹提取HOF,HOG,MBH,trajectory4种特征,其中HOF基于灰度图计算,另外几个均基于dense optical flow(密集光流)计算。最后利用FV(Fisher Vector)方法对特征进行编码,再基于编码结果训练SVM分类器。
早期研究
Large-scale Video Classification with Convolutional Neural Networks(2014)
2DCNN, 能不能自动的捕捉运动信息?
- single frame
- stacked frames
双流法
迁移学习
- 最后一层(或者最后L层)
- fine-tune 所有层(小学习率)
Two-Stream Convolutional Networks for Action Recognition in Videos(2014)
双流架构:
- 空域网络(spatial networks)
- 时域网络(temporal networks)
理论支撑: 双流体系结构与双流假设相关,即人类视觉皮层包含两条路径, 如下
- 腹侧流(ventral stream, 执行物体识别)
- 背侧流(dorsal stream, 识别运动信息)
将空时网络解耦的好处:
时域网络可以使用预训练的 ImageNet 上预训练的模型.

TSN: Temporal Segment Networks: Towards Good Practices for Deep Action Recognition(2016)
光流的作用
On the Integration of Optical Flow and Action Recognition(2017) (2018CVPR)
大多数表现优秀的动作识别算法使用光流作为“黑匣子”输入。 在这里,我们更深入地考察光流与动作识别的结合,并研究为什么光流有帮助, 光流算法对动作识别有什么好处,以及如何使其更好。
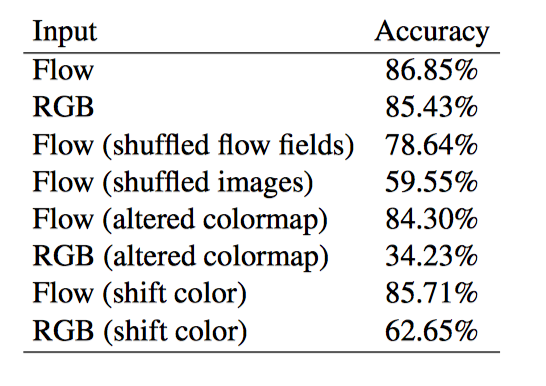
实验结果表明: 当前体系结构中光流的大部分价值在于它对场景表示的表观不变(invariant to appearance), 也表明运动轨迹不是光流成功的根源,并且建立有用的运动表示仍然是光流自身无法解决的一个悬而未决的问题。
由于光流是从图像序列计算出来的,所以有人可能会争辩说,训练有素的网络可以学习如何计算光流,如果光流是有用的,则不需要明确计算光流。
尽管使用显式运动估计作为涉及视频任务的输入可能看起来很直观,但人们可能会争辩说使用运动并不是必需的。 一些可能的论点是,当前数据集中的类别可以从单帧中识别出来,并且可以从单帧中识别视觉世界中更广泛的许多对象和动作.
C3D
Learning Spatiotemporal Features with 3D Convolutional Networks(2015)
3D 卷积
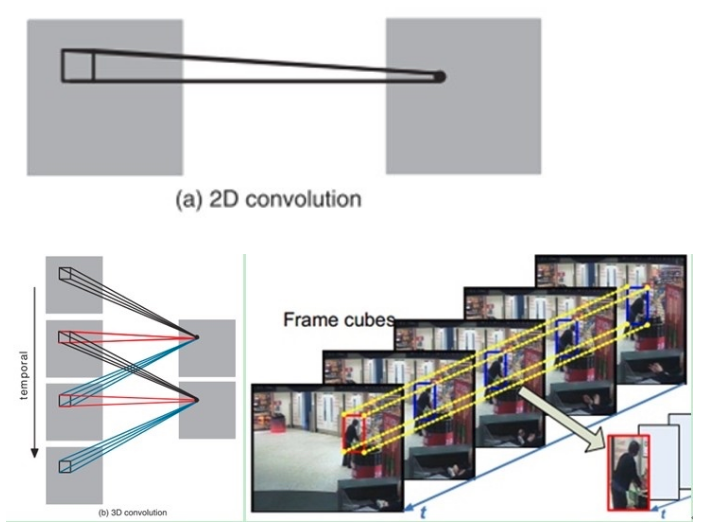
C3D能把 ImageNet 的成功(迁移学习)复制到视频领域吗?
 

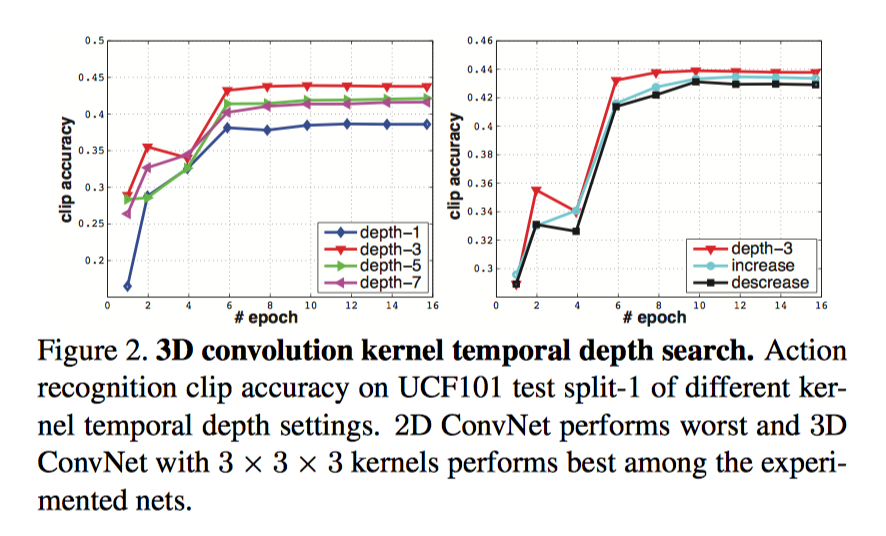 

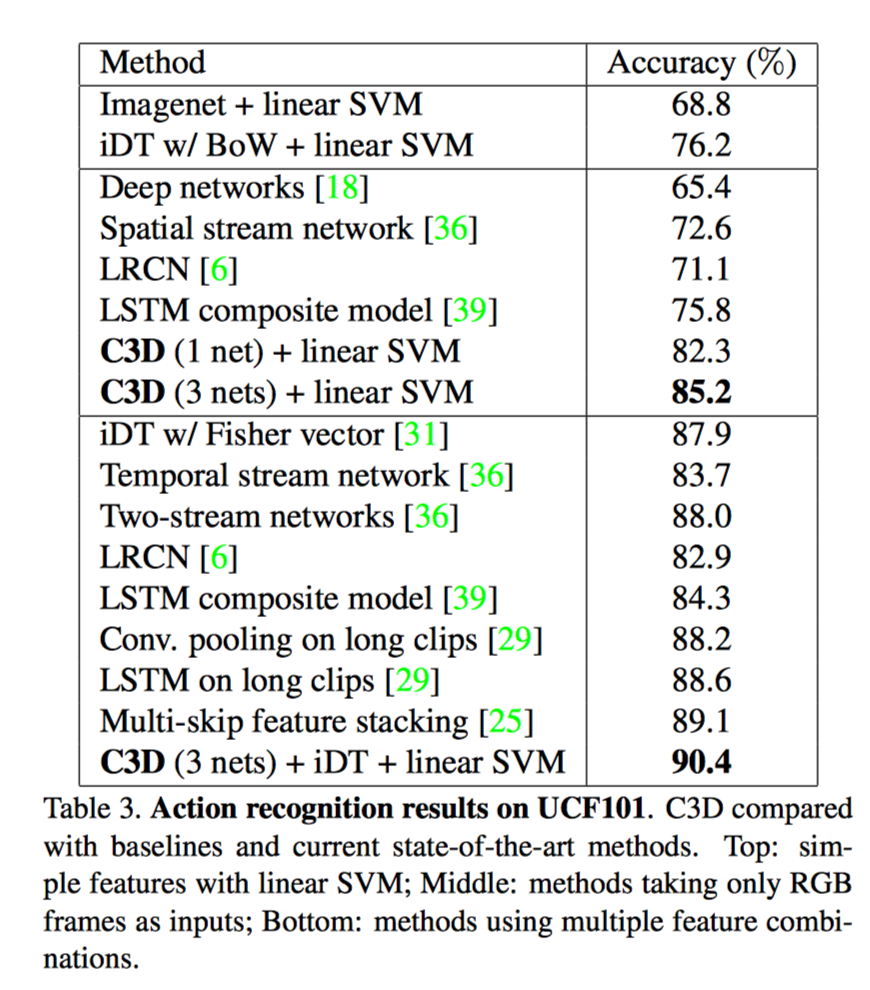 

速度
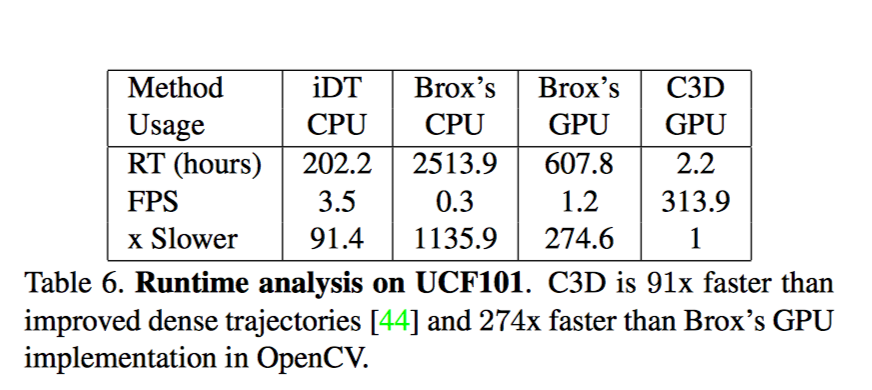 

iDT官方提供的计算法方法没有 GPU 版本
Brox一种计算光流的方法; 包括 I/O 时间, 平均一组图片的光流计算时间为0.85-0.9s
———————————————我———–是————分————割————–线——————————————————–
==============================================================================================
下图为目前主流模型的比较。其中T3D标称效果好于I3D,但由于结果是作者复现得来,故在这里不做比较。顺序自上向下按UCF101的准确率排列。
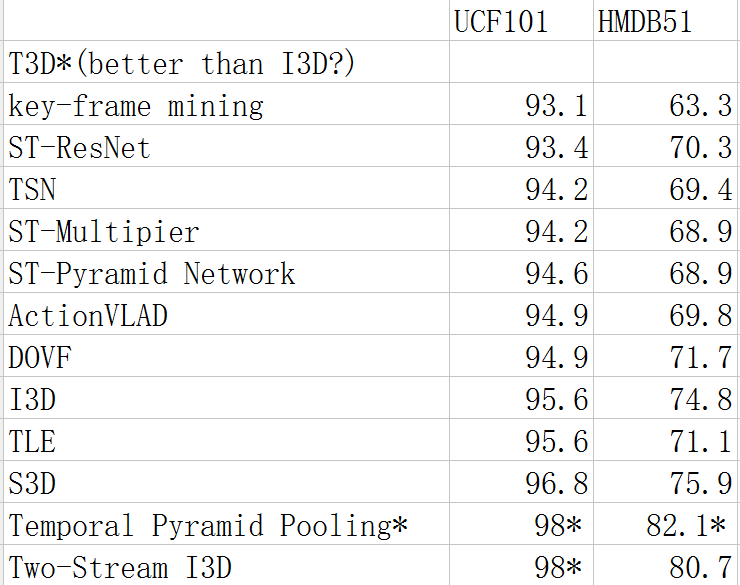
表中最后两个见下面4,7
目前Action Recognition的研究方向(发论文的方向)分为三大类。
- Structure
- Inputs
- Connection
Structure
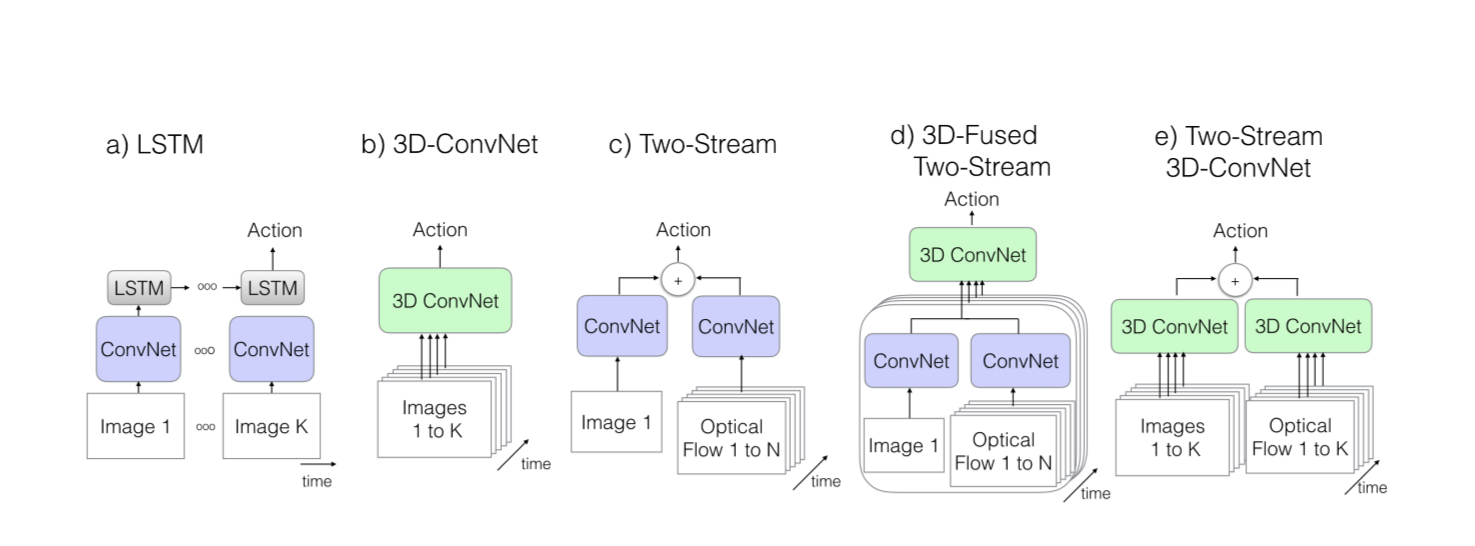
这里的结构主要指网络结构。目前,主流的结构都是基于 Two-Stream Convolutional Networks和 C3D 发展而来,所以这一块内容也主要讨论这两种结构的各种演化中作为benchmark的一些结构。
1.
首先讨论TSN模型,这是港中文汤晓鸥组的论文,也是目前的benchmark之一,许多模型也是在TSN的基础上进行了后续的探索。
Temporal Segment Networks: Towards Good Practices for Deep Action Recognition【ECCV2016】
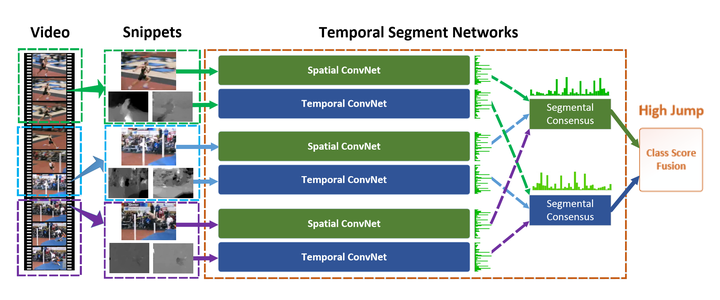
该论文继承了双流网络的结构,但为了解决long-term的问题,作者提出使用多个双流网络,分别捕捉不同时序位置的short-term信息,然后进行融合,得到最后结果。
2.
Deep Local Video Feature for Action Recognition 【CVPR2017】
TSN改进版本之一。
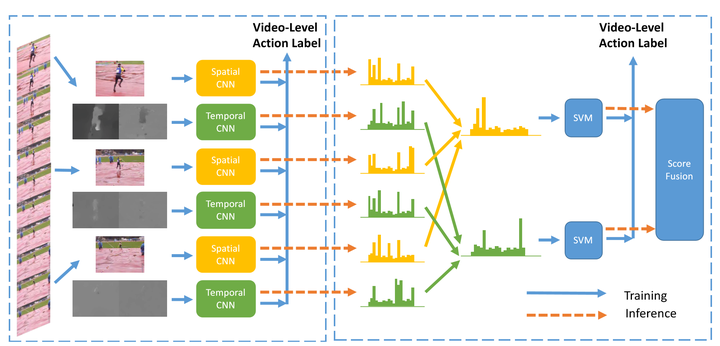
改进的地方主要在于fusion部分,不同的片段的应该有不同的权重,而这部分由网络学习而得,最后由SVM分类得到结果。
3.
Temporal Relational Reasoning in Videos
TSN改进版本二。
这篇是MIT周博磊大神的论文,作者是也是最近提出的数据集 Moments in time 的作者之一。
该论文关注时序关系推理。对于哪些仅靠关键帧(单帧RGB图像)无法辨别的动作,如摔倒,其实可以通过时序推理进行分类。如下图。

除了两帧之间时序推理,还可以拓展到更多帧之间的时序推理
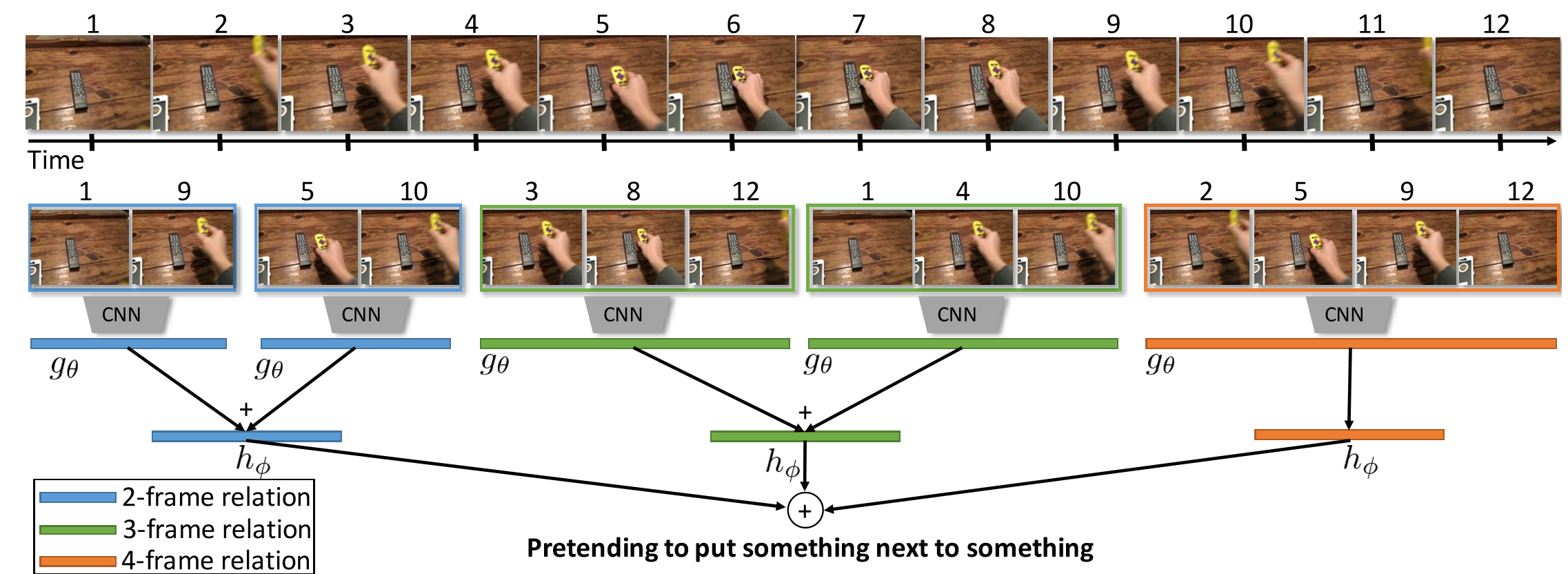
通过对不同长度视频帧的时序推理,最后进行融合得到结果。
该模型建立TSN基础上,在输入的特征图上进行时序推理。增加三层全连接层学习不同长度视频帧的权重,及上图中的函数g和h。
除了上述模型外,还有更多关于时空信息融合的结构。这部分与connection部分有重叠,所以仅在这一部分提及。这些模型结构相似,区别主要在于融合module的差异
4.Two-Stream I3D
动作在单个帧中可能不明确,然而, 现有动作识别数据集的局限性意味着性能最佳的视频架构不会明显偏离单图分析,因为他们依赖在ImageNet上训练的强大图像分类器。
数据集: Kinetics
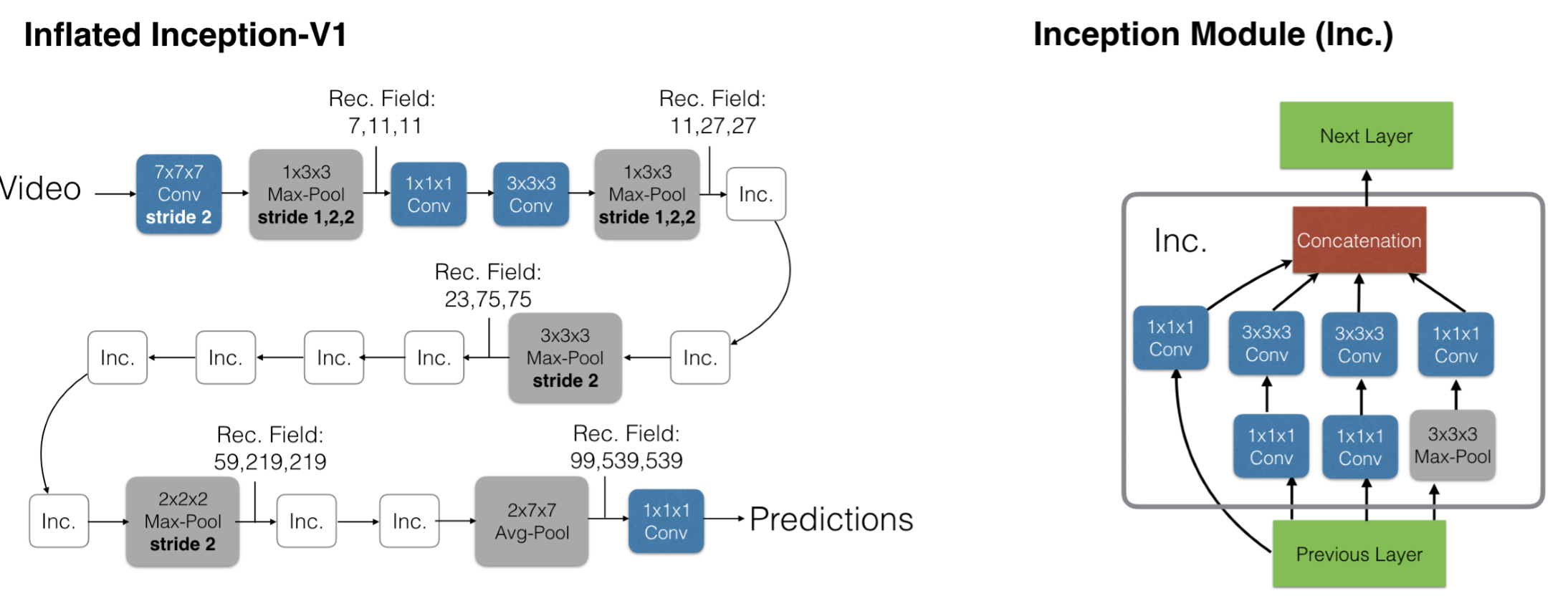
即基于inception-V1模型,将2D卷积扩展到3D卷积。
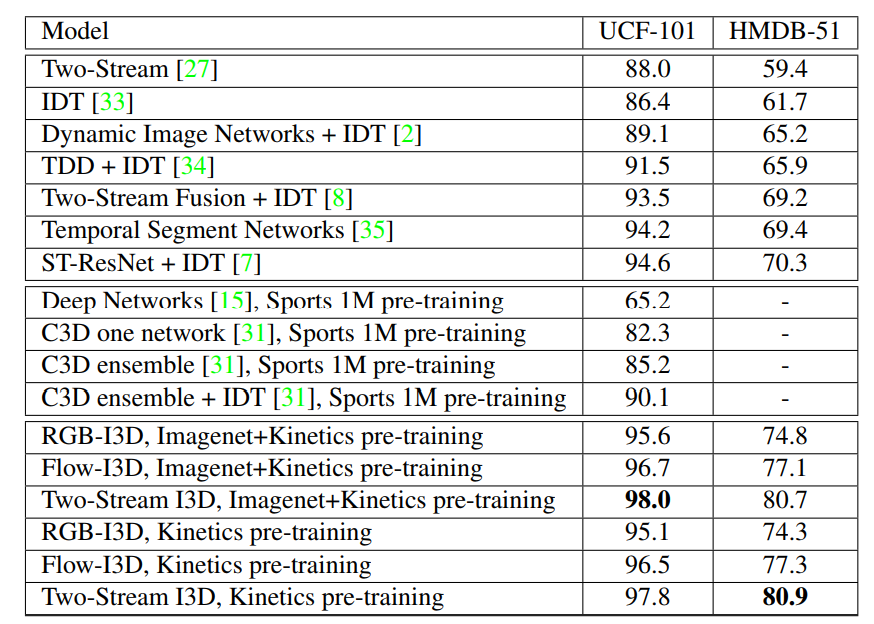
I3D 性能更好的原因:
一是 I3D的架构更好,
二是 Kinetic 数据集更具有普适性
5.
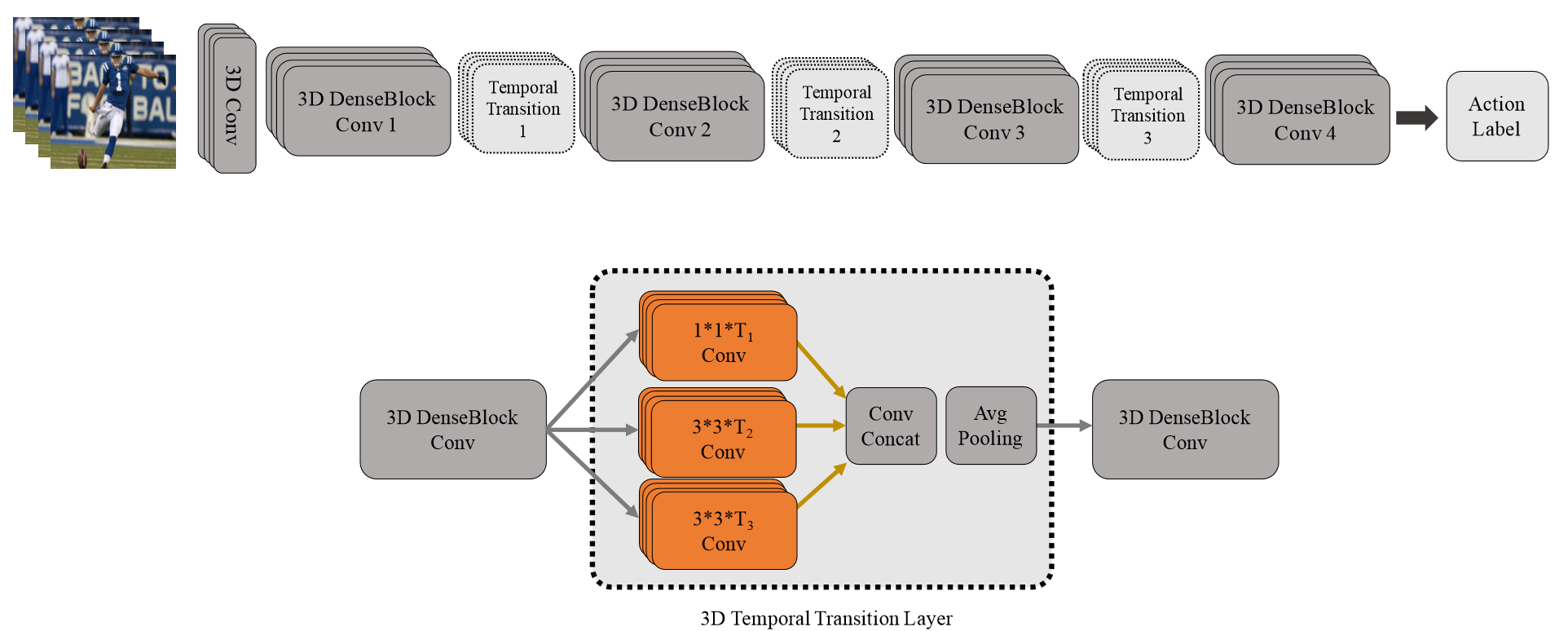
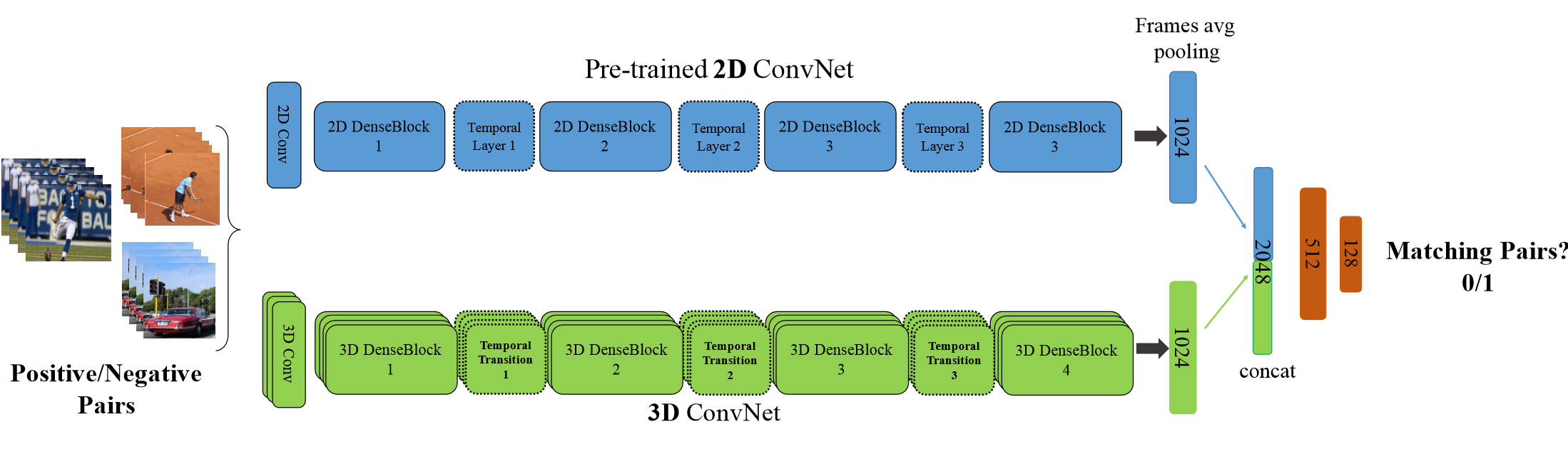
该论文值得注意的,一方面是采用了3D densenet,区别于之前的inception和Resnet结构;另一方面,TTL层,即使用不同尺度的卷积(inception思想)来捕捉讯息。
6.
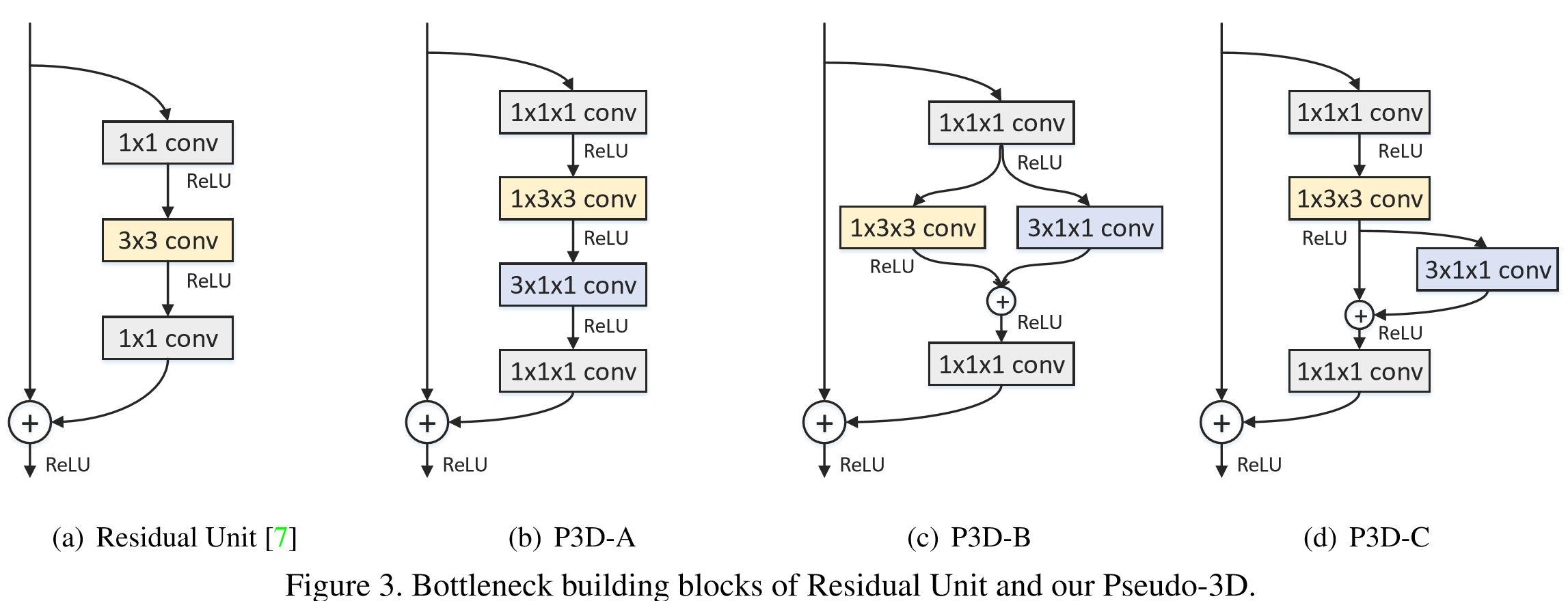
改进ResNet内部连接中的卷积形式。然后,超深网络,一般人显然只能空有想法,望而却步
7.
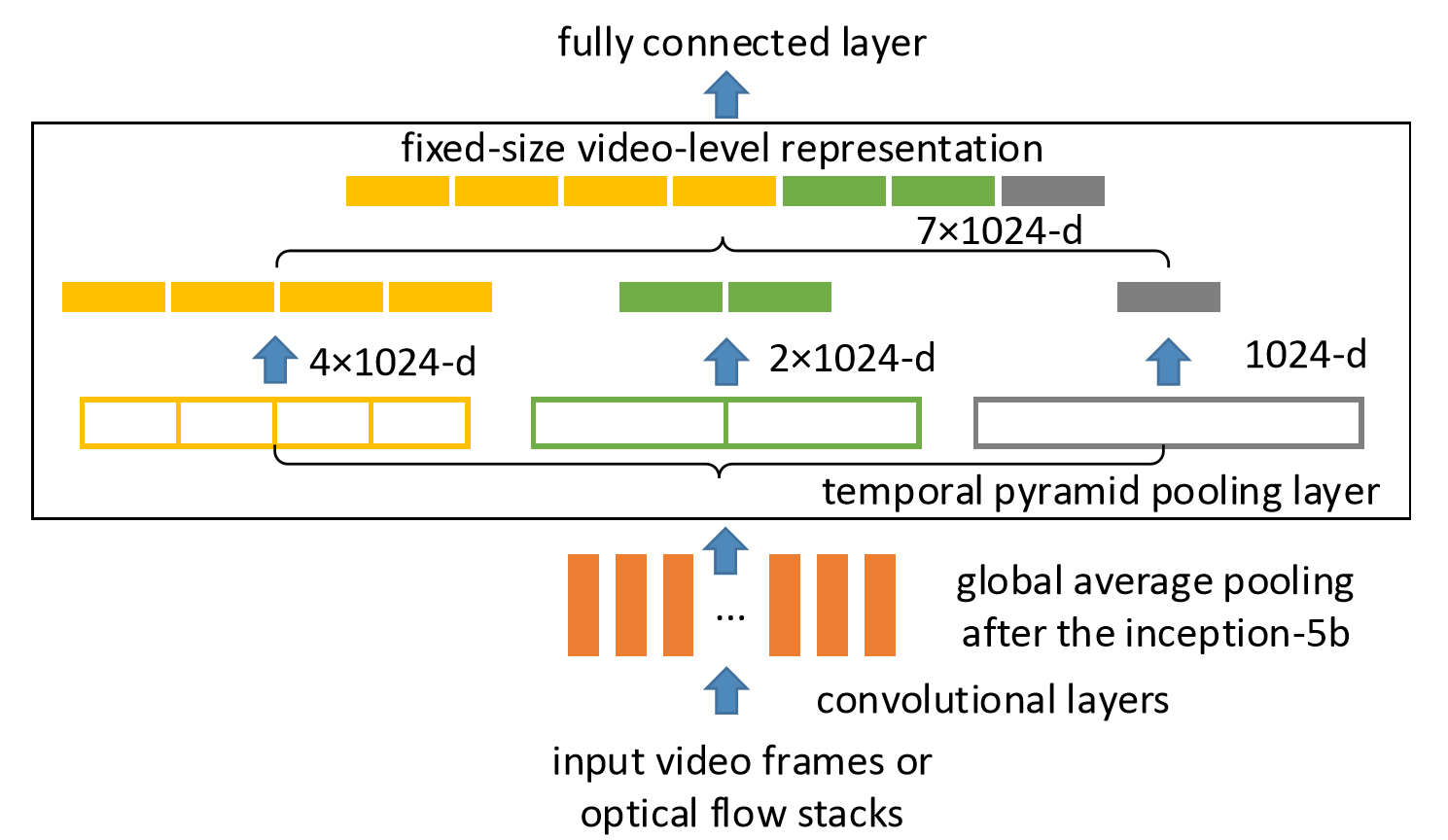
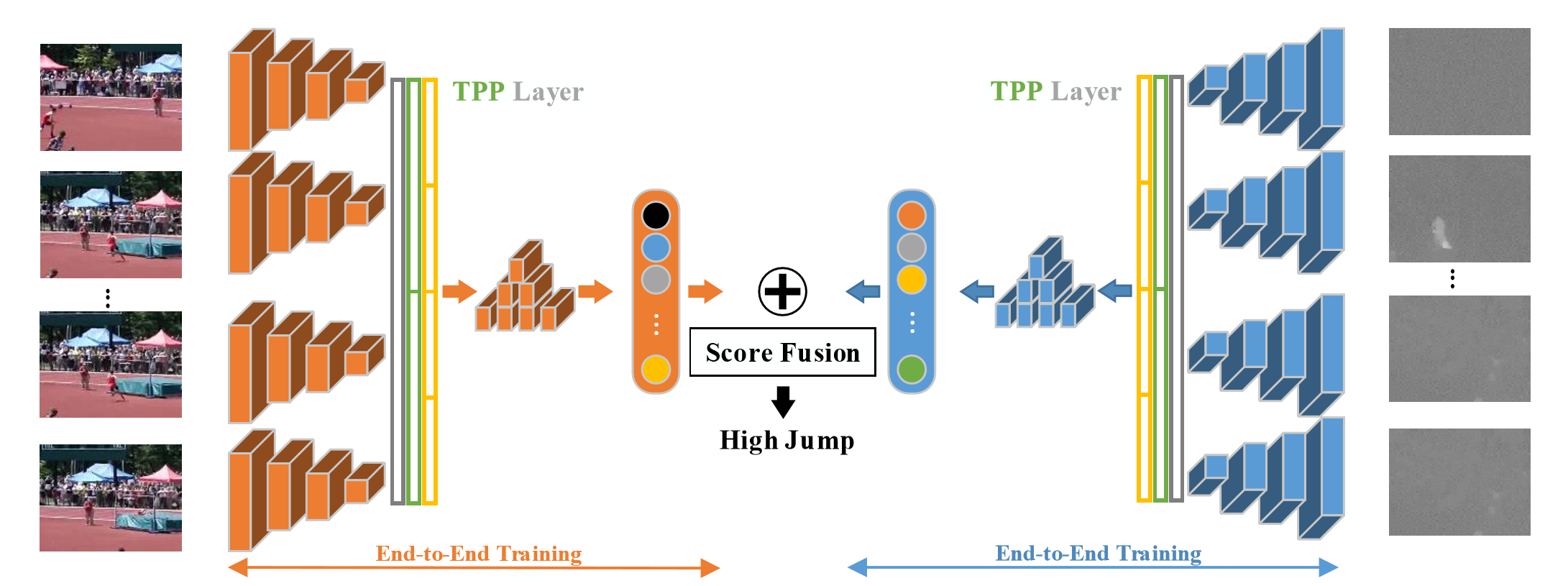
Pooling。时空上都进行这种pooling操作,旨在捕捉不同长度的讯息。
In this paper, we propose Deep networks with Temporal Pyramid Pooling (DTPP), an end-to-end video-level representation learning approach.
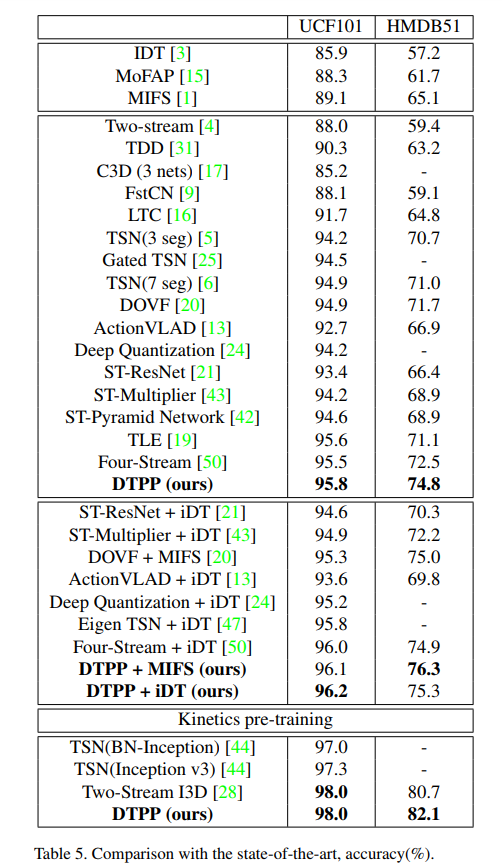
Finally, DTPP achieves the state-of-the-art performance on UCF101 and HMDB51, either by ImageNet pre-training or Kinetics pre-training.
8.TLE

TLE层的核心.
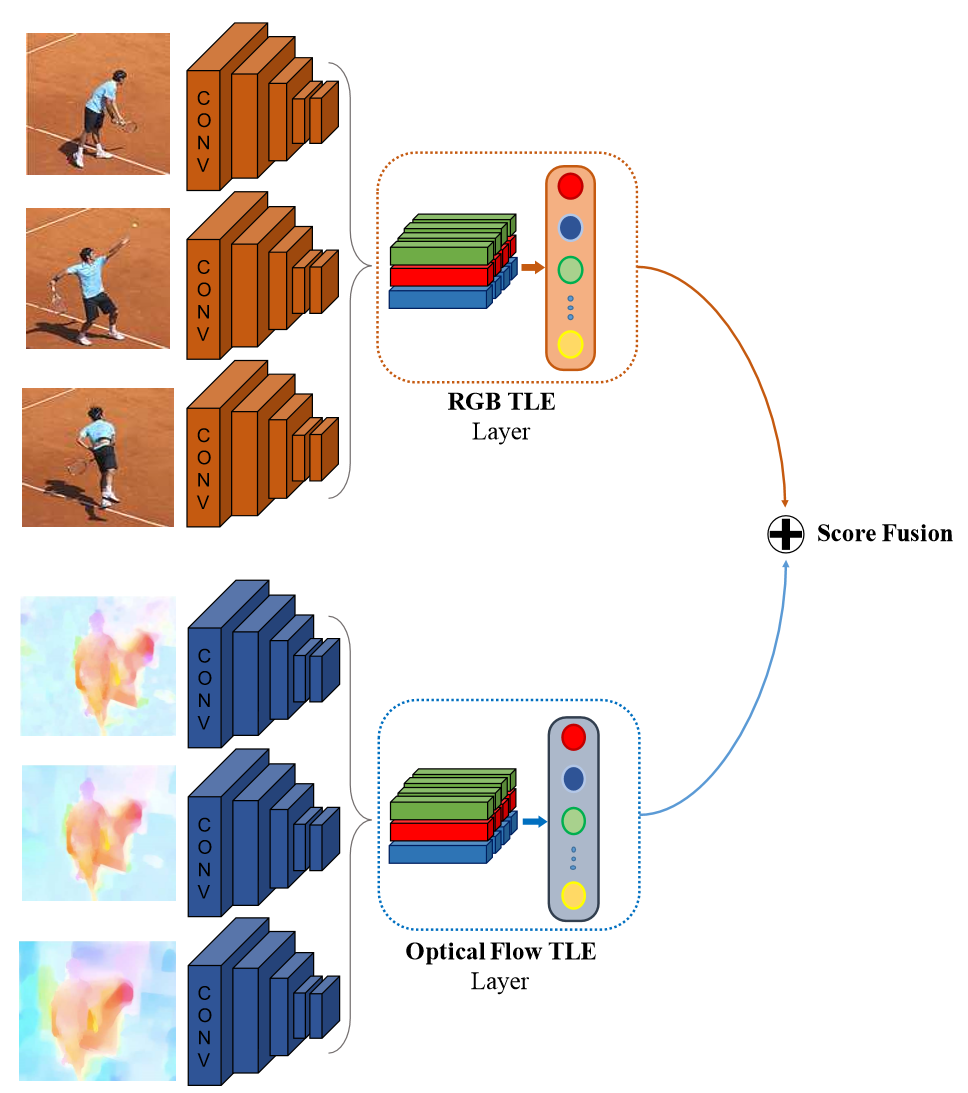
TLE层在双流网络中的使用。
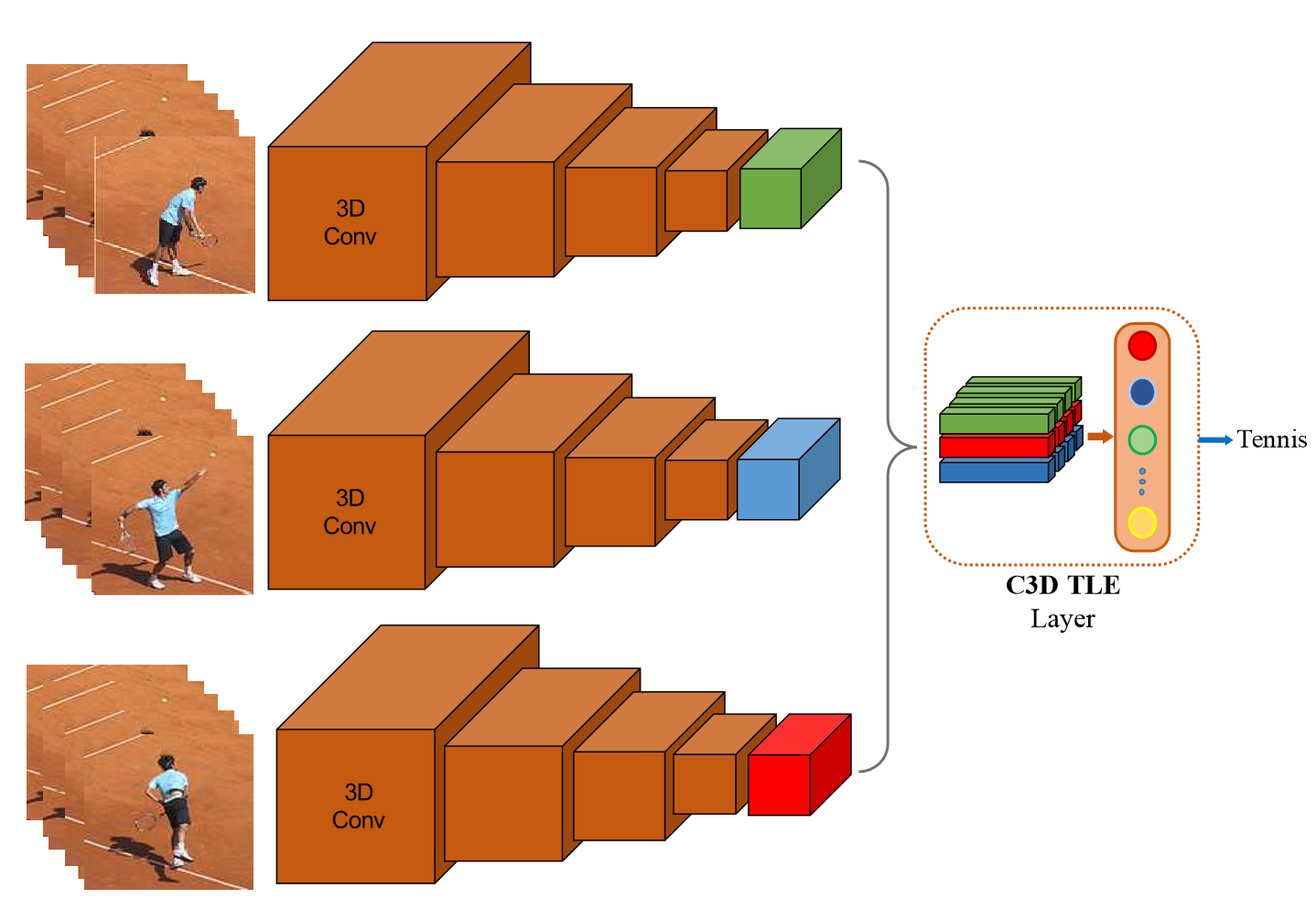
TLE层在C3D结构网络中的使用。
Connection
这里连接主要是指双流网络中时空信息的交互。一种是单个网络内部各层之间的交互,如ResNet/Inception;一种是双流网络之间的交互,包括不同fusion方式的探索,目前值得考虑的是参照ResNet的结构,连接双流网络。
这里主要讨论双流的交互。不同论文之间的交互方式各有不同。
9.
Spatiotemporal Multiplier Networks for Video Action Recognition【CVPR2017】
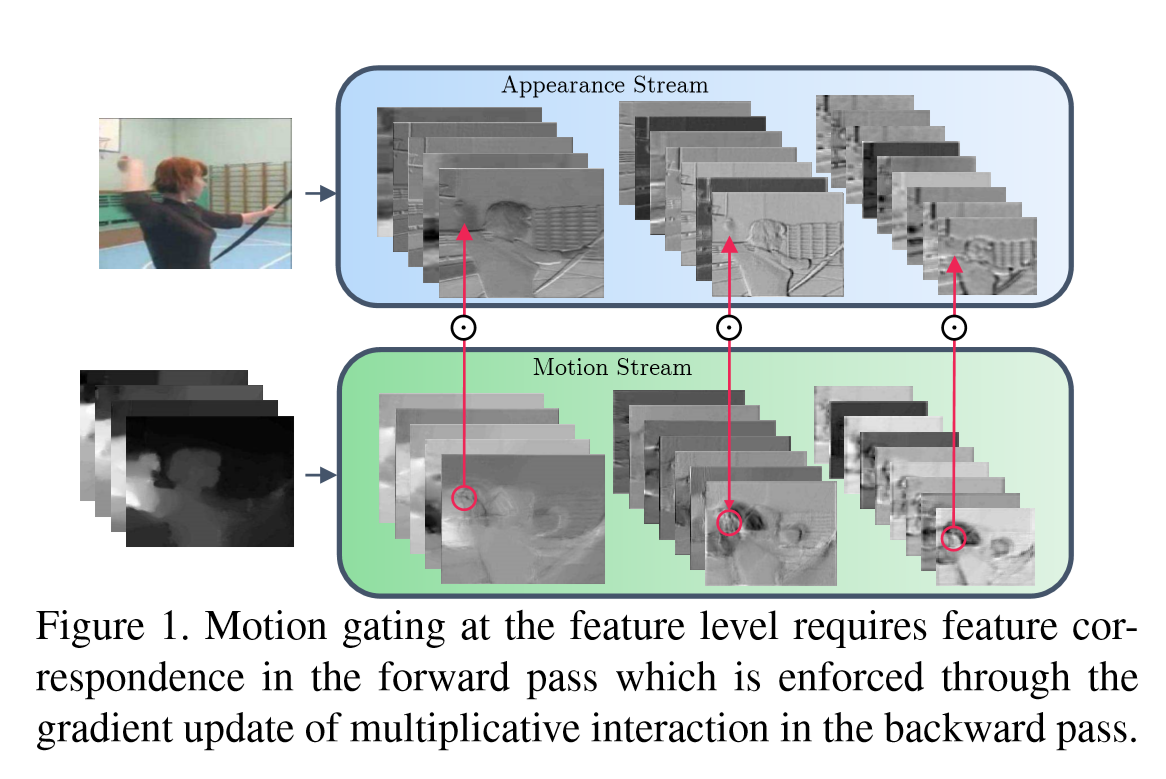
网络的结构如上图。空间和时序网络的主体都是ResNet,增加了从Motion Stream到Spatial Stream的交互。论文还探索多种方式。
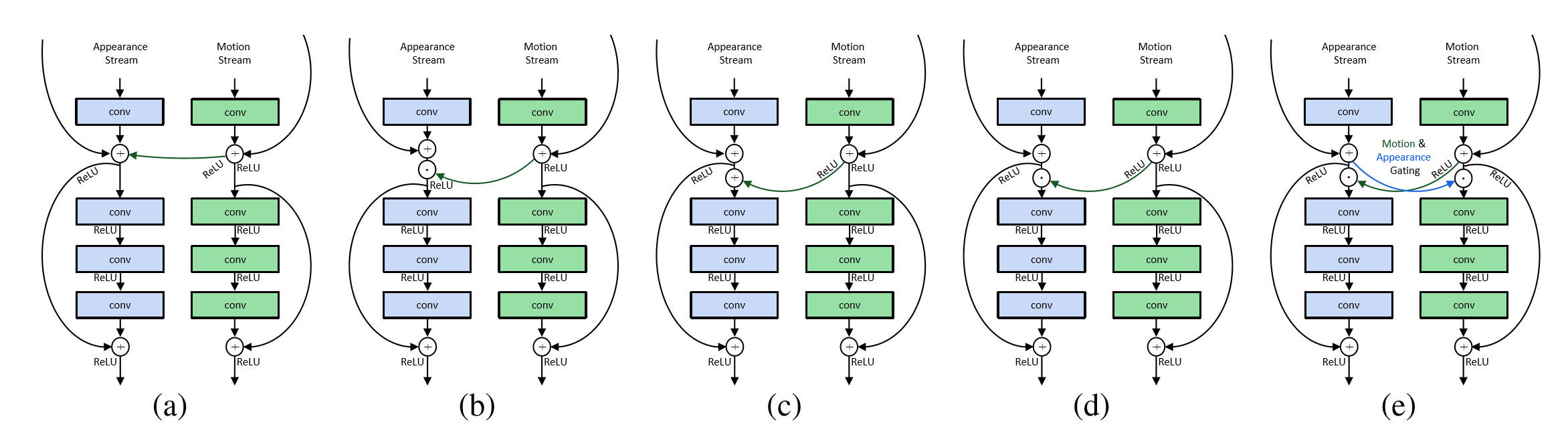
10.
Spatiotemporal Pyramid Network for Video Action Recognition 【CVPR2017】
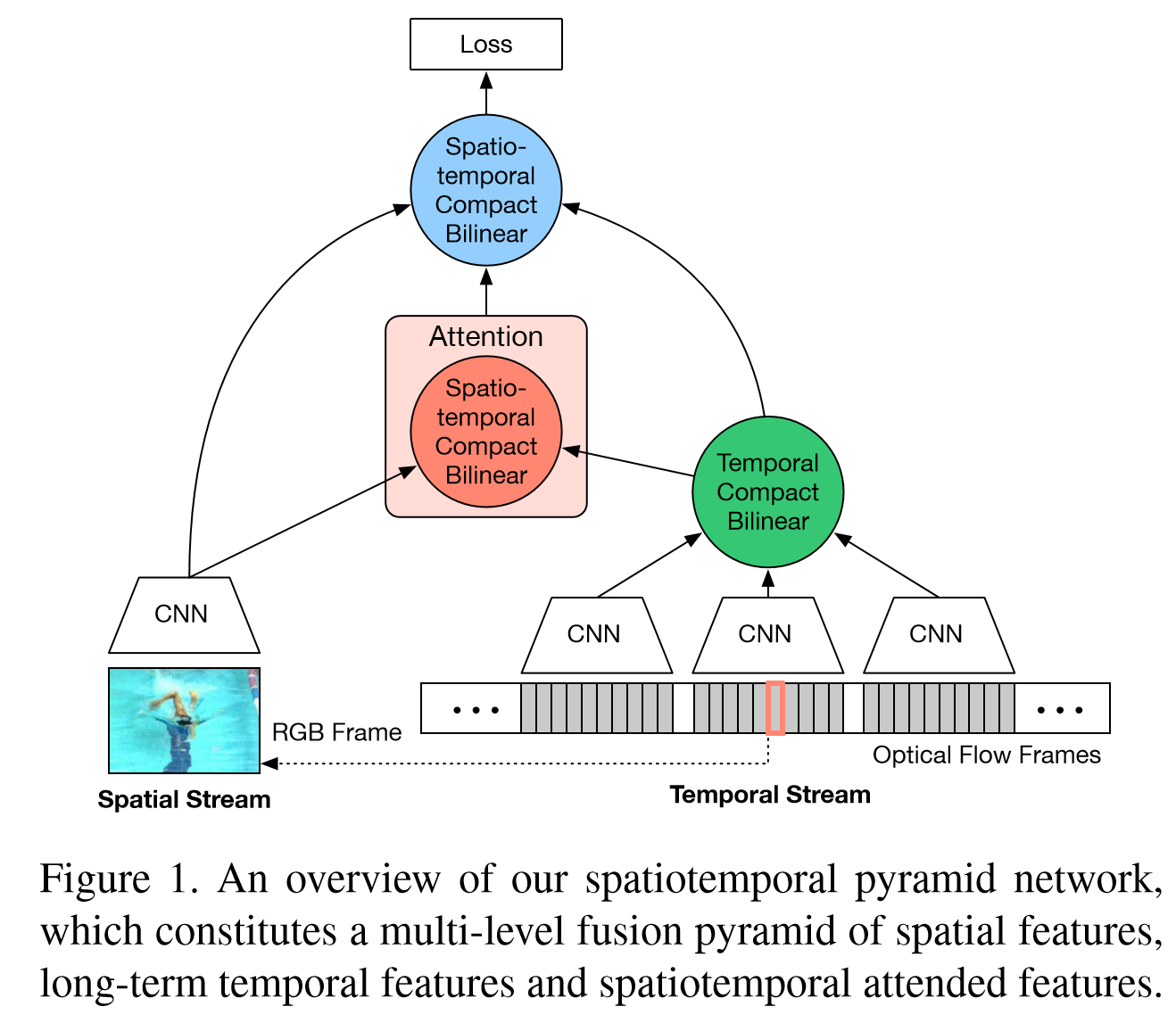
论文作者认为,行为识别的关键就在于如何很好的融合空间和时序上的特征。作者发现,传统双流网络虽然在最后有fusion的过程,但训练中确实单独训练的,最终结果的失误预测往往仅来源于某一网络,并且空间/时序网络各有所长。论文分析了错误分类的原因:空间网络在视频背景相似度高的时候容易失误,时序网络在long-term行为中因为snippets length的长度限制容易失误。那么能否通过交互,实现两个网络的互补呢
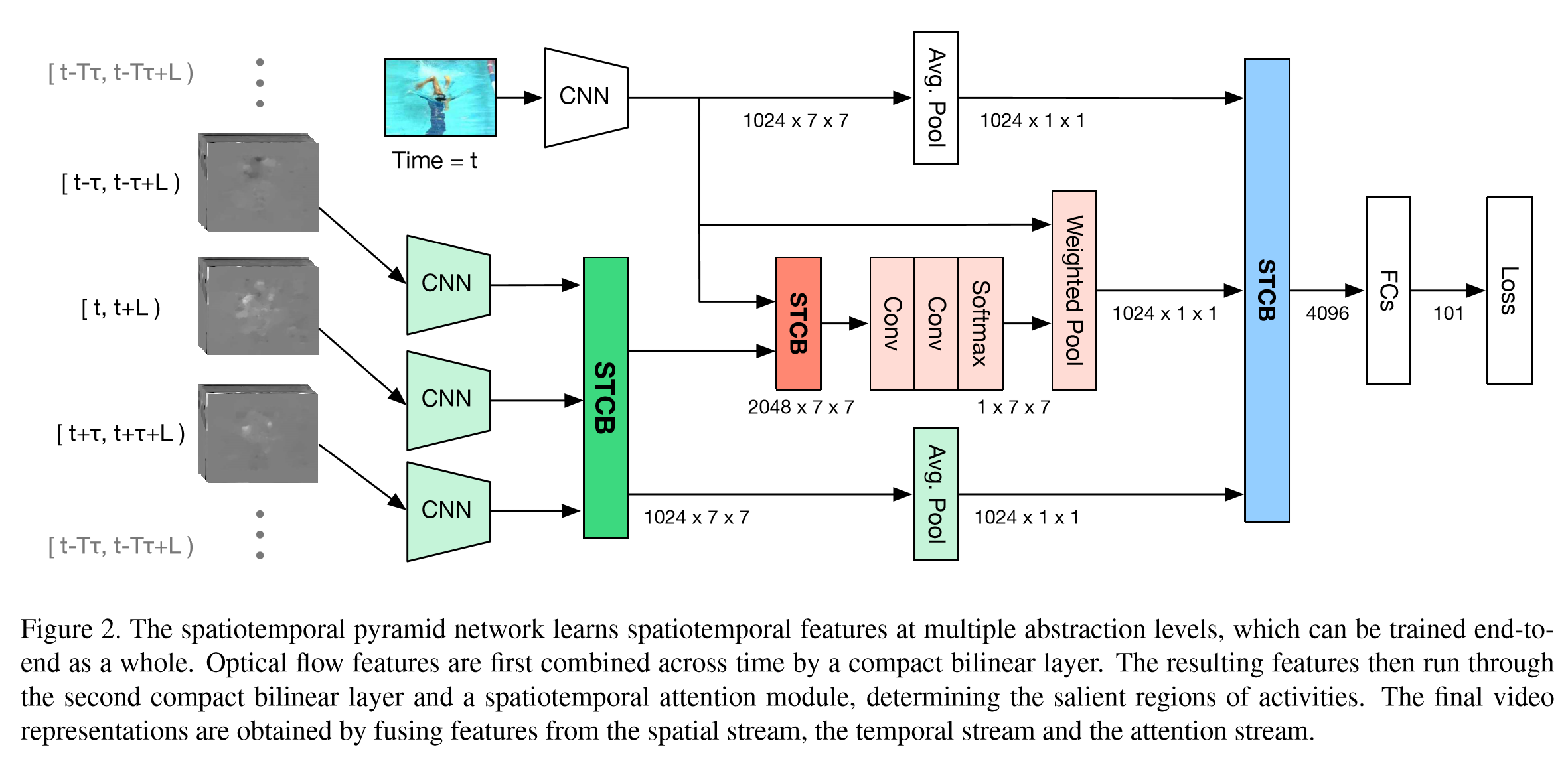
该论文重点在于STCB模块,详情请参阅论文。交互方面,在保留空间、时序流的同时,对时空信息进行了一次融合,最后三路融合,得出最后结果。
11.
Attentional pooling for action recognition 【NIPS2017】
12.
ActionVLAD for video action classification 【CVPR2017】
这两篇论文从pooling的层面提高了双流的交互能力,这两篇笔者还在看,有兴趣的读者请自行参阅论文。后期会附上论文的解读。
13.
Deep Convolutional Neural Networks with Merge-and-Run Mappings
这篇论文也是基于ResNet的结构探索新的双流连接方式。
14.
论文:Non-local Neural Networks for Video Classification
论文链接:https://arxiv.org/abs/1711.07971
代码链接:https://github.com/facebookresearch/video-nonlocal-net
通过特征学习到特征与特征之间的关系,这样类似于对全局特征做了attention,对于多帧的输入,不管是2D还是3D卷积,都提供了更多帮助学习action的信息。作者开源了代码,应该是目前的state-of-the-art。
总结:
- 在motion特征被理解之前,双流网络可能仍然是主流。
- 时空信息交互仍然有探索的余地,个人看来也是最有可能发论文的重点领域。
- 输入方面,替代光流的特征值得期待。
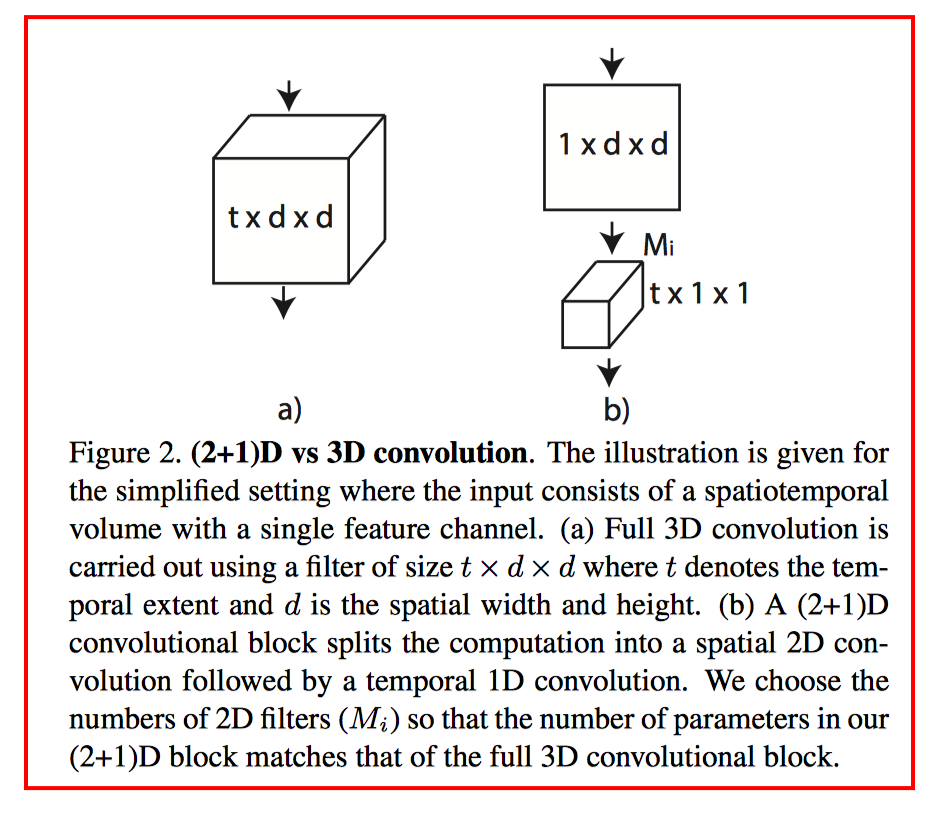
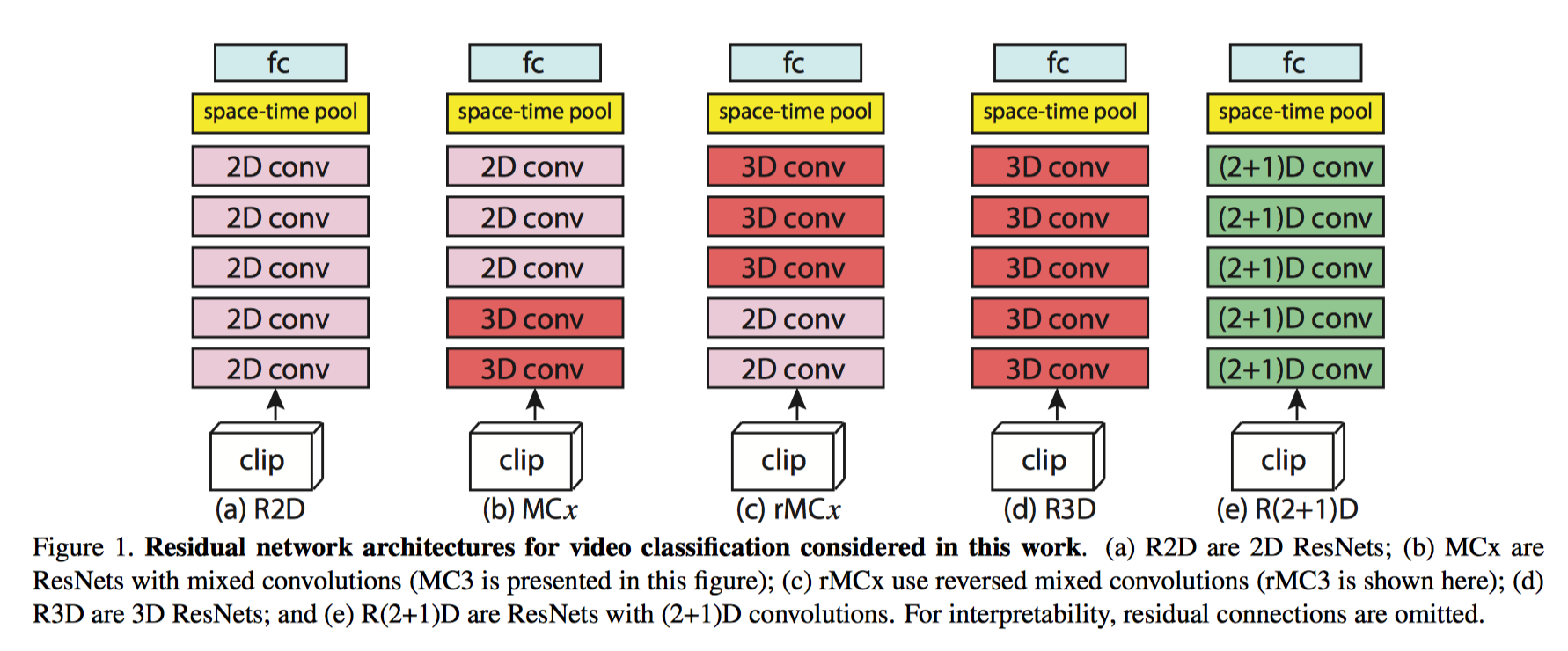
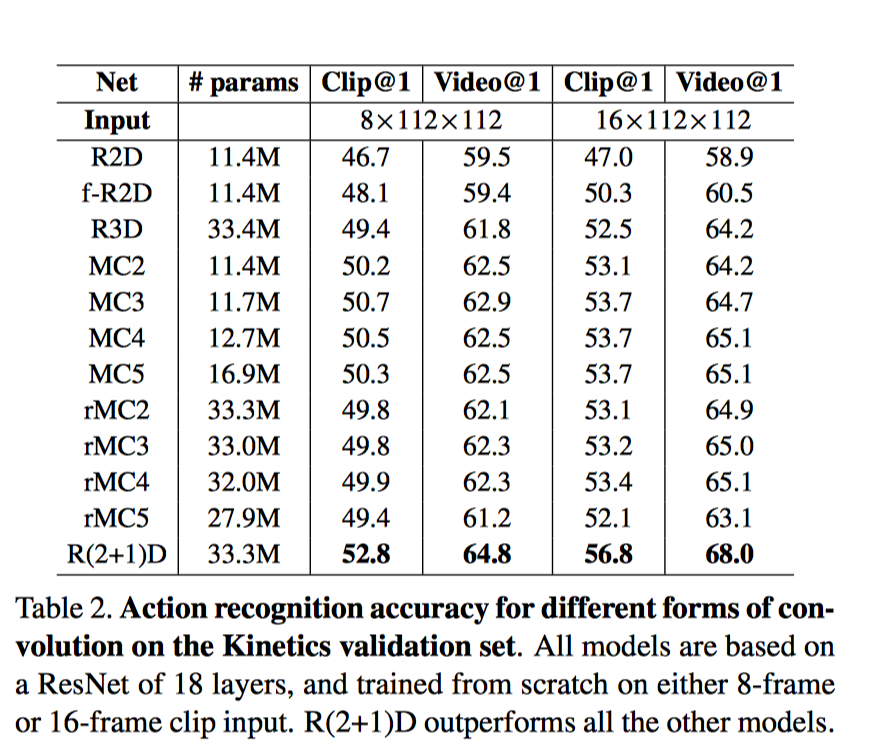
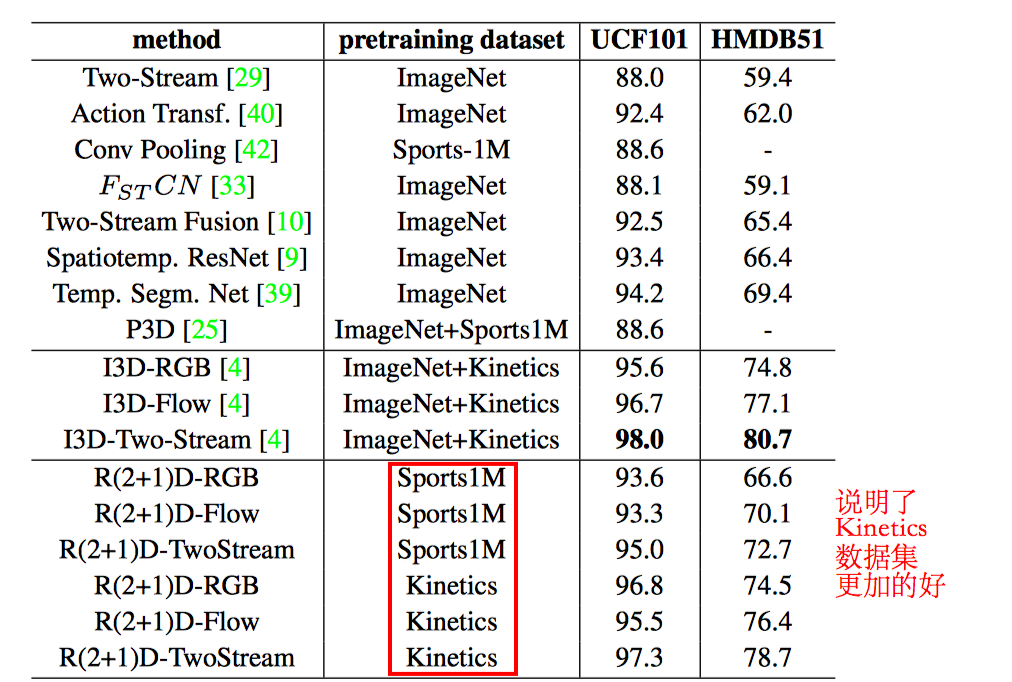
15.R(2+1)D
S3D?
P3D?
我们的研究动机源于观察到这样一个现象, 在动作识别中, 基于视频的单帧的2D CNN在仍然是不错的表现。
基于视频单帧的 2D CNN(RESNET-152[1])的性能非常接近的Sport-1M基准上当前最好的算法。这个结果是既令人惊讶和沮丧,因为2D CNN 无法建模时间和运动信息。基于这样的结果,我们可以假设,时间结构对的识别作用并不是至关重要,因为已经包含一个序列中的静态画面已经能够包含强有力的行动信息了。
研究目标: 我们表明,3D ResNets显著优于为相同的深度2D ResNets, 从而说明时域信息对于动作识别来说很重要.
[1]Learning spatio-temporal representation with pseudo-3d residual networks



16.ECO
论文标题:ECO: Efficient Convolutional Network for Online Video Understanding, ECCV 2018
github主页:https://github.com/mzolfaghari/ECO-efficient-video-understanding(提供了一个实时预测的接口)
主要贡献:
1. 采用离散采样的方法减少冗余帧,实现了online video understanding,轻量化网络的处理速度可以达到237帧/秒(ECO Lite-4F,Tesla P100,UCF-101 Accuracy为87.4%)。
2. 使用2D+3D卷积完成帧间信息融合。
备注:
1. 以下是ECO Lite的网络结构:
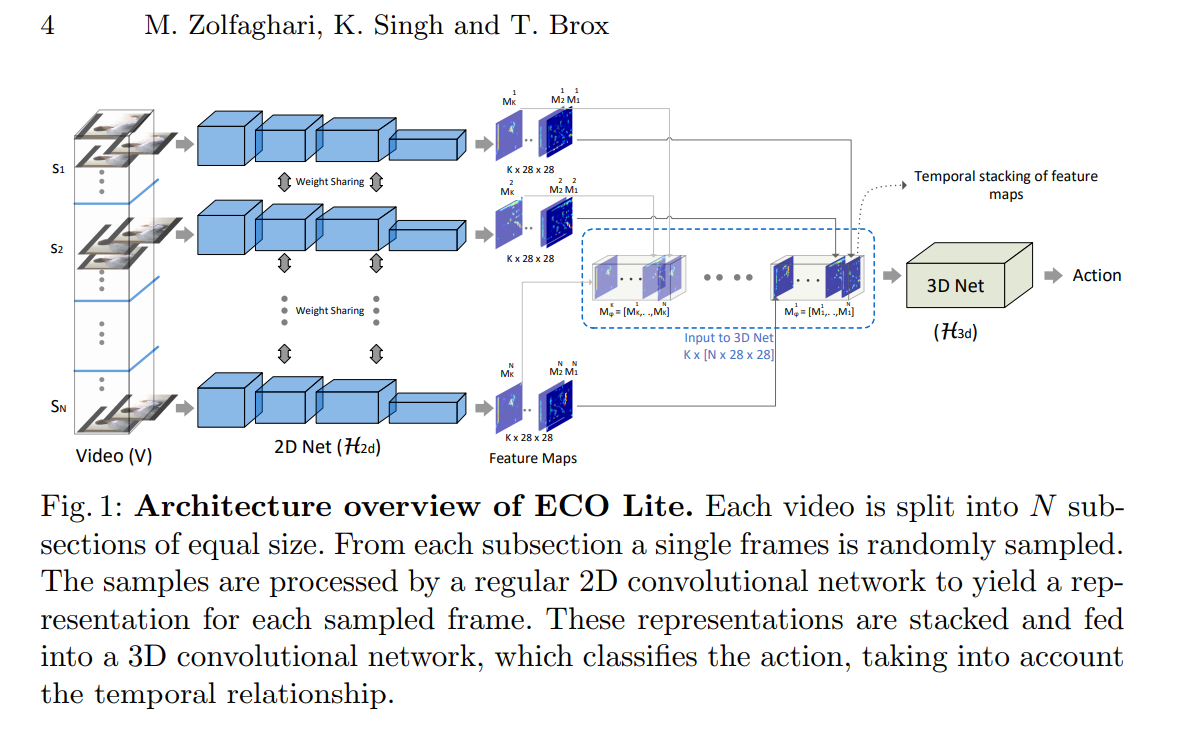
首先,将一段视频分成等长的N段,再从每一段中随机选取一帧输入网络(S1~SN);输入图像首先经过共享的2D卷积子网络得到96*28*28的feature map,然后输入到一个3D卷积子网络中,得到对应动作类别数目的一维向量。
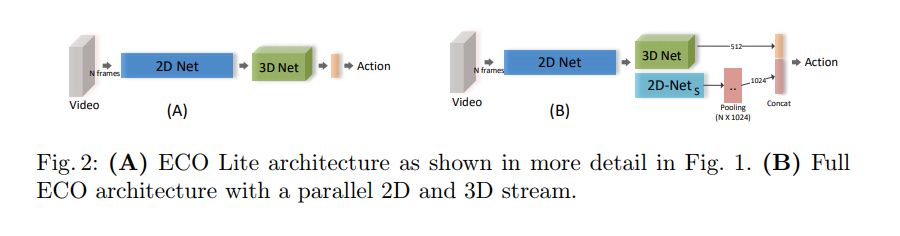
2. 关于帧间信息融合的部分,作者还尝试了使用2D与3D卷积相结合的方案(ECO Full),如下图所示:
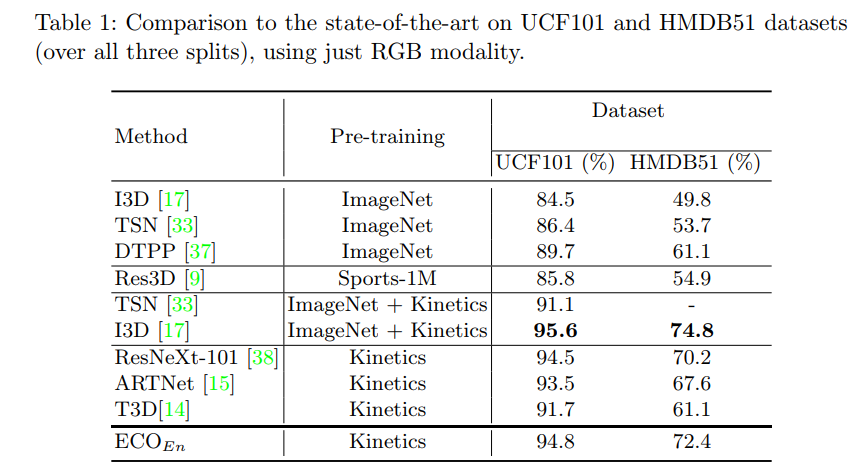
3. 以下是ECO网络在UCF-101和HMDB-51数据集上的测试结果:
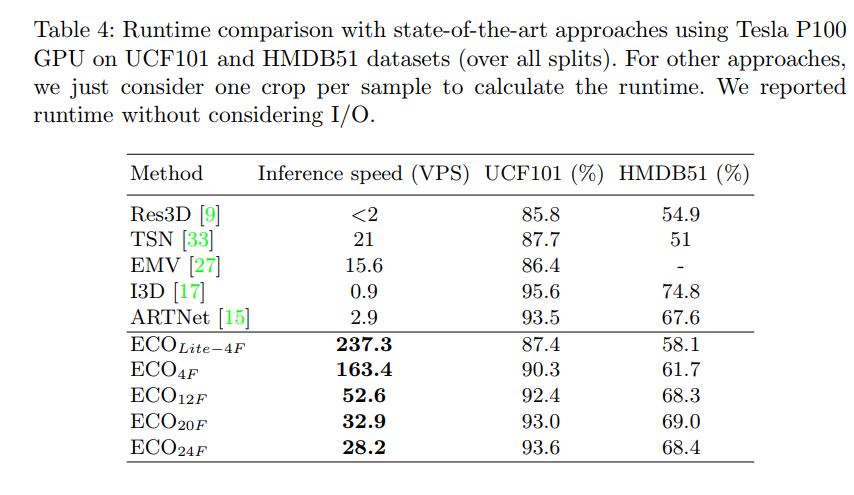
以下是网络在运行速度方面的测试结果:
作者还测试了不同版本的ECO模型,结果如下:
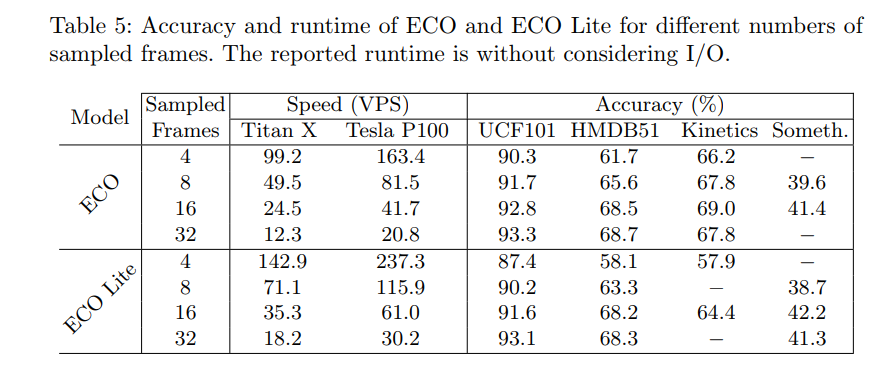
参考博客:[论文笔记] 用于在线视频理解的高效卷积网络
下面列表为行为识别及相关领域(如目标识别,手势估计)的资源
Action Recognition
Spatio-Temporal Action Detection
- Action Tubelet Detector for Spatio-Temporal Action Localization – V. Kalogeiton et al, arXiv2017.
- Am I Done? Predicting Action Progress in Videos – F. Becattini et al, arXiv2017.
- Chained Multi-stream Networks Exploiting Pose, Motion, and Appearance for Action Classification and Detection – M. Zolfaghari et al, arXiv2017.
- Generic Tubelet Proposals for Action Localization – J. He et al, arXiv2017.
- Incremental Tube Construction for Human Action Detection – H. S. Behl et al, arXiv2017.
- Tube Convolutional Neural Network (T-CNN) for Action Detection in Videos – R. Hou et al, arXiv2017.
- Online Real time Multiple Spatiotemporal Action Localisation and Prediction – G. Singh et al, arXiv2016.
- Multi-region two-stream R-CNN for action detection – X. Peng and C. Schmid. ECCV2016. [code]
- Spot On: Action Localization from Pointly-Supervised Proposals – P. Mettes et al, ECCV2016.
- Deep Learning for Detecting Multiple Space-Time Action Tubes in Videos – S. Saha et al, BMVC2016. [code][project web]
- Learning to track for spatio-temporal action localization – P. Weinzaepfel et al. ICCV2015.
- Action detection by implicit intentional motion clustering – W. Chen and J. Corso, ICCV2015.
- Finding Action Tubes – G. Gkioxari and J. Malik CVPR2015. [code][project web]
- APT: Action localization proposals from dense trajectories – J. Gemert et al, BMVC2015. [code]
- Spatio-Temporal Object Detection Proposals – D. Oneata et al, ECCV2014. [code][project web]
- Action localization with tubelets from motion – M. Jain et al, CVPR2014.
- Spatiotemporal deformable part models for action detection – Y. Tian et al, CVPR2013. [code]
- Action localization in videos through context walk – K. Soomro et al, ICCV2015.
- Fast Action Proposals for Human Action Detection and Search – G. Yu and J. Yuan, CVPR2015. Note: code for FAP is NOT available online. Note: Aka FAP.
Temporal Action Detection
- SST: Single-Stream Temporal Action Proposals – S. Buch et al, CVPR2017.
- R-C3D: Region Convolutional 3D Network for Temporal Activity Detection – H. Xu et al, arXiv2017.
- DAPs: Deep Action Proposals for Action Understanding – V. Escorcia et al, ECCV2016. [code][raw data]
- Online Action Detection using Joint Classification-Regression Recurrent Neural Networks– Y. Li et al, ECCV2016. Noe: RGB-D Action Detection
- Temporal Action Localization in Untrimmed Videos via Multi-stage CNNs – Z. Shou et al, CVPR2016. [code] Note: Aka S-CNN.
- Fast Temporal Activity Proposals for Efficient Detection of Human Actions in Untrimmed Videos – F. Heilbron et al, CVPR2016. [code] Note: Depends on C3D, aka SparseProp.
- Actionness Estimation Using Hybrid Fully Convolutional Networks – L. Wang et al, CVPR2016. [code] Note: The code is not a complete verision. It only contains a demo, not training. [project web]
- Learning Activity Progression in LSTMs for Activity Detection and Early Detection – S. Ma et al, CVPR2016.
- End-to-end Learning of Action Detection from Frame Glimpses in Videos – S. Yeung et al, CVPR2016. [code][project web]Note: This method uses reinforcement learning
- Fast Action Proposals for Human Action Detection and Search – G. Yu and J. Yuan, CVPR2015. Note: code for FAP is NOT available online. Note: Aka FAP.
- Bag-of-fragments: Selecting and encoding video fragments for event detection and recounting – P. Mettes et al, ICMR2015.
- Action localization in videos through context walk – K. Soomro et al, ICCV2015.
Spatio-Temporal ConvNets
- Deep Temporal Linear Encoding Networks – A. Diva et al, arXiv 2016.
- Temporal Convolutional Networks: A Unified Approach to Action Segmentation and Detection – C. Lea et al, CVPR 2017. [code]
- Long-term Temporal Convolutions – G. Varol et al, TPAMI2017. [project web][code]
- Temporal Segment Networks: Towards Good Practices for Deep Action Recognition – L. Wang et al, arXiv 2016. [code]
Action Classification
- Dynamic Image Networks for Action Recognition – H. Bilen et al, CVPR2016. [code][project web]
- Long-term Recurrent Convolutional Networks for Visual Recognition and Description – J. Donahue et al, CVPR2015. [code][project web]
- Describing Videos by Exploiting Temporal Structure – L. Yao et al, ICCV2015. [code] note: from the same group of RCN paper “Delving Deeper into Convolutional Networks for Learning Video Representations”
- Two-Stream SR-CNNs for Action Recognition in Videos – L. Wang et al, BMVC2016.
- Real-time Action Recognition with Enhanced Motion Vector CNNs – B. Zhang et al, CVPR2016. [code]
- Action Recognition with Trajectory-Pooled Deep-Convolutional Descriptors – L. Wang et al, CVPR2015. [code]
- Convolutional Two-Stream Network Fusion for Video Action Recognition – C. Feichtenhofer et al, CVPR2016. [code]
- Learning Spatiotemporal Features with 3D Convolutional Networks – D. Tran et al, ICCV2015. [the official Caffe code][project web] Note: Aka C3D. [Python Wrapper] Note that the official caffe does not support python wrapper. [TensorFlow], [TensorFlow + Keras], [Another TensorFlow Implemetation], [Keras C3D Project web]: [Keras code], [Pretrained weights].
在行为识别领域,比较主流的算法有two-streams,3D convolutions 和RNN,尤其以two-streams算法
性能良好。Action Recognition Datasets
- 20BN-JESTER, 20BN-SOMETHING-SOMETHING
- AVA
- ActivityNet Note: They provide a download script and evaluation code here .
- Charades
- THUMOS14 Note: It overlaps with UCF-101 dataset.
- THUMOS15 Note: It overlaps with UCF-101 dataset.
- HOLLYWOOD2: Spatio-Temporal annotations
- UCF-101, annotation provided by THUMOS-14, and corrupted annotation list, UCF-101 corrected annotations and different version annotaions. And there are also some pre-computed spatiotemporal action detection results
- UCF-50.
- UCF-Sports, note: the train/test split link in the official website is broken. Instead, you can download it from here.
- HMDB
- J-HMDB
- LIRIS-HARL
- KTH
- MSR Action Note: It overlaps with KTH datset.
- Sports-1M – Large scale action recognition dataset.
- YouTube-8M, technical report
- YouTube-BB, technical report
附录:
论文列表(顺序不分先后):
Structure:
- Temporal Segment Networks: Towards Good Practices for Deep Action Recognition【ECCV2016】
- Temporal Relational Reasoning in Videos
- Deep Temporal Linear Encoding Networks 【CVPR2017】
- End-to-end Video-level Representation Learning for Action Recognition
- Rethinking Spatiotemporal Feature Learning For Video Understanding
- Spatiotemporal Residual Networks for Video Action Recognition【NIPS2016】
- Temporal 3D ConvNets: New Architecture and Transfer Learning for Video Classification
- Video Classification via Relational Feature Encoding Networks
- I3D
- Hidden Two-Stream Convolutional Networks for Action Recognition
- Learning Gating ConvNet for Two-Stream based Methods in Action Recognition
- Deep Local Video Feature for Action Recognition 【CVPR2017】
- Learning Spatio-Temporal Representation with Pseudo-3D Residual Networks【ICCV2017】
- Convolutional Two-Stream Network Fusion for Video Action Recognition 【CVPR2016】
Inputs:
- AdaScan: Adaptive Scan Pooling in Deep Convolutional Neural Networks for Human Action Recognition in Videos 【CVPR2017】
- Optical Flow Guided Feature: A Fast and Robust Motion Representation for Video Action Recognition
- A Key Volume Mining Deep Framework for Action Recognition 【CVPR2016】
Connection:
- Spatiotemporal Multiplier Networks for Video Action Recognition【CVPR2017】
- Beyond Gaussian Pyramid: Multi-skip Feature Stacking for Action Recognition【CVPR2015】
- Deep Convolutional Neural Networks with Merge-and-Run Mappings
- Human Action Recognition using Factorized Spatio-Temporal Convolutional Networks【ICCV2015】
- Attentional pooling for action recognition 【NIPS2017】
- Spatiotemporal Pyramid Network for Video Action Recognition 【CVPR2017】
- ActionVLAD for video action classification 【CVPR2017】
当前这个领域需要考虑的问题?
专注于动作, 还是场景理解
一个视频中多个动作同时进行
严重依赖物体和场景首先无论是双流法还是3D卷积核,网络到底学到了什么?
会不会只是物体或场景的特征呢?而动作识别,重点在于action。MIT最近公布了新的数据集 Moments in time,Moments in Time,在这个数据集里,action成为关键。例如,opening这个动作,可以是小孩双眼open,也可以是门open,还可以是鸟的翅膀open。这样的数据集对当前主流的算法提出了挑战,把video这块的注意力聚焦在action,而不是物体和场景。
一些算法实现
| 算法 | 实现 |
|---|---|
| TSN(双流法) | http://yjxiong.me/others/tsn/ |
| I3D | https://github.com/deepmind/kinetics-i3d |
| R(2+1)D | https://github.com/facebookresearch/R2Plus1D |
参考链接:
1.github jinwchoi/awesome-action-recognition
2.https://zhuanlan.zhihu.com/p/28791320
3.https://zhuanlan.zhihu.com/p/33040925
4.https://zhuanlan.zhihu.com/p/26460437
5.https://www.cnblogs.com/nowgood/p/actionrecognition.html
在此鸣谢!!如有商业侵权,请联系我删除,谢谢!
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/152016.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
