大家好,又见面了,我是你们的朋友全栈君。
我们通过requests可以很轻松地就获得网页上的所有内容,但是这些内容往往会夹杂着许多我们不需要的东西,因此我们需要解析和提取 HTML 数据。
在先前介绍过的解析和提取html内容的库,只能够处理静态文本执行简单的搜索,缺乏灵活性,不能处理动态的文本信息。
下面来介绍一下正则表达式。
什么是正则表达式?
- 正则表达式是用来简洁表达一组字符串的表达式
- 正则表达式是一种通用的字符串表达框架
- 正则表达式可以判断某字符串的特征归属
- 是一种模式,把该模式应用文本匹配,然后获取我们需要的内容
正则表达式可以干什么?
- 用来测试字符串内的模式。
例如,可以测试输入字符串,以查看字符串内是否出现电话号码模式或信用卡号码模式。这称 为数据验证。 - 替换文本
可以使用正则表达式来识别文档中的特定文本,完全删除该文本或者用其他文本替换它、 - 基于模式匹配从字符串中提取字符串
可以查找文档中或输入域内特定的文本;可以使用正则表达式来搜索和替换标记。
正则表达式在文本处理中十分常用:
- 同时查找或替换一组字符串
- 匹配字符串的全部或部分(主要)
正则表达式的语法(正则表达式由字符和操作符构成)
- 常用的操作符
-
. 表示任何单个字符
-
[]字符集,对单个字符给出取值范围,如[abc]表示a,b,c;[a-z]表示a到z单个字符
-
[^ ]非字符集,对单个字符给出排除范围 ,如[^abc]表示非a或b或c的单个字符 -
*前一个字符0次或无限次扩展,如abc* 表示 ab、abc、abcc、abccc等 -
+前一个字符1次或无限次扩展 ,如abc+ 表示 abc、abcc、abccc等 -
?前一个字符0次或1次扩展 ,如abc? 表示 ab、abc -
|左右表达式任意一个 ,如abc|def 表示 abc、def -
{m}扩展前一个字符m次 ,如ab{2}c表示abbc -
{m,n}扩展前一个字符m至n次(含n) ,如ab{1,2}c表示abc、abbc -
^匹配字符串开头 ,如^abc表示abc且在一个字符串的开头 -
$匹配字符串结尾 ,如abc$表示abc且在一个字符串的结尾 -
( )分组标记,内部只能使用 | 操作符 ,如(abc)表示abc,(abc|def)表示abc、def -
\d数字,等价于[0‐9] -
\w单词字符,等价于[A‐Za‐z0‐9_]
-
re的使用方式
- 调用方式:import re
- re库采用raw string类型表示正则表达式,表示为:r’text’,raw string是不包含对转义符再次转义的字符串
re库的主要功能函数:
- re.search() 在一个字符串中搜索匹配正则表达式的第一个位置,返回match对象
- re.search(pattern, string, flags=0)
- re.match()从一个字符串的开始位置起匹配正则表达式,返回match对象
- re.match(pattern, string, flags=0)
- re.findall()搜索字符串,以列表类型返回全部能匹配的子串
- re.findall(pattern, string, flags=0)
- re.split()将一个字符串按照正则表达式匹配结果进行分割,返回列表类型
- re.split(pattern, string, flags=0)
- re.finditer()搜索字符串,返回一个匹配结果的迭代类型,每个迭代元素是match对象
- re.finditer(pattern, string, flags=0)
- re.sub()在一各字符串中替换所有匹配正则表达式的子串,返回替换后的字符
- re.sub(pattern,string, flags=0)
参数解析:
- pattern:指的是正则表达式
- string:指的是我们需要进行操作的字符串
- flags : 正则表达式使用时的控制标记:
– re.I –> re.IGNORECASE : 忽略正则表达式的大小写,[A‐Z]能够匹配小写字符
– re.M –> re.MULTILINE : 正则表达式中的^操作符能够将给定字符串的每行当作匹配开始
– re.S –> re.DOTALL : 正则表达式中的.操作符能够匹配所有字符,默认匹配除换行外的所有字符
re库的另外一种等价用法(编译)
- regex = re.compile(pattern, flags=0):将正则表达式的字符串形式编译成正则表达式的对象。
#生成re对象:
import re
content = 'hello, i am a boy'
regex = re.compile('\w*')
sentence = regex.match(content)
sentence.group()
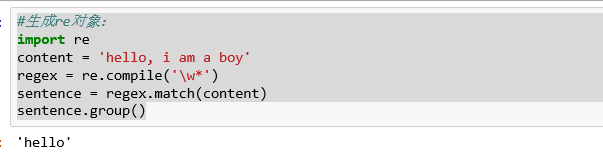

#调用函数
sentence = re.match('\w*', content)
sentence.group()

re库的贪婪匹配和最小匹配
- .* Re库默认采用贪婪匹配,即输出匹配最长的子串
- *? 只要长度可能不同的,都可以通过在操作符后增加?变成最小匹配
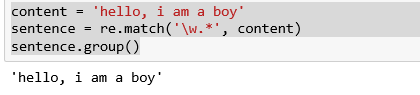
content = 'hello, i am a boy'
sentence = re.match('\w.*', content)
sentence.group()
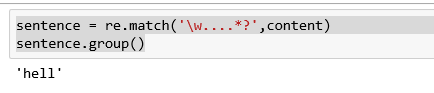
sentence = re.match('\w....*?',content)
sentence.group()
re实战(淘宝网)
目标任务:淘宝商品比价定向爬虫
-
本次任务不是爬取简单的公开网站,而是需要进行登录的网站。
-
user-agent:浏览器的请求头,伪装成浏览器访问
-
cookie:某些网站为了辩护用户身份,进行Session跟踪而储存在用户本地终端上的数据(通产进行加密),由用户客户端计算机暂时或永久保存的信息
-
爬取网址:https://s.taobao.com/search?q=书包&js=1&stats_click=search_radio_all%25
-
爬取思路:
- 提交商品搜索请求,循环获取页面
- 对于每个页面,提取商品名称和价格信息
- 将信息输出到屏幕上
#导入包
import requests
import re
1.提交商品搜索请求,循环获取页面
def getHTMLText(url):
""" 请求获取html,(字符串) :param url:爬取网址 :return:字符串 """
try:
#添加头信息。
kv = {
'cookie':'thw=cn; t=3a4bdb8ce710f4e08f06672eff50e11f; tracknick=%5Cu5B81%5Cu5B811506; enc=32crCvME19D5T1NsQOG7tM3gDhuldVnNxF5w1zi5Im8mzrEvaY5QTtwKNlQwxLBX0HzHlkoP3d7rEhajqxc10g%3D%3D; alitrackid=blog.csdn.net; _samesite_flag_=true; cookie2=17521ca57c5c81794cdfbef9bc911b57; _tb_token_=748de15575973; sgcookie=ELBr4B6ocMPiPRnpCjUuD; unb=1836673364; uc3=nk2=pzbgZmfhJt8%3D&lg2=WqG3DMC9VAQiUQ%3D%3D&id2=UonYtwYyCmtNnA%3D%3D&vt3=F8dBxGR00GvTSr%2Foeq4%3D; csg=a5febed0; lgc=%5Cu5B81%5Cu5B811506; cookie17=UonYtwYyCmtNnA%3D%3D; dnk=%5Cu5B81%5Cu5B811506; skt=4810f4df38a08bb5; existShop=MTU4NzczMTI5MQ%3D%3D; uc4=nk4=0%40pQCSQaNt9vUvrb9b%2Frbk64nNPg%3D%3D&id4=0%40UOEy0PVcvmzEYslIV%2BnxO7u8WPBq; _cc_=UtASsssmfA%3D%3D; _l_g_=Ug%3D%3D; sg=64e; _nk_=%5Cu5B81%5Cu5B811506; cookie1=AnOUmyuG%2FSGOMG%2FTgbi6kT4HmCgSwMuD7OzFxs1fmH4%3D; tfstk=ctd5B0qAeuqWrUAzgHgVUhUj1YCCZ9PfoSj2PKKv6lnE2KT5iyNNfvfdPoNABZ1..; lastalitrackid=login.taobao.com; uc1=cookie16=U%2BGCWk%2F74Mx5tgzv3dWpnhjPaQ%3D%3D&cookie21=VT5L2FSpccLuJBreK%2BBd&cookie15=WqG3DMC9VAQiUQ%3D%3D&existShop=false&pas=0&cookie14=UoTUPcvNlDaTLA%3D%3D; mt=ci=98_1; v=0; JSESSIONID=07211823E845B1F60CC7BFC7059495D2; isg=BNracrXJUHfcN9wJi-nwL8XlK4D8C17lvKS64eRTJ204V3mRzJj29eplJyNLh9Z9; l=eBxTR0u7QyjArwtDBO5wlurza779NIRf1sPzaNbMiIHca6HFTFgYxNQc0yPW7dtjgtfAQetrhV5GsRnkSMUKg2HvCbKrCyCloxJw-',
'user-agent':'Mozilla/5.0'
}
r = requests.get(url, timeout=30, headers=kv)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return '爬取失败'
2.对于每个页面,提取商品名称和价格信息
def parsePage(glist, html):
""" 解析网页,搜索需要的信息 :param glist:列表作为存储容器 :return:商品信息的列表 """
try:
#使用正则表达式提取信息
price_list = re.findall(r'\"view_price"\:\"[\d\.]*\"',html)
name_list = re.findall(r'\"raw_title\"\:\".*?\"',html)
for i in range(len(price_list)):
price = eval(price_list[i].split(":")[1])
name = eval(name_list[i].split(":")[1])
glist.append([price, name])
except:
print('解析失败')
3.将信息输出到屏幕上
def printGoodList(glist):
tplt = "{0:^4}\t{1:^6}\t{2:^10}"
print(tplt.format("序号", "商品价格", "商品名称"))
count = 0
for g in glist:
count = count + 1
print(tplt.format(count, g[0], g[1]))
# 根据页面url的变化寻找规律,构建爬取url
goods_name = "书包" # 搜索商品类型
start_url = "https://s.taobao.com/search?q=" + goods_name
info_list = []
page = 3 # 爬取页面数量
count = 0
for i in range(page):
count += 1
try:
url = start_url + "&s=" + str(44*i)
html = getHTMLText(url)#爬取url
parsePage(info_list, html)#解析HTMl和爬取内容
print('\r爬取页面当前进度:{:.2f}%'.format(count*100/page),end='')#显示进度条
except:
continue
printGoodList(info_list)

发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/150579.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
