大家好,又见面了,我是你们的朋友全栈君。
在开始之前想先说下阅读完三尾先生这篇文章的一点个人理解,文章写得挺好的,很值得新手学习了解,首先谈下逆向激活成功教程思路
1.需要逆向的时候一般是遇到了加密问题,加密情况有提交参数加密和返回结果加密等情况。但不管怎样的加密只要页面能正常显示,那就有解密过程!
2.先找到加密的字段名,通过字段名在sources全局搜索
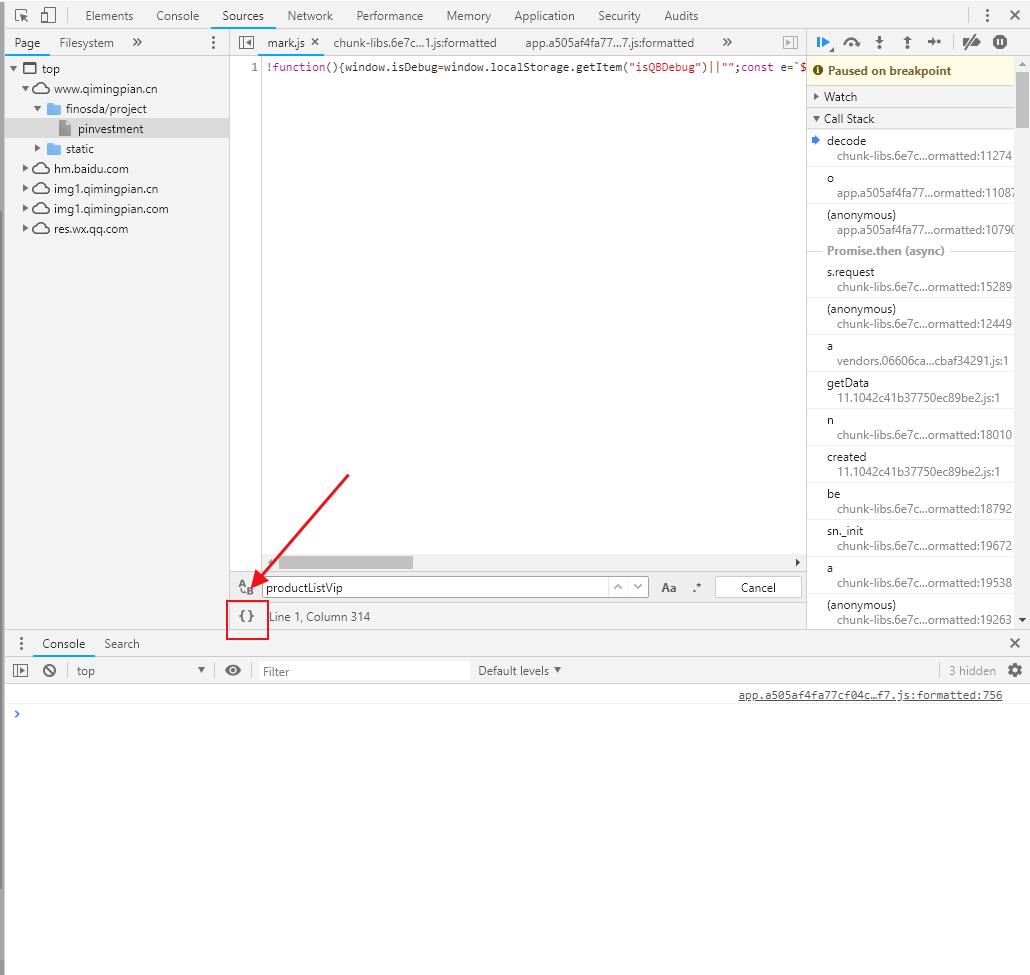
3.在含有这些字段的位置打断点,一般sources里看到的会是一行的压缩代码,我们可以通过点击左下角的双大括号格式化js代码
4. 格式化代码后,通过断点一步步查看参数在哪一步骤发生了变化,或在哪一步骤获得的值。一般结果解密可按js执行顺序断点,这篇文章就是一篇典型的结果解密的文章。而请求参数的加密一般就需要反复断点了,先断点到加密完成(即ajax发送参数值)然后再反复断点一步一步的往上推直到原始参数的传参;
(下面就是三尾先生 初探js逆向的原文了,很值得阅读了解练手)
前言
本文适合爬虫新手阅读,大佬也别绕道,欢迎指正和调教。
js逆向是让爬虫萌新们比较头疼的一块领域,因为市面上大部分的爬虫书籍等教程都未涉及这方面知识,需要爬取用js加密的网站时常常无从下手,只能使用selenium等自动化框架来模拟人工点击。但这种方式往往效率低下,所以本文将以企名片这个网站为例,带大家初探js逆向。
之所以选择这个网站,首先它难度不大,适合练手;其次即便激活成功教程了加密参数,想爬取数据还是得下些功夫,因为未登录情况下只显示一页数据,即便登录还得认证啥的比较麻烦。
废话不多说,下面进入正题。
环境准备
(了解思路的朋友可忽略该环境准备,有个浏览器即可,这里推荐chrome)
因为涉及js的调试验证,所以除了Python环境外,你还需要Nodejs(js的运行环境)和WebStorm(IDE)。
Nodejs去官网下载安装包后直接一键安装即可,安装完毕后去控制台运行node –version,如果出现版本号即代表安装成功。
WebStorm安装完后需要激活,激活教程网上很多,大家自行搜索。它是Jet Brains的产品(和PyCharm是同一家公司),所以使用方式与PyCharm很类似。
分析过程
直接访问这个地址https://www.qimingpian.com/finosda/project/pinvestment,看到的是这个界面:
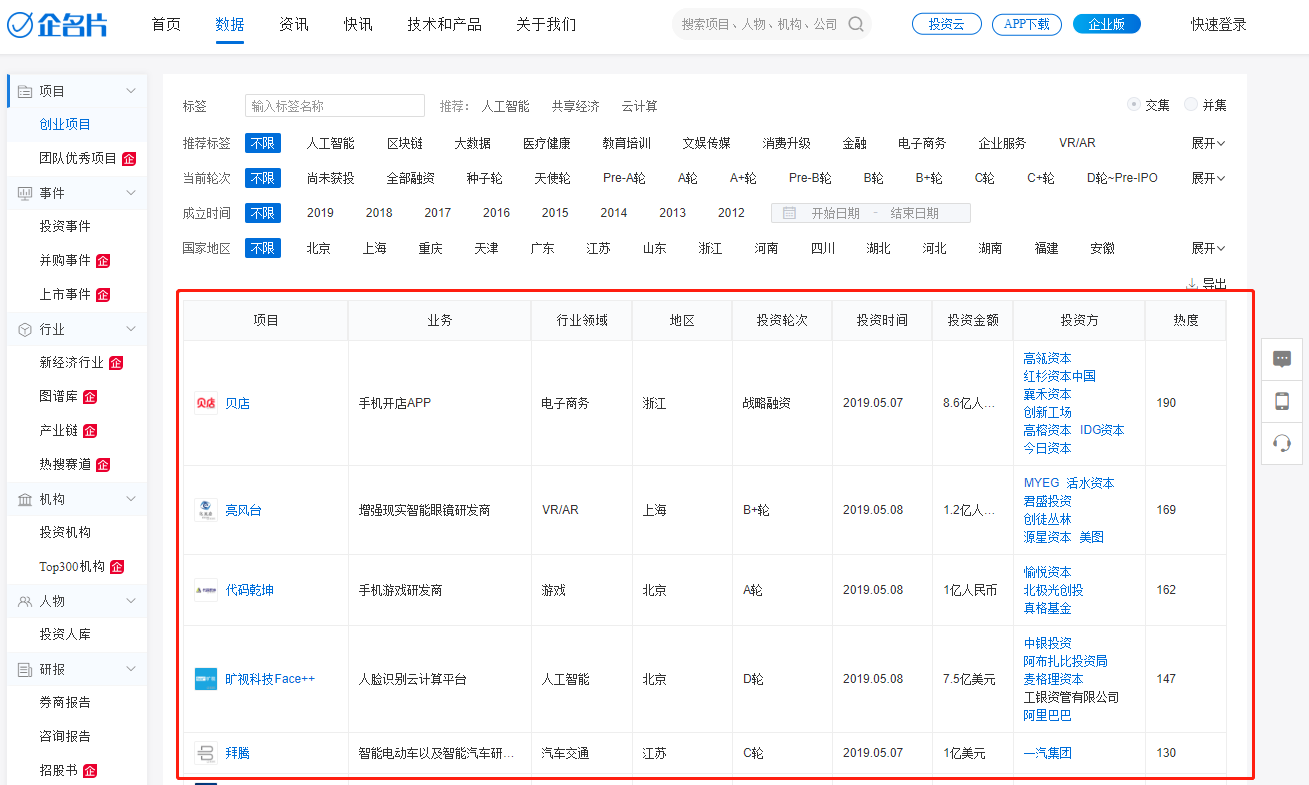

我们需要获取图中红框里的数据,也就是创业项目列表。打开开发者工具,刷新一下页面,看看它发起了哪些请求:
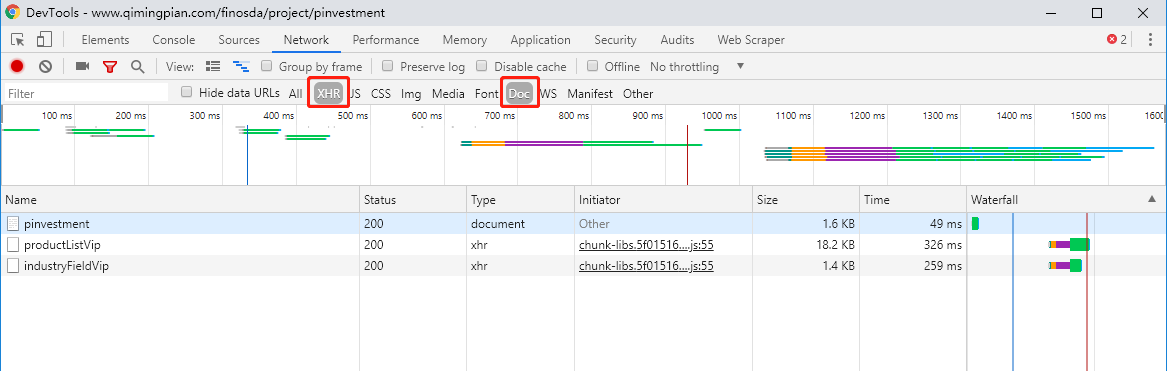
为减少干扰,先只看XHR和Doc的请求,一共有三个:pinvestment、productListVip、industryFieldVip。
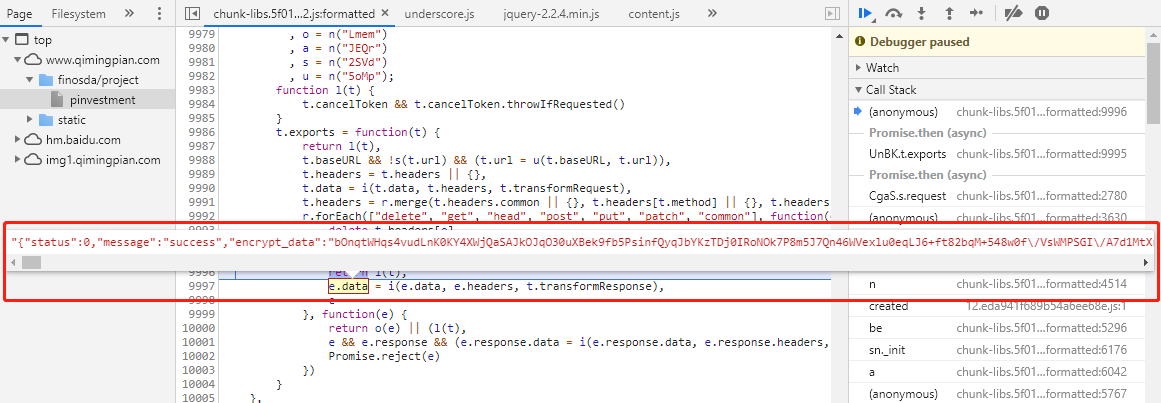
在pinvestment的响应内容里,只能看到一堆js的调用,并没有我们想要的html,说明网页是由js动态生成的。
而在productListVip和industryFieldVip的响应内容里,都有一个”encrypt_data”的参数,很明显这是一个加密参数,参数内容像是一串Base64字符。既然网站对这个参数做了加密,说明它不想被爬取,所以可以做个假设:我们的目标数据就是encrypt_data参数里的内容。
有了这个假设,目的就很明确了,只要激活成功教程这个加密参数就行。
爬虫新手们往往走完上面步骤就止步不前。不妨思考一下,参数虽做了加密,但网页毕竟要正常显示内容,所以在网页渲染的过程中,一定有个地方对这个参数做了解密,然后将数据写入html。
也就是说,我们需要在网页渲染的过程里,一步步观察,看看到底是哪个位置对这个参数做了解密。
在开发者工具里的Sources选项卡中,可以找到这个网页的js文件夹,界面右侧有断点调试栏。
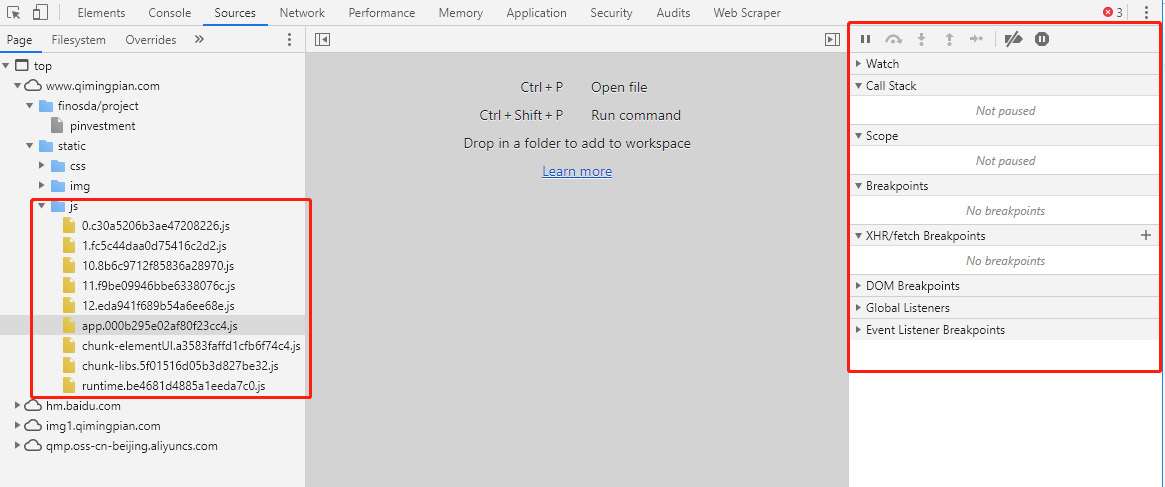
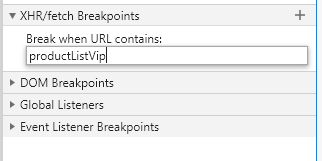
在js文件里打上断点,然后一步步调试,就能重现网页渲染的过程。那么断点应该打在哪个位置呢?在断点调试栏里有个XHR/fetch Breakpoints,它支持在发送XHR请求的位置打上断点,我们找到的两个含加密参数的请求就是XHR类型的,正好用上这个功能。点击+号输入请求名称即可:
刷新页面,然后一步一步执行,发现可疑信息就把鼠标移上去看下
调试的两个小技巧:
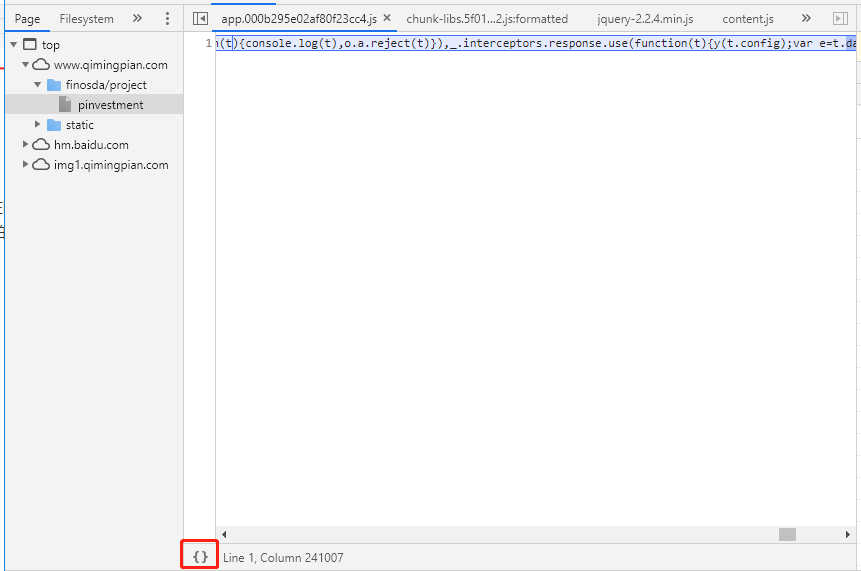
压缩的js点击左下角的花括号来美化
在调试过程中使用Console执行js代码。比如我觉得这个函数很可疑,想执行一下看看。
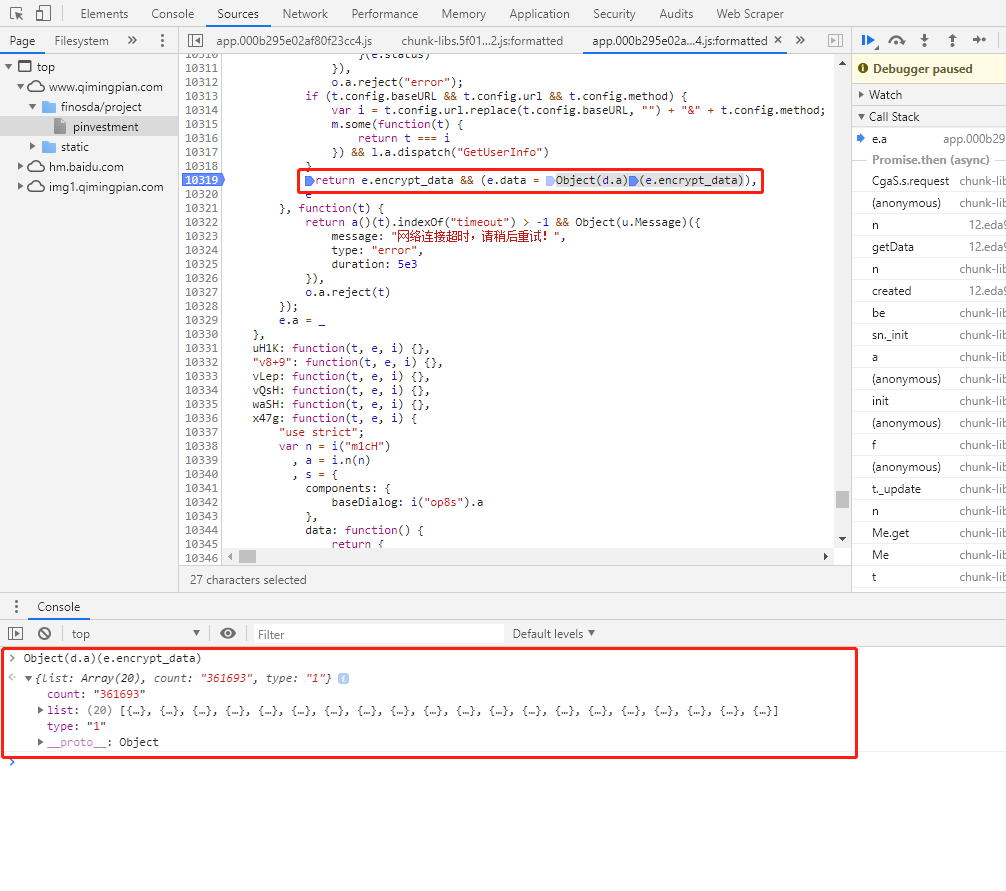
function o(t)就是我们需要的解密函数,可以看到它先调用s函数,传入了四个参数,除了a.a.decode(t)外其他三个都是写死的,最后用JSON.parse转为json对象。
然而,找到解密函数后,我们要做的不是去分析它函数内部做了什么,虽然可以研究它的解密算法然后用Python重写,但这样太复杂且没必要。因为我们可以用PyExecJS这个库,直接用Python调用并执行js代码。
这时候,WebStorm就派上用场了。新建一个js文件,把function o里涉及的代码全部抠下来。然后执行console.log把执行结果打印出来。篇幅问题就只贴部分代码:
//解密函数
function my_decrypt(t) {
return JSON.parse(s("5e5062e82f15fe4ca9d24bc5", my_decode(t), 0, 0, "012345677890123", 1))
}
//解密函数依赖项
function my_decode(t) {
c = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"
f = /[\t\n\f\r ]/g
var e = (t = String(t).replace(f, "")).length;
e % 4 == 0 && (e = (t = t.replace(/==?$/, "")).length),
(e % 4 == 1 || /[^+a-zA-Z0-9/]/.test(t)) && l("Invalid character: the string to be decoded is not correctly encoded.");
for (var n, r, i = 0, o = "", a = -1; ++a < e; )
r = c.indexOf(t.charAt(a)),
n = i % 4 ? 64 * n + r : r,
i++ % 4 && (o += String.fromCharCode(255 & n >> (-2 * i & 6)));
return o
}
//测试代码,加密参数太长就不贴上来了
encrypt_data = "xxx"
decrypt_data = my_decrypt(encrypt_data)
console.log(decrypt_data)
确实是我们需要的数据没错,最后用Python去调用解密函数就行了。调用时还有个需要注意的地方,因为直接返回object给Python会报错,所以这里将JSON.parse移除了,返回parse前的json字符串,
//解密函数
function my_decrypt(t) {
return s("5e5062e82f15fe4ca9d24bc5", my_decode(t), 0, 0, "012345677890123", 1)
}
同时为了防止这串字符串内有特殊编码的字符,这里将它转成base64再return:
function my_decrypt(t) {
return new Buffer(s("5e5062e82f15fe4ca9d24bc5", my_decode(t), 0, 0, "012345677890123", 1)).toString("base64")
}
然后在Python中用base64库的b64decode方法来解码即可。
本文所有代码已上传至Github,旨在学习和技术分享,请勿用于商业用途。
总结
最后总结一下,说说关于逆向的个人看法。
之所以市面上很少有爬虫逆向的书籍,除了因为它比较”敏感”之外,也因为它并没有固定的方法论。上文提供的也只是一种思路,其实还是有很多取巧的方式,比如在我们已知参数名为encrypt_data的情况下,在js文件夹下全局搜索,分分钟就能找到解密函数。
逆向过程挺糟心,也挺有趣的,且逆向成功后会有很大的成就感。
总而言之,逆向是一个提出假设和实际验证的过程,比如上文中的encrypt_data,我们不能百分百确定它就是我们需要的数据,但可以假设它是,来作为我们的突破口,即便最后发现不是,大不了再做新的假设。这有点像侦探探案,通过已知的信息作为线索来抽丝剥茧,最终破案。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/150716.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
