大家好,又见面了,我是你们的朋友全栈君。
一般来说,机器学习有三种算法:
1.监督式学习
监督式学习算法包括一个目标变量(也就是因变量)和用来预测目标变量的预测变量(相当于自变量).通过这些变量,我们可以搭建一个模型,从而对于一个自变量,我们可以得到对应的因变量.重复训练这个模型,直到它能在训练数据集上达到理想的准确率
属于监督式学习的算法有:回归模型,决策树,随机森林,K近邻算法,逻辑回归等算法
2.无监督式算法
无监督式学习不同的是,无监督学习中我们没有需要预测或估计的因变量.无监督式学习是用来对总体对象进行分类的.它在根据某一指标将客户分类上有广泛作用.
属于无监督式学习的算法有:关联规则,K-means聚类算法等
3.强化学习
这个算法可以训练程序作出某一决定,程序在某一情况下尝试所有的可能行为,记录不同行动的结果并试着找出最好的一次尝试来做决定
属于强化学习的算法有:马尔可夫决策过程
常见的机器学习算法有:
1.线性回归 (Linear Regression)
2.逻辑回归 (Logistic Regression)
3.决策树 (Decision Tree)
4.支持向量机(SVM)
5.朴素贝叶斯 (Naive Bayes)
6.K邻近算法(KNN)
7.K-均值算法(K-means)
8.随机森林 (Random Forest)
9.降低维度算法(Dimensionality Reduction Algorithms)
10.Gradient Boost和Adaboost算法一个一个来说:
1.线性回归
线性回归是利用连续性变量来估计实际数值(比如房价等),我们通过线性回归算法找出自变量和因变量的最佳线性关系,图形上可以确定一条最佳的直线.这条最佳直线就是回归线.线性回归关系可以用Y=ax+b表示.
在这个Y=ax+b这个公式里:
Y=因变量
a =斜率
x=自变量
b=截距
a和b可以通过最下化因变量误差的平方和得到(最小二乘法)
我们可以假想一个场景来理解线性回归.比如你让一个五年级的孩子在不问同学具体体重多少的情况下,把班上的同学按照体重从轻到重排队。这个孩子会怎么做呢?他有可能会通过观察大家的身高和体格来排队。这就是线性回归!这个孩子其实是认为身高和体格与人的体重有某种相关。而这个关系就像是前一段的Y和X的关系。
给大家画一个图,方便理解,下图用的线性回归方程是Y=0.28x+13.9.通过这个方程,就可以根据一个人的身高预测他的体重信息.

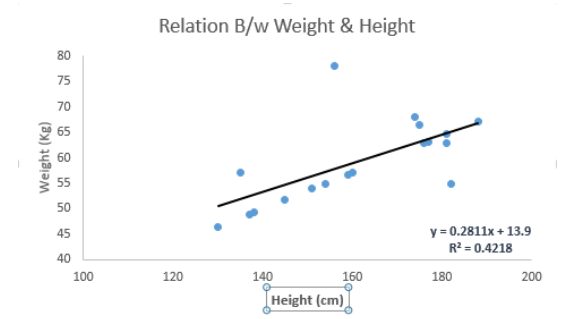
线性回归还分为:一元线性回归和多元线性回归.很明显一元只有一个自变量,多元有多个自变量.
拟合多元线性回归的时候,可以利用多项式回归或曲线回归
Import Library
from sklearn import linear_model
x_train=input_variables_values_training_datasets
y_train=target_variables_values_training_datasets
x_test=input_variables_values_test_datasets
# Create linear regression object
linear = linear_model.LinearRegression()
# Train the model using the training sets and check score
linear.fit(x_train, y_train)
linear.score(x_train, y_train)
#Equation coefficient and Intercept
print('Coefficient: \n', linear.coef_)
print('Intercept: \n', linear.intercept_)
#Predict Output
predicted= linear.predict(x_test)2.逻辑回归
逻辑回归最早听说的时候以为是回归算法,其实是一个分类算法,不要让他的名字迷惑了.通常利用已知的自变量来预测一个离散型因变量的值(通常是二分类的值).简单来讲,他就是通过拟合一个Lg来预测一个时间发生的概率,所以他预测的是一个概率值,并且这个值是在0-1之间的,不可能出这个范围,除非你遇到了一个假的逻辑回归!
同样用例子来理解:
假设你的一个朋友让你回答一道题。可能的结果只有两种:你答对了或没有答对。为了研究你最擅长的题目领域,你做了各种领域的题目。那么这个研究的结果可能是这样的:如果是一道十年级的三角函数题,你有70%的可能性能解出它。但如果是一道五年级的历史题,你会的概率可能只有30%。逻辑回归就是给你这样的概率结果。
数学又来了,做算法这行业是离不开数学的,还是好好学学数学吧
最终事件的预测变量的线性组合就是:
odds= p/ (1-p) = probability of event occurrence / probability of not event occurrence
ln(odds) = ln(p/(1-p))
logit(p) = ln(p/(1-p)) = b0+b1X1+b2X2+b3X3....+bkXk在这里,p是我们感兴趣的事件出现的概率.他通过筛选出特定参数值使得观察到的样本值出现的概率最大化,来估计参数,而不是像普通回归那样最小化误差的平方和.
至于有的人会问,为什么需要做对数呢?简单来说这是重复阶梯函数的最佳方法.
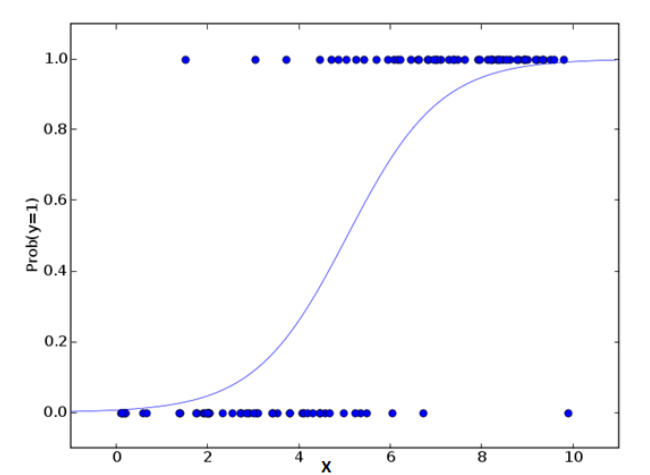
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
# Train the model using the training sets and check score
model.fit(X, y)
model.score(X, y)
#Equation coefficient and Intercept
print('Coefficient: \n', model.coef_)
print('Intercept: \n', model.intercept_)
#Predict Output
predicted= model.predict(x_test)逻辑回归的优化:
加入交互项
减少特征变量
正则化
使用非线性模型
3.决策树
这是我最喜欢也是能经常使用到的算法。它属于监督式学习,常用来解决分类问题。令人惊讶的是,它既可以运用于类别变量(categorical variables)也可以作用于连续变量。这个算法可以让我们把一个总体分为两个或多个群组。分组根据能够区分总体的最重要的特征变量/自变量进行。
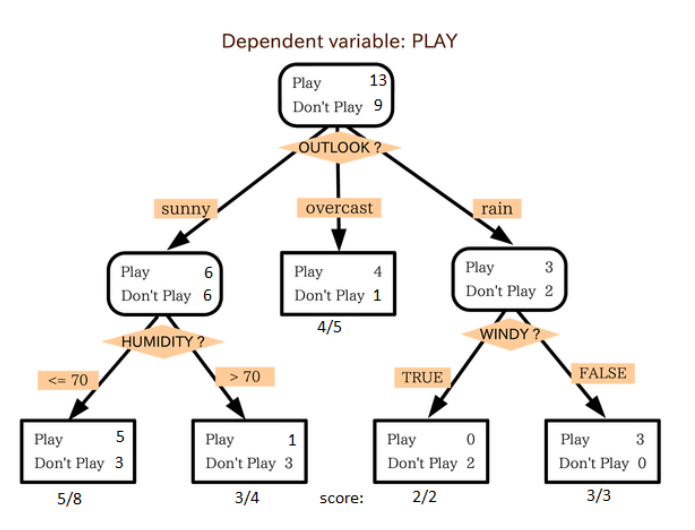
从上图中我们可以看出,总体人群最终在玩与否的事件上被分成了四个群组。而分组是依据一些特征变量实现的。用来分组的具体指标有很多,比如Gini,information Gain, Chi-square,entropy。
from sklearn import tree
# Create tree object
model = tree.DecisionTreeClassifier(criterion='gini') # for classification, here you can change the algorithm as gini or entropy (information gain) by default it is gini
# model = tree.DecisionTreeRegressor() for regression
# Train the model using the training sets and check score
model.fit(X, y)
model.score(X, y)
#Predict Output
predicted= model.predict(x_test)4. 支持向量机(SVM)
这是一个分类算法。在这个算法中我们将每一个数据作为一个点在一个n维空间上作图(n是特征数),每一个特征值就代表对应坐标值的大小。比如说我们有两个特征:一个人的身高和发长。我们可以将这两个变量在一个二维空间上作图,图上的每个点都有两个坐标值(这些坐标轴也叫做支持向量)。
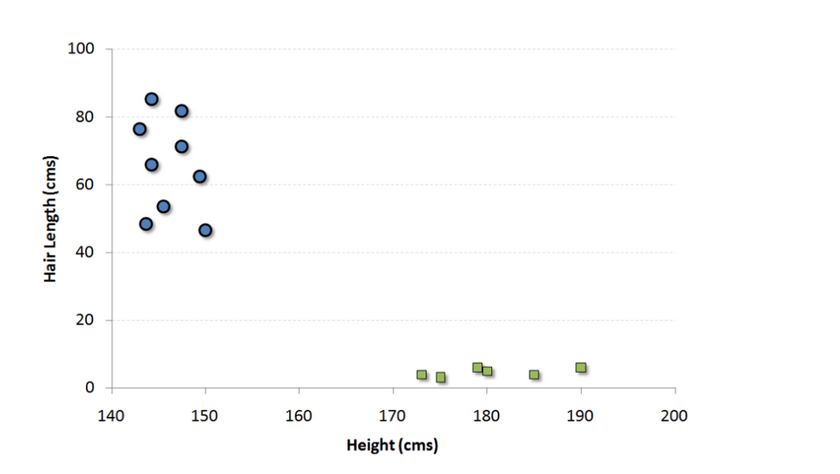
现在我们要在图中找到一条直线能最大程度将不同组的点分开。两组数据中距离这条线最近的点到这条线的距离都应该是最远的。
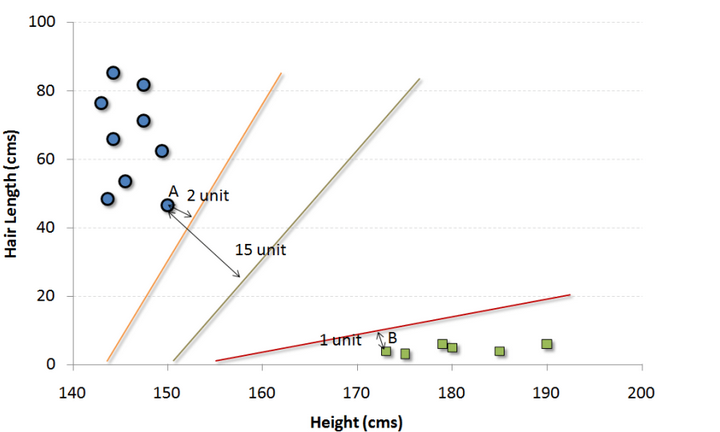
在上图中,黑色的线就是最佳分割线。因为这条线到两组中距它最近的点,点A和B的距离都是最远的。任何其他线必然会使得到其中一个点的距离比这个距离近。这样根据数据点分布在这条线的哪一边,我们就可以将数据归类。
#Import Library
from sklearn import svm
#Assumed you have, X (predictor) and Y (target) for training data set and x_test(predictor) of test_dataset
# Create SVM classification object
model = svm.svc() # there is various option associated with it, this is simple for classification. You can refer link, for mo# re detail.
# Train the model using the training sets and check score
model.fit(X, y)
model.score(X, y)
#Predict Output
predicted= model.predict(x_test)5. 朴素贝叶斯
这个算法是建立在贝叶斯理论上的分类方法。它的假设条件是自变量之间相互独立。简言之,朴素贝叶斯假定某一特征的出现与其它特征无关。比如说,如果一个水果它是红色的,圆状的,直径大概7cm左右,我们可能猜测它为苹果。即使这些特征之间存在一定关系,在朴素贝叶斯算法中我们都认为红色,圆状和直径在判断一个水果是苹果的可能性上是相互独立的。
朴素贝叶斯的模型易于建造,并且在分析大量数据问题时效率很高。虽然模型简单,但很多情况下工作得比非常复杂的分类方法还要好。
贝叶斯理论告诉我们如何从先验概率P(c),P(x)和条件概率P(x|c)中计算后验概率P(c|x)。算法如下:

-
P(c|x)是已知特征x而分类为c的后验概率。
-
P(c)是种类c的先验概率。
-
P(x|c)是种类c具有特征x的可能性。
-
P(x)是特征x的先验概率。
例子: 以下这组训练集包括了天气变量和目标变量“是否出去玩”。我们现在需要根据天气情况将人们分为两组:玩或不玩。整个过程按照如下步骤进行:
步骤1:根据已知数据做频率表
步骤2:计算各个情况的概率制作概率表。比如阴天(Overcast)的概率为0.29,此时玩的概率为0.64.
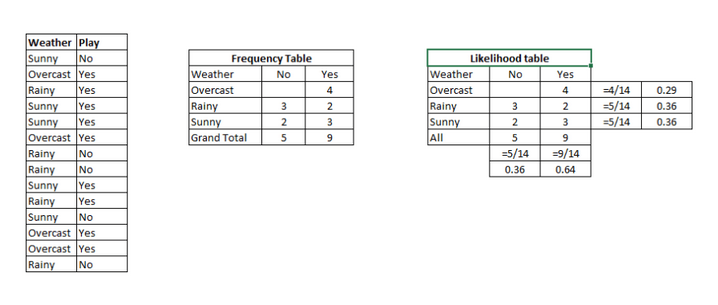
步骤3:用朴素贝叶斯计算每种天气情况下玩和不玩的后验概率。概率大的结果为预测值。
提问: 天气晴朗的情况下(sunny),人们会玩。这句陈述是否正确?
我们可以用上述方法回答这个问题。P(Yes | Sunny)=P(Sunny | Yes) * P(Yes) / P(Sunny)。
这里,P(Sunny |Yes) = 3/9 = 0.33, P(Sunny) = 5/14 = 0.36, P(Yes)= 9/14 = 0.64。
那么,P (Yes | Sunny) = 0.33 * 0.64 / 0.36 = 0.60>0.5,说明这个概率值更大。
当有多种类别和多种特征时,预测的方法相似。朴素贝叶斯通常用于文本分类和多类别分类问题。
#Import Library
from sklearn.naive_bayes import GaussianNB
#Assumed you have, X (predictor) and Y (target) for training data set and x_test(predictor) of test_dataset
# Create SVM classification object model = GaussianNB() # there is other distribution for multinomial classes like Bernoulli Naive Bayes, Refer link
# Train the model using the training sets and check score
model.fit(X, y)
#Predict Output
predicted= model.predict(x_test)6.KNN(K-邻近算法)
这个算法既可以解决分类问题,也可以用于回归问题,但工业上用于分类的情况更多。 KNN先记录所有已知数据,再利用一个距离函数,找出已知数据中距离未知事件最近的K组数据,最后按照这K组数据里最常见的类别预测该事件。
距离函数可以是欧式距离,曼哈顿距离,闵氏距离 (Minkowski Distance), 和汉明距离(Hamming Distance)。前三种用于连续变量,汉明距离用于分类变量。如果K=1,那问题就简化为根据最近的数据分类。K值的选取时常是KNN建模里的关键。
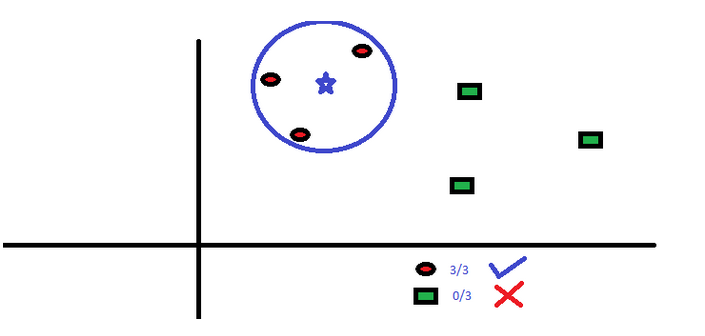
KNN在生活中的运用很多。比如,如果你想了解一个不认识的人,你可能就会从这个人的好朋友和圈子中了解他的信息。
在用KNN前你需要考虑到:
-
KNN的计算成本很高
-
所有特征应该标准化数量级,否则数量级大的特征在计算距离上会有偏移。
-
在进行KNN前预处理数据,例如去除异常值,噪音等。
#Import Library
from sklearn.neighbors import KNeighborsClassifier
#Assumed you have, X (predictor) and Y (target) for training data set and x_test(predictor) of test_dataset
# Create KNeighbors classifier object model
KNeighborsClassifier(n_neighbors=6) # default value for n_neighbors is 5
# Train the model using the training sets and check score
model.fit(X, y)
#Predict Output
predicted= model.predict(x_test)7. K均值算法(K-Means)
这是一种解决聚类问题的非监督式学习算法。这个方法简单地利用了一定数量的集群(假设K个集群)对给定数据进行分类。同一集群内的数据点是同类的,不同集群的数据点不同类。
还记得你是怎样从墨水渍中辨认形状的么?K均值算法的过程类似,你也要通过观察集群形状和分布来判断集群数量!
K均值算法如何划分集群:
从每个集群中选取K个数据点作为质心(centroids)。
将每一个数据点与距离自己最近的质心划分在同一集群,即生成K个新集群。
找出新集群的质心,这样就有了新的质心。
重复2和3,直到结果收敛,即不再有新的质心出现。
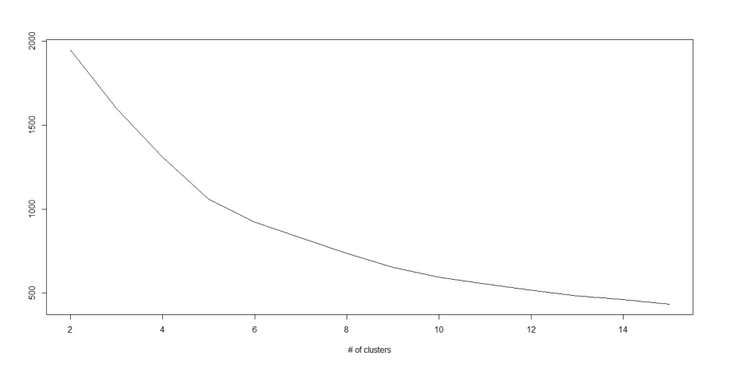
怎样确定K的值:
如果我们在每个集群中计算集群中所有点到质心的距离平方和,再将不同集群的距离平方和相加,我们就得到了这个集群方案的总平方和。
我们知道,随着集群数量的增加,总平方和会减少。但是如果用总平方和对K作图,你会发现在某个K值之前总平方和急速减少,但在这个K值之后减少的幅度大大降低,这个值就是最佳的集群数。

#Import Library
from sklearn.cluster import KMeans
#Assumed you have, X (attributes) for training data set and x_test(attributes) of test_dataset
# Create KNeighbors classifier object model
k_means = KMeans(n_clusters=3, random_state=0)
# Train the model using the training sets and check score
model.fit(X)
#Predict Output
predicted= model.predict(x_test)8.随机森林
随机森林是对决策树集合的特有名称。随机森林里我们有多个决策树(所以叫“森林”)。为了给一个新的观察值分类,根据它的特征,每一个决策树都会给出一个分类。随机森林算法选出投票最多的分类作为分类结果。
怎样生成决策树:
-
如果训练集中有N种类别,则有重复地随机选取N个样本。这些样本将组成培养决策树的训练集。
-
如果有M个特征变量,那么选取数m << M,从而在每个节点上随机选取m个特征变量来分割该节点。m在整个森林养成中保持不变。
-
每个决策树都最大程度上进行分割,没有剪枝。
#Import Library from sklearn.ensemble import RandomForestClassifier #Assumed you have, X (predictor) and Y (target) for training data set and x_test(predictor) of test_dataset # Create Random Forest object model= RandomForestClassifier() # Train the model using the training sets and check score model.fit(X, y) #Predict Output predicted= model.predict(x_test)9.降维算法(Dimensionality Reduction Algorithms)
在过去的4-5年里,可获取的数据几乎以指数形式增长。公司/政府机构/研究组织不仅有了更多的数据来源,也获得了更多维度的数据信息。
例如:电子商务公司有了顾客更多的细节信息,像个人信息,网络浏览历史,个人喜恶,购买记录,反馈信息等,他们关注你的私人特征,比你天天去的超市里的店员更了解你。
作为一名数据科学家,我们手上的数据有非常多的特征。虽然这听起来有利于建立更强大精准的模型,但它们有时候反倒也是建模中的一大难题。怎样才能从1000或2000个变量里找到最重要的变量呢?这种情况下降维算法及其他算法,如决策树,随机森林,PCA,因子分析,相关矩阵,和缺省值比例等,就能帮我们解决难题。
#Import Libraryfrom sklearn import decomposition#Assumed you have training and test data set as train and test# Create PCA obeject pca= decomposition.PCA(n_components=k) #default value of k =min(n_sample, n_features)# For Factor analysis#fa= decomposition.FactorAnalysis()# Reduced the dimension of training dataset using PCAtrain_reduced = pca.fit_transform(train)#Reduced the dimension of test datasettest_reduced = pca.transform(test)10.Gradient Boosing 和 AdaBoost
GBM和AdaBoost都是在有大量数据时提高预测准确度的boosting算法。Boosting是一种集成学习方法。它通过有序结合多个较弱的分类器/估测器的估计结果来提高预测准确度。这些boosting算法在Kaggle,AV Hackthon, CrowdAnalytix等数据科学竞赛中有出色发挥。
#Import Library
from sklearn.ensemble import GradientBoostingClassifier
#Assumed you have, X (predictor) and Y (target) for training data set and x_test(predictor) of test_dataset
# Create Gradient Boosting Classifier object
model= GradientBoostingClassifier(n_estimators=100, learning_rate=1.0, max_depth=1, random_state=0)
# Train the model using the training sets and check score
model.fit(X, y)
#Predict Output
predicted= model.predict(x_test)GradientBoostingClassifier 和随机森林是两种不同的boosting分类树。人们经常提问
这两个算法有什么不同。
原文链接:http://blog.csdn.net/han_xiaoyang/article/details/51191386
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/150559.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
