大家好,又见面了,我是你们的朋友全栈君。
P2P技术应用
一、P2P的工作方式概述
二、P2P文件分发
1.P2P体系结构的扩展性
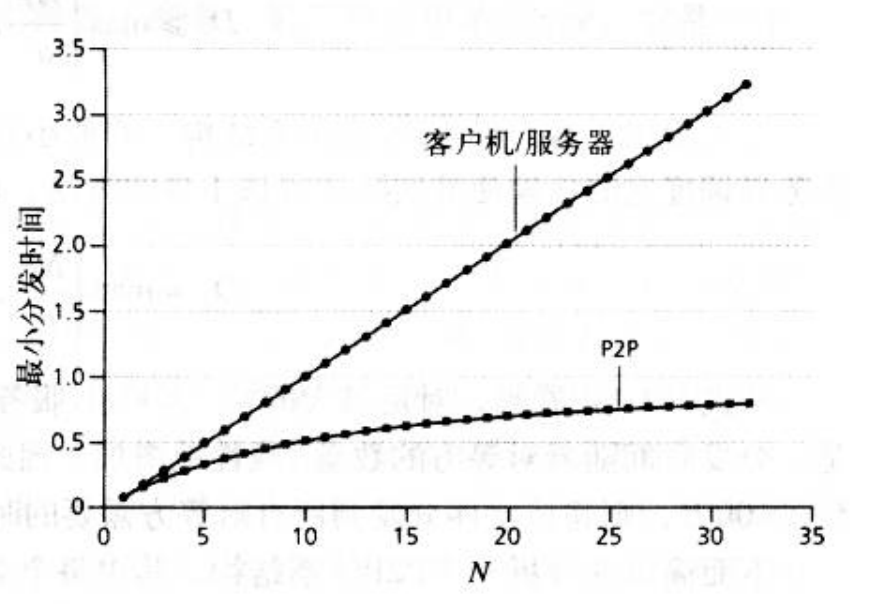
为了比较客户机/服务器体系结构与对等体系结构,阐述P2P的扩展性,我们现在考虑一个用于两种体系结构类型的简单定量模型,将一个文件分发给一个固定集合。如图1所示,服务器和对等方使用接入链路与因特网相连。其中,u-s表示服务器接人链路的上载速率,u-i表示第i个对等方接入链路的上载速率,d-i表示第i个对等方接入链路的下载速率。此外,F表示被分发的文件长度(以比特计),N表示要获得文件拷贝的对等方的数量。分发时间(distribution time) 是N个对等方得到文件拷贝所需要的时间。在下面关于分发时间的分析中,对两种体系都做了简化的假设,即因特网核心具有大量的带宽,这意味着所有瓶颈都在网络接入链路上。我们还假设服务器和客户机没有运行任何其他网络应用,因此它们所有上载和下载访问带宽都用于分发文件。
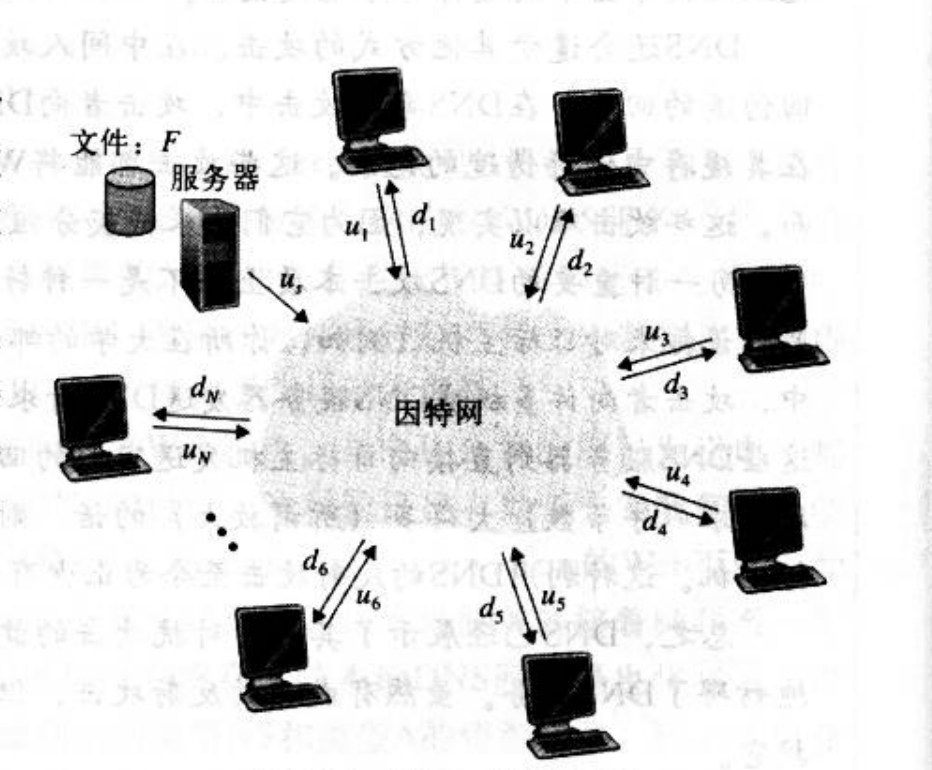

- 服务器必须向N个对等方的每个都传输一个文件拷贝,因此该服务器必须传输NF比特,因为该服务器的上载速率是u_s,所以分发给文件的时间至少是NF/u_s.
- 令d_min表示下载速率最小的对等方的下载速率,即d_min=min{d1,d2,……,dn}。下载速率最小的对等方不可能在F/d_min秒之内获得该文件的所有F比特。因此,最小分发时间至少为F/d_min。
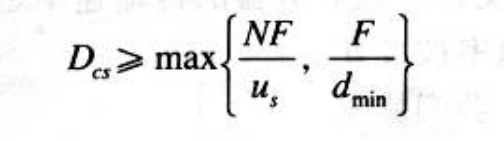
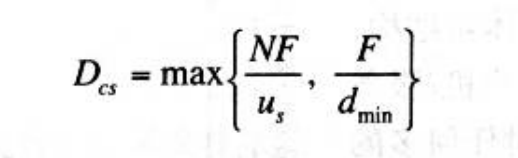
下面简单地分析一下P2P体系结构,其中每个对等方都能够帮助服务器来分发文件。也就是说,当一个对等方接收到文件数据时,它可以利用自己的上载能力重新将数据分发给其他对等方。计算P2P体系结构的分发时间在某种程度上比计算客户机/服务器体系结构的分发时间更复杂,因为分发时间取决于每个对等方如何向其他对等方分发部分该文件。但不管怎样,都可以得到对该最小分发时间的一个简单表达式。我们先作下列观察:
- 在分发的开始,只有服务器拥有文件。为了是这些对等方得到该文件,服务器必须经其接入链路至少发送一次该文件的每一个比特。因此,最下分发时间至少是F/u_s。( 与客户机/服务器方案不同,服务器发送过一次的比特可能就不用再次发送了,因为对等方可以互相重新发送这些比特。)
- 与客户机/服务器体系结构相同,下载速率最小的对等方不可能在F/d_min秒之内获得所有的F比特。因此,最小分发时间至少为F/d_min。
- 最后,系统的总上载能力等于服务器的上载速率加上每个对等方的上载速率,即u_total=u_s+u1+…+un。系统必须向N个对等方的每个交付F比特,因此总共交付NF比特。这不可能快于u_total的速率完成。所以,最小分发时间至少是nf/(u_s+u1+….+un)。

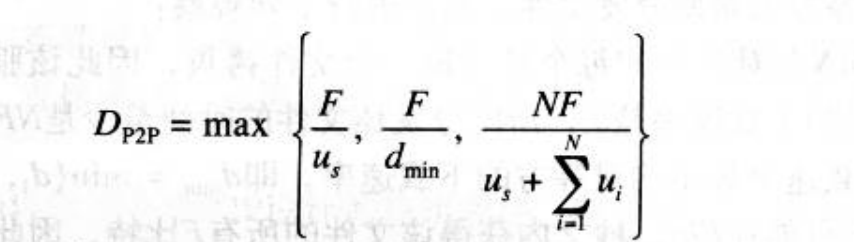
2.BitTorrent
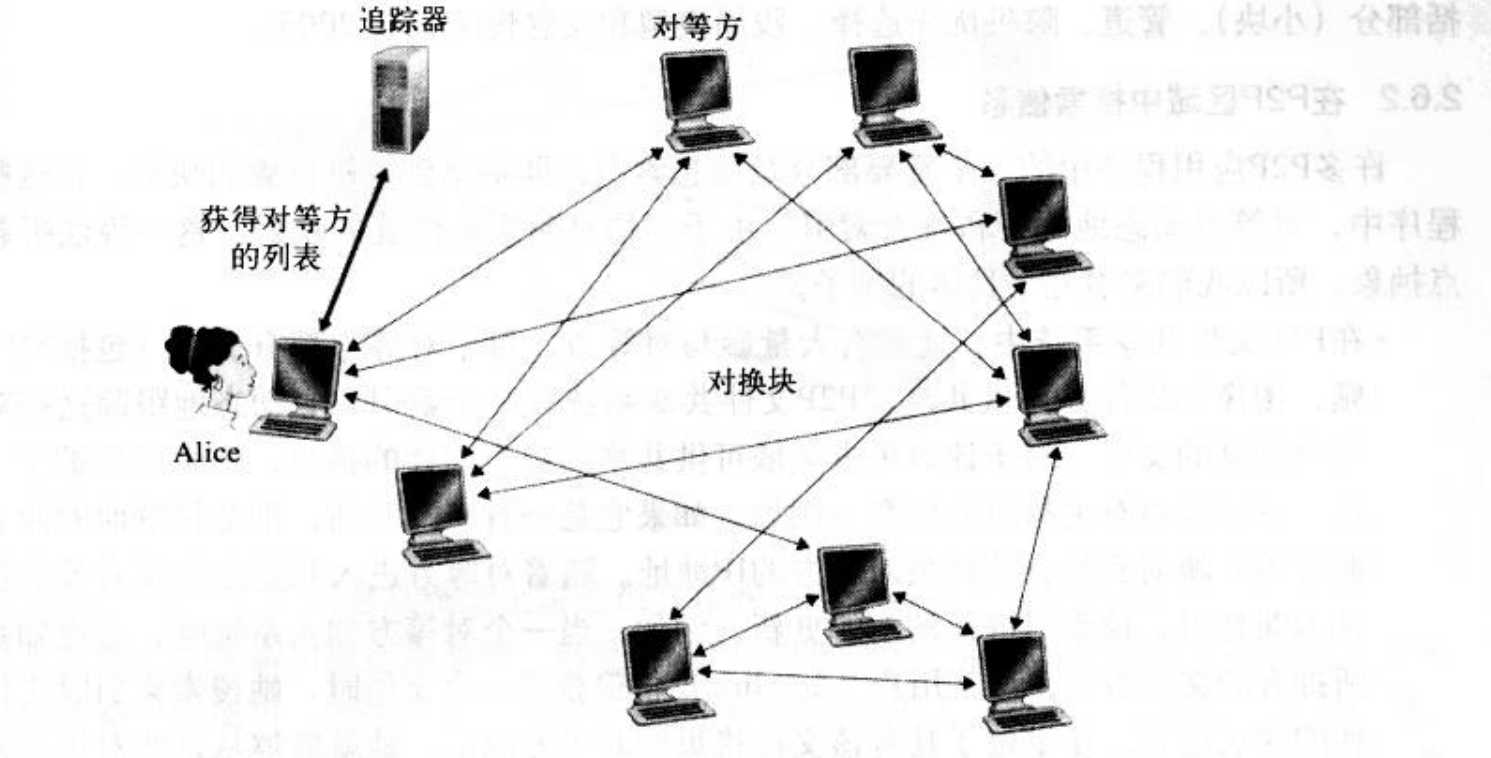
居,那么她将获得L个块列表。因此,Alice将对她当前还没有的块发出请求(仍通过TCP连接)。
因此,在任何给定的时刻,Alice将具有块的子集并知道其邻居具有哪些块。于是,Alice将作出两个重要决定。第一,她应当向她的邻居请求哪些块呢? 第二,她请求的块应当发送
给她的哪些邻居? 在决定请求哪些块的过程中,Alice使用一种称为最稀罕优先(rarest first )的技术。这种技术的思路是,根据她没有的块从她的邻居中确定最稀罕的块(最稀罕的块就
是在她的邻居中拷贝数量最少的那些块),并优先请求那些最稀罕的块。按照此方式,最稀罕的块更迅速地重新分发,其目标(大致) 是均衡每个块在洪流中的拷贝数量。
为了决定她响应哪个请求,BitTorrent使用了一种机灵的对换算法。其基本想法是Alice确定其邻居的优先权,这些邻居是那些当前能够以最高的速率供给她数据的。特别是,Alice对于她的每个邻居都持续地测量接收到比特的速率,确定以最高速率流人的4个邻居。然后,她将数据块发给这4个邻居。每过10秒,她重新计算该速率并可能修改这4个对等方。更重要的每过30秒,她要随机地选择一个另外的邻居并向它发送块。我们将这个随机选择的对等
方称为Bob。因为Alice在向Bob发送数据,所以她可能成为Bob前4位上载者之一,这样的话Bob将开始向Alice发送数据。如果Bob向Alice发送数据的速率足够高,那么他也能成为Alice的前4位上载者。换言之,每过30秒Alice将随机地选择一名新的对换伙伴并开始与那位伙伴进行对换。如果这两个对等方都满足此对换要求,那么它们会将对方放人其前4位列表中并继
续与对方进行对换,直到对等方之一发现了一个更好的伙伴为止。这样,对等方就能够以趋
于满意的速率上载。而随机选择邻居是为了让新的对等方得到块,因此它们能够有对换的东西。除了这5个对等方(4个“前面”对等方和1个探测对等方),所有其他相邻对等方均被“阻止”,即它们不能从Alice接收到任何块。
3.在P2P区域中搜索信息
可供共享的文件。对于该对等方区域可供共享的每个文件的拷贝,该索引维护了一个记录,该记录将有关拷贝的信息(例如,如果它是一首MP3歌曲,则是该歌曲的曲名、作曲家等) 映射到具有该拷贝对等方的IP地址。随着对等方进人和退出以及对等方获得文件的新拷贝,该索引进行动态的更新。例如,当一个对等方加入系统时,它通知系统它所拥有的文件索引。当某用户(如Alice) 希望获得一个文件时,她搜索索引以定位该文件的拷贝位置。在定位了具有该文件拷贝的对等方以后,她就能够从这些对等方处下载该文件。一旦她具有了该完整文件,就会更新索引以将她具有的该文件新拷贝算在内。
HandsomeBob。当HandsomeBob在具有IP地址X的主机上启动他的即时讯息客户机时,他的客户机将通知该索引HandsomeBob正以IP地址X在线。随后,当BeautifulAlice启动她的即时讯息客户机时,因为HandsomeBob位于她的好友列表中,所以她的客户机在该索引上搜索HandsomeBob并发现了他以IP地址X在线。然后,BeautifulAlice可以与具有地址X的主机创建一个直接的TCP连接,并与HandsomeBob开始即时讯息通信。除了即时讯息外,许多其他应用程序也使用索引来进行跟踪,包括因特网电话系统。
定位文件的一个最直接的办法是提供一个集中式索引(centralized index),就像Napster那样。Napster是第一家大规模部署P2P文件共享应用程序的商业公司。在这种设计中,
由一台大型服务器(或服务器场(farm)) 来提供索引服务。如图所示,当用户启动P2P文件共享应用程序时,该应用程序将它的IP地址以及可供共享的文件名称(如它存储的所有MP3标题)通知索引服务器。该索引服务器从每个活动的对等方那里收集这些信息,从而建立一个集中式的动态索引,将每个文件拷贝映射到一个IP地址集合。注意,具有集中式索引的P2P文件共享系统实际上是一种P2P和客户机/服务器混合体系结构。文件分发是P2P的,但搜索是客户机/服务器的。目前很多应用程序都采用了这样的混合体系结构,如许多即时讯息应用程序。
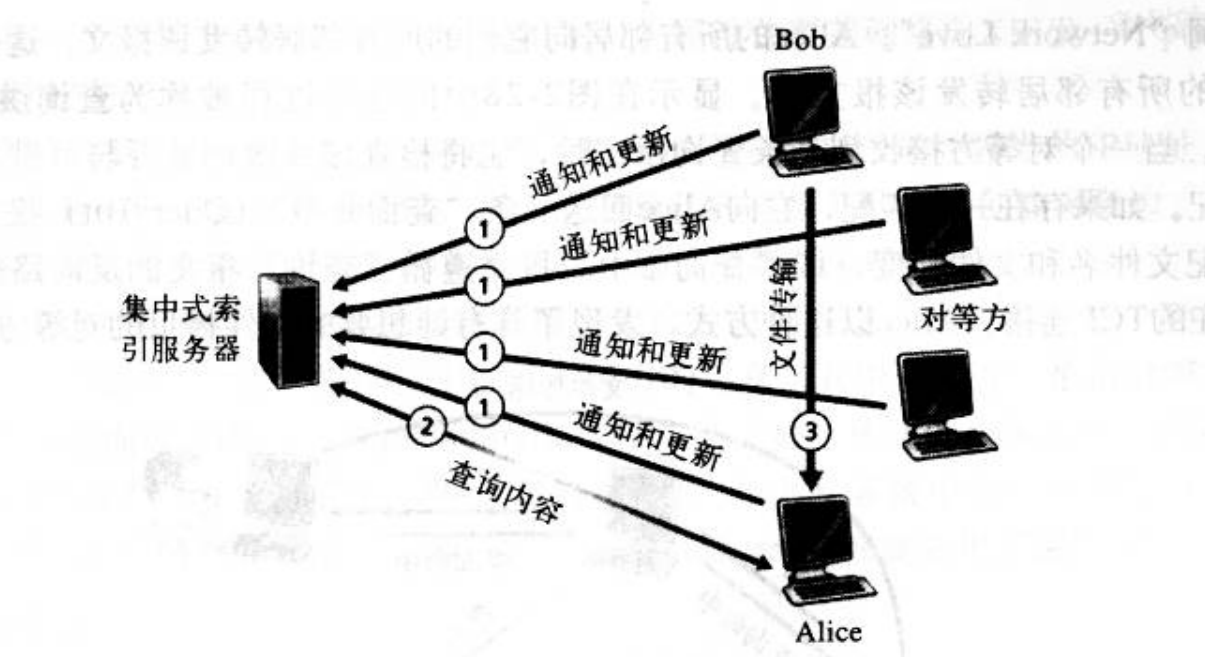
- 单点故障。如果索引服务器崩溃,则整个P2P应用也就随之崩溃。即使服务器场还有多余的服务器可以使用,因特网与服务器场之间的连接也可能失效,从而导致整个应用崩溃。
- 性能瓶颈和基础设施费用。在一个大型的P2P系统中,有着成千上万条的连接用户,集中式服务器必须维护一个庞大的索引,每秒钟必须对数千次查询做出响应。事实上,
- Napster作为2000年最流行的P2P应用,其中央服务器承受了巨大通信量问题的折磨。
- 侵犯版权。尽管这个主题超出了本书的范围,但我们还是要简要地提一下唱片录音行业所关注的问题(最低程度这样说),即P2P文件共享系统允许用户免费获取受版权保护的。 当一个P2P文件内容共享公司有一台集中式索引服务器时,法律程序将迫使该索引服务器不得不关闭。不过关闭具有更分散的体系结构的系统要困难得多。
在Gnutella中,对等方形成了一个抽象的逻辑网络,该网络被称为覆盖网络(overlay network)。用图论的术语来说,如果对等方X与另一个对等方Y维护了一个TCP连接,那么我们就说在X和Y之间有一条边(edge)。图由所有活跃的对等方和连接的边(持续的TCP连接)它定义了覆盖网络。注意,一条边不是一条物理通信链路,而是一条抽象链路,该链
路可能由下面的许多物理链路组成。例如,某覆盖网络中的一条边可能表示在立陶宛的一个对等方与在巴西的一个对等方之间的TCP连接。
尽管一个覆盖网络可能有成千上万参与对等方,但一个给定的对等方通常与该覆盖网络中的少量(通常少于10个) 节点连接,如图2-28所示。后面我们将解释当对等方加人和离开网络时,覆盖网络是如何构建和维护的。此时我们假定覆盖网络已经存在,先关往某对等方定位和检索内容。
在这种设计中,对等方通过已经存在的TCP连接,
向覆盖网络中的相邻对等方发送报文。
当Alice要定位“Network Love”时,
她的客户机向她的所有邻居发送一条查询报文,该报文包括关键词“Network Love”。Alice的所有邻居向它们的所有邻居转发该报文,这些邻居又接着向它们的所有邻居转发该报文等。显示在图2-28中的这个过程被称为查询洪泛(query flooding)。当一个对等方接收到一条查询报文时,它将检查该关键词是否与可供共享的任何文件相匹配。如果存在一个匹配,它向Alice回送一条“查询命中”(QueryHit) 报文,该报文包含了匹配文件名和文件长度。该“查询命中”报文遵循“查询”报文的反向路径,因而使用预先存在的TCP连接。Alice以这种方式,发现了具有她想要的文件拷贝的对等方。
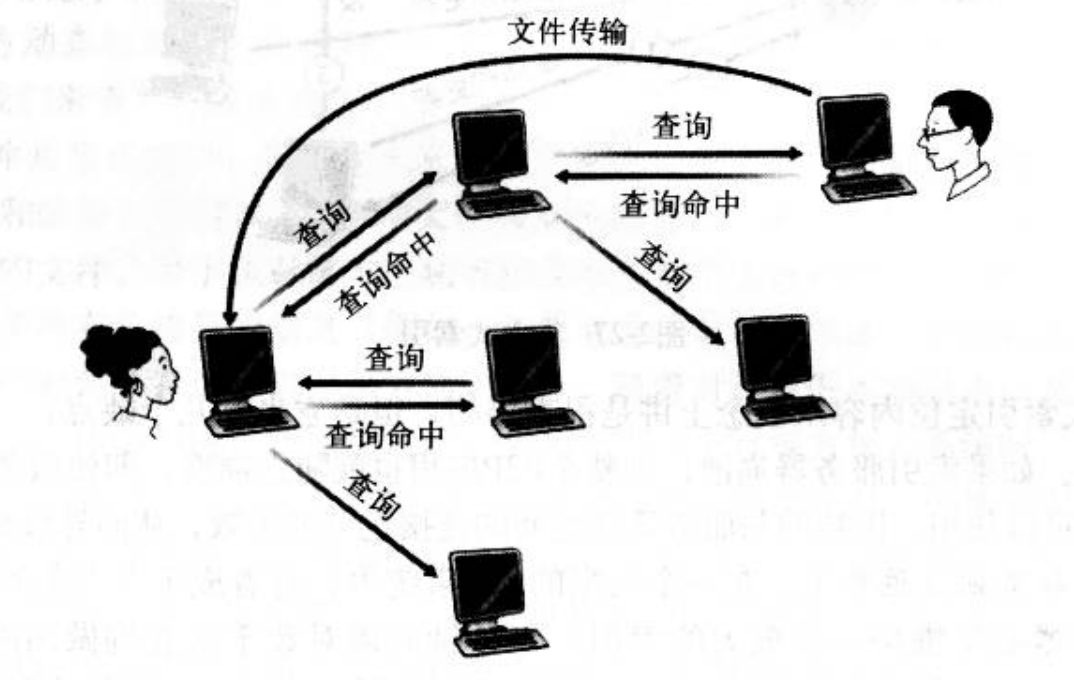
尽管这种分布式设计简单而优美,但也常因其扩展性差而受到批评。特别是对于洪泛查询,只要某对等方发起查询,该查询就会传播到整个覆盖网络中的每个其他对等方,从而在连接对等方的支撑网络(如因特网) 中产生大量流量。Gnutella的设计者为解决该问题使用了范围受限查询洪泛(limited scope query flooding)。具体说来,当Alice发出她的初始查询报文时,该报文中的对等方计数字段被设置一个特定值(比如说7)。每当该查询报文到达一个新对等该对等方在向其覆盖邻居转发该请求之前就将对等方计数字段减1。当某对等方接收到方时,一个对等方计数字段为0的查询时,它就停止转发该查询。用这种方式,洪泛被局限于覆盖网络的某个区域。
显然,这种范围受限查询洪泛减少了查询流量。然而,它也减少了对等方的数量。因此,即使你希望查找的内容在对等方区域的某个地方,你也可能不能定位到它。
1) 对等方X必须首先发现某些已经位于覆盖网络中的其他对等方。解决这种引导跨接问题(bootstrap problem) 的一种方法是,让X维护一张对等方的列表(IP地址),这些对等方经常在该覆盖网络中开机; 另一种方法是,X能够联系维护这种列表的跟踪站点(像BitTorrent中那样)。
5) 当X接收到该pong报文后,它知道了该覆盖网络中的许多对等方的IP地址。然后,它能够与某些其他对等方建立TCP连接,从而从它自己向该覆盖网络中创建多条边。
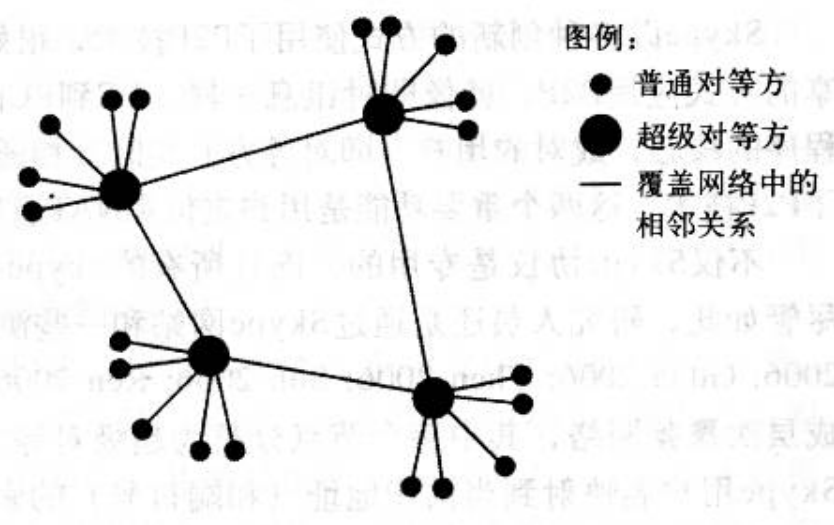
为了处理这种限制,超级对等方之间相互建立TCP连接,从而形成一个覆盖网络。借助于这个覆盖网络,超级对等方可以向其相邻超级对等方转发查询。该方法类似于查询洪泛,但覆盖网络中的超级对等方仅使用了范围受限查询洪泛。当某对等方进行关键词匹配时,它向其超级对等方发送带有该关键词的查询。超级对等方则用其具有相关文件的子对等方的IP地址进行响应,这些文件的描述符与关键词(连同这相匹配。该超级对等方还可能向一个或多个相邻超级对等方转发该查询。些文件的标识符)如果某相邻对等方收到了这样一个请求,它也会用具有匹配文件的子对等方的IP地址进行响应。超级对等方的响应遵循该覆盖网络中的反向路径。
通过将少量更强大的对等方指派为超级对等方,层次覆盖设计充分利用了对等方的异质性(heterogeneity of the peers),形成了一个层次覆盖网络的顶层,如图2-29所示。与范围受限查询洪泛设计(像初始的Gnutella设计那样) 相比,层次覆盖设计允许数量多得多的对等方检查匹配,而不会产生过量的查询流量。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/150744.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
