大家好,又见面了,我是你们的朋友全栈君。
文章目录
1. 转置卷积定义
在语义分割的预测过程中,我们需要对每个像素进行目标检测,那就出现一个问题,我们先是对输入的图像通过二维卷积神经网络进行不断的高宽减半的压缩,最后得到一个预测,但我们如果需要对每个像素进行识别,就要通过预测反推每个像素里面的类别。举个例子,我们对猫狗识别时,我们不仅仅要识别猫在哪,还要将关于猫的每个像素给识别出来,这时就要求我们需要用到转置卷积。转置卷积可以使得图像不断变大,使得我们生成的图像和原始图像具有相同大小,那么我们就能够狠方便的进行语义分割。
2. 自定义转置卷积
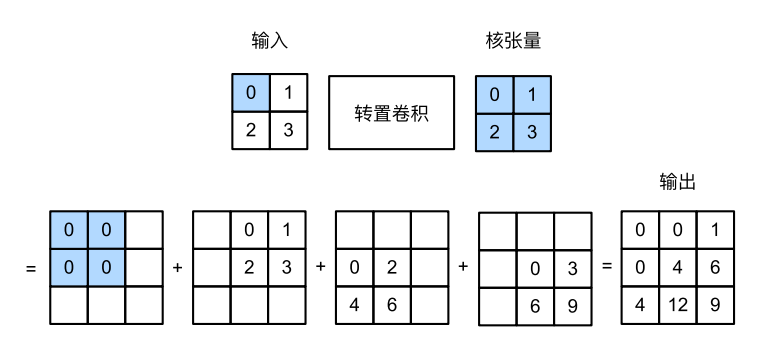

具体就是,用卷积核 K=torch.tensor([[0,1],[2,3]]),不断的跟输入中的每个元素 x i , j x_{i,j} xi,j相乘,最后所有的元素相加得到输出卷积,具体如上图所示。
- 代码
# 导入数据库
# 1.导入数据库
import torch
from torch import nn
# 2. 定义输入矩阵 x
x = torch.Tensor([[0, 1], [2, 3]])
k = torch.Tensor([[0, 1], [2, 3]])
# 3. 定义转置卷积函数
def tran_conv(x, k):
h, w = k.shape
y = torch.zeros((x.shape[0] + h - 1, x.shape[1] + w - 1))
for i in range(x.shape[0]):
for j in range(x.shape[1]):
y[i:i + h, j:j + w] += x[i, j] * k
return y
# 4.定义输入张量 X ,转置卷积核 K
X = torch.Tensor([[0, 1], [2, 3]])
K = torch.Tensor([[0, 1], [2, 3]])
# 5.输出 Y
Y = tran_conv(X, K)
print(f'Y={
Y}')
# 6. 将 X,K 变成四维张量,方便卷积计算
X_conv = X.reshape(1, 1, 2, 2)
K_conv = K.reshape(1, 1, 2, 2)
# 7. 定义二维转置卷积运算,输入通道1,输出通道1,卷积核 K 为 2 X 2 ,无偏置
tconv = nn.ConvTranspose2d(1, 1, kernel_size=2, bias=False)
# 8. 将 转置卷积核的值赋为 K_conv
tconv.weight.data = K_conv
# 9. 输入张量(X_conv) -> 转置卷积(tconv+K_conv) -> 输出张量
Y_conv = tconv(X_conv)
# 10. 为了核对计算结果跟我们自定义的值是否一致,将批量为1的维度去掉
Y_conv_squeeze = Y_conv.squeeze()
print(f'Y_conv={
Y_conv}')
print(f'Y_conv_squeeze={
Y_conv_squeeze}')
# 11.判断自定义的转置卷积函数值是否跟官方调用函数值一致
print(f'Y == Y_conv_squeeze:{
Y == Y_conv_squeeze}')
- 结果
Y=tensor([[ 0., 0., 1.],
[ 0., 4., 6.],
[ 4., 12., 9.]])
Y_conv=tensor([[[[ 0., 0., 1.],
[ 0., 4., 6.],
[ 4., 12., 9.]]]], grad_fn=<SlowConvTranspose2DBackward>)
Y_conv_squeeze=tensor([[ 0., 0., 1.],
[ 0., 4., 6.],
[ 4., 12., 9.]], grad_fn=<SqueezeBackward0>)
Y == Y_conv_squeeze:tensor([[True, True, True],
[True, True, True],
[True, True, True]])
3. 转置卷积
-
padding:作用在输出张量中,行与列上减去padding行和列
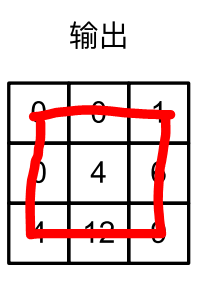
-
stride:作用在中间矩阵中
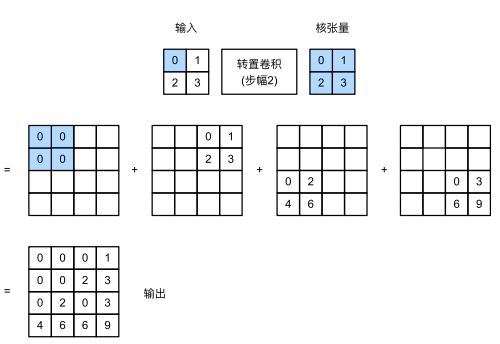
- 代码
# 1.导入数据库
import torch
from torch import nn
# 2. 定义输入矩阵 x
x = torch.Tensor([[0, 1], [2, 3]])
k = torch.Tensor([[0, 1], [2, 3]])
# 3. 定义转置卷积函数
def tran_conv(x, k):
h, w = k.shape
y = torch.zeros((x.shape[0] + h - 1, x.shape[1] + w - 1))
for i in range(x.shape[0]):
for j in range(x.shape[1]):
y[i:i + h, j:j + w] += x[i, j] * k
return y
# 4.定义输入张量 X ,转置卷积核 K
X = torch.Tensor([[0, 1], [2, 3]])
K = torch.Tensor([[0, 1], [2, 3]])
# 5.输出 Y
Y = tran_conv(X, K)
print(f'Y={
Y}')
# 6. 将 X,K 变成四维张量,方便卷积计算
X_conv = X.reshape(1, 1, 2, 2)
K_conv = K.reshape(1, 1, 2, 2)
# 7. 定义二维转置卷积运算,输入通道1,输出通道1,卷积核 K 为 2 X 2 ,无偏置
tconv = nn.ConvTranspose2d(1, 1, kernel_size=2, bias=False)
# 8. 将 转置卷积核的值赋为 K_conv
tconv.weight.data = K_conv
# 9. 输入张量(X_conv) -> 转置卷积(tconv+K_conv) -> 输出张量
Y_conv = tconv(X_conv)
# 10. 为了核对计算结果跟我们自定义的值是否一致,将批量为1的维度去掉
Y_conv_squeeze = Y_conv.squeeze()
print(f'Y_conv={
Y_conv}')
print(f'Y_conv_squeeze={
Y_conv_squeeze}')
# 11.判断自定义的转置卷积函数值是否跟官方调用函数值一致
print(f'Y == Y_conv_squeeze:{
Y == Y_conv_squeeze}')
# 12.padding = 1 ,转置卷积中是对输出减去padding=1的行和列
tconv_padding_1 = nn.ConvTranspose2d(1, 1, kernel_size=2, padding=1, bias=False)
tconv_padding_1.weight.data = K_conv
Y_conv_padding_1 = tconv_padding_1(X_conv)
print(f'Y_conv_padding_1={
Y_conv_padding_1}')
# 13.stride = 2 , 转置卷积是在中间的进行步幅扩充,即卷积核K在输入X中以两个步幅进行滑动,
# 输入是 [2,2],转置卷积核[2,2],stride=2 则输出 Y 大小为 4 = (2-1)*2+2-1+1
tconv_stride_2 = nn.ConvTranspose2d(1, 1, kernel_size=2, stride=2, bias=False)
tconv_stride_2.weight.data = K_conv
Y_conv_stride_2 = tconv_stride_2(X_conv)
print(f'Y_conv_stride_2={
Y_conv_stride_2}')
- 结果
Y=tensor([[ 0., 0., 1.],
[ 0., 4., 6.],
[ 4., 12., 9.]])
Y_conv=tensor([[[[ 0., 0., 1.],
[ 0., 4., 6.],
[ 4., 12., 9.]]]], grad_fn=<SlowConvTranspose2DBackward>)
Y_conv_squeeze=tensor([[ 0., 0., 1.],
[ 0., 4., 6.],
[ 4., 12., 9.]], grad_fn=<SqueezeBackward0>)
Y == Y_conv_squeeze:tensor([[True, True, True],
[True, True, True],
[True, True, True]])
Y_conv_padding_1=tensor([[[[4.]]]], grad_fn=<SlowConvTranspose2DBackward>)
Y_conv_stride_2=tensor([[[[0., 0., 0., 1.],
[0., 0., 2., 3.],
[0., 2., 0., 3.],
[4., 6., 6., 9.]]]], grad_fn=<SlowConvTranspose2DBackward>)
4. 用卷积的角度思考转置卷积[重点]
4.1 说明
转置卷积是一种卷积
- 它将输入和核进行了重新排列
- 同卷积一般都是做下采样不同,它通常用作上采样
- 如果卷积将输入从(h,w)变成(h’,w’),同样超参数下它将(h’,w’)变成(h,w)
4.2 填充为0,步幅为1
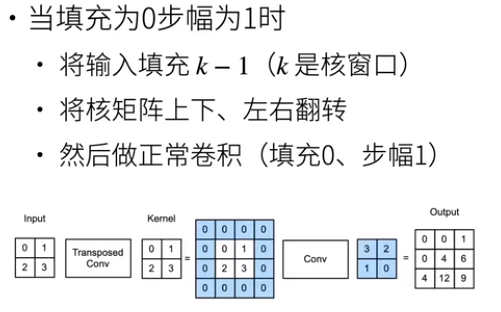
4.3 填充为p,步幅为1

4.4 填充为p,步幅为s
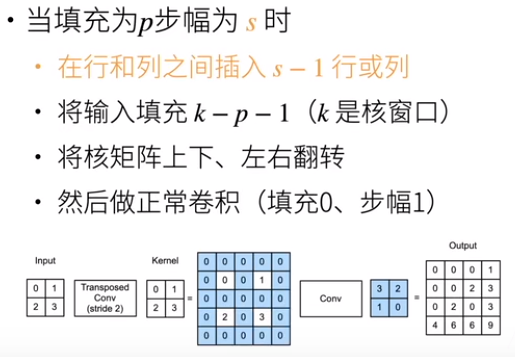
5. 转置卷积的初始化
转置卷积跟普通卷积一样,我们都需要对卷积核进行初始化,常用的是进行双线性插值初始化卷积核具体代码如下;
- 代码
# -*- coding: utf-8 -*-
# @Project: zc
# @Author: zc
# @File name: os_test
# @Create time: 2022/1/4 8:38
import torch
def bilinear_kernel(in_channels, out_channels, kernel_size):
""" :param in_channels: 输入通道数 :param out_channels: 输出通道数 :param kernel_size: 卷积核大小 :return: """
# factor = 2
factor = (kernel_size + 1) // 2
# center = 1.5
if kernel_size % 2 == 1:
center = factor - 1
else:
center = factor - 0.5
# 创建一个元祖 og[0] = tensor[4,1];og[1]=tensor[1,4]
og = (torch.arange(kernel_size).reshape(-1, 1),
torch.arange(kernel_size).reshape(1, -1))
# 进行插值计算,生成 4 x 4 的矩阵
filt = (1 - torch.abs(og[0] - center) / factor) * (1 - torch.abs(og[1] - center) / factor)
# 生成一个全为0的矩阵 (in_chanels,out_channels,kernel_size,kernel_size)
# 将初始化的 filt 值放入到 weight 内
weight = torch.zeros((in_channels, out_channels,
kernel_size, kernel_size))
# weight的形状,将filt整体值以对角线进行赋值
# [[filt],[0],[0]]
# [0],[filt],[0]
# [0],[0],[filt]]
weight[range(in_channels), range(out_channels), :, :] = filt
return weight
# y :[3,3,4,4]
y = bilinear_kernel(3, 3, 4)
print(f'y={
y}')
print(f'y_shape={
y.shape}')
print(f'y0={
y[0]}')
print(f'y1={
y[1]}')
print(f'y2={
y[2]}')
- 结果
y=tensor([[[[0.0625, 0.1875, 0.1875, 0.0625],
[0.1875, 0.5625, 0.5625, 0.1875],
[0.1875, 0.5625, 0.5625, 0.1875],
[0.0625, 0.1875, 0.1875, 0.0625]],
[[0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000]],
[[0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000]]],
[[[0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000]],
[[0.0625, 0.1875, 0.1875, 0.0625],
[0.1875, 0.5625, 0.5625, 0.1875],
[0.1875, 0.5625, 0.5625, 0.1875],
[0.0625, 0.1875, 0.1875, 0.0625]],
[[0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000]]],
[[[0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000]],
[[0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000]],
[[0.0625, 0.1875, 0.1875, 0.0625],
[0.1875, 0.5625, 0.5625, 0.1875],
[0.1875, 0.5625, 0.5625, 0.1875],
[0.0625, 0.1875, 0.1875, 0.0625]]]])
y_shape=torch.Size([3, 3, 4, 4])
y0=tensor([[[0.0625, 0.1875, 0.1875, 0.0625],
[0.1875, 0.5625, 0.5625, 0.1875],
[0.1875, 0.5625, 0.5625, 0.1875],
[0.0625, 0.1875, 0.1875, 0.0625]],
[[0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000]],
[[0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000]]])
y1=tensor([[[0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000]],
[[0.0625, 0.1875, 0.1875, 0.0625],
[0.1875, 0.5625, 0.5625, 0.1875],
[0.1875, 0.5625, 0.5625, 0.1875],
[0.0625, 0.1875, 0.1875, 0.0625]],
[[0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000]]])
y2=tensor([[[0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000]],
[[0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000]],
[[0.0625, 0.1875, 0.1875, 0.0625],
[0.1875, 0.5625, 0.5625, 0.1875],
[0.1875, 0.5625, 0.5625, 0.1875],
[0.0625, 0.1875, 0.1875, 0.0625]]])
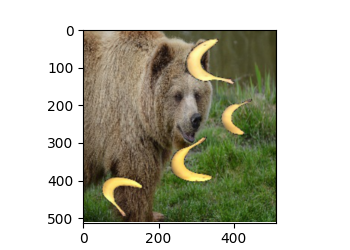
6. 转置卷积图像应用
我们可以将一个图像通过转置卷积将高宽增加两倍。
- 代码
# -*- coding: utf-8 -*-
# @Project: zc
# @Author: zc
# @File name: os_test
# @Create time: 2022/1/4 8:38
import os
import matplotlib.pyplot as plt
import torch
import torchvision.transforms
from torch import nn
from d2l import torch as d2l
def bilinear_kernel(in_channels, out_channels, kernel_size):
""" :param in_channels: 输入通道数 :param out_channels: 输出通道数 :param kernel_size: 卷积核大小 :return: """
# factor = 2
factor = (kernel_size + 1) // 2
# center = 1.5
if kernel_size % 2 == 1:
center = factor - 1
else:
center = factor - 0.5
# 创建一个元祖 og[0] = tensor[4,1];og[1]=tensor[1,4]
og = (torch.arange(kernel_size).reshape(-1, 1),
torch.arange(kernel_size).reshape(1, -1))
# 进行插值计算,生成 4 x 4 的矩阵
filt = (1 - torch.abs(og[0] - center) / factor) * (1 - torch.abs(og[1] - center) / factor)
# 生成一个全为0的矩阵 (in_chanels,out_channels,kernel_size,kernel_size)
# 将初始化的 filt 值放入到 weight 内
weight = torch.zeros((in_channels, out_channels,
kernel_size, kernel_size))
# weight的形状,将filt整体值以对角线进行赋值
# [[filt],[0],[0]]
# [0],[filt],[0]
# [0],[0],[filt]]
weight[range(in_channels), range(out_channels), :, :] = filt
return weight
conv_trans = nn.ConvTranspose2d(3, 3, kernel_size=4, padding=1, stride=2, bias=False)
conv_trans.weight.data.copy_(bilinear_kernel(3, 3, 4))
path = os.path.join(os.getcwd(), 'img', 'banana.jpg')# path='D:\\zc\\img\\banana.jpg'
print(f'path={
path}')
# in_img = (3,256,256)
in_img = torchvision.transforms.ToTensor()(d2l.Image.open(path))
# X = (1,3,256,256)
X = in_img.unsqueeze(0)
# Y = (1,3,512,512) 转置卷积的stride=2 所以尺寸上放大了 2 倍
Y = conv_trans(X)
# out_img = [512,512,3]
out_img = Y[0].permute(1, 2, 0).detach()
d2l.set_figsize()
# in_img.permute(1,2,0) = [256,256,3]
print('input image shape:', in_img.permute(1, 2, 0).shape)
# d2l.plt.imshow(in_img.permute(1, 2, 0))
print('output_image_shape:', out_img.shape)
d2l.plt.imshow(out_img)
print('output_image_shape_after:',out_img.shape)
plt.show()
- 结果
path=D:\zc\img\banana.jpg
input image shape: torch.Size([256, 256, 3])
output_image_shape: torch.Size([512, 512, 3])
output_image_shape_after: torch.Size([512, 512, 3])
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/151948.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
