大家好,又见面了,我是你们的朋友全栈君。
前言
闲鱼服务端应用广泛使用 Java 技术栈,基于JVM提供的托管式堆内存管理,开发者无需过多关心对象创建/回收时的内存分配/释放动作,垃圾回收器(Garbage Collector)会在需要的时候自动清理堆内不再使用的对象,保证有可用空间用于新对象分配。
开发者在享受到自动内存管理的便利时,也不可避免的需要承担垃圾回收器在进行死亡对象清理时的一些开销,例如机器资源利用率上升,应用线程被短暂暂停等。根据JVM使用的垃圾回收算法的不同以及回收的堆区域的不同,GC过程中用户线程的暂停时间、完成一次GC的耗时、也有所不同。
其中,全堆内存清理(Full GC,下称FGC)会扫描整个堆空间,清理掉所有死亡对象,而FGC是Stop the world(下文简称STW)的,也就是意味着会暂停全部的用户线程直到GC结束。一趟FGC的停顿时长视堆空间大小和存活对象数量多少而定,通常从几秒到几十秒不等。在这期间,应用无法对外提供任何服务,表现为接口超时,成功率下降,上游依赖线程池打满等,十分影响用户体验,甚至可能出现访问压力转移到其他健康机器上,使得健康机器对象分配压力增大,最终产生FGC而导致集群雪崩。
对于前台业务应用而言,正常承接业务流量的过程中产生的对象大部分都为朝生夕灭的对象,理论绝大部分对象上应该能通过新生代GC(YGC)被清理掉;而大部分GC算法,都是在老年代占用空间超过一定阈值时,才会触发FGC。因此,一旦出现了FGC,通常意味着这个应用的对象分配或垃圾回收相关的JVM参数存在问题,是业务运行时的重大隐患,需要尽快排查并根治。
本文通过三则前台应用FGC调优案例,分别介绍了由于JVM参数、中间件配置、业务代码层面引起的FGC的现象、分析过程及对应解法。希望能起到抛砖引玉的作用,以及给有同样疑惑的读者朋友们带来一些启发。
商品域核心应用发布及运行时FGC
现象
闲鱼商品域某核心应用,在正常承接业务流量时,集群不时有少量FGC出现,引起接口RT毛刺及成功率略微下跌。在应用发布过程中,集群FGC次数明显上升,接口抖动明显,且大部分FGC出现在未在发布批次的机器上。
此应用承接了对闲鱼商品增删改查操作的绝大部分流量。集群运行时的FGC不仅会影响用户体验,成为以后业务发展过程中的重大隐患,而且发布时的抖动会使得代码万一出问题时没办法快速回退到上一个版本,是安全生产的重大风险,需要尽快解决。
分析
选择一台发生了FGC的机器,查看其JVM信息监控,如下图所示: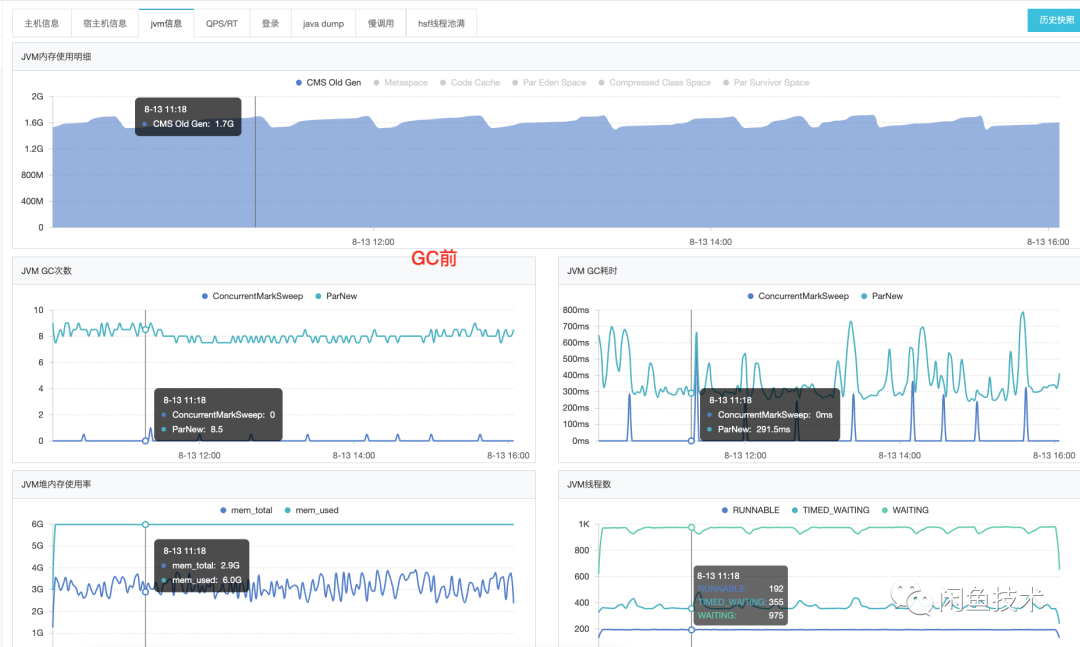

图中不难得出大量有用的信息:
-
应用采用 ParNew + CMS组合。
-
老年代到达1.7G左右占用时,触发CMS Old Gen GC。【1.7G可能是一个固定的Old Gen回收阈值】
-
老年代占用会随着时间的推移缓慢升高,逐渐触顶。【Survivor空间可能不够用】
-
Old Gen GC 一次回收大约200MB,水位回落到 1.5G,单次回收收益不明显。【老年代存在不少固定占用的大对象】
从监控上看,这是一种非常明显的因为担保分配,使得一些最终会死亡的对象进入到老年代,老年代触到CMS回收阈值产生CMS Old Gen GC的表象。但是在没有充分的证据之前,并不能盲目的下结论,还需要继续小心谨慎地求证上述假设,从而根据深层次的原因制定能根治FGC现象的解决方案。
针对假设1和2,查看应用JVM参数配置:
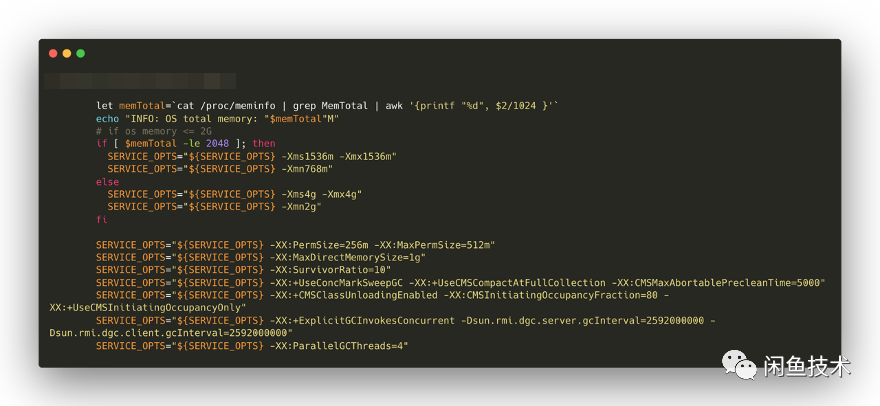
可以看到,应用确实是使用CMS作为垃圾回收器,堆大小被配置为4G,Young区2G,Old区2G,CMSInitiatingOccupancyFraction参数被配置为80%,这意味着老年代占用超过80%时触发CMS Old Gen回收,2G*0.8 = 1.6G,差不多就是监控中体现的1.7G左右开始回收,然后老年代占用回落。
另外还可以顺便得到:SurvivorRatio=10,单个Survivor区 2048 * /(10+1+1) = 174762K左右这一结论,能够为接下来的分析提供帮助。
对于假设3,监控系统上以分钟为粒度聚合的折线图就不太能满足需求了,需要通过GC日志,对机器每次GC回收结束后,各个区域的堆空间占用进行分析,看是否存在一次YGC结束后,Survivor区占用较高的情况。一段非常有代表性的GC日志如下图所示:

注意到ParNew是STW的算法,不存在回收过程中对象分配的可能。而一次ParNew回收前后的堆空间变化可以用下图来表示:
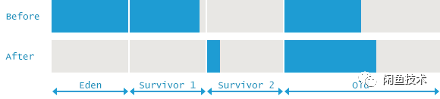
计算GC日志中各个区域的存活对象占用空间变化:
第一次回收: Young区 40225K存活,全堆1697070K存活,Old区1697070-40225=1656845K
第二次回收: Young区174720K存活,全堆1859440K存活,Old区1859440-174720=1684720K
Old区占用上涨约27875K
而先前通过JVM参数,可以知道单个Survivor区大小约为174762K,第二次回收极有可能出现了担保分配。Survivor区可能在某些回收中,显得不够用。
对于假设4,可以随机找一台线上机器,将流量切走后执行带FGC的Heap dump,目的是拿到FGC过后的堆对象集合。查看支配树,如下图所示:

可以看到排前4的对象已经占用了老年代约 687MB的空间,整体约1.3G的对象常驻老年代空间。且这4个对象对于业务而言都是十分重要的对象,初步来看并没有太大的优化空间。
分析到这里,该应用FGC的根因就呼之欲出了。
根因
偶现Survivor不够用的担保分配(可能还有晋升) -> Old Gen占用上涨 -> Old Gen 距离回收阈值仅有约200M的余量 -> 频繁 CMS Old Gen GC。
在应用发布过程中,又因为正在启动的应用,RPC、HTTP服务等没有上线,或者是处于小流量预热阶段,整个集群的流量就会倾斜到不在发布流程中的机器,使得每台机器需要承受的QPS升高,对象分配压力增大,YGC次数增多,通过担保分配晋升老年代的速率加快,导致老年代更快的触顶,出现频繁FGC。
解法
虽然该应用的FGC成因并不难分析,但是为其制定一个能根治FGC的解法却还是需要一些考量。
商品业务经过长时间的发展,该应用代码量非常大,业务逻辑错综复杂,且依赖了大量中间件、二方服务,很难去搞清楚这些业务对象的存活周期。要想解决这个应用的FGC现象,最好的办法就是:在不触发FGC的前提下清理掉担保到Old Gen的Young区存活对象。
该应用之前使用CMS回收器,但是通过后续分析发现,很难在CMS上达成上述目标。主要是因为存在以下几点困难:
-
Survivor 存在不够用现象。然而业务复杂,很难给出一个一定够用的数字。盲目调大,挤占了Young区的空间,导致YGC频繁,可能存在吞吐下降,RT升高的风险。
-
Old Gen 常驻大对象多?考虑大对象治理。依赖的服务未必有治理方案、升级回归存在成本。
-
Old Gen固定阈值产生CMS Old Gen GC?
调高阈值?有担保分配失败,回退到全堆STW FGC的风险。
调大Old Gen?全堆大小不变的话挤占Young区,风险同1。
增大全堆大小?应用容器内存吃紧,有容器OOM进程被杀的风险,以及这么做只是减少了Old Gen FGC的次数,没法根治。 且存在Old区变大,CMS Old Gen GC耗时变长的风险。
最终决定更换垃圾回收器为G1GC,因为G1GC默认晋升代数15代,可以使得更少的对象晋升到老年代,且支持Mixed GC增量式回收老年代垃圾。因此通过担保分配、晋升到Old区的垃圾可以通过Mixed GC清理。Mixed GC发生在YGC中,而G1的YGC又是能并发回收的,与ParNew相比具有更好的用户体验。
在G1GC默认的参数基础上,使用 G1NewSizePercent 参数固定Eden下限30%,设置 InitiatingHeapOccupancyPercent 为60%,保证Eden区不会过于小影响吞吐量,留10%的余量给Mixed GC时的并发分配动作;设置 MaxGCPauseMillis 为 120ms,期望稍微牺牲停顿时间换取更大吞吐量,以及Region大小4MB:期望GC能更精细的分配及标记Region,减少空间浪费。
成效
最终该应用发布抖动消失,FGC消失,GC耗时相比优化前(CMS)总体下降近一半。业务高峰期对象分配压力极大的时候,仍能控制在一分钟GC总耗时不超过500ms的水平下清理老年区所有死亡对象。FGC现象被彻底根治。

首页应用发布FGC
现象
闲鱼首页应用,在发布过程中每次都会存在一小批机器,在应用启动后陷入FGC,必须手动重启才能恢复;每次陷入FGC的机器IP均不重复,通过置换容器也无法解决问题。与上文提及的商品域应用不同的是,首页应用在正常运行时不会出现FGC,正常机器的JVM堆监控及GC日志显示内存分配压力不算太大,且该应用已经在使用G1GC。
分析
查看发生FGC机器的JVM监控: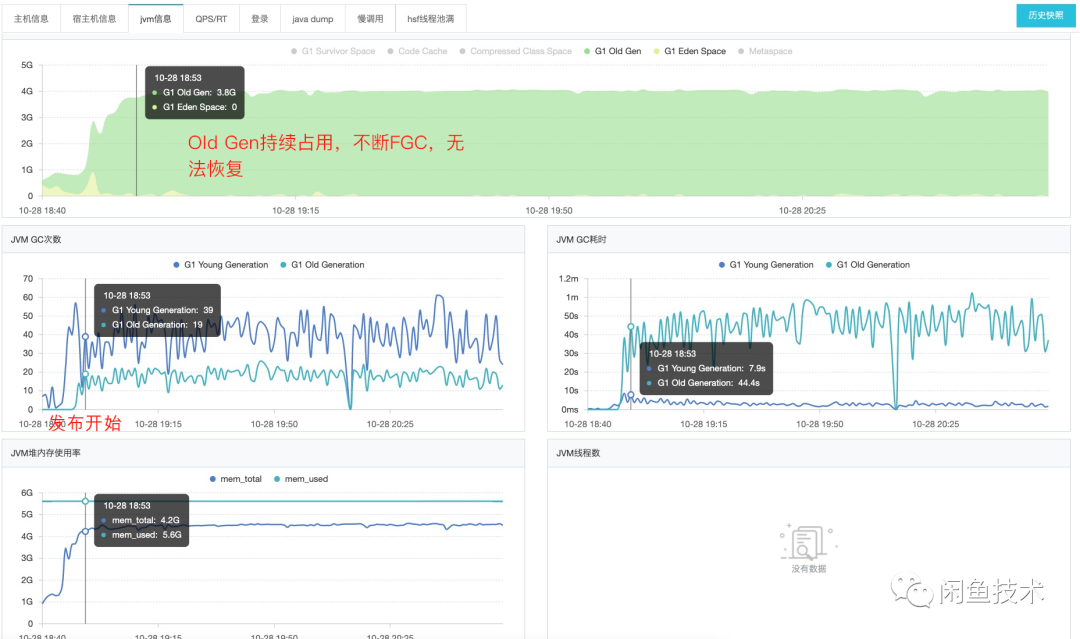
可以看到,从发布开始之后,有问题的机器老年代空间持续上涨,随后出现大量的FGC。从图中的GC耗时来看,一分钟有44.4s在FGC,7.9s在YGC。总计有52.3s处于GC状态。应用基本上没法响应外界请求。
从监控上看,也不难得知这是比较典型的堆内存泄漏。一般有两种情况:无用对象不释放,或者是对象存活周期由于某些原因而显著变长,导致堆里面存在大量存活对象,空间不够用。对于这种情况,通常需要借助Heap dump来观察堆里面究竟是什么对象大量占用空间。
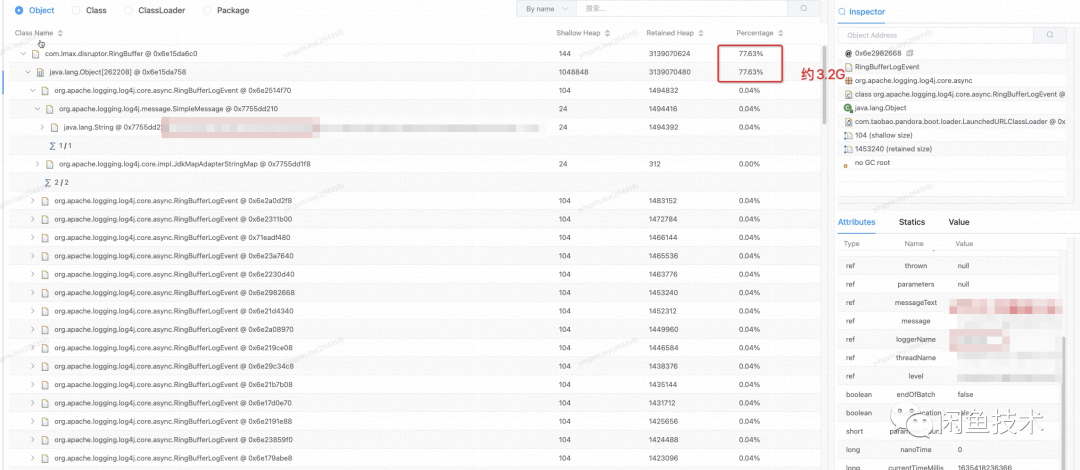
从Heap dump结果中,发现堆里面存在大量的Log4j RingBufferLogEvent,也就是说,堆里有大量的Log4j异步线程没来得及消费的日志请求。而且最大的消息体竟然能到1.4M左右的大小。
通过对消息体内部的字符串分析,发现这是线上某个接口的出入参日志。通过对线上请求的抓包分析,发现该接口返回的内容确实较多,平均在1M以上。而这些接口出入参,又确实需要通过打日志的方式,上报到日志平台保存起来,供排查问题使用。这种出入参记录方式在闲鱼被广泛使用,通过review打日志的代码,发现并没有什么明显的问题。因此,问题基本上与应用的代码没太大相关性。唯一值得注意的点是日志体较大,考虑从日志产生到落盘的整个流程入手分析,看整个过程是否存在性能瓶颈。
闲鱼服务端应用为了提升打日志性能,降低同步调用打日志时出现IO Hang的风险,开启了Log4j的异步日志打印功能。这也是Log4j官网比较推荐的一种性能优化方式。具体原理如下图所示:
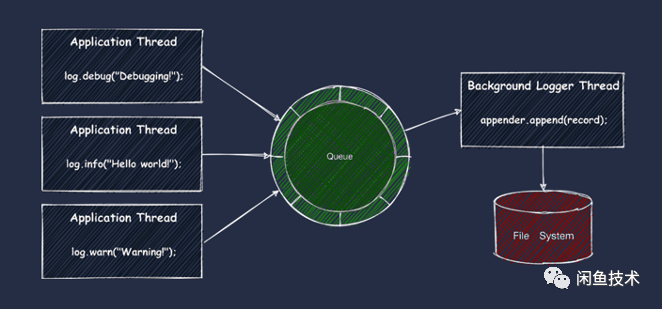
在正常情况下,应用代码调用日志输出方法后,传入的日志文本会被封装成一个Event,投递到Log4j内部的一个环形队列中(由 disruptor 提供,这是一种无锁跨线程通信的库,能够提供比队列更高的吞吐和更低的延迟)就立即返回。由Log4j的后台线程不断消费环形队列中的Event,将日志输出到文件上。
而 disruptor 中,环形队列的容量是以slot为单位组织的。在正常情况下是一个应用全局共享 262144 个slot。每个Event在RingBuffer中占用一个slot,一个slot里的Event占用空间大小则不做限制。
RingBufferSize 其实有两种取值,如果打开了 ThreadLocals RingBuffer
条件是:!IS_WEB_APP && PropertiesUtil.getProperties().getBooleanProperty("log4j2.enable.threadlocals", true)如果条件为真,那么每个线程一个buffer,每个buffer有 4096个 Slot。否则,整个应用共享 262144 个 Slot。
这个考量其实不难理解,因为WEB APP肯定有很多处理请求的线程,如果每个线程单独维护一组slot,这会导致整个应用里面有极大量的、互相独立的RingBuffer,有概率导致严重的内存占用。
这就有可能出现以下的情况:应用有可能打出很大的日志,这就可能出现,Slot占用并不多,但是每个Slot的Event都很大,内存消耗非常可观。
另外,注意到应用使用的 Log4j 版本为 2.8.2,在官方的Jira上有一个issue: LOG4J2-2031。此issue记载在某些情况下会出现日志乱序以及日志打印无响应的情况。原因是因为 2.8.2 中默认的 AsyncQueueFullPolicy 为 SYNCHRONOUS,此策略会在RingBuffer满的时候绕过RingBuffer,直接向文件输出日志内容,导致日志乱序。
此外,还发现日志输出过程中,会把日志message复制2遍,第一遍在org.apache.logging.log4j.core.layout.PatternLayout#encode里toText调用,把日志内容复制到自己维护的一个放在ThreadLocal的StringBuffer里面。第二次是encoder.encode(text, destination);调用,会把StringBuffer的内容拷进RollingRandomAccessFileManager内部的ByteBuffer里。所以,对于一个日志写入调用,峰值可能产生3倍内存占用。如果日志体很大的话,瞬时的堆占用将非常可观。可能出现来不及消费的日志Event挤占新生代空间,导致频繁YGC,吞吐量下降及日志Event对象晋升到老年代,进而出现FGC,由于FGC是STW的,会把Log4j后台写日志的线程也暂停掉,进一步影响了后台日志消费线程的执行,导致情况进一步恶化。
对比2.8.2及2.14.1的源码,其中一处变化是修改了默认的异步队列满策略:2.14.1判断了当前日志写入线程是不是Log4j的回写线程,如果不是,就让当前线程等待RingBuffer消费出Slot。实践证明,这样的策略是更加合理的。
在日志体较大的情况下,还有一个细节值得注意:有一个叫做 MessagePatternConverter 的 Converter。这个Converter是会搜索整个日志文件,把${}占位符替换成真实值。具体实现是用了一个for循环的方法搜索形如${的连续字符并加以处理。对于刚才那种上MB大小、且根本没有
${}占位符需要替换的的请求日志,此特性只能是浪费计算资源,影响日志消费速度。
public void format(final LogEvent event, final StringBuilder toAppendTo) {
final Message msg = event.getMessage();
if (msg instanceof StringBuilderFormattable) {
final boolean doRender = textRenderer != null;
final StringBuilder workingBuilder = doRender ? new StringBuilder(80) : toAppendTo;
final int offset = workingBuilder.length();
if (msg instanceof MultiFormatStringBuilderFormattable) {
((MultiFormatStringBuilderFormattable) msg).formatTo(formats, workingBuilder);
} else {
((StringBuilderFormattable) msg).formatTo(workingBuilder);
}
// TODO can we optimize this?
// 这里,会全文搜索 ${} 然后尝试替换。如果不需要这个特性的场合都是可以关闭来提高性能的。
if (config != null && !noLookups) {
for (int i = offset; i < workingBuilder.length() - 1; i++) {
if (workingBuilder.charAt(i) == '$' && workingBuilder.charAt(i + 1) == '{') {
final String value = workingBuilder.substring(offset, workingBuilder.length());
workingBuilder.setLength(offset);
workingBuilder.append(config.getStrSubstitutor().replace(event, value));
}
}
}
if (doRender) {
textRenderer.render(workingBuilder, toAppendTo);
}
return;
}
if (msg != null) {
String result;
if (msg instanceof MultiformatMessage) {
result = ((MultiformatMessage) msg).getFormattedMessage(formats);
} else {
result = msg.getFormattedMessage();
}
if (result != null) {
toAppendTo.append(config != null && result.contains("${")
? config.getStrSubstitutor().replace(event, result) : result);
} else {
toAppendTo.append("null");
}
}
}根因
最终,我们认为导致此现象发生的原因是:冷 JVM 涌入大量大日志打印请求 -> RingBuffer 大量占用堆内存 + 日志消费跟不上速度 -> 触发YGC,甚至是STW FGC -> STW FGC暂停Log4j消费写盘线程 -> 恶性循环,应用雪崩。
在问题排查过程中 ,还发现首页应用使用的新版 AliJDK 在使用新版协程支持来处理线程间切换以及阻塞、唤醒调用时,存在极小概率出现调度器死循环,部分/全部线程失去响应,JVM僵死的情况。不排除协程调度器死循环可能影响Log4j日志消费线程的情况。该场景极难复现,出现时Thread dump工具、JVM Agent等诊断工具均无法连接上JVM,看不到现场,排查难度高。
此外,全协程模型带来的性能提升感知不强。因此,为了保险起见,处理此问题时,顺便也关闭了新版协程,使得JVM回退到传统的线程模型运行代码。
解法
对于该应用的FGC问题,采取4步走策略,逐个击破:
-
RingBuffer大量占用堆内存: 通过限制RingBuffer Slot数为一个合理值,保证应用中最大的LogEvent填满RingBuffer时也不至于把堆撑爆。本应用设置的是2048。
一般情况下,该值不需要调整。因为通常情况下极少有应用会产生超大日志体。如确实需要调整此参数,需要结合应用的日志使用场景,分情况评估。
-
JVM过冷:延长新启动机器小流量预热时长。
-
Log4j 队列满时内存占用过大:升级Log4j到2.14.1。使用新版队列满策略,同步等待队列消费出slot。
-
Log消费过程存在无意义的计算:对于不需要占位符替换的场景关闭占位符替换特性,提高消费速度。
成效
应用上述策略后,发布参数调整的修复分支。效果立竿见影,此分支发布过程中无任何FGC发生。回访应用负责人,此后所有的发布均不再出现上文提及的FGC。
玩家业务应用运行时FGC
现象
某玩家业务应用,使用G1GC垃圾回收器,平时集群正常承接业务流量,没有FGC,对象分配压力并不大。但是有一天集群突然出现FGC,且随着时间的推移FGC的频率越来越高。机器重启无法解决问题。

分析
查看发生FGC机器的JVM监控,可惜监控并没能给到太多有用的信息:
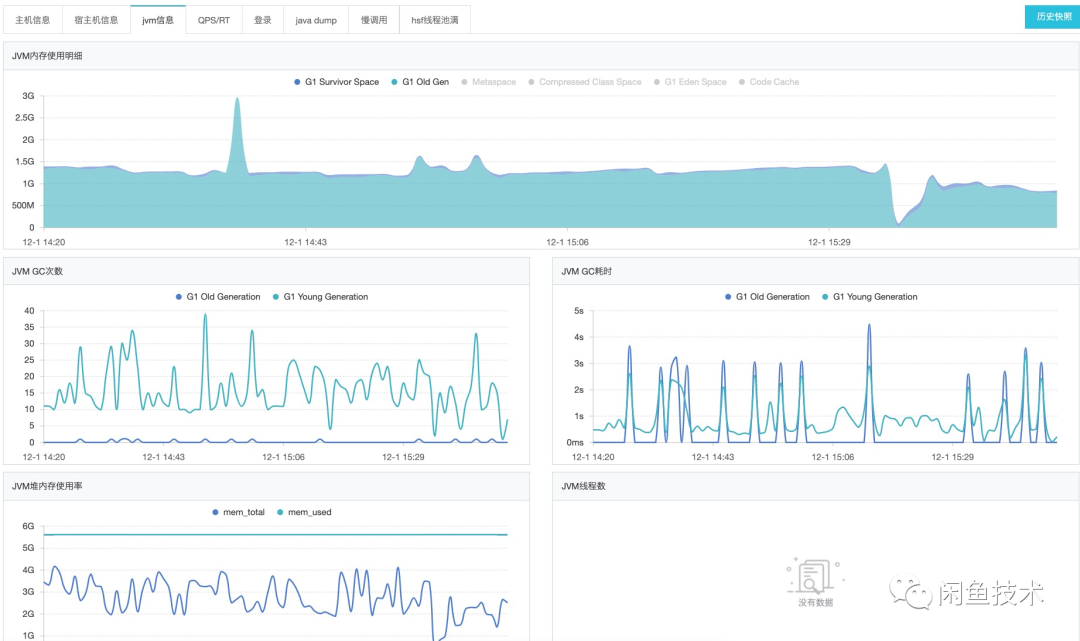
从监控上看,堆使用率、YGC次数等都比较正常,机器运行过程中老年代基本上保持在相对稳定的水位,偶尔出现FGC时,也能迅速清理掉堆中死亡对象,使得占用迅速回落到正常水位。因此基本可以排除内存泄漏、担保分配、晋升等原因而出现的缓慢上升的老年代占用。
从接口QPS、RT、Load等指标看,这些指标也非常平稳,可以排除有瞬时大流量冲击机器导致爆发式业务压力产生的FGC。多次FGC之间间隔并不规律;排查过定时任务调度平台,也可以排除由于某些内存压力较大的定时任务产生的FGC。
分析到这里,没有更好的办法,把目光转向FGC发生时的gc日志、应用日志,期望从日志中得到有价值的信息。
查看gc日志,发现在若干次正常的YGC后,存在一次to-space exhausted: 这是一次因为Eden区空间不够而产生的YGC,而在这次YGC中Survivor区也不够用。一般情况下G1GC因为会根据新生代对象存活率自适应调整Survivor区大小,基本上极少出现to-space exhausted。随后日志显示Old区占用上涨了数百MB。显然,这预示着业务中有超大对象分配。
这是一次因为Eden区空间不够而产生的YGC,而在这次YGC中Survivor区也不够用。一般情况下G1GC因为会根据新生代对象存活率自适应调整Survivor区大小,基本上极少出现to-space exhausted。随后日志显示Old区占用上涨了数百MB。显然,这预示着业务中有超大对象分配。
一旦知道有”超大对象”分配,方向就变得明朗了起来。G1认为占用了超过Region大小一半的连续堆空间的对象是大对象。且在大对象分配时,会给出大对象分配的调用栈。
该应用中配置的Region大小为32M,一半则为16M。
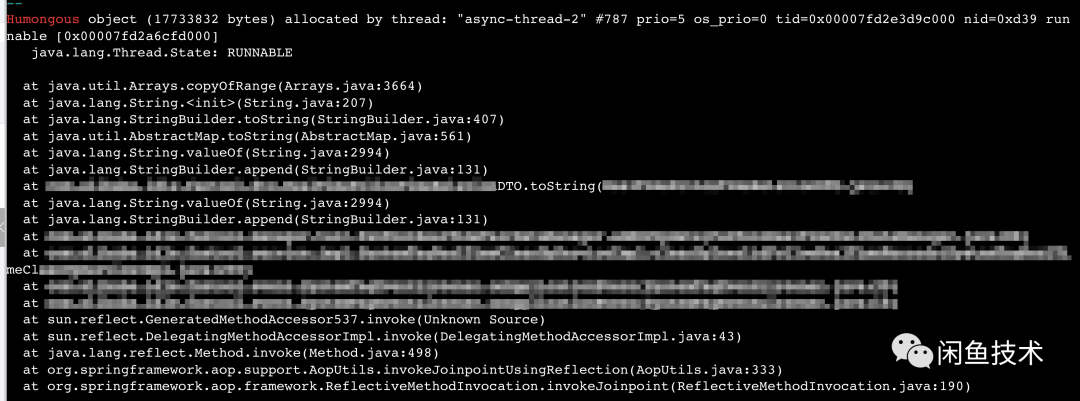
根因
通过排查上述调用栈的代码,发现是一句日志打印的代码引发的血案。具体现场如下代码段所示:
// type definition
@Data
public class MapWrapper {
// ...
public Map<Key, Value> manyEntryMap;
// ...
}
// biz code
MapWrapper instance = xxx;
log.info("print some log with plus concation! obj: " + instance);
// Correct way to print a log with object should be:
// log.info("print some log with plus concation! obj: {}", instance);一个类实例里面封装着一个有非常多的Entry的Map,这个类又因为有@Data注解,lombok会为其隐式实现toString方法。而在打印日志过程中,使用 + 操作符连接字符串和对象,会默认调用对象的toString方法,将对象转化成字符串形式。
该对象在没转换成字符串的时候,虽然里面的Map有非常多的Entry,但是都是分散在堆的各处的,不是连续的内存。体现为MapWrapper的支配堆空间可能很大,但是本体占用十分小。
一旦调用toString方法,将对象转换成字符串形式时,就会把Map里面每个entry都转化成字符串形式保存在一个字符串里;而字符串本体需要一段连续的内存来保存char信息,因此需要一段连续的堆空间来存储这个字符串。如果Map的Entry很多,那么最终出来的字符串就会很大,当超过了一半Region大小时,G1会认为这是一个大对象,直接分配到老年代。
更要命的是,底层在使用StringBuilder来append字符串,当StringBuilder需要扩容时,会创建一个新的char[]数组,并把原来的内容复制到新的char[]数组里面。如果原来的char[]数组已经是分配到老年代的大对象了,那新的char[]数组也会被分配到老年代,最终一次toString可能产生好几个驻留在老年代的大对象,尽管它们已经死亡。
反映到gc日志上,即为老年代激增数百MB。
可能有读者好奇,理论上一个日志对象这么大,应该能在磁盘利用率,磁盘写入IO量等指标上有所反映。而该应用设置的线上环境日志等级为WARN,这个产生了大对象分配的日志打印等级为INFO。所以这个大对象不会打到磁盘上。因此,一条根本不会被打印到磁盘上的日志,就因为一个小小的 +,就多出了大量的计算工作、内存分配,甚至导致了线上FGC的发生。
解法
看上去复杂的问题,解法有时候反而非常简单:可以通过修改代码,使用”{}”占位符来拼接对象;也可以直接优化掉这句日志打印。
成效
负责此业务的同学优化掉了上述日志、排查了大Map产生的业务场景并做了相关优化。修复上线后,FGC消失。
总结
本文介绍的三则前台应用FGC问题,分别是由JVM参数、中间件配置、业务代码层面引起。三则案例监控表象、分析过程、解决方法不尽相同。但是给开发同学们的启发却是相通的。
从工程层面:开发同学在写每一行代码的时候,都应该清楚这行代码的行为、包括时间、空间复杂度,以及一些极端情况下会产生的后果;开发功能时,应该充分了解业务特点,设计合适的数据结构;使用中间件,框架时,应该熟悉中间件提供的特性,遵循中间件的推荐用法,避免日后埋坑。
从问题分析层面:要培养透过现象看本质的思考方式,熟悉各种监控指标的作用以及监测的对象,在出现问题的时候能够快速通过各项指标定位问题点,为快速止血及后续的修复提供方向。
从技术层面:借用一句Oracle官方文档对G1回收器调优参数介绍时的总结:”When you evaluate or tune any garbage collection, there is always a latency versus throughput trade-off”。GC调优的根本难点在于:找到回收吞吐量和停顿时间的平衡点。应用的平均GC吞吐量 = sum(每次GC回收的堆空间) / sum(GC运行时间)。目前市面上有很多“并发式”垃圾回收算法,允许用户线程和垃圾回收线程同时运行,以便获得更短的停顿时间。然而,停顿时间并不等于GC运行时间,如果一个GC算法虽然停顿时间很短,但是总体运行时间较长;在GC完成前,被死亡对象占用的堆空间可能是无法完全释放的,与GC线程并发运行的用户线程在这个时间段仍然会继续分配新对象,如果堆剩余空间不足以坚持到GC执行完成,就有可能因为堆空间不足,回退到STW的FGC,反而得不偿失。因此,在配置垃圾回收器的相关参数时,也需要综合考虑应用的对象分配特点,模拟线上真实业务负载,找到最合适的参数值,从而保证业务运行稳定。

发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/150802.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
