大家好,又见面了,我是你们的朋友全栈君。
前言
免责声明:
本篇博文的初衷是分享自己学习逆向分析时的个人感悟,所涉及的内容仅供学习、交流,请勿将其用于非法用途!!!任何由此引发的法律纠纷均与作者本人无关,请自行负责!!!
版权声明:
未经作者本人授权,禁止转载!!!


上篇博客已经分析了网易云音乐的加密参数。本篇通过酷狗音乐进行逆向分析,进而加深对逆向分析流程的理解。
目标:通过输入歌名或者歌手名,列出相应的音乐信息,然后通过选择某一项,将对应的音乐下载到本地指定目录。
工具:Google Chrome、PyCharm
这里依旧以我最喜欢的歌手本兮为例,这里播放了一首下雪的季节,需要RMB才能听完整版的:

1. 请求分析
如果想要下载一首歌,我们首先要获取到这首歌所对应的 u r l url url。随机选择一首歌进行播放,打开Chrome的开发者工具,刷新看一下对应的请求,找到我们想要的歌曲文件的 u r l url url,就是下面这个:
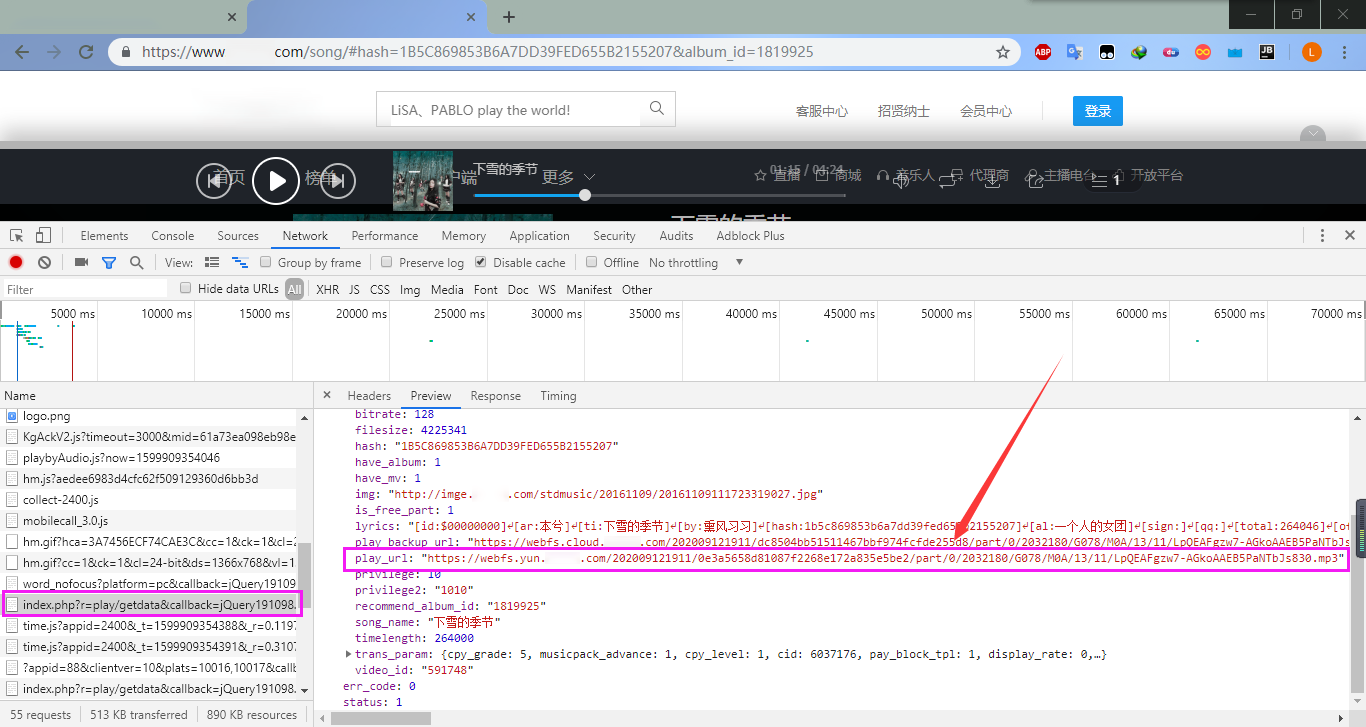
然后找到该请求对应的 u r l url url,分析一下该请求:
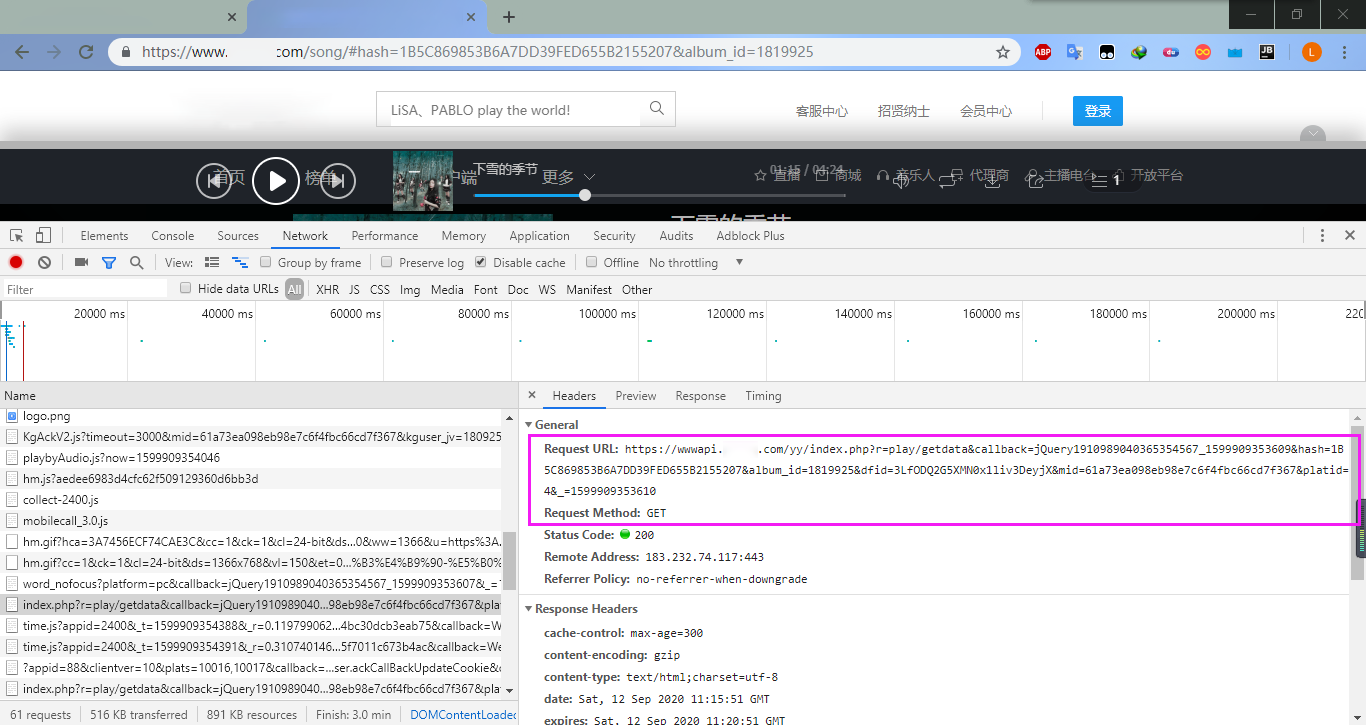
可知,获取数据的 u r l url url 为https://wwwapi.xxxxx.com/yy/index.php?r=play/getdata&callback=jQuery1910989040365354567_1599909353609&hash=1B5C869853B6A7DD39FED655B2155207&album_id=1819925&dfid=3LfODQ2G5XMN0x1liv3DeyjX&mid=61a73ea098eb98e7c6f4fbc66cd7f367&platid=4&_=1599909353610,请求方式为GET,它要提交的参数已经包含在了 u r l url url 里,而且里面有很多不是必须的参数。
经过几次刷新发现,参数callback和_的值是一直在变化的,其他参数是固定的。根据经验,GET请求方式的 u r l url url 一般是可以简化的,即去掉不是必须的参数后仍然可以正常得到数据,简化后的 u r l url url 为https://wwwapi.xxxxx.com/yy/index.php?r=play/getdata&hash=1B5C869853B6A7DD39FED655B2155207,但是通过程序访问这个 u r l url url 却是失败的,这说明,请求需要cookie。
综上分析可以猜测到,一首歌对应一个参数hash的值,而且这个参数肯定在搜索结果中,下面要做的就是找到这个hash。
2. 获取参数
我们来到搜索界面:

然后打开Chrome的开发者工具,刷新看一下对应的请求,找到我们想要的搜索结果列表,就是下面这个:
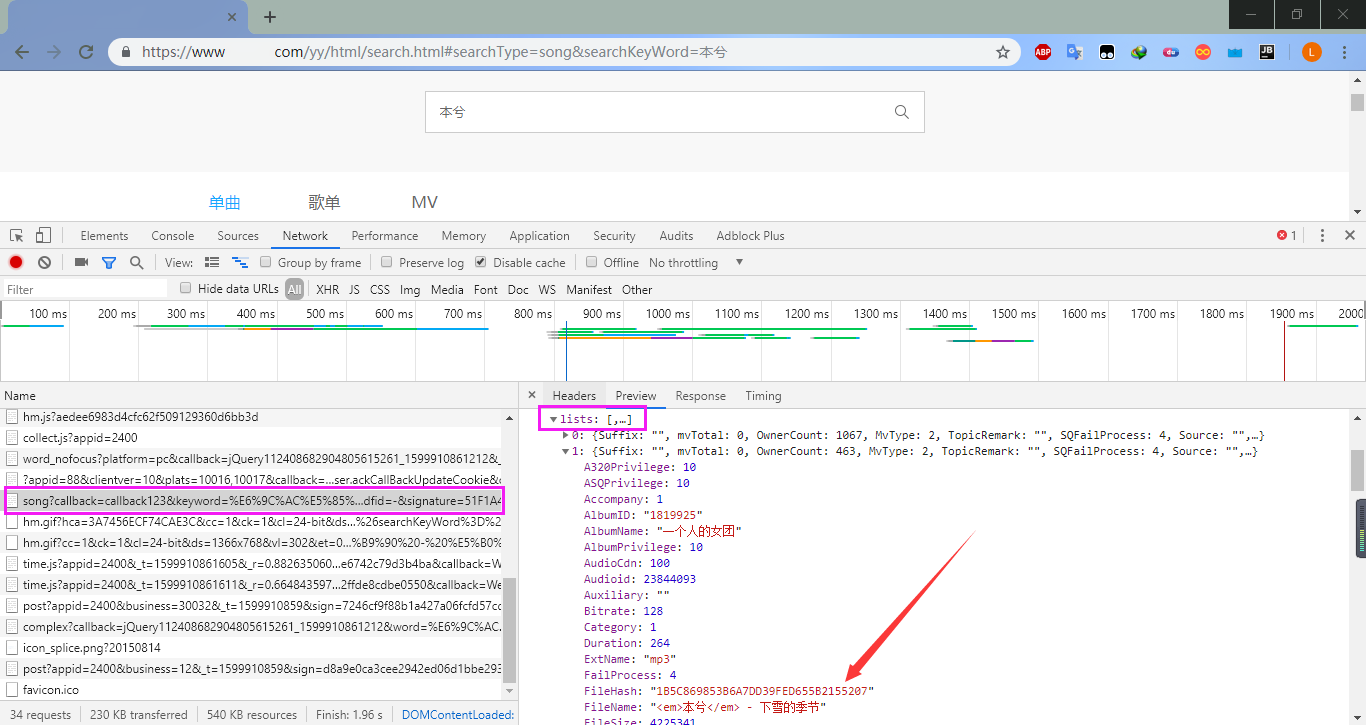
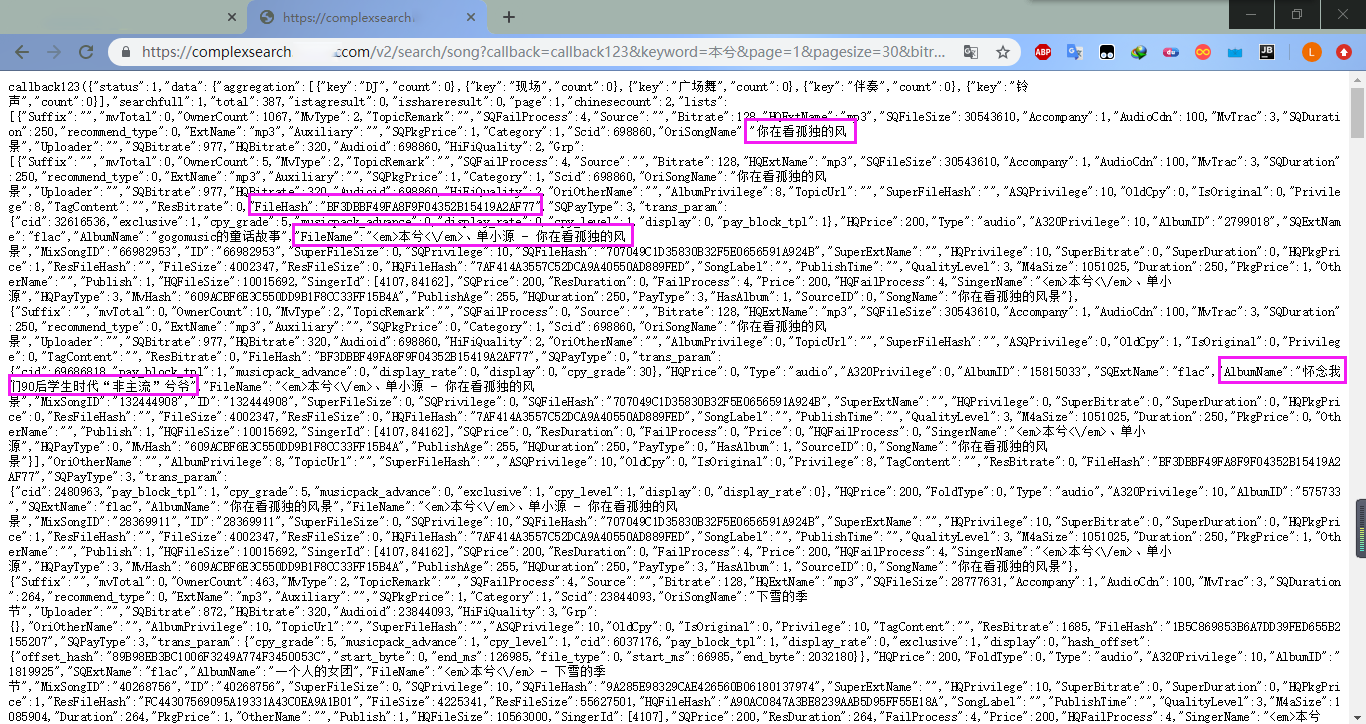
可以看到,我们想要的hash其实就是FileHash,而且里面还有歌名、歌手以及专辑等信息。然后找到对应的 u r l url url,分析一下该请求:
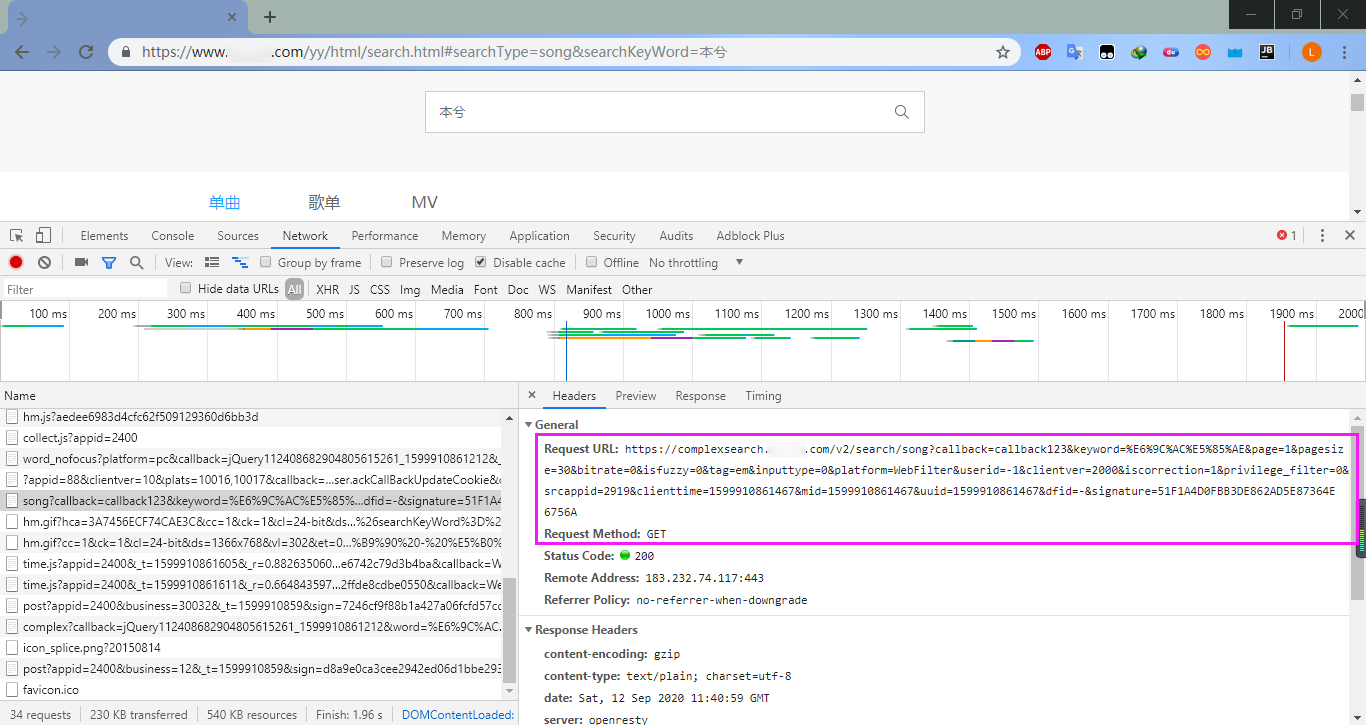
依旧是个GET请求, u r l url url 为https://complexsearch.xxxxx.com/v2/search/song?callback=callback123&keyword=%E6%9C%AC%E5%85%AE&page=1&pagesize=30&bitrate=0&isfuzzy=0&tag=em&inputtype=0&platform=WebFilter&userid=-1&clientver=2000&iscorrection=1&privilege_filter=0&srcappid=2919&clienttime=1599910861467&mid=1599910861467&uuid=1599910861467&dfid=-&signature=51F1A4D0FBB3DE862AD5E87364E6756A,先简单分析一下它的参数是什么意思,参数keyword就是我们在搜索那里输入的内容,参数page为页数,参数pagesize表示每页显示多少条信息。这里依旧是很长的一串,我尝试这简化 u r l url url,然而并没有成功,错误信息为"error_msg" : "Parameter Error"、"error_msg" : "err signature"和"error_msg" : "err appid(srcappid) or clientver or mid or dfid",可以推测出参数signature应该是很重要的,而且经过刷新发现参数signature、clienttime、mid和uuid每次都会发生变化,且后面三个一直相同。估计参数可能被加密了,全局搜索参数signature,将其定位:
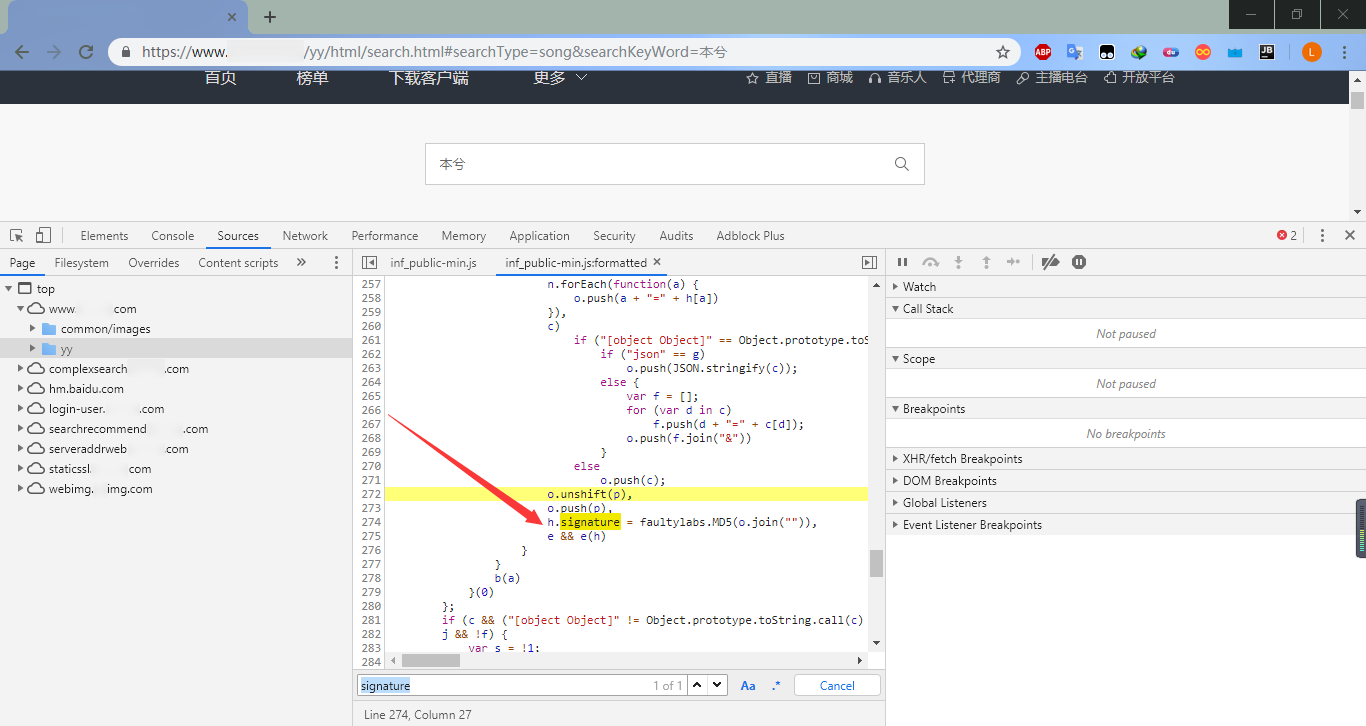
果然,参数signature被MD5加密了,打上几个断点,然后debug看一下:
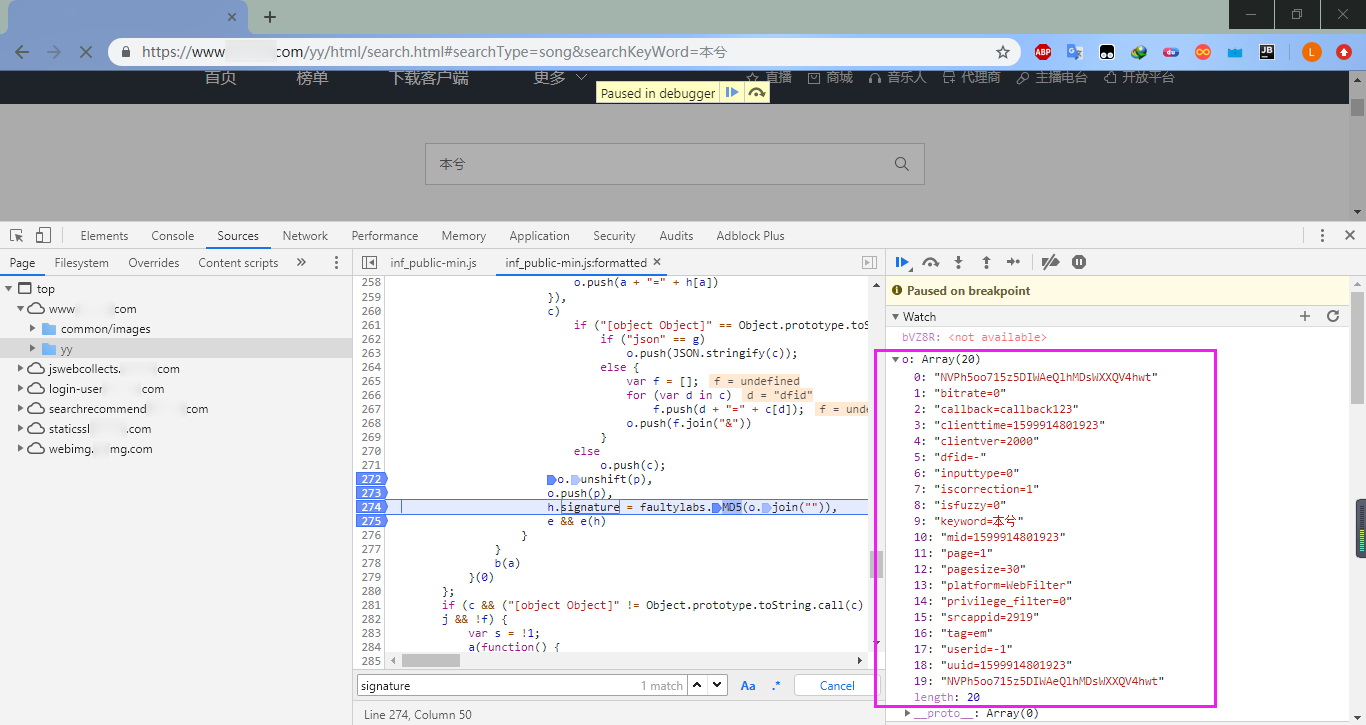
参数是20个,但是只有参数clienttime、mid和uuid发生变化,而且它们还相同,找一下它们来自哪里,向上定位到了它们的位置:
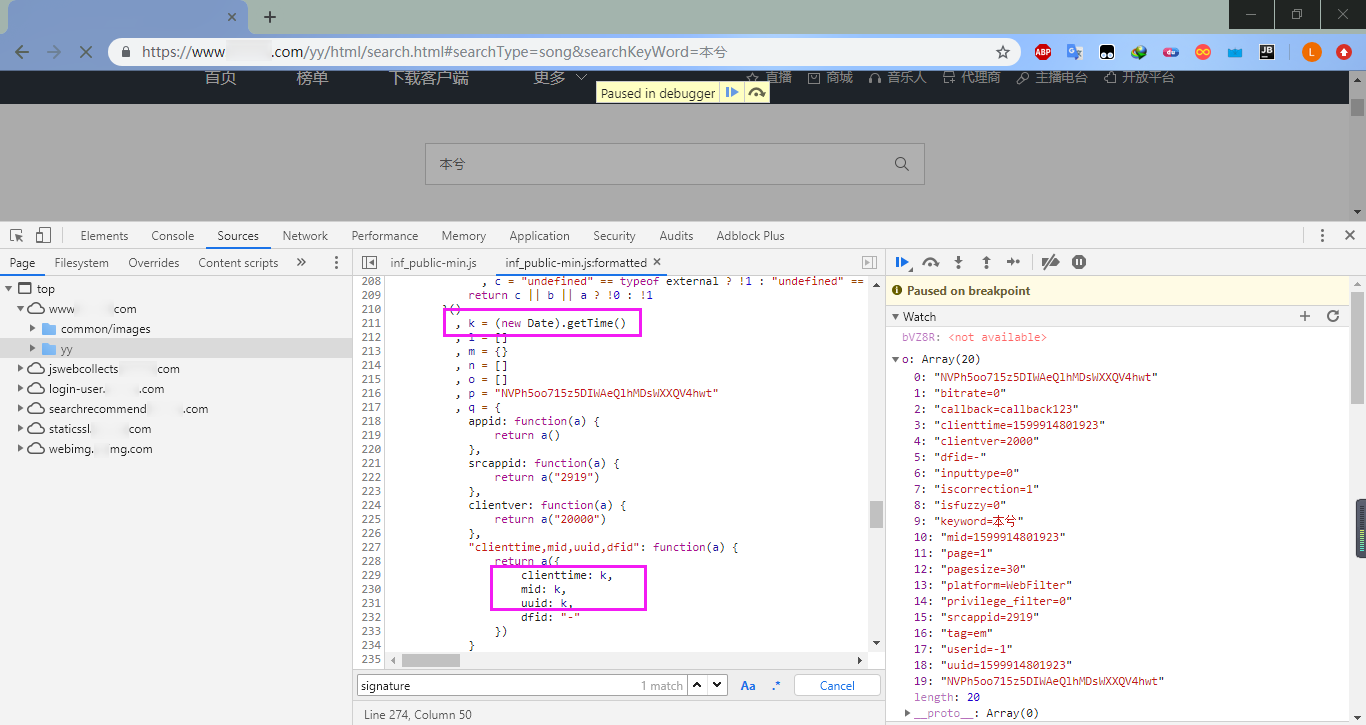
发现是个时间序列,由JavaScript中的getTime()方法生成的,它返回的是毫秒数,在Python中可以用time模块的time()方法代替。下面来模拟一下MD5加密,这里可以使用Python的标准库hashlib:
def MD5Encrypt(self, text):
# 返回当前时间的时间戳(1970纪元后经过的浮点秒数)
k = time.time()
k = int(round(k * 1000))
info = ["NVPh5oo715z5DIWAeQlhMDsWXXQV4hwt", "bitrate=0", "callback=callback123",
"clienttime={}".format(k), "clientver=2000", "dfid=-", "inputtype=0",
"iscorrection=1", "isfuzzy=0", "keyword={}".format(text), "mid={}".format(k),
"page=1", "pagesize=30", "platform=WebFilter", "privilege_filter=0",
"srcappid=2919", "tag=em", "userid=-1", "uuid={}".format(k), "NVPh5oo715z5DIWAeQlhMDsWXXQV4hwt"]
# 创建md5对象
new_md5 = md5()
info = ''.join(info)
# 更新哈希对象
new_md5.update(info.encode(encoding='utf-8'))
# 加密
result = new_md5.hexdigest()
return result.upper()
这个加密的结果就是参数signature,为了检验结果的正确性,我们将时间序列和上面的保持一致,即clienttime = mid = uuid=1599910861467,运行结果如下:
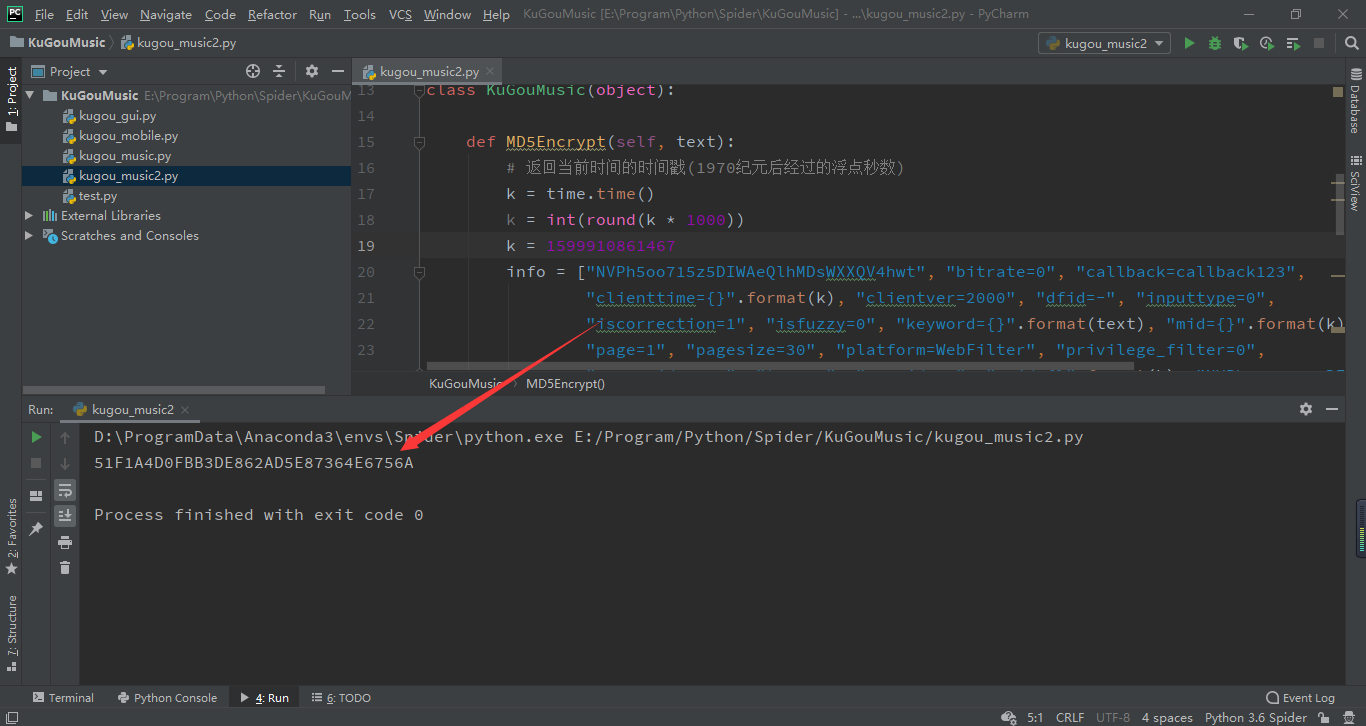
结果是正确的,然后我们拼接成 u r l url url即可:
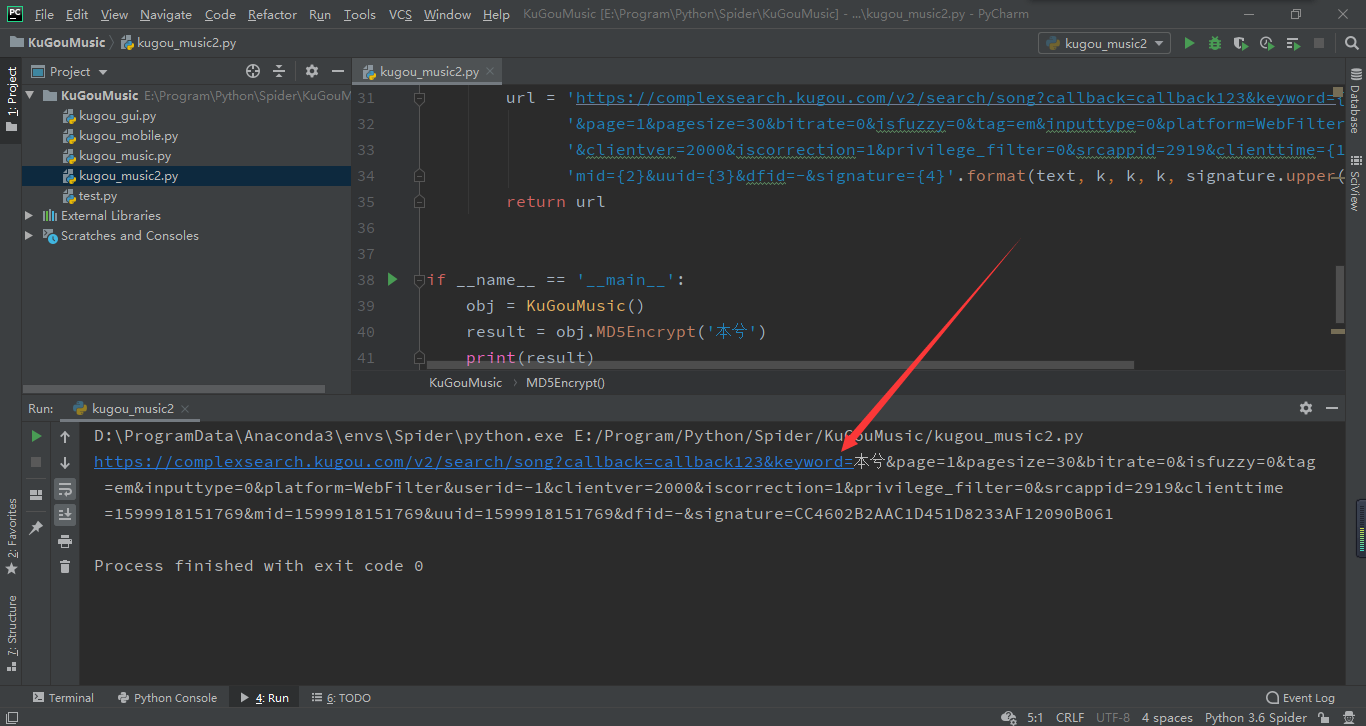
我们访问拼成的 u r l url url可以正常得到数据:
u r l url url小常识:
+ 表示空格
/ 分隔目录和子目录
? 分隔实际的URL和参数
% 表示特殊字符
# 表示书签
& 表示参数间的分隔符
= 表示参数的值
3. 提取信息
两个请求的 u r l url url 我们都已经获得了,下面就是将数据从json格式的文本中提取出来,然后对歌曲文件 u r l url url 发起请求,将结果以二进制形式保存,后缀名为.mp3。不废话,直接上代码:
# -*- coding: utf-8 -*-
# @Time : 2020/9/12 21:01
# @Author : XiaYouRan
# @Email : youran.xia@foxmail.com
# @File : kugou_music2.py
# @Software: PyCharm
import time
from hashlib import md5
import json
import requests
import re
import os
class KuGouMusic(object):
def __init__(self):
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
def MD5Encrypt(self, text):
# 返回当前时间的时间戳(1970纪元后经过的浮点秒数)
k = time.time()
k = int(round(k * 1000))
info = ["NVPh5oo715z5DIWAeQlhMDsWXXQV4hwt", "bitrate=0", "callback=callback123",
"clienttime={}".format(k), "clientver=2000", "dfid=-", "inputtype=0",
"iscorrection=1", "isfuzzy=0", "keyword={}".format(text), "mid={}".format(k),
"page=1", "pagesize=30", "platform=WebFilter", "privilege_filter=0",
"srcappid=2919", "tag=em", "userid=-1", "uuid={}".format(k), "NVPh5oo715z5DIWAeQlhMDsWXXQV4hwt"]
# 创建md5对象
new_md5 = md5()
info = ''.join(info)
# 更新哈希对象
new_md5.update(info.encode(encoding='utf-8'))
# 加密
signature = new_md5.hexdigest()
url = 'https://complexsearch.kugou.com/v2/search/song?callback=callback123&keyword={0}' \
'&page=1&pagesize=30&bitrate=0&isfuzzy=0&tag=em&inputtype=0&platform=WebFilter&userid=-1' \
'&clientver=2000&iscorrection=1&privilege_filter=0&srcappid=2919&clienttime={1}&' \
'mid={2}&uuid={3}&dfid=-&signature={4}'.format(text, k, k, k, signature.upper())
return url
def get_html(self, url):
# 加一个cookie
cookie = 'kg_mid=61a73ea098eb98e7c6f4fbc66cd7f367; kg_dfid=3LfODQ2G5XMN0x1liv3DeyjX; kg_dfid_collect=d41d8cd98f00b204e9800998ecf8427e; Hm_lvt_aedee6983d4cfc62f509129360d6bb3d=1599906321; Hm_lpvt_aedee6983d4cfc62f509129360d6bb3d=1599922649'.split(
'; ')
cookie_dict = {
}
for co in cookie:
co_list = co.split('=')
cookie_dict[co_list[0]] = co_list[1]
try:
response = requests.get(url, headers=self.headers, cookies=cookie_dict)
response.raise_for_status()
response.encoding = 'utf-8'
return response.text
except Exception as err:
print(err)
return '请求异常'
def parse_text(self, text):
count = 0
hash_list = []
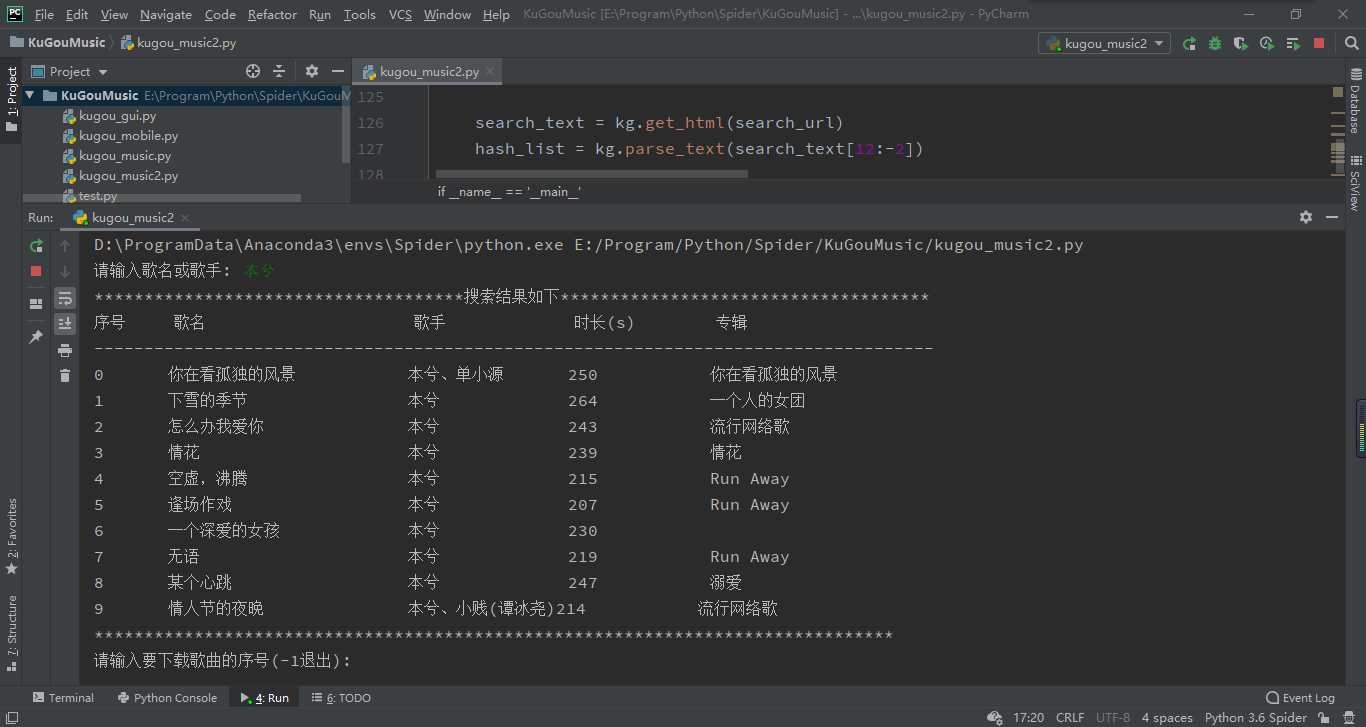
print('{:*^80}'.format('搜索结果如下'))
print('{0:{5}<5}{1:{5}<15}{2:{5}<10}{3:{5}<10}{4:{5}<20}'.format('序号', '歌名', '歌手', '时长(s)', '专辑', chr(12288)))
print('{:-^84}'.format('-'))
song_list = json.loads(text)['data']['lists']
for song in song_list:
singer_name = song['SingerName']
# <em>本兮</em> 正则提取
# 先匹配'</em>'这4中字符, 然后将其替换
pattern = re.compile('[</em>]')
singer_name = re.sub(pattern, '', singer_name)
song_name = song['SongName']
song_name = re.sub(pattern, '', song_name)
album_name = song['AlbumName']
# 时长
duration = song['Duration']
file_hash = song['FileHash']
file_size = song['FileSize']
# 音质为HQ, 高品质
hq_file_hash = song['HQFileHash']
hq_file_size = song['HQFileSize']
# 音质为SQ, 超品质, 即无损, 后缀为flac
sq_file_hash = song['SQFileHash']
sq_file_size = song['SQFileSize']
# MV m4a
mv_hash = song['MvHash']
m4a_size = song['M4aSize']
hash_list.append([file_hash, hq_file_hash, sq_file_hash])
print('{0:{5}<5}{1:{5}<15}{2:{5}<10}{3:{5}<10}{4:{5}<20}'.format(count, song_name, singer_name, duration, album_name,
chr(12288)))
count += 1
if count == 10:
# 为了测试方便, 这里只显示了10条数据
break
print('{:*^80}'.format('*'))
return hash_list
def save_file(self, song_text):
filepath = './download'
if not os.path.exists(filepath):
os.mkdir(filepath)
text = json.loads(song_text)['data']
audio_name = text['audio_name']
author_name = text['author_name']
album_name = text['album_name']
img_url = text['img']
lyrics = text['lyrics']
play_url = text['play_url']
response = requests.get(play_url, headers=self.headers)
with open(os.path.join(filepath, audio_name) + '.mp3', 'wb') as f:
f.write(response.content)
print("下载完毕!")
if __name__ == '__main__':
kg = KuGouMusic()
search_info = input("请输入歌名或歌手: ")
search_url = kg.MD5Encrypt(search_info)
search_text = kg.get_html(search_url)
hash_list = kg.parse_text(search_text[12:-2])
while True:
input_index = eval(input("请输入要下载歌曲的序号(-1退出): "))
if input_index == -1:
break
download_info = hash_list[input_index]
song_url = 'https://wwwapi.kugou.com/yy/index.php?r=play/getdata&hash={}'.format(download_info[0])
song_text = kg.get_html(song_url)
kg.save_file(song_text)
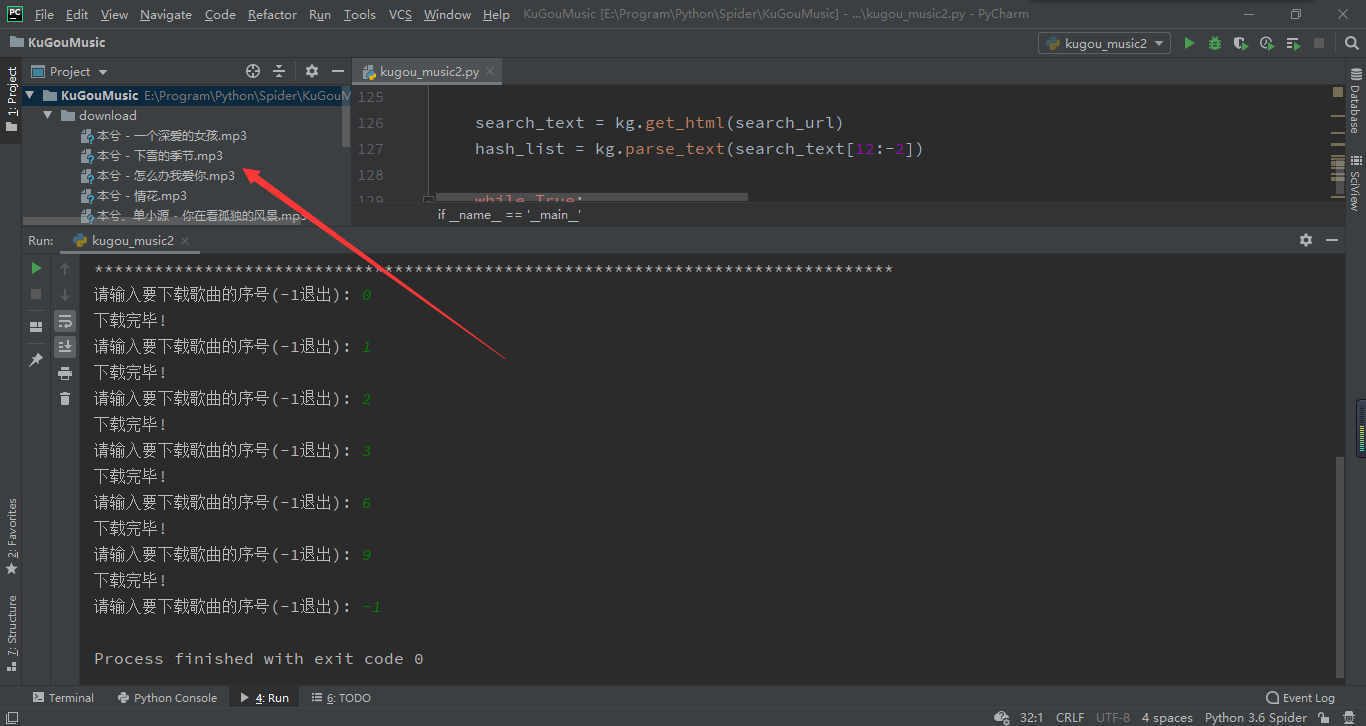
测试结果如下:
结束语
今天分析的搜索结果接口和我以前分析出来的有点不一样,而且以前的接口还可以正常使用,没记错的话以前是不需要cooike的。
url = "https://songsearch.xxxxx.com/song_search_v2?keyword={}&platform=WebFilter".format(song_name)
与网易云音乐相比,酷狗音乐的请求相对来说简单了些,基本上没有什么加密,而且酷狗的音乐版权还贼多,我喜欢ヾ(^∀^)ノ
开源代码仓库
如果喜欢的话记得给我的GitHub仓库点个Star哦!ヾ(≧∇≦*)ヾ
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/150753.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
