大家好,又见面了,我是你们的朋友全栈君。
前段时间线上的zzuser的服务模块出现大量的异常FGC情况,经过大量排查工作,最后锁定是因为一个sql的大查询导致的。这也给了我非常大的教训,同时我在这次问题的排查过程中也获益匪浅,所以把经过写下来或许能给其他处理JVM问题的同学一些启示或者借鉴,本文假设你对JVM有一定的了解,如果不了解,可以看另外一篇文章
问题现象及分析
JVM核心参数配置如下:
-Xms6g -Xmx6g -Xmn3g -Xss1024K -XX:PermSize=256m -XX:MaxPermSize=512m -XX:ParallelGCThreads=20 -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:+UseCMSCompactAtFullCollection -XX:SurvivorRatio=65536 -XX:MaxTenuringThreshold=0 -verbose:gc -XX:+PrintGCTimeStamps -XX:+PrintGCDetails -XX:CMSInitiatingOccupancyFraction=80异常GC日志如下:


线程堆栈信息:
因为FGC后又自动恢复正常,所以jstack并不能打印出当时的真实情况,后面我写了一个脚本在FGC后马上打印线程堆栈信息,基本可以保留线程信息
大家可以看到我们的S区大小基本为空,因为我们的应用服务器都是是无状态的,所以理论上,每次YGC都能将对象回收,所以不需要在S区做任何停留,这在低并发时基本没有问题,但是高并发时就会出现YGC无法回收线程对象的情况,这时候S区为空,对象只能存储在Old区,导致高并发时old区突然暴涨的情况,从而产生大量FGC,但是这种配置即使发生了流量暴涨,也只是正常的YGC和FGC,不会突然在上位到达CMSInitiatingOccupancyFraction=80及Old区到百分之80使用率才进行FGC
可能原因分析
- 对象突然出现在old区,可能是因为有数量可观的大对象被创建,这些对象直接进入old区,导致old区突然增加,这种对象一般是流数据
- 可能是流量暴涨,创建突然对象增多,YGC无法回收,只能分配在old,虽然上文分析过流量暴涨引发的情况和需要解决的现象不同,但是开始是不清楚的
- CPU、内存等资源被其他进程占用,JVM没有足够的资源用以GC,我们的GC配置的是需要20个线程进行回收操作,还是比较耗费资源的。
- 在查找问题的过程中,有文章提到swap分区可能导致问题的产生
- 数据库连接异常,可能导致线程上的对象无法及时释放
分析了可能出现问题的原因,能重现问题,就是离解决问题不远了了,所以现在最重要的是能参考原因,重现异常
手动重现异常
大对象问题
因为我对zzuser业务模块不熟悉,所以请教了其他同学,zzuser模块并不存在流数据等大对象,所以第一个先搁置,实在找不到问题了再说(结果证明确实没有)
流量暴涨
要模拟流量暴涨还是比较容易的,前期我先使用TestNG调用几个方法进行压测,将压力突然调高,方法比较粗糙,后来让运维的同学给我们开了流量,使用tcpcopy将线上的流量引入到测试服务上,这种方式就非常准确科学了。
下图是流量突然增大时的GC情况
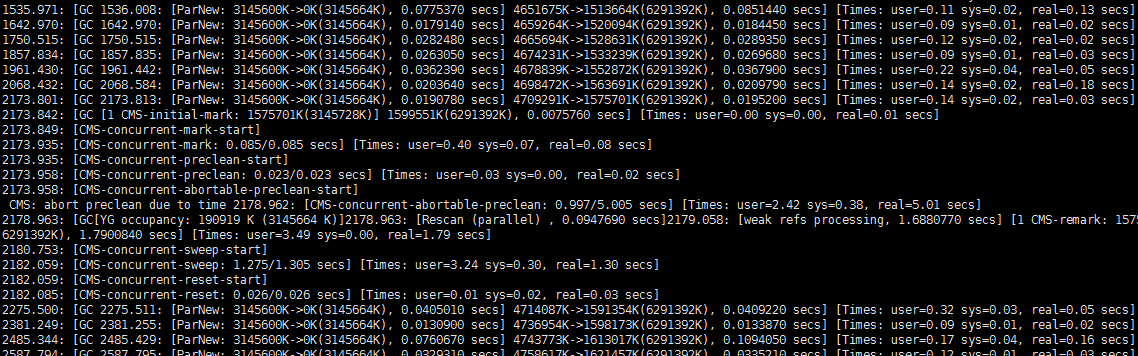
大家可以看到我们的S区大小基本为空,因为我们的应用服务器都是是无状态的,所以理论上,每次YGC都能将对象回收,所以不需要在S区做任何停留,这在低并发时基本没有问题,但是高并发时就会出现YGC无法回收线程对象的情况,这时候S区为空,对象只能存储在Old区,导致高并发时old区突然暴涨的情况,从而产生大量FGC,但是这种配置即使发生了流量暴涨,也只是正常的YGC和FGC,不会突然在上位到达CMSInitiatingOccupancyFraction=80及Old区到百分之80使用率才进行FGC
可以和异常日志红色部分对比,在异常FGC发生之前,会出现一次耗时非常长的YGC,对比之前正常YGC,这次YGC后old区发生了突然增长,然后触发了FGC。显然流量暴涨并不能导致异常FGC,这条路也走不通了。
CPU资源被其他进程占用
这里用到一个脚本,用来将cpu资源消耗光
#! /bin/bash
# filename killcpu.sh
endless_loop()
{
echo -ne "i=0; while true do i=i+100; i=100 done" | /bin/bash &
}
if [ $# != 1 ] ; then
echo "USAGE: $0 <CPUs>"
exit 1;
fi
for i in `seq $1`
do
endless_loop
pid_array[$i]=$! ;
done
for i in "${pid_array[@]}"; do
echo 'kill ' $i ';';
done
CPU使用情况(原图没保存,随便截了个,现象一样)
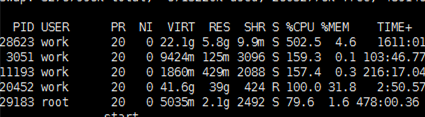
当有其他进程将大量cpu占用以后,在1:1线上流量下基本GC情况不会有太大的差距。
内存被其他进程占用的情况,swap分区问题
因为没有服务器root权限,所以脚本没有运行成功,但是事后分析,理论上JVM的内存在开始已经分配好了,并不会因为内存被其他进程占用过多而导致异常
#!/bin/bash
mkdir /tmp/memory
mount -t tmpfs -o size=20480M tmpfs /tmp/memory
dd if=/dev/zero of=/tmp/memory/block
sleep 5
rm /tmp/memory/block
umount /tmp/memory
rmdir /tmp/memory数据库连接异常
我用TestNG,将代码里面加上sleep(),希望模拟出数据库连接问题,测试后发生JVM依然正常,分析原因,当数据库连接异常时,线程都在等待数据库连接,这时候调用方即使有大量请求堆积到队列中,但是因为工作线程已经都在sleep,所以根本不会创建更多的对象,JVM自然不会有异常
经过各种分析,都无法重现异常,这时候有一台机器发生FGC时没有恢复,基本宕掉了。这是一个大好的机会,我们使用jmap dump了整个堆信息,本来是要jstack线程信息,结果卡住了,就没有保留线程信息。
堆文件分析
因为堆文件是在太大,在线上机器使用jmap分析了好久,也出不来报告,我们将它下载到本地,找了一台16G的Mac进行分析,因为是别人的机器,而且文件太大,爆卡。所以这里就说一个基本现象。
存在3个异常线程,每个线程上的对象达200多万个,耗费内存800多M。加起来就是两个多G的内存,我们Eden区总共才3G,所以这个很有可能是问题的原因。这个现象的发现让我感觉到很有可能是由于数据库查询出太多对象导致的。感觉问题就要找到了,但是如何准确定位还不知道怎么办。
shell脚本
上文讲到我最后利用一个脚本定位了问题,脚本内容
#! /bin/bash
pid=`scf list | grep zzuser | awk '{print $5}'`
echo "pid=$pid"
flag=1
fgc1=0
while((flag==1))
do
sleep 1
fgc2=`scf jstat -gcutil zzuser | sed -n '2'p | awk '{print $8}'`
echo "---------------start----------------">>gc.log
echo "fgc2=$fgc2, fgc1=$fgc1" >> gc.log
echo "fgc2=$fgc2, fgc1=$fgc1"
echo "-------------top--------------">>gc.log
top -b| head -12 >> gc.log
div=`expr $fgc2 - $fgc1`
if [ $div -gt 0 ]
then
fgc1=$fgc2
echo "------------------------------------出现了fgc---------------------------------" >> gc.log
echo "------GC 情况-----"
echo `scf jstat -gcutil zzuser` >> gc.log
for i in {
1..3}
do
#查找消耗最高线程id
# 加上-b不会出现乱码
tid=`top -H -b -p $pid | head -10 | sed -n '8'p | awk '{print($1)}'`
echo "tid=$tid"
tid16=`printf "%x" $tid`
echo "cpu 消耗最高线程 id 是${tid16}啊" >>gc.log
echo "cpu 消耗最高线程 id 是${tid16}"
date=`date`
echo "-------------堆栈信息--${tid}--${tid16}---${date}------------" >> gc.log
jstack $pid | grep -A 20 $tid16 >> gc.log
jstack $pid > $pid$tid.jstack
done
fi
done
很简单,当发生FGC时,将各种信息记录下来方便查询。
运行一天以后,果然发生了数次FGC,查看到最重要的信息
cpu 消耗最高线程 id 是7140啊
-------------堆栈信息--28992--7140---2016年 07月 06日 星期三 15:20:01 CST------------
"async task worker[24]" daemon prio=10 tid=0x00007ff53ce63800 nid=0x7140 runnable [0x00007ff4acb58000]
java.lang.Thread.State: RUNNABLE
at java.util.ArrayList.size(ArrayList.java:177)
at java.util.AbstractList$Itr.hasNext(AbstractList.java:339)
at com.bj58.zhuanzhuan.lib.util.DaoOptimize.populateData(DaoOptimize.java:44)
at com.bj58.zhuanzhuan.zzuser.components.ZZUserService$1.exec(ZZUserService.java:58)
at com.bj58.sfft.utility.dao.basedao.DAOHelper.execQuery(DAOHelper.java:94)
at com.bj58.zhuanzhuan.zzuser.components.ZZUserService.getByUnionid(ZZUserService.java:54)
at ZZUserServiceProxyStub1467616292464.getByUnionid(ZZUserServiceProxyStub1467616292464.java)
at ZZUserServiceProxyStub1467616292464.invoke(ZZUserServiceProxyStub1467616292464.java)
at com.bj58.spat.scf.server.core.proxy.InvokerBase.doInvoke(InvokerBase.java:114)
at com.bj58.spat.scf.server.core.proxy.AsyncInvokerHandle$1.run(AsyncInvokerHandle.java:97)
at com.bj58.spat.utility.expandasync.AsyncWorker.execTimeoutTask(AsyncWorker.java:155)
at com.bj58.spat.utility.expandasync.AsyncWorker.run(AsyncWorker.java:132)
GC发生之前系统资源使用情况
top - 15:19:57 up 331 days, 15:33, 1 user, load average: 3.95, 3.32, 2.78
Tasks: 566 total, 3 running, 562 sleeping, 0 stopped, 1 zombie
Cpu(s): 6.6%us, 2.5%sy, 0.0%ni, 90.3%id, 0.1%wa, 0.0%hi, 0.6%si, 0.0%st
Mem: 131900336k total, 129866704k used, 2033632k free, 33196k buffers
Swap: 32767996k total, 6714812k used, 26053184k free, 50267092k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
28623 work 20 0 22.2g 5.8g 9m S 644.0 4.6 1641:48 java
28002 dia 20 0 19.6g 2.2g 3292 S 227.7 1.8 36196:58 java
11193 work 20 0 1860m 429m 1984 S 156.8 0.3 277:44.58 router
16782 work 20 0 23.3g 3.4g 9.9m S 112.0 2.7 748:04.01 java
31629 work 20 0 23.7g 3.7g 10m S 93.3 2.9 2980:07 java
CPU使用高达644%,而当时消耗最高的线程居然只是一个小小的查询
ZZUserService.getByUnionid(ZZUserService.java:54)找到这段代码
public ZZUser getByUnionid(String unionId, final String strLog) throws Exception {
if (unionId == null) {
throw new Exception("参数错误");
}
String sql = "SELECT * FROM user WHERE `unionid`=" + unionId;
代码只判断了unionId == null ,但是确没有判断unionId == “”的情况,但是为什么以前没有问题呢?因为之前我们系统全是微信用户,所以unionId不存在空的情况。最近接入了其他系统,所以出现了”“的情况。(后来我基于hibernate-validation写了一个小框架方便参数校验)
问题终于找到了,就是这么一个小问题。走了非常多的弯路,总结一下。
JVM问题排查总结
- JVM参数必须设置齐全,GC日志详细必须打印
- 善用工具,使用脚本,当发生问题时,可以将系统的各个日志记录下来,有了日志排查问题事半功倍
- 善用工具类,工具类是大神和前辈的经验结晶,大家踩过非常多坑了,写代码一定要注意,不管代码习惯还是其他小细节问题,都可能导致非常大的问题。比如我校验字符串空时采用
StringUtils.isNotBlank(),在这个情况下就不会出问题 - 调优的问题在另一篇文章 《JVM调优总结》
其他遗留的问题
参数校验太复杂麻烦,不过我已经写了工具解决这个问题,还有一个隐含大问题,就是我们的Dao工具太落后,工作量大,麻烦也隐含难以发现的错误,而且字符串拼接不方便重构和问题排查。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/150810.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
